说明
本次实验考虑两个点:
- 1 按照上一篇谈到的业务目标进行反推,有针对性的寻找策略
- 2 worker增加计算的指标,重新计算之前的实验
内容
工具方面,感觉rabbitmq还是太慢了。看了下,rabbitmq主要还是面向可靠和灵活路由的。目前我的需求虽然不是很需要速度,但是这吞吐太低了实在难受。特别是从结果队列里取数,一条一条的。
终于可以接着继续写了,这周还是很忙,不过成果不错。比较开心小伙伴帮我搞定了kafka,我这个java绝缘体真的是只要搞java就碰到坑。在kafka的过程中,对性能比较关注,实测下来发现json序列化的开销实在是很大。在消息的传输过程中,为了通用性,我对数据都进行了json传输,时间占比在整体80%以上。
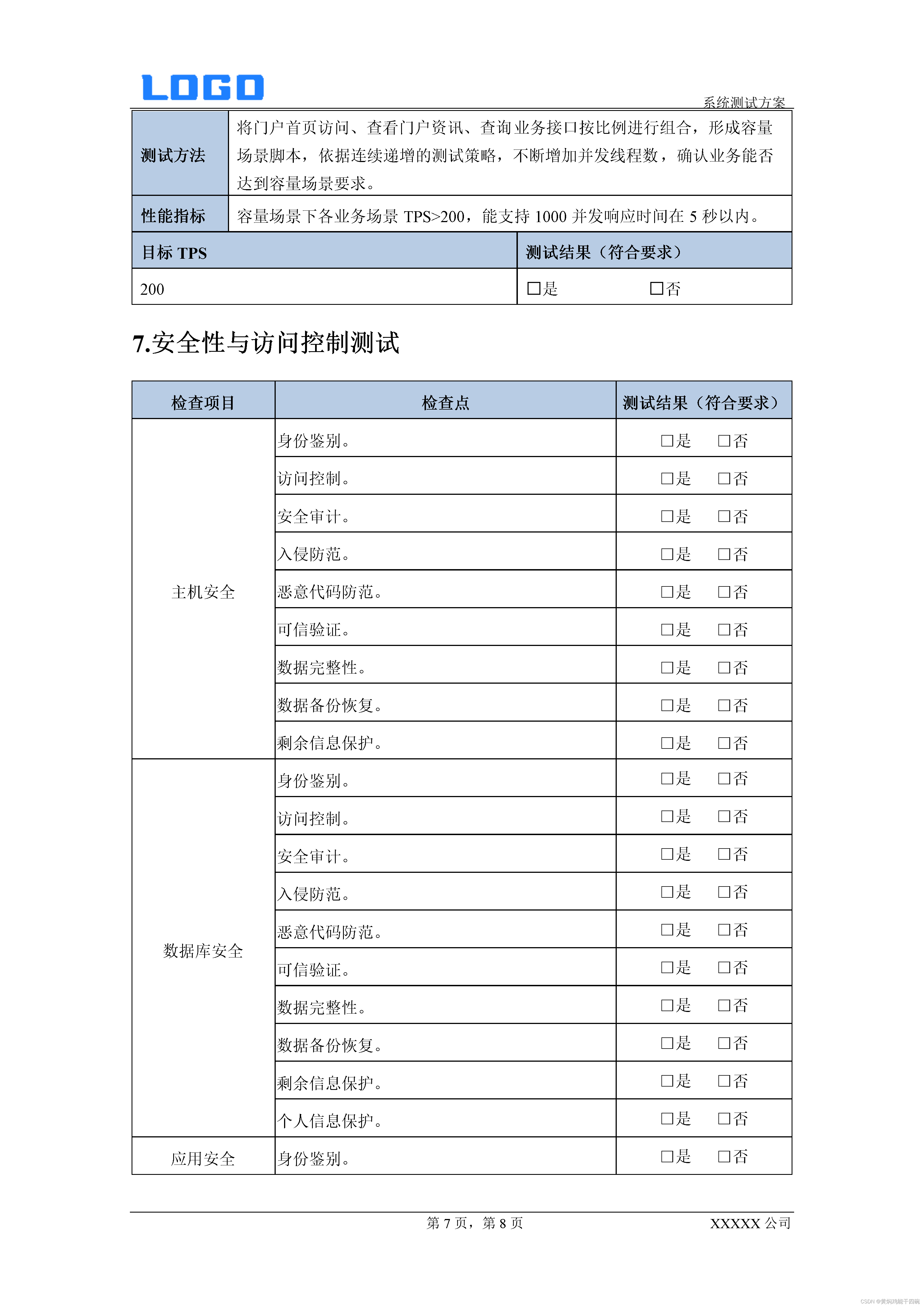
与实验相关的是:这次打算开多个worker快速跑数,一个本能是想利用缓存–Redis。后来一试发现比clickhouse慢了一个量级,前后一想就对上了—序列化太费了。
如果数据是结构化的,尽量直接使用结构化数据库
另外正好最近在转向ORM方式,突然发现实验要保存的数据通过这种方式更加合适。
1 结果对象
先定义结果的数据模型,然后使用mysql进行全局存储。
以下按照之前的计划,生成了短、中、长期指标。
from Basefuncs import *
from sqlalchemy import create_engine, Column, Integer, String, Float, DateTime, Index
from sqlalchemy.orm import sessionmaker,declarative_base
from datetime import datetime
import shortuuid
def get_shortuuid(charset=None):
"""
生成一个简洁的唯一标识符(短 UUID)。
参数:
charset (str, optional): 自定义的字符集。如果未提供,将使用默认字符集。
返回:
str: 生成的短 UUID。
"""
if charset:
su = shortuuid.ShortUUID(charset=charset)
return su.uuid()
else:
return shortuuid.uuid()
m7_24013_url = f"mysql+pymysql://USER:PASSWD@IP:PORT/mydb"
# from urllib.parse import quote_plus
# the_passed = quote_plus('!@#*')
# # 创建数据库引擎
m7_engine = create_engine(m7_24013_url)
# 创建基类
Base = declarative_base()
# 定义数据类型
class SMAEMABacktest(Base):
__tablename__ = 'smaema_backtest'
id = Column(Integer, primary_key=True,autoincrement=True)
short_uuid = Column(String(50), default = lambda: get_shortuuid())
strategy_name = Column(String(50))
long_t = Column(Integer)
short_t = Column(Integer)
deals = Column(Integer)
# 交易时间
median_trade_days = Column(Integer)
# 单利润率
total_mean_npr = Column(Float)
last3_mean_npr = Column(Float)
last1_mean_npr = Column(Float)
# 盈亏比
total_win_loss_ratio = Column(Float)
last3_win_loss_ratio = Column(Float)
last1_win_loss_ratio = Column(Float)
# 胜率
total_win_rate = Column(Float)
last3_win_rate = Column(Float)
last1_win_rate = Column(Float)
get_data_duration = Column(Float)
process_data_duration = Column(Float)
create_time = Column(DateTime, default=lambda: datetime.now())
#def __init__(self,**kwargs):
# self.short_uuid = get_shortuuid()
# for key, value in kwargs.items():
# if key in ['create_time'] and isinstance(value, str):
# value = datetime.strptime(value, '%Y-%m-%d %H:%M:%S')
# setattr(self, key, value)
# 创建表
Base.metadata.create_all(m7_engine)
开始读取数据, 70万条数据1.15秒从数据库取出(如果用redis我记得大约是8秒)
short_t = 100
long_t = 200
# sma
sma_result = SMAEMABacktest(strategy_name ='sma', long_t = long_t, short_t = short_t)
# ema
ema_result = SMAEMABacktest(strategy_name ='ema', long_t = long_t, short_t = short_t)
ch_cfg = CHCfg(database=clickhouse_db, host = clickhouse_ip )
chc = CHClient(**ch_cfg.dict())
query_sql = f'select {clickhouse_select_cols_str} from {clickhouse_table_name}'
tick1 = time.time()
data = chc._exe_sql(query_sql)
tick2 = time.time()
print('getting data %.2f' % (tick2 - tick1 ))
getting data 1.15
主程序如下: 当worker开始执行时去队列取数,然后把结果写到数据库里。
大体上是这样的效果:

2 处理逻辑
def process(input_smaema = None, Session = Session):
gfgo_lite_server = input_smaema.gfgo_lite_server
short_t = input_smaema.short_t
long_t = input_smaema.long_t
clickhouse_db = input_smaema.clickhouse_db
clickhouse_ip = input_smaema.clickhouse_ip
clickhouse_table_name = input_smaema.clickhouse_table_name
clickhouse_select_cols = input_smaema.clickhouse_select_cols
clickhouse_select_cols_str = input_smaema.clickhouse_select_cols_str
ucs = UCS(gfgo_lite_server =gfgo_lite_server)
# Base对象不是pydantic允许属性为空
# sma
sma_result = SMAEMABacktest(strategy_name ='sma', long_t = long_t, short_t = short_t)
# ema
ema_result = SMAEMABacktest(strategy_name ='ema', long_t = long_t, short_t = short_t)
ch_cfg = CHCfg(database=clickhouse_db, host = clickhouse_ip )
chc = CHClient(**ch_cfg.dict())
query_sql = f'select {clickhouse_select_cols_str} from {clickhouse_table_name}'
tick1 = time.time()
data = chc._exe_sql(query_sql)
tick2 = time.time()
print('getting data %.2f' % (tick2 - tick1 ))
t1 = short_t
t2 = long_t
df = pd.DataFrame(data, columns = ['shard','part','block','brick','code','amt','close','high','low',
'open', 'data_dt', 'pid', 'ts','vol'])
df1 = df.sort_values(['data_dt'])
'''
bfill 是 "backward fill" 的缩写,是一种处理缺失值的方法。在数据处理中,当数据序列中存在缺失值(NaN,即 "Not a Number")时,bfill 方法会用该缺失值后面的有效值来填充这个缺失值。
具体来说,bfill 方法从序列的末尾开始向前查找,找到第一个非缺失值,并用这个值来填充前面的缺失值。这个过程会一直进行,直到所有的缺失值都被填充完毕或者到达序列的开头。
'''
df1['sma_t1'] = df1['close'].rolling(window=t1).mean().bfill()
df1['sma_t2'] = df1['close'].rolling(window=t2).mean().bfill()
# 计算指数移动平均线
df1['ema_t1'] = df1['close'].ewm(span=t1, adjust=False).mean()
df1['ema_t2'] = df1['close'].ewm(span=t2, adjust=False).mean()
# 回测
bt_df = df1
import tqdm
# ----------------------- sma
open_orders = []
close_orders = []
for i in tqdm.tqdm(range(len(bt_df))):
tem_dict = dict(bt_df.iloc[i])
data_dt = tem_dict['data_dt']
close = tem_dict['close']
sma_t1 = tem_dict['sma_t1']
sma_t2 = tem_dict['sma_t2']
if len(open_orders) == 0:
if sma_t1 > sma_t2:# 金叉
order_dict = {}
order_dict['but_dt'] = data_dt
order_dict['buy_price'] = close
open_orders.append(order_dict)
continue
if len(open_orders):
if sma_t1< sma_t2: # 死叉
for item in reversed(open_orders):
order_dict = open_orders.pop()
order_dict['sell_dt'] = data_dt
order_dict['sell_price'] = close
order_dict['gp'] = order_dict['sell_price'] - order_dict['buy_price']
close_orders.append(order_dict)
tick3 = time.time()
close_df = pd.DataFrame(close_orders)
sma_result = cal_kpis(close_df = close_df, some_obj = sma_result)
sma_result.get_data_duration = round(tick2 -tick1 , 3)
sma_result.process_data_duration = round(tick3 -tick2 , 3)
with Session() as session:
session.add(sma_result)
session.commit()
# ========================= ema
tick4 = time.time()
open_orders = []
close_orders = []
for i in tqdm.tqdm(range(len(bt_df))):
tem_dict = dict(bt_df.iloc[i])
data_dt = tem_dict['data_dt']
close = tem_dict['close']
ema_t1 = tem_dict['ema_t1']
ema_t2 = tem_dict['ema_t2']
if len(open_orders) == 0:
if ema_t1 > ema_t2:# 金叉
order_dict = {}
order_dict['but_dt'] = data_dt
order_dict['buy_price'] = close
open_orders.append(order_dict)
continue
if len(open_orders):
if ema_t1< ema_t2: # 死叉
for item in reversed(open_orders):
order_dict = open_orders.pop()
order_dict['sell_dt'] = data_dt
order_dict['sell_price'] = close
order_dict['gp'] = order_dict['sell_price'] - order_dict['buy_price']
close_orders.append(order_dict)
tick5 = time.time()
close_df = pd.DataFrame(close_orders)
close_df = pd.DataFrame(close_orders)
ema_result = cal_kpis(close_df = close_df, some_obj = ema_result)
ema_result.get_data_duration = round(tick2 -tick1 , 3)
ema_result.process_data_duration = round(tick5 -tick4 , 3)
with Session() as session:
session.add(ema_result)
session.commit()
print('done')
if __name__ =='__main__':
rm = RabbitManager()
# 获取1个数据
data_list = rm.get_message_early_ack('smaema', count=1)
if len(data_list):
the_task = data_list[0]
short_t = the_task['short_t']
long_t = the_task['long_t']
input_smaema = InputSMAEMA_Para(short_t = short_t ,long_t = long_t)
process(input_smaema)
3 调度
最近也在研究一些简单又可靠的调度方法。
- 1 cron: 简单是简单了,就是有很多缺陷。首先是只能到分钟级,另外没有任务的控制,反正到点就触发。这样如果是长耗时任务,很可能发太多撑爆内存。
- 2 nohup + for(while) : 简单,但是不好控制worker的数量。
- 3 nohup + apscheduler : 这个可以有。最初是打算docker + aps的,但那样要么都执行docker worker,要么就要管理挂载,比较麻烦。未来模式成熟了,可以考虑同时保留 systemd + aps 和docker + aps 两种简单的调度模式并存。
from datetime import datetime
import os
from apscheduler.schedulers.blocking import BlockingScheduler
def exe_sh(cmd = None):
os.system(cmd)
# 后台启动命令 nohup python3 aps.py >/dev/null 2>&1 &
if __name__ == '__main__':
sche1 = BlockingScheduler()
# sche1.add_job(exe_sh,'interval', seconds=1, kwargs ={'cmd':'python3 ./main_handler/main.py'})
sche1.add_job(exe_sh,'interval', seconds=10,
kwargs ={'cmd':'python3 qtv200_0004_sma_ema_clickhouse.py'},
max_instances=20,coalesce=True)
print('[S] starting inteverl')
sche1.start()
我启动了周期任务,10秒一次,最多允许20个任务实例,且超时任务最后会合并(为1次)。看到这种方法是满核调用的。


有意思的是,我问了下deepseek,如果没有骗我的话,aps默认是线程池。

一般来说,python是单进程~单线程的。如果在一个脚本内,一般来说不会突破一个核的限制。现在在调度模式下一个线程实际上触发了多个线程的工作,某种程度上说就绕过了这个限制。
4 结果
还挺理想的,8个核 ~ 20 worker,在睡一觉之后,大约完成了 10%的任务。我打算在另一个位置也启动一下worker。另外注意到租用机的数据读取时间是2秒,比我的主机慢了一倍。

总体上,本次实验应该算是成功了:
指标计算的提升:
- 1 增加了盈亏比
- 2 增加了胜率
架构和工具方面的提升:
- 1 使用clickhouse,增强了worker处理速度
- 2 使用ORM,灵活存储
- 3 使用APS调度
下一步:
- 1 对结果进行数据分析,例如聚类,以发现规律
- 2 准备展开更多的标的的计算,暂时先考虑SMA/EMA策略
- 3 将选出的策略与强化学习框架对接
- 4 准备前端投射,实盘操作