文章汇总
动机

图像的重复消化有助于提高分类精度。ProMPT不是直接进行预测,而是多次重新访问原始图像以检查答案,逐步将预测从粗糙细化到精确。
希望达到的效果如下:

图7:通过迭代进化,ProMPT逐步将CLIP产生的错误结果纠正为正确的结果。
✓
\checkmark
✓表示正确和×表示不正确的预测。
解决办法
可以从中看到每一次的迭代都会从会参考上一层的的特征。
第0次迭代
简单的一个多模态的架构
对过滤器
F
\mathcal{F}
F的描述

x
n
x^n
xn是视觉特征
Z
n
Z^n
Zn文本信息是基于标签集
Z
0
=
{
z
k
0
}
k
=
1
K
Z^0=\{z^0_k\}^K_{k=1}
Z0={zk0}k=1K的文本表示。比如,
z
1
0
z^0_1
z10:a photo of cat;
z
2
0
z^0_2
z20:a photo of dog;
多模态迭代进化(MIE)
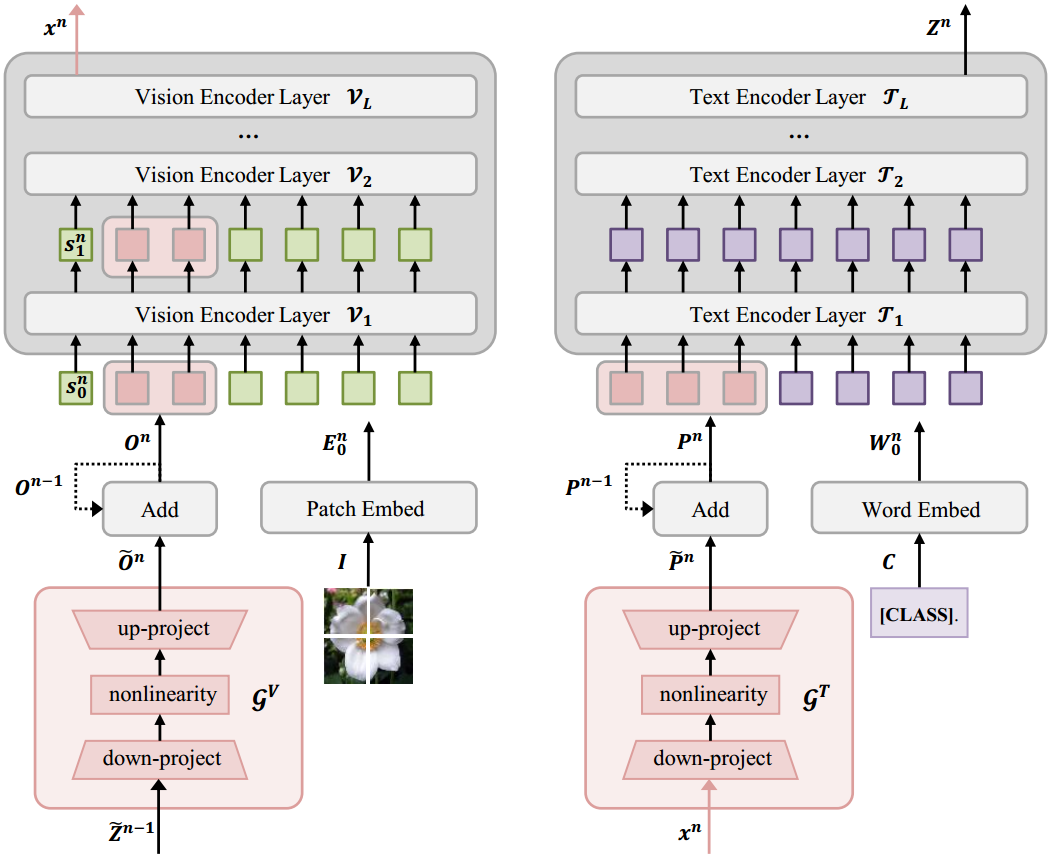
G
V
,
G
T
\mathcal{G}^V,\mathcal{G}^T
GV,GT就是一个mlp,用来调整维度的。
主要关注一个关键的地方即可。Add模块,他保留的上一层的视觉/文本特征prompt
p
n
−
1
p^{n-1}
pn−1,之后再与当前层的prompt
p
n
p^{n}
pn进行相加以实现动机中“反复消化图片”的效果。(个人感觉做得还是有点粗糙,应该能有改进的地方)
训练目标
正常的损
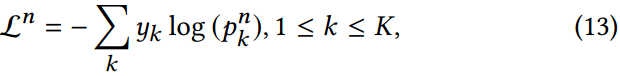
最终的损失是累加每一次(总共
N
N
N次)迭代的损失,其中
λ
\lambda
λ是不变的超参数

L
n
\mathcal{L}^n
Ln的聚合有助于引导模型在每次迭代中进行准确的预测,从而逐步促进多模态学习。
摘要
预训练的视觉语言模型(VLMs)通过提示显示出显著的泛化能力,它利用VLMs作为知识库来提取对下游任务有益的信息。然而,现有方法主要采用单模态提示,仅涉及单模态分支,无法同时调整视觉语言(V-L)特征。此外,VLM编码中的一遍前向管道难以对齐有巨大差距的V-L特性。面对这些挑战,我们提出了一种新的方法——渐进式多模态条件提示微调(Prompt)。ProMPT利用循环结构,通过迭代利用图像和当前编码信息来优化和对齐V-L特征。它包括一个初始化模块和一个多模态迭代演化模块。初始化负责使用VLM对图像和文本进行编码,然后使用特征过滤器选择与图像相似的文本特征。然后,MIE通过类条件视觉提示、实例条件文本提示和特征过滤来促进多模态提示。在每次MIE迭代中,通过视觉生成器从过滤后的文本特征中获得视觉提示,在视觉提示过程中促进图像特征更多地关注目标物体。编码的图像特征被输入到文本生成器中,以生成对类别转换更健壮的文本提示。因此,V-L特征逐渐对齐,从而实现从粗糙到精确的预测。在三种环境下进行了大量的实验来评估ProMPT的功效。结果表明,ProMPT在所有设置下的平均性能都优于现有方法,证明了其优越的泛化和鲁棒性。代码可从https://github.com/qiuxiaoyu9954/ProMPT获得。
1.介绍
近年来,预训练视觉语言模型(VLMs)的出现,如CLIP[38]和ALIGN[19],标志着计算机视觉(CV)领域的重大飞跃,特别是在下游任务的泛化方面。vlm在大规模对齐的文本-图像对上进行训练,使它们能够在预训练期间从自然语言中学习开放集视觉概念。
该方法显著提高了它们的zero-shot泛化能力。一个典型的视觉语言模型架构由一个文本编码器和一个图像编码器组成。在推理过程中,手工制作的模板提示符与所有类别输入相结合,通过文本编码器生成文本特征。然后将这些特征与图像编码器提取的图像特征进行比较,以计算相似度,从而确定预测的类别。
虽然vlm在泛化到新类方面表现出令人印象深刻的性能,但在为下游任务对它们进行微调时,会出现重大挑战。首先,整个模型的微调需要大量的数据,因为数据不足会导致过拟合。其次,微调大规模模型需要大量的计算资源,并且有可能灾难性地忘记先前获得的知识。针对上述问题,广泛的研究[21,38,52,53]强调了快速学习是一种有效的范例。它起源于自然语言处理(NLP)领域[27,28,37,42],包括硬提示和软提示。硬提示是人工制作的句子模板,旨在重组输入,使其类似于预训练中的格式。然而,设计模板需要仔细的验证和密集的劳动,因为微小的措辞变化会显著影响性能[53]。最近,一系列研究[23,43,49,54]探索了vlm的软提示。具体来说,软提示是一种可学习的向量,它被注入到模型中,以激发对下游任务有益的信息。一个代表性方法是CoOp[53],它以端到端方式训练可学习的参数,同时保持整个预训练参数的固定。
考虑到上述研究,我们总结了以下几点考虑。首先,依赖vlm的图像分类是一项多模态任务,它与V-L模态之间存在显著的领域差距,以及数据采集和注释方面的挑战。现有的方法通常使用一遍转发管道,其中文本和图像编码器分别处理输入文本和图像一次。预测是通过V-L特征之间的相似性来推断的。然而,由于图像和文本之间的巨大差距,有效地对齐它们的特征是非常重要的。其次,现有的vlm提示方法主要集中在适应语言分支,而视觉分支不变。由于vlm的主要目标是协调V-L分支中的嵌入,单个文本提示可能会阻碍对两个分支中输出嵌入之间的相关性进行建模,从而导致次优解。针对这些问题,我们提出了一种简单而有效的渐进多模态条件提示调谐(Prompt)方法。
图1:我们提出的方法的说明。ProMPT逐步细化分类置信度,通过迭代网络处理从“猫”到“狗”进行纠错。
ProMPT从Feng等人[10,11]的工作中获得灵感,发现在人类识别图像的过程中,图像是可以被重复和深刻理解的。**图像的重复消化有助于提高分类精度。ProMPT不是直接进行预测,而是多次重新访问原始图像以检查答案,逐步将预测从粗糙细化到精确。**在图1中,当将图像输入到我们的网络中进行分类时,正确类别的置信度随着每次迭代而逐步提高。这个过程使预测从最初错误的“猫”到最终正确的“狗”得到纠正。
具体来说,我们实现了一个循环架构,该架构采用迭代进化策略来对齐V-L特征以进行准确的预测。ProMPT包括两个主要模块:初始化模块和多模态迭代演化(MIE)模块。在初始化中,对于给定的图像,我们利用原始CLIP对文本和图像进行编码,生成V-L特征。然后计算余弦相似度以选择top-𝑎类别的文本特征,作为MIE的初始输入。然后,通过MIE逐步更新V-L特征,包含三个步骤:类条件视觉提示、实例条件文本提示和特征过滤。一方面,为了使视觉编码更专注于相关的目标对象,视觉提示通过视觉生成器从顶部的𝑎文本特征中派生出来。另一方面,受cooop[52]的启发,我们通过文本生成器将图像特征转换为实例条件文本提示,以促进泛化。特征过滤旨在选择与图像最相关的top-𝑎文本特征。与大多数单模态方法不同,我们在两个V-L分支中引入提示,以促进V-L特性的对齐。在整个迭代过程中,视觉和文本提示被不断优化,激发了vlm的有用知识,并促进了V-L特征的更好对齐。提示演变的结果,从粗略到准确的预测。
为了评估我们提出的ProMPT的有效性,我们进行了三种代表性设置的综合实验:从基础到新类别的泛化,跨数据集评估和领域泛化。实验结果表明,该方法优于已建立的基线。值得注意的是,在从基本类到新类的泛化设置中,我们的方法在11个数据集中的10个超过了基准CoCoOp[52],在新类中实现了3.2%的绝对性能提高,在谐波平均(HM)中实现了1.97%的绝对性能提高。此外,在跨数据集评估和领域泛化设置中,ProMPT表现出有效的泛化性和鲁棒性,具有最佳的平均精度。
2.相关工作
在本节中,我们提供了相关工作的概述,重点是视觉语言模型和提示学习。
视觉语言模型
最近,CV领域见证了vlm的出现和越来越多的应用,如CLIP [38], ALIGN[19]和Florence[50],特别是在few-shot或zero-shot学习场景中。视觉语言模型是在基于对比学习的网络海量噪声图像文本对的语料库上进行训练的,方法是将匹配的图像文本对的表示拉近,而将不匹配的图像文本对的表示推远,以学习对齐的视觉语言表示。在自然语言的监督下,vlm在广泛的下游任务中表现出令人印象深刻的功效。然而,尽管它们具有学习广义表示的能力,但直接应用于特定的下游任务通常会导致显著的性能下降,这构成了实质性的挑战。大量研究表明,通过为下游任务(如视觉识别[12,51 - 53]、视频理解[1,8,22,29,55]和目标检测[7,13,41])定制方法来定制vlm,可以提高性能。在这项工作中,我们提出了视觉语言模型的渐进式多模态条件提示调优,以促进小样本设置下的图像分类任务。
提示学习
提示学习起源于NLP领域,一般分为硬提示和软提示。硬提示[21,25,34,37,46]是指手工制作的句子模板。通过在模板中插入输入句子,预训练模型模仿下游任务中的预训练形式,从而更好地引出模型所学到的知识。此外,一系列作品将可学习向量作为伪令牌注入模型的输入层或隐藏层,参与Transformer的注意力计算,称为软提示[14,27,28,30,31]。这些可以更有效地从预训练的模型中提取对下游任务有用的信息。鉴于NLP中提示学习的突出优势,许多方法[2,26,32,39,54]已被用于视觉和视觉语言领域,其中的预训练模型原始参数保持不变,并且只更新一些额外的可学习提示参数。VPT[20]通过在输入空间中加入一些可训练的参数,同时保持模型主干冻结,实现了显著的性能提升。CoOp[53]通过将单词模板建模为语言分支中的可学习向量,将类clip的vlm用于下游图像识别任务。CoCoOp[52]进一步发展了CoOp[53],为每张图像引入了输入条件提示,从而增强了CoOp的泛化能力。TPT[43]通过单个测试样本动态学习自适应提示。DetPro[7]学习基于VLMs的开放词汇目标检测的软提示表示。上述方法主要涉及视觉或语言分支的单模态提示,限制了vlm只能在单一模态上进行优化,而忽略了多模态特征交互。相反,我们在两个V-L分支中同时引入了可优化的软提示,旨在促进V-L表示之间的对齐。
3.方法
在本节中,我们通过审查预训练CLIP的架构开始。在此之后,我们简要概述了所提出的方法ProMPT的总体框架。随后,我们详细介绍了ProMPT的两个主要组成模块,即初始化和多模态迭代进化(MIE)。最后,详细介绍了为ProMPT量身定制的培训目标设计。
3.1 CLIP回顾
我们的模型是在预训练CLIP的基础上构建的,它由一个文本编码器和一个图像编码器组成。文本编码器采用Transformer[45]将文本编码为矢量化表示,而图像编码器则基于视觉转换器(vision Transformer, ViT)[6]或ResNet[15]将图像处理为特征向量。在预训练过程中,Radford等[38]收集了大量的图像-文本对,对CLIP进行对比学习,使CLIP能够学习联合的V-L表示。因此,CLIP擅长于执行零射击视觉识别任务,其参数完全冻结。遵循现有方法[52,53],我们的工作采用了基于viti的CLIP模型。我们将在下面详细介绍视觉和文本输入的编码过程。
编码图像 图像编码器
V
V
V包括
L
L
L层transformer
{
V
L
}
l
=
1
L
\{V_L\}^L_{l=1}
{VL}l=1L首先将图像
I
I
I嵌入到隐嵌入
E
0
∈
R
M
a
×
d
v
E_0\in R^{M_a\times d_v}
E0∈RMa×dv中。将图像编码器中一个可学习的类令牌
s
l
∈
R
d
v
s_l\in R^{d_v}
sl∈Rdv与
E
l
−
1
E_{l-1}
El−1一起依次送入
V
l
V_l
Vl得到
E
l
E_l
El。

为了得到最终的图像表示符,图像投影层
P
I
\mathcal{P}_I
PI将
s
L
s_L
sL从
V
L
V_L
VL变换为共享的V-L潜嵌入空间,

编码的文本 给定输入文本,具有
L
L
Ltransformer层的文本编码器
{
τ
l
}
l
=
1
L
\{\tau_l\}^L_{l=1}
{τl}l=1L将其标记并嵌入到单词嵌入
W
0
=
[
w
0
,
1
,
w
0
,
2
,
.
.
.
,
w
0
,
M
b
]
W_0=[w_{0,1},w_{0,2},...,w_{0,M_b}]
W0=[w0,1,w0,2,...,w0,Mb]。每层嵌入
W
l
−
1
W_{l-1}
Wl−1输入第
i
i
itransformer层
τ
l
\tau_l
τl如下:

以类似于图像分支的方式,文本
z
z
z表示通过文本投影层从最后一个转换层的最后一个令牌
w
L
,
M
b
w_{L,M_b}
wL,Mb中得到,在相同的嵌入空间中
x
x
x,

zero-shot推理。在zero-shot推理过程中,文本输入由手工制作的提示组成(例如,’ A photo of A [CLASS] '),其中[CLASS]被替换为标签的类名。第
k
k
k类的分数通过计算文本编码器和图像编码器输出之间的余弦相似度来量化。本计算采用相似度函数sim(),温度参数为,表示为:

3.2 框架概述
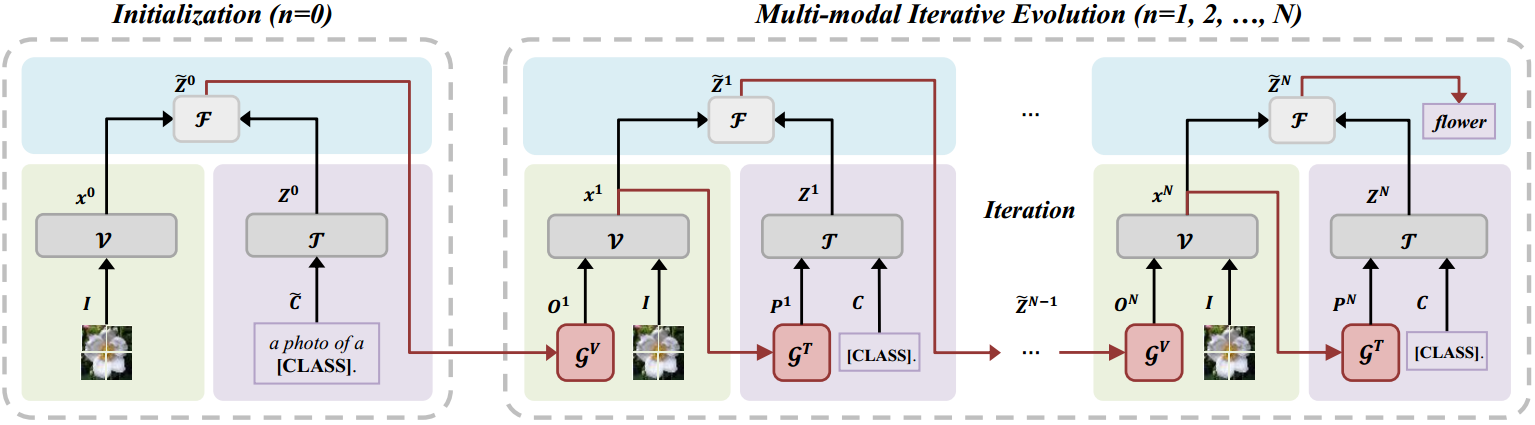
图2:采用迭代策略的ProMPT框架概述。它包括一个初始化和一个多模态迭代进化(MIE)模块,旨在逐步将预测从粗糙细化到精确。初始化包含CLIP并引入一个特征过滤器来选择最接近图像特征的top-𝑎文本特征。MIE的每次迭代都涉及类条件视觉提示、实例条件文本提示和特征过滤。将top-𝑎特征输入到视觉生成器中产生视觉提示,再将编码后的图像特征输入到文本生成器中得到文本提示。总的来说,ProMPT是通过最小化MIE分类的累积CE损失来优化的。
为了有效地将vlm转移到图像分类任务中,我们探索了多模态提示的性能,这是对大多数现有单模态提示方法的一种改进。以前的方法[52,53],在语言分支中引入可学习的提示,单独调整该分支的文本编码。然而,我们假设仅限制文本编码器的提示是次优的。为了更好地调整V-L特性,我们提倡多模态提示调优。受VPT[20]的启发,我们的方法将可学习的软提示集成到CLIP中的ViT的深层中。图2显示了我们提议的ProMPT(渐进式多模态条件提示调优)框架的整体架构。在视觉分支中,视觉提示由与图像最相关的文本特征生成,鼓励图像特征更多地集中在图像中的目标对象上。同时,在语言分支中,我们应用图像特征来生成语言提示符。Zhou等人[52]已经证明这些动态提示可以提高概括性。
此外,我们模仿人类识别图像的过程,其中图像可以反复分析,直到实现准确的识别。具体来说,我们将ProMPT划分为两个主要阶段:初始化
(
n
=
0
)
(n=0)
(n=0)和多模态迭代进化
(
n
=
1
,
.
.
.
,
N
)
(n=1,...,N)
(n=1,...,N),其中
n
n
n表示迭代次数。该策略旨在在每次迭代中逐步优化更相关的提示,促进V-L特征的对齐。
3.3 初始化
对于具有图像
I
I
I和一组标签
C
=
{
c
k
}
k
=
1
K
C=\{c_k\}^K_{k=1}
C={ck}k=1K的图像分类任务,初始化阶段利用CLIP的原始结构对输入的图像和文本进行编码。
ViT
V
V
V将
I
I
I分割成
M
a
M_a
Ma固定大小的patch,这些patch投影到patch embedding中
E
0
0
∈
R
M
a
×
d
v
E^0_0\in R^{M_a\times d_v}
E00∈RMa×dv。除另有说明外,公式中的上标一致表示迭代次数。随后,初始化过程中图像编码的过程如下,类似于式1、式2:

在语言分支中,将设置的变量填写到模板提示符中,生成的变量为
C
~
=
{
a photo of a
c
k
}
k
=
1
K
\tilde{C}=\{\text{a photo of a }c_k\}^K_{k=1}
C~={a photo of a ck}k=1K。每个类别
c
~
k
\tilde c_k
c~k是嵌入到标记并嵌入
W
~
0
0
=
[
P
0
,
w
0
0
]
∈
R
(
M
b
)
×
d
l
\tilde{W}^0_0=[P_0,w^0_0]\in R^{(M_b)\times d_l}
W~00=[P0,w00]∈R(Mb)×dl,其中
P
0
∈
R
b
×
d
l
P_0\in R^{b\times d_l}
P0∈Rb×dl的映射进行手工模板a photo of a和
W
0
0
=
[
w
0
,
1
0
,
.
.
.
,
w
0
,
(
M
b
−
b
)
0
]
W^0_0=[w^0_{0,1},...,w^0_{0,(M_b-b)}]
W00=[w0,10,...,w0,(Mb−b)0]代表类别的嵌入
c
k
c_k
ck。在此步骤之后,对每一层
τ
\tau
τ进行
W
~
0
0
\tilde{W}^0_0
W~00编码,得到最后一层
τ
L
\tau_L
τL的
W
~
L
0
\tilde W^0_L
W~L0。在
W
~
L
0
\tilde W^0_L
W~L0的最后一个位置上的特征
w
L
,
(
M
b
−
b
)
0
w^0_{L,(M_b-b)}
wL,(Mb−b)0通过文本投影层
P
T
\mathcal{P}_T
PT映射为文本表示的情况下的文本表示。
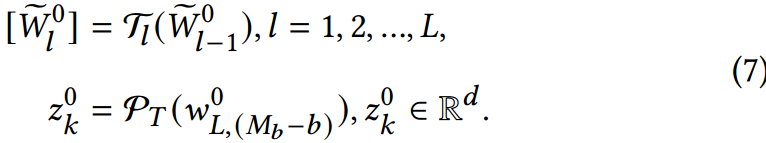
值得注意的是,我们结合了一个特征过滤器
F
\mathcal{F}
F来提取有价值的文本信息,该文本信息是基于标签集
Z
0
=
{
z
k
0
}
k
=
1
K
Z^0=\{z^0_k\}^K_{k=1}
Z0={zk0}k=1K的文本表示。如图3所示,我们首先计算预测概率
{
p
1
0
,
p
2
0
,
.
.
.
,
p
K
0
}
\{p^0_1,p^0_2,...,p^0_K\}
{p10,p20,...,pK0}根据式5的所有类。然后,文本特征
Z
~
0
\tilde Z^0
Z~0对应于最上面的𝑎最高概率值被选择。稍后,在MIE期间使用
Z
~
0
\tilde Z^0
Z~0生成条件提示
图3:特征过滤器
F
\mathcal{F}
F的实现过程。在第
n
n
n轮迭代中,特征过滤器以图像特征
x
n
x^n
xn和文本特征
Z
n
Z^n
Zn作为输入,计算它们的余弦相似度,并根据相似度选择最前面的
a
a
a文本特征
W
~
L
0
\tilde W^0_L
W~L0。然后
Z
~
n
\tilde Z^n
Z~n作为第
(
n
+
1
)
(n+1)
(n+1)次迭代的输入。
3.4 多模态迭代进化(MIE)
CLIP在各种任务中显示出显著的有效性,特别是在zero-shot的情况下。因此,我们在初始化中得到的
a
a
a类别
Z
~
0
\tilde Z^0
Z~0的特征是近似有效的。我们将
Z
~
0
\tilde Z^0
Z~0和图像
I
I
I一起输入到多模态迭代进化(MIE)模块中,该模块旨在保持和增强图像和文本特征之间的对齐。这样,初始化时的V-L特征最终收敛到精确对齐状态。MIE包含三个子过程:类条件视觉提示、实例条件文本提示和特征过滤,每个子过程都有助于特征对齐的迭代细化。
图4:第n个迭代的类条件视觉提示和实例条件文本提示。
类条件视觉提示。为了迫使图像特征在编码过程中更多地关注与类别相关的信息,我们实现了类别条件视觉提示。如图4的左侧所示,我们在第
n
n
n迭代中引入提示符
{
O
j
n
∈
R
a
×
d
v
}
j
=
1
J
\{O_j^n\in R^{a\times d_v}\}^J_{j=1}
{Ojn∈Ra×dv}j=1J直到特定深度
J
J
J。具体来说,我们设计了一组视觉生成器
G
V
=
{
G
j
V
}
j
=
1
J
\mathcal{G}^V=\{\mathcal{G}^V_j\}^J_{j=1}
GV={GjV}j=1J,将
Z
~
n
−
1
\tilde Z^{n-1}
Z~n−1映射为相应的视觉提示
O
j
n
O^n_j
Ojn,以便在
V
j
\mathcal{V}_j
Vj中应用。此外,插入Add模块,充分集成和融合第
n
−
1
n-1
n−1迭代过程的类条件视觉提示。

其中
G
j
V
\mathcal{G}^V_j
GjV通过一个两层MLP (Linear-ReLU-Linear)实现,负责将文本特征映射到图像嵌入空间。量纲变换过程表示为
d
→
d
16
→
d
v
d \rightarrow \frac{d}{16} \rightarrow d_v
d→16d→dv。考虑到构建
J
J
J单独的
G
j
V
\mathcal{G}^V_j
GjV会大大增加训练参数,我们在
G
V
\mathcal{G}^V
GV上共享权矩阵并设置特定层的偏置项,目的是平衡训练参数和模型性能。
形式上,输入嵌入表示为
[
s
0
n
,
O
0
n
,
E
0
n
]
[s^n_0,O^n_0,E^n_0]
[s0n,O0n,E0n]。在图像编码器的相应层中进一步注入其他视觉提示符,参与自注意计算,最终的图像
x
n
x^n
xn表示形式为:
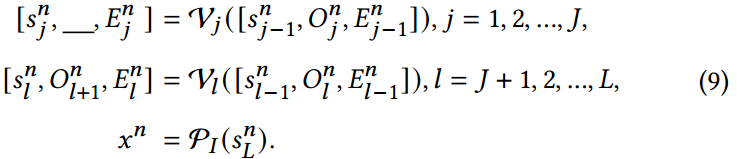
实例条件文本提示。受CoCoOp[52]的启发,我们应用图像分支中的特征符
x
n
x^n
xn生成实例条件文本提示通过文本生成器
G
T
=
{
G
r
T
}
r
=
1
R
\mathcal{G}^T=\{\mathcal{G}^T_r\}^R_{r=1}
GT={GrT}r=1R。如图4右侧所示,
G
r
T
\mathcal{G}^T_r
GrT的体系结构与
G
j
V
\mathcal{G}^V_j
GjV的体系结构相同。相反,我们使用一个生成器在输入层
τ
1
\tau_1
τ1创建插入文本提示,从而设置
R
=
1
R=1
R=1。量纲变换的具体过程如下
d
→
d
16
→
d
l
d \rightarrow \frac{d}{16} \rightarrow d_l
d→16d→dl。通过添加操作,图像特征
x
n
x^n
xn经过
G
T
\mathcal{G}^T
GT,得到文本提示
p
0
n
∈
R
b
×
d
l
p^n_0\in R^{b\times d_l}
p0n∈Rb×dl;

获得文本提示后,将它们与
W
0
n
W^n_0
W0n连接起来,然后依次输入
τ
l
\tau_l
τl,以便在第
n
n
n迭代期间计算标签集
Z
n
=
{
z
k
n
}
k
=
1
K
Z^n=\{z^n_k\}^K_{k=1}
Zn={zkn}k=1K的文本特征。
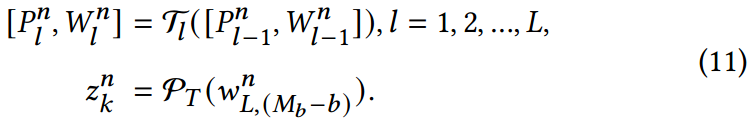
特征过滤。
与初始化类似,MIE的特征过滤如图3所示,根据预测概率
{
p
1
n
,
p
2
n
,
.
.
.
,
p
K
n
}
\{p_1^n,p^n_2,...,p^n_K\}
{p1n,p2n,...,pKn},与式5类似。随后,这些过滤的特征
Z
~
n
\tilde Z^n
Z~n被用作下一个迭代过程的输入,继续进化的循环。

3.5. 训练目标
为了优化ProMPT,我们采用了一个交叉熵损失函数,目的是在由式12推导出的第
n
n
n迭代过程中,最小化ground-truth标签与预测概率之间的距离。
其中,
y
k
y_k
yk表示ground-truth标签的one-hot向量。在整个训练阶段,先进的提示保持CLIP的整个参数固定,同时从事提示符和生成器的优化。为此,我们对MIE中所有迭代的输出应用
L
n
\mathcal{L}^n
Ln,不包括初始化。综上所述,我们模型的最终损失函数为:
其中,对于调节每个迭代进化的重要性,
λ
\lambda
λ作为一个恒定的加权因子。
L
n
\mathcal{L}^n
Ln的聚合有助于引导模型在每次迭代中进行准确的预测,从而逐步促进多模态学习。
4.实验



图6:ProMPT促进了预测的细化,从最初的粗糙到精确和准确的分类。符号“✔”代表正确的分类。
图7:通过迭代进化,ProMPT逐步将CLIP产生的错误结果纠正为正确的结果。分别表示正确和不正确的预测。
5.结论
在这项工作中,我们为VLMs在图像分类中引入了一种名为渐进式多模态条件提示调谐(Prompt)的创新框架。为了有效地细化和对齐图像和文本表示,ProMPT使用了一个循环架构来利用原始图像和当前编码信息。此外,所提出的多模态条件提示调整不仅可以生成与类别相关的视觉提示,使图像特征更集中于目标类别,而且还可以产生更适合类别转换的鲁棒文本提示。这样,通过多模态迭代进化策略,分类结果由粗到精逐步收敛。在三个代表性设置上的大量实验结果表明了我们提出的方法的有效性,与具有大边际的基线相比,显示出更好的泛化和鲁棒性。
参考资料
论文下载(ICMR 2024 Oral)
https://arxiv.org/abs/2404.11864

代码地址(未开源)
https://github.com/qiuxiaoyu9954/ProMPT