动态网页爬虫是专门设计用来爬取动态网页内容的自动化程序或工具。与静态网页爬虫不同,动态网页的内容不是预先存储在服务器上的HTML文件,而是根据用户的请求、交互、时间、数据库状态或其他外部因素动态生成的。这些动态内容通常通过JavaScript、AJAX(Asynchronous JavaScript and XML)或其他客户端脚本技术在浏览器中异步加载。

动态网页爬虫的特点:
-
实时性:由于动态网页内容是根据用户请求实时生成的,因此动态网页爬虫能够获取到最新的数据。
-
依赖客户端渲染:动态网页的内容通常是在浏览器端通过JavaScript渲染的,这意味着爬虫需要模拟浏览器的行为来执行JavaScript并渲染DOM(文档对象模型)。
-
AJAX和WebSockets:动态网页经常通过AJAX调用与服务器进行异步通信,获取或更新页面内容。WebSockets则提供了全双工通信渠道,使得服务器可以主动向客户端推送数据。动态网页爬虫需要处理这些通信过程。
-
复杂性:由于动态网页的生成涉及多个技术栈(如HTML、CSS、JavaScript、AJAX、WebSockets等),因此动态网页爬虫的实现相对复杂。
实现方法:
-
使用浏览器自动化工具:如Selenium、Puppeteer(Node.js环境)或Pyppeteer(Python封装版)等,这些工具可以模拟用户在浏览器中的操作,包括打开网页、点击链接、填写表单、执行JavaScript等,从而获取渲染后的页面内容。
-
网络抓包工具:通过分析浏览器与服务器之间的通信(如使用Wireshark、Fiddler、Chrome DevTools等工具),识别出动态内容加载的AJAX请求,然后使用HTTP客户端库(如requests、urllib等)直接发送这些请求并获取数据。
-
无头浏览器:无头浏览器是指没有图形用户界面(GUI)的浏览器,它们可以在没有显示界面的情况下执行JavaScript和渲染DOM。例如,Puppeteer和Pyppeteer都是基于Chromium的无头浏览器解决方案。
-
JavaScript执行引擎:一些爬虫框架(如Scrapy的Splash插件)集成了JavaScript执行引擎,允许爬虫在执行HTML解析之前先执行页面中的JavaScript代码。
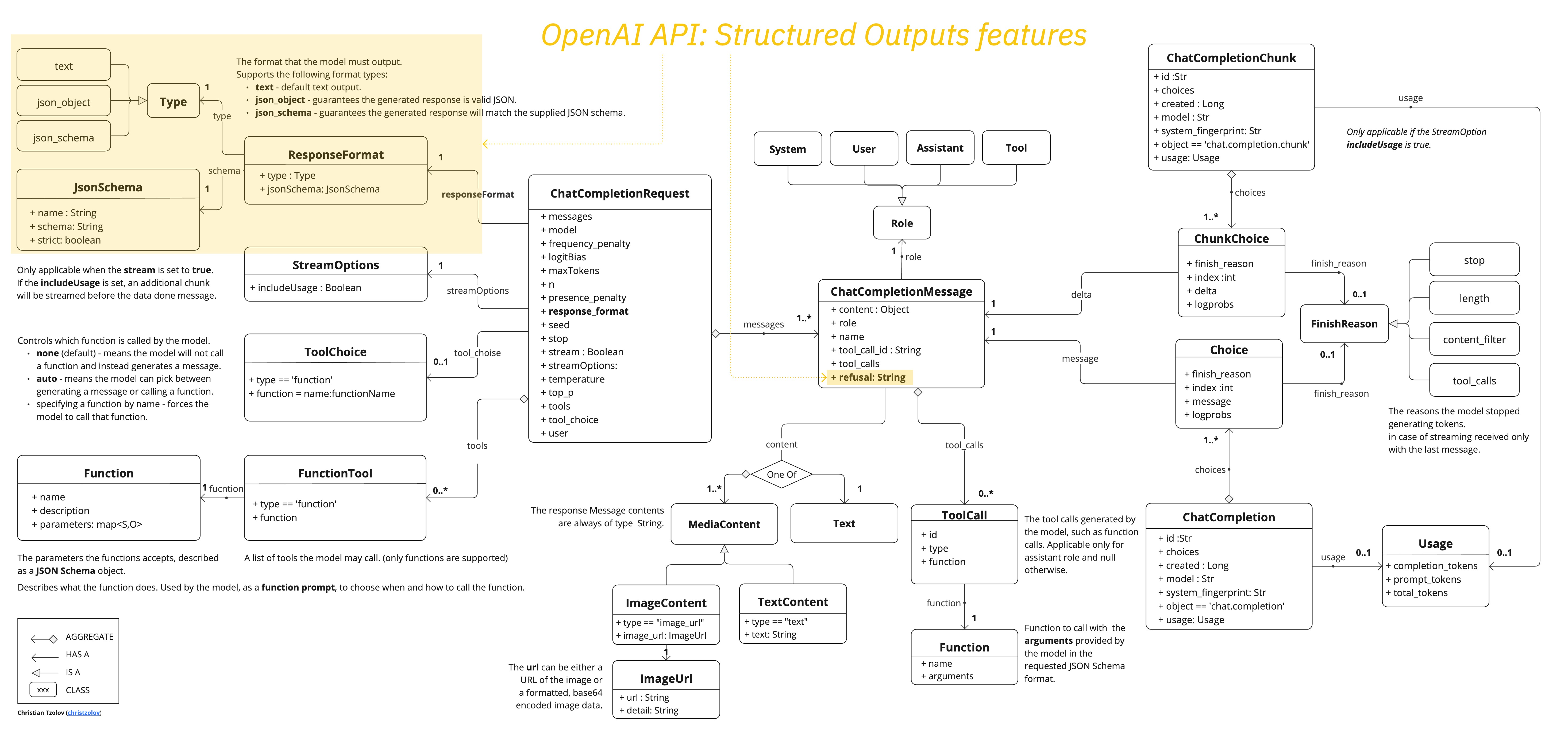
AJAX(Asynchronous JavaScript and XML)是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。通过AJAX,网页可以异步地(在后台)与服务器交换数据并更新部分网页内容,而无需重新加载整个页面。这对于创建动态、交互式和响应迅速的网页应用程序非常有用。
AJAX工作原理
-
创建XMLHttpRequest对象:AJAX通过XMLHttpRequest对象与服务器交换数据。尽管名字中包含“XML”,但AJAX通信可以返回任何类型的数据,包括JSON、HTML、纯文本等。
-
配置请求:设置请求的方法(如GET或POST)、URL以及可能的请求头、请求体等。
-
发送请求:将配置好的请求发送到服务器。
-
处理响应:当服务器响应时,XMLHttpRequest对象会触发相应的事件(如
onreadystatechange),此时可以读取服务器的响应数据,并使用JavaScript来更新网页的DOM。
示例代码
以下是一个简单的AJAX示例,用于从服务器动态加载HTML内容并插入到网页中。假设我们有一个服务器端的脚本(例如data.php),它返回一些HTML数据。
HTML文件(index.html)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>AJAX Example</title>
</head>
<body>
<div id="content">内容将在这里加载...</div>
<button onclick="loadContent()">加载内容</button>
<script>
function loadContent() {
var xhr = new XMLHttpRequest(); // 创建XMLHttpRequest对象
xhr.open('GET', 'data.php', true); // 配置请求,URL为'data.php',异步模式
// 当接收到响应时执行此函数
xhr.onreadystatechange = function () {
if (xhr.readyState === 4 && xhr.status === 200) {
// 检查是否请求已完成并且响应已成功返回
document.getElementById('content').innerHTML = xhr.responseText; // 更新DOM
}
};
xhr.send(); // 发送请求
}
</script>
</body>
</html>
PHP文件(data.php)
<?php
// 假设的服务器端脚本,返回一些HTML内容
echo '<p>这是通过AJAX动态加载的内容!</p>';
?>
项目实操
怎么说了那么多理论,说实话也不想那么啰嗦。可是吧,这些东西经常会被问到,干脆直接写下来,下次还有人问就直接把这篇文章发给他,一劳永逸!
我们拿一个法院信息公示网页举例:
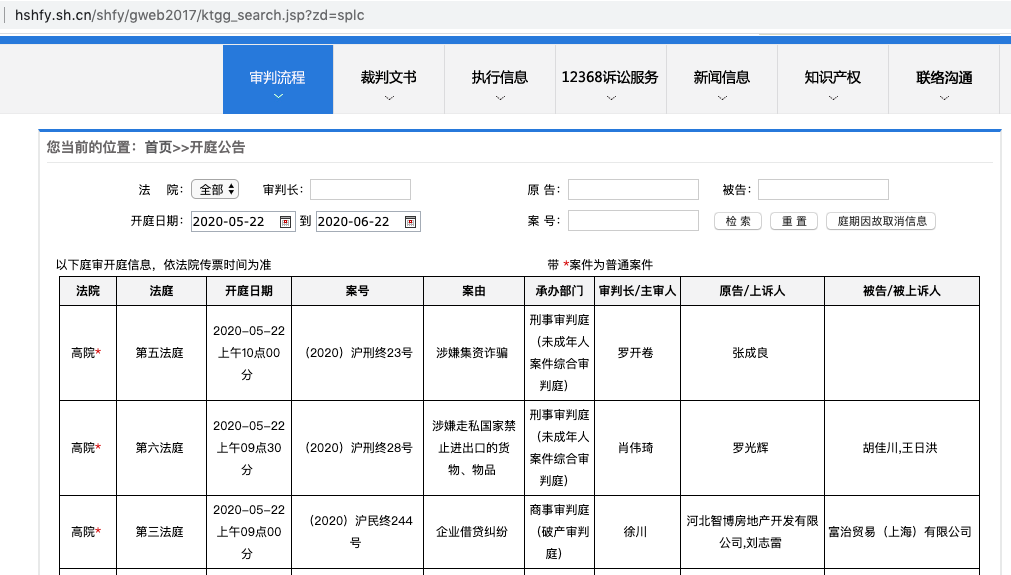
那我们就开启爬虫的正确姿势吧,先用解析接口的方法来写爬虫。
首先,找到真实请求。右键检查,点击Network,选中XHR,刷新网页,选择Name列表中的jsp文件。没错,就这么简单,真实请求就藏在里面。
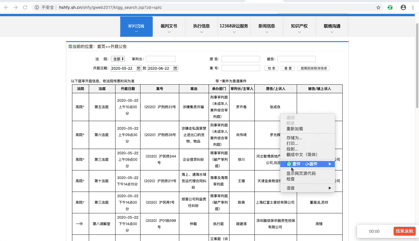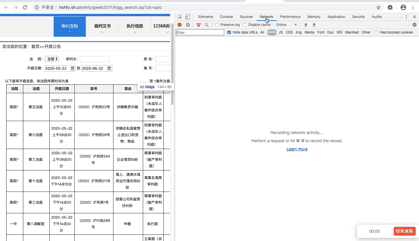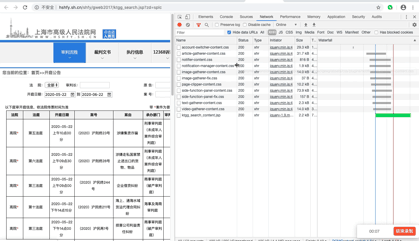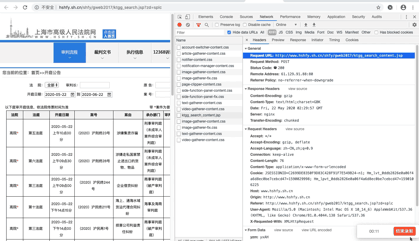
我们再仔细看看这个jsp,这简直是个宝啊。有真实请求url,有请求方法post,有Headers,还有Form Data,而From Data表示给url传递的参数,通过改变参数,咱们就可以获得数据!
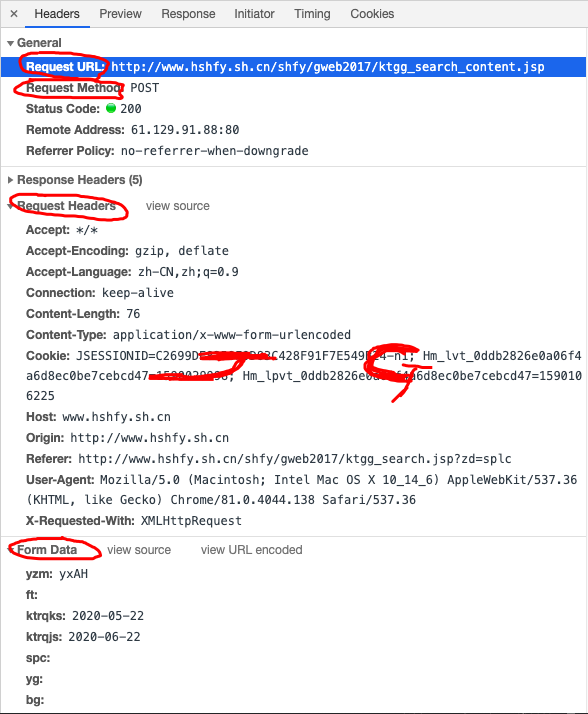
我们再仔细看看这些参数,pagesnum参数不就是代表页数嘛!我们尝试点击翻页,发现只有pagesnum参数会变化。

既然发现了它,那就赶紧抓住它。打开PyCharm,导入了爬虫所需的库。
1from urllib.parse import urlencode
2import csv
3import random
4import requests
5import traceback
6from time import sleep
7from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造真实请求,添加Headers。
1base_url = 'http://www.hshfy.sh.cn/shfy/gweb2017/ktgg_search_content.jsp?' #这里要换成对应Ajax请求中的链接
2
3headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gweb2017/ktgg_search.jsp?zd=splc',
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13}
构建get_page函数,自变量为page,也就是页数。以字典类型创建表单data,用post方式去请求网页数据。这里要注意要对返回的数据解码,编码为’gbk’,否则返回的数据会乱码!另外我还加了异常处理优化了下,以防意外发生。
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构建parse_page函数,对返回的网页数据进行解析,用Xpath提取所有字段内容,保存为csv格式。有人会问为这么喜欢用Xpath,因为简单好用啊!!!
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
最后,遍历一下页数,调用一下函数。OK,搞定!
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
我们来看一下最终效果:
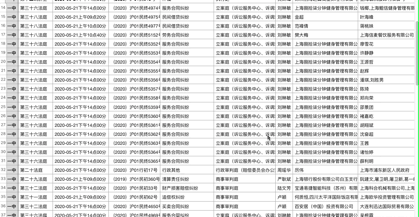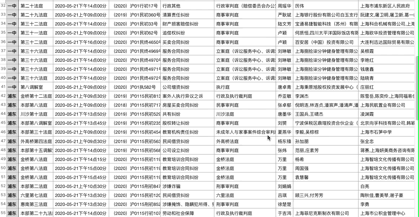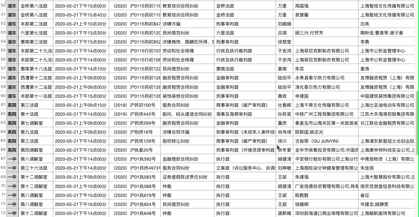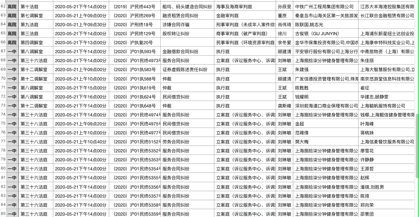
结 语
总结一下,对于AJAX动态加载网页爬虫,一般就两种方式:解析接口;Selenium。这次就先介绍了解析接口方式,个人还是推荐解析接口的方式,如果解析的是json数据,就更好爬了。实在没办法了再用Selenium吧。
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
————————————————

**全套Python学习资料分享:
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

👉学习软件

👉全套PDF电子书

👉实战案例

👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】