机器学习&深度学习中的搜索算法浅谈
搜索算法是计算机科学中的核心算法,用于在各种数据结构(如数组、列表、树、图等)中查找特定元素或信息。这些算法不仅在理论上具有重要意义,还在实际应用中扮演着关键角色。本文将详细探讨搜索算法的基本概念、常见分类及经典算法(如A*算法及其变种),并介绍这些算法在不同场景中的应用。
1. 什么是搜索算法?
搜索算法用于在给定的数据结构中查找特定元素或满足特定条件的信息。无论是查找一个数字、搜索路径,还是在复杂图结构中定位某个节点,搜索算法都能帮助我们有效地找到目标。
举个栗子:想象你在图书馆寻找一本书。你可以从头到尾检查每个书架上的每本书,直到找到它。这类似于线性搜索。如果书架按照书名的字母顺序排列,你可以使用更高效的方法,从中间开始寻找,逐步缩小搜索范围,这类似于二分搜索。如果你在城市中寻找某个地方,你可能会从一个地点开始,按照既定的路线进行探索,这类似于深度优先搜索(DFS)。而如果你选择从市中心开始,逐步扩展到周围的区域,这就像广度优先搜索(BFS)。
2. 常见的搜索算法分类
搜索算法可以按照应用方式和目标数据结构进行分类。以下是几种常见的搜索算法:
2.1 线性搜索(Linear Search)
线性搜索是最基本的搜索算法。它逐一检查数据结构中的每个元素,直到找到目标元素或遍历完所有元素为止。
数学意义:
- 给定一个包含
n
n
n 个元素的数组
A
A
A,线性搜索目标值
x
x
x 的过程可以描述为:
for i = 0 to n − 1 do \text{for } i = 0 \text{ to } n-1 \text{ do} for i=0 to n−1 do
if A [ i ] = x then return i \quad \text{if } A[i] = x \text{ then return } i if A[i]=x then return i
else continue \quad \text{else } \text{continue} else continue
如果找到目标值 x x x,返回其索引,否则返回 -1 表示未找到。
时间复杂度:O(n),其中n是数据结构中的元素个数。
空间复杂度:O(1),不需要额外的存储空间。
举个栗子:假设你在一组无序的电话号码列表中寻找一个特定的号码,你只能从头到尾逐个查看,直到找到它,这就是线性搜索的原理。
代码示例:
def linear_search(arr, target):
for i in range(len(arr)):
if arr[i] == target:
return i
return -1
2.2 二分搜索(Binary Search)
二分搜索是一种高效的搜索算法,适用于有序数据结构。它通过每次将搜索范围一分为二,不断缩小查找区间,直到找到目标元素或确定目标不存在。
数学意义:
- 二分搜索在数组
A
A
A 中查找目标值
x
x
x 的过程如下:
low = 0 \text{low} = 0 low=0
high = n − 1 \text{high} = n-1 high=n−1
while low ≤ high do \text{while } \text{low} \leq \text{high} \text{ do} while low≤high do
mid = ⌊ low + high 2 ⌋ \quad \text{mid} = \left\lfloor \frac{\text{low} + \text{high}}{2} \right\rfloor mid=⌊2low+high⌋
if A [ mid ] = x then return mid \quad \text{if } A[\text{mid}] = x \text{ then return } \text{mid} if A[mid]=x then return mid
else if A [ mid ] < x then low = mid + 1 \quad \text{else if } A[\text{mid}] < x \text{ then low} = \text{mid} + 1 else if A[mid]<x then low=mid+1
else high = mid − 1 \quad \text{else high} = \text{mid} - 1 else high=mid−1
最终,如果找到目标值 x x x,返回其索引,否则返回 -1。
时间复杂度:O(log n)。
空间复杂度:O(1),只需常量级的额外空间。
举个栗子:如果你在一本按字母顺序排列的电话簿中查找一个人的名字,你可以从中间开始,根据名字的字母顺序决定向前或向后查找,这就是二分搜索的思想。
代码示例:
def binary_search(arr, target):
low, high = 0, len(arr) - 1
while low <= high:
mid = (low + high) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
low = mid + 1
else:
high = mid - 1
return -1
2.3 深度优先搜索(Depth-First Search, DFS)
深度优先搜索(DFS)是一种用于图或树结构的搜索算法。它从一个节点出发,沿着一条路径深入搜索,直到找到目标或到达叶子节点(无子节点的节点),然后回溯并尝试其他路径。
数学意义:
- DFS的递归过程可以定义为:
DFS ( v ) = Mark v as visited \text{DFS}(v) = \text{Mark } v \text{ as visited} DFS(v)=Mark v as visited
for each u adjacent to v do \text{for each } u \text{ adjacent to } v \text{ do} for each u adjacent to v do
if u is not visited then DFS ( u ) \quad \text{if } u \text{ is not visited then } \text{DFS}(u) if u is not visited then DFS(u)
时间复杂度:O(V + E),其中V是节点数,E是边数。
空间复杂度:O(V),由于递归调用栈的深度可能达到节点总数。
举个栗子:假设你在一个迷宫中行走,你总是沿着一个方向走到尽头,然后再回头寻找其他未走过的路径,这就类似于DFS的策略。
代码示例(使用递归):
def dfs(graph, start, visited=None):
if visited is None:
visited = set()
visited.add(start)
for next_node in graph[start] - visited:
dfs(graph, next_node, visited)
return visited
2.4 广度优先搜索(Breadth-First Search, BFS)
广度优先搜索(BFS)也是一种用于图或树结构的搜索算法。它从一个节点开始,逐层向外扩展搜索,直到找到目标元素。
数学意义:
- BFS的非递归过程通常使用队列实现:
BFS ( v ) = Initialize queue with v \text{BFS}(v) = \text{Initialize queue with } v BFS(v)=Initialize queue with v
while queue is not empty do \text{while queue is not empty do} while queue is not empty do
u = Dequeue \quad u = \text{Dequeue} u=Dequeue
for each w adjacent to u do \quad \text{for each } w \text{ adjacent to } u \text{ do} for each w adjacent to u do
if w is not visited then \quad \quad \text{if } w \text{ is not visited then} if w is not visited then
Mark w as visited and enqueue w \quad \quad \quad \text{Mark } w \text{ as visited and enqueue } w Mark w as visited and enqueue w
时间复杂度:O(V + E)。
空间复杂度:O(V),用于存储队列和访问标记。
举个栗子:如果你从城市的中心开始,逐步向外扩展
搜索,直到找到某个特定地点,这就类似于BFS的策略。
代码示例(使用队列):
from collections import deque
def bfs(graph, start):
visited = set()
queue = deque([start])
while queue:
vertex = queue.popleft()
if vertex not in visited:
visited.add(vertex)
queue.extend(graph[vertex] - visited)
return visited
3. A*算法:启发式搜索的典范
A*算法是一种广泛应用于路径规划的启发式搜索算法。它结合了广度优先搜索和深度优先搜索的优点,通过启发式函数引导搜索过程,以找到从起点到终点的最优路径。
3.1 A*算法的核心思想
A*算法的核心思想是在搜索过程中,同时考虑从起点到当前节点的实际代价
g
(
n
)
g(n)
g(n) 和从当前节点到目标节点的预估代价
h
(
n
)
h(n)
h(n)(即启发式函数)。总代价为:
f
(
n
)
=
g
(
n
)
+
h
(
n
)
f(n) = g(n) + h(n)
f(n)=g(n)+h(n)
算法每次扩展代价最小的节点,直至找到目标节点。
3.2 启发式函数的选择
启发式函数 h ( n ) h(n) h(n) 的选择对A*算法的效率有着至关重要的影响。一个好的启发式函数应当是可接受的,即不会高估从当前节点到目标节点的实际代价,从而保证A*算法找到的是最优解。
常见的启发式函数:
- 曼哈顿距离(用于网格地图):假设只能水平或垂直移动,启发式函数为:
h ( n ) = ∣ x goal − x n ∣ + ∣ y goal − y n ∣ h(n) = |x_{\text{goal}} - x_n| + |y_{\text{goal}} - y_n| h(n)=∣xgoal−xn∣+∣ygoal−yn∣ - 欧几里得距离:假设可以任意方向移动,启发式函数为:
h ( n ) = ( x goal − x n ) 2 + ( y goal − y n ) 2 h(n) = \sqrt{(x_{\text{goal}} - x_n)^2 + (y_{\text{goal}} - y_n)^2} h(n)=(xgoal−xn)2+(ygoal−yn)2
3.3 A*算法的应用场景
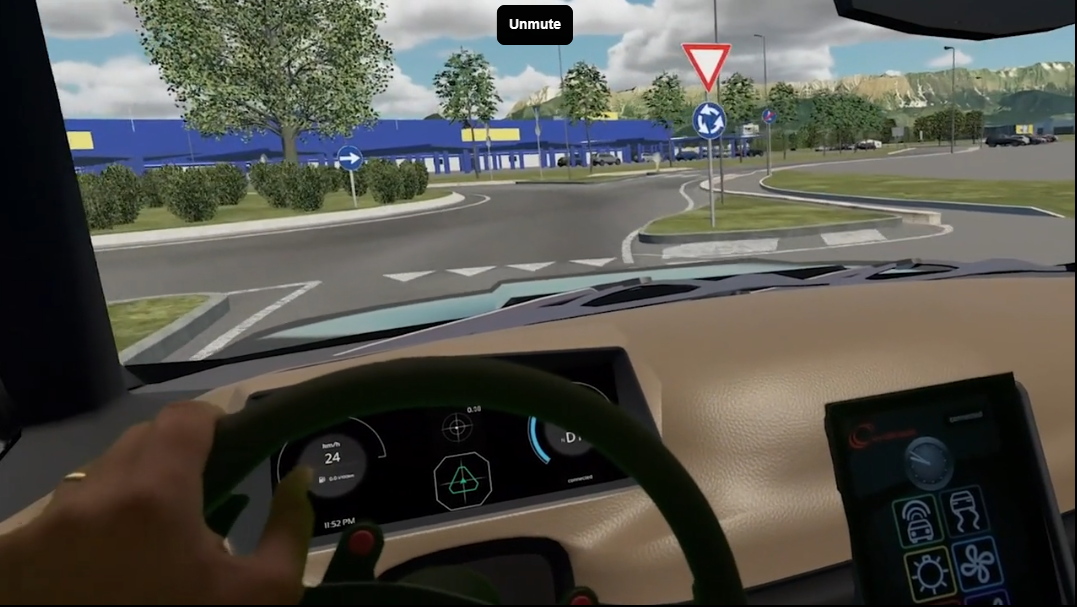
举个栗子:假设你驾驶一辆汽车在城市中导航。A*算法就像GPS导航系统,它不仅考虑你目前的位置(已走过的路),还会根据你距离目的地的直线距离来估算最优路径,从而引导你绕开交通拥堵,以最短时间到达目的地。
- 路径规划:在机器人导航、游戏AI中寻找从起点到目标的最短路径。
- 地图搜索:如Google Maps或GPS导航系统中的路径规划。
代码示例:
from queue import PriorityQueue
def a_star(graph, start, goal, h):
open_set = PriorityQueue()
open_set.put((0, start))
came_from = {}
g_score = {node: float('inf') for node in graph}
g_score[start] = 0
while not open_set.empty():
current = open_set.get()[1]
if current == goal:
path = []
while current in came_from:
path.append(current)
current = came_from[current]
return path[::-1]
for neighbor, cost in graph[current]:
tentative_g_score = g_score[current] + cost
if tentative_g_score < g_score[neighbor]:
came_from[neighbor] = current
g_score[neighbor] = tentative_g_score
f_score = tentative_g_score + h(neighbor, goal)
open_set.put((f_score, neighbor))
return None
4. 其他经典的搜索算法
除了A*算法,还有其他几种经典的搜索算法在不同场景中有着广泛的应用。
4.1 Dijkstra算法
Dijkstra算法是A*算法的前身,主要用于寻找加权图中从单个起点到所有其他节点的最短路径。它类似于A*,但不使用启发式函数,仅基于实际代价 g ( n ) g(n) g(n) 进行搜索。
数学意义:
- 初始化:将起点的代价设为0,其他节点代价为无穷大,将起点放入优先队列。
- 循环:
- 从优先队列中选取代价最小的节点进行扩展。
- 更新其邻居节点的代价,如果邻居节点的代价减少,将其放入优先队列。
- 重复以上过程,直到所有节点都被处理。
时间复杂度:O(V^2) 或 O((V + E) \log V)(使用优先队列优化)。
举个栗子:假设你要找到从你家到城市中所有商店的最短路径,你从家出发,计算到达每个商店的最短距离,并不断更新其他商店的最短路径,这就是Dijkstra算法的工作方式。
应用场景:最短路径搜索,如网络路由、城市交通规划。
代码示例:
from queue import PriorityQueue
def dijkstra(graph, start):
queue = PriorityQueue()
queue.put((0, start))
distances = {vertex: float('infinity') for vertex in graph}
distances[start] = 0
while not queue.empty():
current_distance, current_vertex = queue.get()
if current_distance > distances[current_vertex]:
continue
for neighbor, weight in graph[current_vertex]:
distance = current_distance + weight
if distance < distances[neighbor]:
distances[neighbor] = distance
queue.put((distance, neighbor))
return distances
4.2 Bellman-Ford算法
Bellman-Ford算法用于寻找含负权边的图中的最短路径。它通过反复放松边来更新路径的代价。
数学意义:
- 初始化:将起点的代价设为0,其他节点代价为无穷大。
- 循环
∣
V
∣
−
1
|V|-1
∣V∣−1 次(其中
∣
V
∣
|V|
∣V∣ 是节点数):
- 对图中的每条边
(
u
,
v
)
(u, v)
(u,v) 执行松弛操作:
if g ( v ) > g ( u ) + w ( u , v ) then g ( v ) = g ( u ) + w ( u , v ) \text{if } g(v) > g(u) + w(u, v) \text{ then } g(v) = g(u) + w(u, v) if g(v)>g(u)+w(u,v) then g(v)=g(u)+w(u,v)
- 对图中的每条边
(
u
,
v
)
(u, v)
(u,v) 执行松弛操作:
时间复杂度:O(VE)。
举个栗子:假设你在城市中寻找最便宜的公交路线,你要不断更新不同路线的花费,直到找到最便宜的方案,这就是Bellman-Ford算法的思路。
应用场景:处理图中可能存在负权边的情况,如金融领域的套利检测。
代码示例:
def bellman_ford(graph, start):
distance = {node: float('inf') for node in graph}
distance[start] = 0
for _ in range(len(graph) - 1):
for node in graph:
for neighbor, weight in graph[node]:
if distance[node] + weight < distance[neighbor]:
distance[neighbor] = distance[node] + weight
# Check for negative-weight cycles
for node in graph:
for neighbor, weight in graph[node]:
if distance[node] + weight < distance[neighbor]:
return "Graph contains a negative-weight cycle"
return distance
4.3 Floyd-Warshall算法
Floyd-Warshall算法用于计算加权图中所有节点对之间的最短路径。它是动态规划的一种形式。
数学意义:
- 设定初始状态:
if i = j then d [ i ] [ j ] = 0 \text{if } i = j \text{ then } d[i][j] = 0 if i=j then d[i][j]=0
else if ( i , j ) is an edge then d [ i ] [ j ] = w ( i , j ) \text{else if } (i, j) \text{ is an edge then } d[i][j] = w(i, j) else if (i,j) is an edge then d[i][j]=w(i,j)
else d [ i ] [ j ] = ∞ \text{else } d[i][j] = \infty else d[i][j]=∞ - 对每个中间节点
k
k
k 执行更新操作:
d [ i ] [ j ] = min ( d [ i ] [ j ] , d [ i ] [ k ] + d [ k ] [ j ] ) d[i][j] = \min(d[i][j], d[i][k] + d[k][j]) d[i][j]=min(d[i][j],d[i][k]+d[k][j])
时间复杂度:O(V^3)。
举个栗子:假设你要计算城市中任意两个地点之间的最短路径,你可以通过逐一考虑每个中间点来优化路径,这就是Floyd-Warshall算法的工作方式。
应用场景:适用于计算全图的最短路径矩阵,如网络分析、交通网络优化。
代码示例:
def floyd_warshall(graph):
distance = {i: {j: float('inf') for j in graph} for i in graph}
for node in graph:
distance[node][node] = 0
for neighbor, weight in graph[node]:
distance[node][neighbor] = weight
for k in graph:
for i in graph:
for j in graph:
distance[i][j] = min(distance[i][j], distance[i][k] + distance[k][j])
return distance
5. 算法比较与选择
在实际应用中,选择合适的搜索算法至关重要。下表对比了不同算法的优缺点及适用场景。
| 算法 | 时间复杂度 | 空间复杂度 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| 线性搜索 | O(n) | O(1) | 简单易实现 | 效率低,适用于小规模数据 | 无序数据的小规模查找 |
| 二分搜索 | O(log n) | O(1) | 高效 | 仅适用于有序数据 | 有序数组或列表查找 |
| 深度优先搜索 | O(V + E) | O(V) | 遍历完整图,内存占用少 | 可能陷入死循环或路径过长 | 树或图的深度遍历 |
| 广度优先搜索 | O(V + E) | O(V) | 找到最短路径 | 内存占用大,效率较低 | 树或图的广度遍历 |
| Dijkstra算法 | O(V^2) 或 O((V + E) \log V) | O(V) | 找到最短路径 | 不能处理负权边 | 图中最短路径搜索 |
| Bellman-Ford算法 | O(VE) | O(V) | 处理负权边 | 效率较低 | 含负权边的图中最短路径搜索 |
| A*算法 | O(E) | O(V) | 效率高,找到最优路径 | 启发式函数选择影响效果 | 路径规划,游戏AI |
| Floyd-Warshall算法 | O(V^3) | O(V^2) | 计算全图所有节点对的最短路径 | 内存占用大,适用规模有限 | 全图最短路径分析 |



![[vue] pdf.js / vue-pdf 文件花屏问题](https://i-blog.csdnimg.cn/direct/9ee4cec22138473a88801c212fce7e4d.png)