任务讲解
此次的任务和一般以模型为中心的任务不同,是以数据为核心的。要求在官方给定的数据集的基础上进行数据清洗和数据合成,生成更为优质的数据集,以提高多模态模型的性能。(此次的模型以图文能力为主)
我们将会对给定的数据集进行 data-juicer 的处理,data-juicer相当于是一个数据集的处理管线,它可以帮我们用各类定制化的算子实现的pipeline来对我们的数据集进行多样组合的处理,同时我们也可以用 data-juicer 复现很多无论是传统多模态、大语言模型还是视频理解相关模型的数据处理工作;在处理工作结束后,我们将会使用 MGM 增强框架来对多模态模型进行微调。
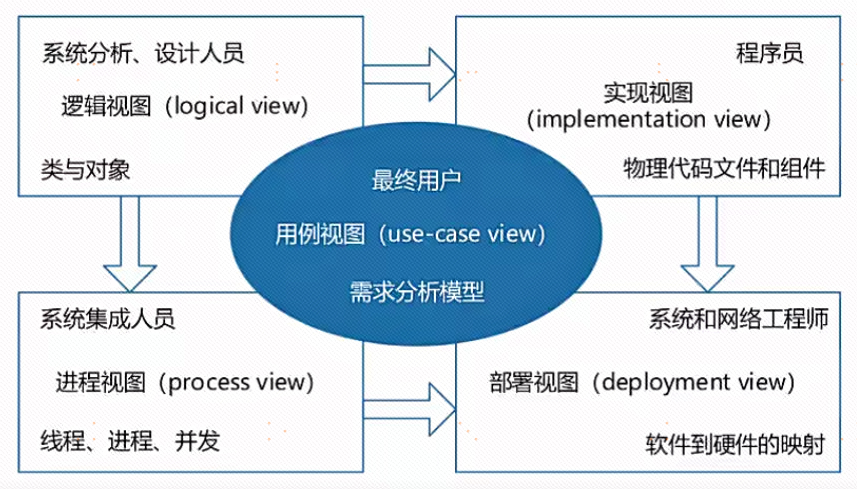
多模态模型有两个关键组件,一是视觉编码器,二是语言模型,其中我们将会使用 gemma 作为我们的语言模型基座,gemma-2B 是谷歌开源的强大人工智能模型,参数量只有2B;而对于视觉编码器我们将会使用使用 CLIP-L (clip-vit-large-patch14-336)。这两个模型我们也可以在微调代码中可以完全看见全流程。
所以,我们需要做的事情是尽量找到合适的方式组织数据集,通过算子的排列组合演奏出美妙的数据奏曲;不过 data-juicer 的算子还是比较多的,之后我们会对他的细节进行详细学习。
Baseline详解
具体的代码大家可以去链接里找到,Datawhale提供了非常详尽的教程。
Datawhale (linklearner.com)
在此只是大概回顾一下整个baseline的流程。
环境准备
SCRIPT_DIR=$(cd "$(dirname "$0")" && pwd)
# for data-juicer
echo "[1] Installing toolkit/data-juicer"
cd ${SCRIPT_DIR}/toolkit
git clone https://github.com/modelscope/data-juicer.git
cd data-juicer
pip install ".[all]"
# for MGM training
echo "[2] Installing toolkit/training"
cd ${SCRIPT_DIR}/toolkit/training
pip install -e .
pip install flash-attn --no-build-isolation
echo "Done"这个部分就是最基础的环境准备。
下载数据集
SCRIPT_DIR=$(cd "$(dirname "$0")" && pwd)
# for base models
echo "[1] Downloading base models for training..."
mkdir -p ${SCRIPT_DIR}/toolkit/training/model_zoo/LLM/gemma
cd ${SCRIPT_DIR}/toolkit/training/model_zoo/LLM/gemma
axel -n 5 http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/models/gemma-2b-it.tar.gz
tar zxvf gemma-2b-it.tar.gz
mkdir -p ${SCRIPT_DIR}/toolkit/training/model_zoo/OpenAI
cd ${SCRIPT_DIR}/toolkit/training/model_zoo/OpenAI
axel -n 5 http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/models/clip-vit-large-patch14-336.tar.gz
tar zxvf clip-vit-large-patch14-336.tar.gz
axel -n 5 http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/models/openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup.tar.gz
tar zxvf openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup.tar.gz
# for training data
echo "[2] Downloading seed datasets..."
mkdir -p ${SCRIPT_DIR}/input
cd ${SCRIPT_DIR}/input
axel -n 5 http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/data/stage_1/pretrain_stage_1_10k.tar.gz
tar zxvf pretrain_stage_1_10k.tar.gz
cd pretrain_stage_1_10k
axel -n 5 http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/data/stage_1/mgm_pretrain_stage_1_10k.jsonl
axel -n 5 http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/data/stage_1/stage_1.json
echo "[3] Downloading finetuning datasets..."
mkdir -p ${SCRIPT_DIR}/toolkit/training/data
cd ${SCRIPT_DIR}/toolkit/training/data
axel -n 5 http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/data/stage_1/finetuning_stage_1_12k.tar.gz
tar zxvf finetuning_stage_1_12k.tar.gz
cd finetuning_stage_1_12k
axel -n 5 http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/data/stage_1/mgm_instruction_stage_1_12k.json
# for eval data
echo "[4] Downloading evaluation datasets"
mkdir -p ${SCRIPT_DIR}/toolkit/training/data
cd ${SCRIPT_DIR}/toolkit/training/data
axel -n 5 http://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/dj-competition/better_synth/data/stage_1/eval_stage_1.tar.gz
tar zxvf eval_stage_1.tar.gz
echo "Done"这里我们下载得到用于训练、评测模型的数据,同时解释一下axel:一个linux用于加速下载的轻量级工具。
数据处理
Image Caption任务结合了计算机视觉和自然语言处理,目标是让AI理解图像并自动生成描述。
我们选择BLIP作为多模态caption算子,Data-juicer调用该算子来进行图片对应文字字幕的获取。
(BLIP 是 2022 年的 caption 工作,发表在 ICML-2022,在多模态大模型还没有横空出世的时候,BLIP就是那个时代的caption小王子(当然现在已经是老王子了);对我们来说 BLIP 以他免费、免费、免费、且参数量小的优势为我们所称道)
首先需要下载BLP模型:
### 下载BLIP模型,大概需要20分钟
from modelscope import snapshot_download
model_dir = snapshot_download('goldsj/blip2-opt-2.7b',
cache_dir='/root/autodl-tmp/better_synth_challenge_baseline/models',
revision='master')
dataset_path: input/pretrain_stage_1_10k/mgm_pretrain_stage_1_10k.jsonl
export_path: output/image_captioning_output/res_10k.jsonl
np: 1
process:
- image_captioning_mapper:
hf_img2seq: '/root/autodl-tmp/better_synth_baseline_autoDL/models/goldsj/blip2-opt-2___7b' # You can replace this path to a local downloaded HF model
keep_original_sample: false # we only need the recaptioned captions
训练
主要是分为pretrain和finetune环节。
首先是有关显卡的相关配置,这里强烈建议大家对照教程认真设置。
#!/bin/bash
############################################################################
########################### Editable Part Begins ###########################
############################################################################
# exp meta information
EXP_NAME=default
PRETRAIN_DATASET=../output/image_captioning_output/res_10k.jsonl
PRETRAIN_DATASET_IMAGE_PATH=../input/pretrain_stage_1_10k
# training args
# pretraining
# make sure PRETRAIN_BATCH_SIZE_PER_GPU * PRETRAIN_GRADIENT_ACCUMULATION_STEPS * num_gpus = 256
# **NOTICE**: the default setting is for 1 GPU
PRETRAIN_BATCH_SIZE_PER_GPU=2
PRETRAIN_GRADIENT_ACCUMULATION_STEPS=128
PRETRAIN_DATALOADER_NUM_WORKERS=4
# finetuning
# make sure FINETUNE_BATCH_SIZE_PER_GPU * FINETUNE_GRADIENT_ACCUMULATION_STEPS * num_gpus = 128
# **NOTICE**: the default setting is for 1 GPU
FINETUNE_BATCH_SIZE_PER_GPU=2
FINETUNE_GRADIENT_ACCUMULATION_STEPS=64
FINETUNE_DATALOADER_NUM_WORKERS=4
# log and ckpt
LOGGING_STEP=1
CKPT_SAVE_STEPS=100
TOTAL_SAVE_CKPT_LIMIT=1
# inference args
# inference for some benchmarks supports multi-gpus
INFER_CUDA_IDX="0"
############################################################################
############################ Editable Part Ends ############################
############################################################################
SCRIPT_DIR=$(cd "$(dirname "$0")" && pwd)
ORIGINAL_DATASET_ALL=$SCRIPT_DIR/../input/pretrain_stage_1_10k/stage_1.json
# check the global size
PRETRAIN_PASS=`python $SCRIPT_DIR/training/preprocess/check_global_batch_size.py $PRETRAIN_BATCH_SIZE_PER_GPU $PRETRAIN_GRADIENT_ACCUMULATION_STEPS 256`
if [ "$PRETRAIN_PASS" = "False" ]; then
echo "[ERROR] The global batch size of pretraining stage is not 256! Please check and retry."
exit
fi
FINETUNE_PASS=`python $SCRIPT_DIR/training/preprocess/check_global_batch_size.py $FINETUNE_BATCH_SIZE_PER_GPU $FINETUNE_GRADIENT_ACCUMULATION_STEPS 128`
if [ "$FINETUNE_PASS" = "False" ]; then
echo "[ERROR] The global batch size of finetuning stage is not 128! Please check and retry."
exit
fi
# check number of dataset samples
MAX_SAMPLE_NUM=200000
SAMPLED_PRETRAIN_DATASET=$PRETRAIN_DATASET-200k.jsonl
python $SCRIPT_DIR/training/preprocess/check_sample_number.py $PRETRAIN_DATASET $SAMPLED_PRETRAIN_DATASET $MAX_SAMPLE_NUM
# convert dataset from dj format to llava format
PRETRAIN_DATASET_JSON=$SAMPLED_PRETRAIN_DATASET.json
python $SCRIPT_DIR/data-juicer/tools/multimodal/data_juicer_format_to_target_format/dj_to_llava.py $SAMPLED_PRETRAIN_DATASET $PRETRAIN_DATASET_JSON --image_special_token "<__dj__image>" --restore_questions True --original_llava_ds_path $ORIGINAL_DATASET_ALLpretrain阶段:
# train model
PRETRAIN_NAME=MGM-2B-Pretrain-$EXP_NAME
FINETUNE_NAME=MGM-2B-Finetune-$EXP_NAME
AUX_SIZE=768
NUM_TRAIN_EPOCHS=1
PRETRAIN_SAMPLE_NUM=200000
mkdir -p $SCRIPT_DIR/../output/training_dirs/$PRETRAIN_NAME
deepspeed $SCRIPT_DIR/training/mgm/train/train_mem.py \
--deepspeed $SCRIPT_DIR/training/scripts/zero2_offload.json \
--model_name_or_path $SCRIPT_DIR/training/model_zoo/LLM/gemma/gemma-2b-it \
--version gemma \
--data_path $PRETRAIN_DATASET_JSON \
--image_folder $PRETRAIN_DATASET_IMAGE_PATH \
--vision_tower $SCRIPT_DIR/training/model_zoo/OpenAI/clip-vit-large-patch14-336 \
--vision_tower_aux $SCRIPT_DIR/training/model_zoo/OpenAI/openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup \
--mm_projector_type mlp2x_gelu \
--tune_mm_mlp_adapter True \
--mm_vision_select_layer -2 \
--mm_use_im_start_end False \
--mm_use_im_patch_token False \
--image_size_aux $AUX_SIZE \
--bf16 True \
--output_dir $SCRIPT_DIR/../output/training_dirs/$PRETRAIN_NAME \
--num_train_epochs $NUM_TRAIN_EPOCHS \
--per_device_train_batch_size $PRETRAIN_BATCH_SIZE_PER_GPU \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps $PRETRAIN_GRADIENT_ACCUMULATION_STEPS \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps $CKPT_SAVE_STEPS \
--save_total_limit $TOTAL_SAVE_CKPT_LIMIT \
--learning_rate 1e-3 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps $LOGGING_STEP \
--tf32 True \
--model_max_length 2048 \
--gradient_checkpointing True \
--dataloader_num_workers $PRETRAIN_DATALOADER_NUM_WORKERS \
--lazy_preprocess True \
--report_to none \
2>&1 | tee $SCRIPT_DIR/../output/training_dirs/$PRETRAIN_NAME/pretrain.log这里我们使用的就是 mgm 框架在进行微调,我们可以看到其中的详细参数以及数据集的地址,包括使用的是 deepseed(使用的是zero2 的优化策略,使用内存换显存,这也是为什么内存需求比较大)我们可以看到其中前面提到的大语言模型以及对应的视觉编码器。
finetune阶段:
mkdir -p $SCRIPT_DIR/../output/training_dirs/$FINETUNE_NAME
deepspeed $SCRIPT_DIR/training/mgm/train/train_mem.py \
--deepspeed $SCRIPT_DIR/training/scripts/zero2_offload.json \
--model_name_or_path $SCRIPT_DIR/training/model_zoo/LLM/gemma/gemma-2b-it \
--version gemma \
--data_path $SCRIPT_DIR/training/data/finetuning_stage_1_12k/mgm_instruction_stage_1_12k.json \
--image_folder $SCRIPT_DIR/training/data/finetuning_stage_1_12k \
--vision_tower $SCRIPT_DIR/training/model_zoo/OpenAI/clip-vit-large-patch14-336 \
--vision_tower_aux $SCRIPT_DIR/training/model_zoo/OpenAI/openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup \
--pretrain_mm_mlp_adapter $SCRIPT_DIR/../output/training_dirs/$PRETRAIN_NAME/mm_projector.bin \
--mm_projector_type mlp2x_gelu \
--mm_vision_select_layer -2 \
--mm_use_im_start_end False \
--mm_use_im_patch_token False \
--image_aspect_ratio pad \
--group_by_modality_length True \
--image_size_aux $AUX_SIZE \
--bf16 True \
--output_dir $SCRIPT_DIR/../output/training_dirs/$FINETUNE_NAME \
--num_train_epochs $NUM_TRAIN_EPOCHS \
--per_device_train_batch_size $FINETUNE_BATCH_SIZE_PER_GPU \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps $FINETUNE_GRADIENT_ACCUMULATION_STEPS \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps $CKPT_SAVE_STEPS \
--save_total_limit $TOTAL_SAVE_CKPT_LIMIT \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps $LOGGING_STEP \
--tf32 True \
--model_max_length 2048 \
--gradient_checkpointing True \
--dataloader_num_workers $FINETUNE_DATALOADER_NUM_WORKERS \
--lazy_preprocess True \
--report_to none \
2>&1 | tee $SCRIPT_DIR/../output/training_dirs/$FINETUNE_NAME/finetuning.log主要就是多了个 pretrain_mm_mlp_adapter 以及一些学习参数的不同。
测评
# inference for submission
# TextVQA
echo "Infer on TextVQA..."
bash $SCRIPT_DIR/eval/textvqa.sh $FINETUNE_NAME $INFER_CUDA_IDX
# MMBench
echo "Infer on MMBench..."
bash $SCRIPT_DIR/eval/mmbench.sh $FINETUNE_NAME "mmbench_dev_20230712" $INFER_CUDA_IDX
# copy this script to output
cp $0 $SCRIPT_DIR/../output/train.sh
# info
echo "Training and Inference done."
echo "Training checkpoints are stored in output/training_dirs/$FINETUNE_NAME."
echo "Inference results are stored in output/eval_results/$FINETUNE_NAME."
具体是通过 TextVQA 以及 MMBench 的测试验证
优化策略
可以看到上述的训练过程中并没有对官方给出的数据集进行一些更加深入的清晰甚至合成一些需要的数据。
为了提高多模态模型的能力,我们往往需要具有更高的内容一致性的数据:
这里具体指训练数据中图片和关于图片的描述之间的匹配度。
大致的方法即可以采用的有关算子有下面一些(根据Data-juicer开发者的分享总结)
图文CLIP相似度

图片和描述较为符合的数据一般具有较高的图文CLIP相似度(>0.3),即图片和描述具有较高的一致性。
图文BLIP匹配分

图片和描述较为符合的数据一般具有较高的图文BLIP匹配分
图文内容主体召回率

图文内容主体召回率指的是,在图片描述中提取出一些内容主体比如例子中的家具、枕头等,然后在图像中进行识别,看能否识别出相应对象。
质量和多样性

多算子
以上算子可以单独作为指标对数据进行筛选,也可以相互组合。但需要注意的是,单独使用效果较好的算子不一定组合起来就能实现更好的效果。


重复数据
同时,关于重复数据有趣的一点是:

对于一致性不够的数据处理方式也有两种:
(1)根据图片生成更为一致的描述

相较于原描述,新的描述更为清晰、简洁。(原描述中具体的信息如princess kate 对于模型来说可能是较难学习到的)
(2)根据描述生成更为一致的图片

相较于原图片,新图片去除了水印,并且放大了其中的太阳这个内容主体。
最后,关于合成的数据,其实也不能盲目相信,可以进行多轮的数据合成和数据清洗。
有兴趣的可以了解一下sandbox(协助你快速评估算子调度效果,快速实验得到好的数据集清洗菜谱。)
![[vue] pdf.js / vue-pdf 文件花屏问题](https://i-blog.csdnimg.cn/direct/9ee4cec22138473a88801c212fce7e4d.png)