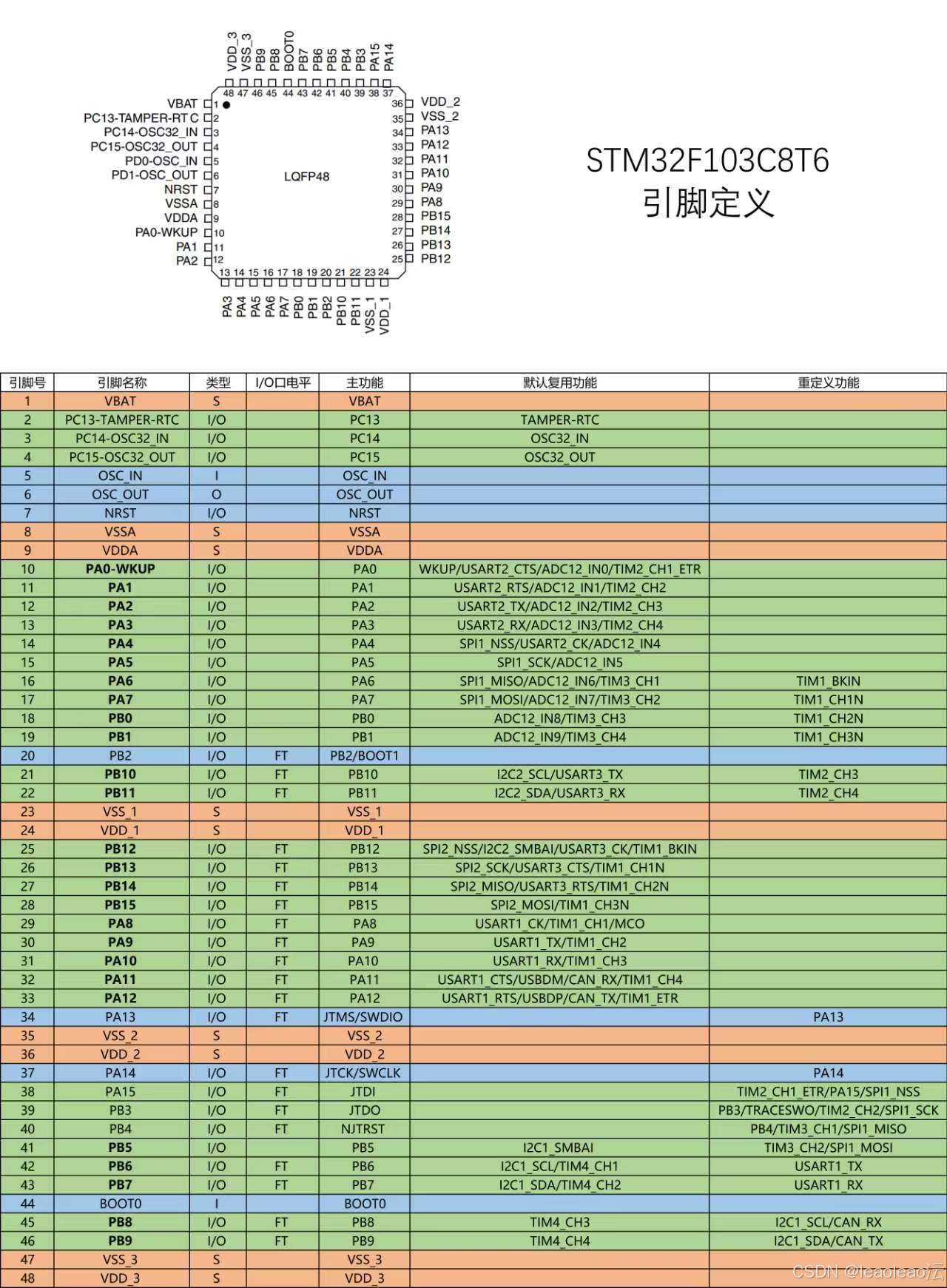
人工智能咨询培训老师叶梓 转载标明出处
如何让机器有效地理解和处理视频内容,一直是计算机视觉领域的一个挑战。最近,Google Research的研究人员提出了一种名为VideoPrism的新型视频编码器,旨在通过单一的冻结模型处理多样化的视频理解任务。以往的模型往往在处理注重外观的任务和以运动为中心的推理时难以平衡,导致在多个基准测试中落后于特定任务的专用模型。VideoPrism通过统一的模型,能够处理包括分类、定位、检索、字幕生成和问题回答等在内的广泛视频理解任务。

方法
VideoPrism的预训练数据由两部分组成:3600万个带手动标注字幕的高质量视频片段,以及5820万个带有噪声并行文本的视频片段。这些数据分别来自Anonymous-Corpus #1和其它几个数据集,如WTS-70M、YT-Temporal-180M等。这些视频片段不仅数量庞大,而且涵盖了从日常生活到科学观察的多个领域。
尽管3600万视频-字幕对是迄今为止用于视频基础模型(ViFMs)的最大数据集,但与用于图像基础模型(FMs)的图像-语言数据相比,仍然小了一个数量级。因此,研究团队还收集了大量通过自动语音识别(ASR)、元数据和大型多模态模型生成的噪声文本的视频-文本数据。
另外为了避免模型过度适应特定的评估基准,VideoPrism的预训练数据有意避免使用任何评估基准(如Kinetics)的训练集。同时,为了确保没有数据泄露,预训练语料库经过仔细的去重处理,与本文使用的33个评估基准中的所有视频进行了对比。

VideoPrism的模型架构基于标准的Vision Transformer(ViT),并采用了ViViT的时空分解设计。然而,与ViViT不同,VideoPrism去除了空间编码器后立即进行的全局平均池化层,这样做的目的是保留输出令牌序列中的时空维度,以便于需要细粒度特征的下游任务,例如时空动作定位。
VideoPrism有两种模型配置:VideoPrism-g和VideoPrism-B。VideoPrism-g使用具有10亿参数的ViT-giant网络进行空间编码,而VideoPrism-B则是使用ViT-Base网络的较小变体。

VideoPrism的训练算法旨在利用第前面提到的视频-文本对和视频数据,通过可扩展的方式训练VideoPrism,使其成为一个能够捕捉视频中外观和运动语义的基础视频编码器。训练流程包括两个阶段:视频-文本对比训练和掩蔽视频建模。

STAGE 1: 视频-文本对比训练
在第一阶段,通过对比学习对齐视频编码器和文本编码器,使用所有的视频-文本对。这一阶段的目标是最小化小批量中所有视频-文本对的相似性得分的对称交叉熵损失。初始化空间编码模块时使用了CoCa的图像模型,并在预训练中加入了WebLI数据集。视频编码器的特征在损失计算前通过多头注意力聚合器(MAP)进行聚合。这使得视频编码器能够从语言监督中学习丰富的视觉语义,并为第二阶段的训练提供语义视频嵌入。
STAGE 2: 掩蔽视频建模
第二阶段的训练专注于从视频数据中学习外观和运动信息。在第一阶段的基础上,进一步训练视频编码器,使用改进的掩蔽视频建模方法。这些改进包括:
-
令牌洗牌方案:为了防止解码器在预测掩蔽令牌时仅复制和粘贴未掩蔽的令牌,从而简化任务,研究团队引入了一种新颖的令牌洗牌方案。在将编码器的输出令牌序列馈送到解码器之前,对其进行随机洗牌,解码器在洗牌后的序列中加入位置嵌入。
-
全局-局部蒸馏:为了解决在第二阶段训练中仅使用掩蔽建模损失可能导致的外观重点任务性能下降的问题,研究团队添加了额外的损失,让第二阶段模型使用第一阶段教师模型的可见令牌来蒸馏完整视频的全局嵌入。
这种双阶段训练方法不仅提高了模型在多个视频理解基准上的性能,还确保了VideoPrism能够在广泛的任务中保持出色的泛化能力。
实验
VideoPrism在多种视频中心理解任务上的评估,旨在证明其能力和泛化性。这些任务被分为四大类:(1) 一般视频理解,包括分类和时空定位;(2) 零样本视频-文本检索;(3) 零样本视频字幕生成和问答;(4) 科学领域的计算机视觉。
分类和时空定位
VideoPrism与最先进的基础模型(FMs)在视频GLUE(Yuan等人,2023)上进行了比较,这是一个视频唯一的理解基准。视频GLUE通过四种适应方法在八个标志性数据集上评估FMs,代表以外观为重点的动作识别(VC (A))、富含动作的动作识别(VC (M))、多标签视频分类(VC (ML))、时间动作定位(TAL)和时空动作定位(STAL)。此外,该基准引入了视频GLUE分数(VGS),考虑适应成本和性能之间的权衡,为FMs在视频唯一理解任务上的能力提供全面视图。
数据集:视频GLUE中的八个数据集包括Kinetics400(K400)、Moments-in-Time(MiT)、Something-Something v2(SSv2)、Diving48(D48)、Charades、ActivityNet v1.3、Atomic Visual Actions(AVA)和AVA-Kinetics(AVA-K)。

主要结果:表2显示了在视频GLUE上的冻结骨干网络结果。VideoPrism在所有数据集上都大幅度超越了基线模型。此外,将VideoPrism的底层模型大小从ViT-B增加到ViT-g显著提高了性能。没有基线模型能在所有基准测试中排名第二,这表明以前的可能针对视频理解的某些方面进行了开发,而VideoPrism在这一广泛的任务范围内持续改进。这一结果暗示VideoPrism将各种视频信号整合到一个编码器中:多粒度的语义、外观与运动线索、时空信息,以及对不同视频来源(例如,网络视频与脚本化表演)的鲁棒性。
零样本视频-文本检索和分类
为了使VideoPrism具备零样本视频-文本检索和视频分类的能力,研究团队遵循LiT(Zhai等人,2022b)的方法来学习一个文本编码器,该编码器生成的文本嵌入与VideoPrism中的相应视频嵌入相匹配。选择LiT文本编码器是为了反映第一阶段训练中的编码器,并在视频编码器上附加一个MAP头。LiT调整是在第一阶段的相同预训练数据上进行的。
数据集:在MSRVTT、VATEX和ActivityNet上评估VideoPrism的零样本视频-文本检索性能。对于零样本视频分类任务,实验涉及Kinetics-400、Charades、SSv2-Temporal和SSv2-Events,以及NExT-QA的ATP-Hard子集。SSv2和NExT-QA(ATP-Hard)分别专注于运动和时间推理。

主要结果:表3和表4分别总结了视频-文本检索和视频分类的结果。VideoPrism在大多数基准测试中都设定了新的最高标准,并且在具有挑战性的数据集上取得了显著的改进(例如,在ActivityNet上提高了9.5%,在SSv2-Events上提高了4.4%,在Charades上提高了6.6 mAP)。VideoPrism-B的大多数结果实际上比现有的更大规模模型更好。此外,VideoPrism与在领域内数据和额外模态(例如音频)上预训练的模型相比,性能相当或更好。这些在零样本检索和分类任务中的改进展示了VideoPrism的强大泛化能力。
零样本视频字幕生成和问答
VideoPrism在生成性视频-语言任务,即视频字幕生成和视频问答(QA)上的能力进一步得到了评估。在这些任务中,研究团队将VideoPrism与语言解码器PaLM-2配对。为了连接这两个模型,引入并训练了几个连接层,同时保持VideoPrism和语言解码器冻结状态。在零样本配置下,对视频字幕和QA基准进行评估。值得注意的是,模型并没有针对字幕生成和QA任务分别进行调整。
数据集:在标准的零样本视频字幕数据集上评估模型,包括MSRVTT、VATEX和YouCook2,以及视频QA基准,包括MSRVTT-QA、MSVD-QA和NExT-QA。对于视频QA,为了确保模型输出答案的长度和风格与真实答案匹配,采用了Flamingo的零样本方法,并使用下游任务训练集中的两镜头文本提示。另外对于MSRVTT-QA和MSVD-QA,实验采用了封闭词汇表评估配置。

主要结果:表5和表6分别展示了零样本视频字幕生成和QA的结果。尽管模型架构简单且适配器参数数量少,但VideoPrism模型在冻结视觉和语言模型的方法中表现最佳,除了在VATEX上。结果表明,VideoPrism编码器能够很好地泛化到视频到语言的生成任务。
科学领域的计算机视觉任务
与通常关注人类中心数据的视频分析基准不同,研究团队在科学数据集上的一系列视频上评估了VideoPrism,以评估其泛化能力和在科学应用中的潜在用途。这些数据集涵盖了行为学、行为神经科学、认知科学和生态学等领域。
数据集:专注于大规模视频数据集,这些数据集通过科学实验进行了领域专业知识的注释。数据集包括苍蝇、老鼠、黑猩猩和肯尼亚动物的视频。除了ChimpACT数据集用于时空动作定位外,所有数据集都用于视频行为分类。使用之前在这些数据集上定义的标准数据分割,并使用mAP度量标准进行评估,KABR使用宏观准确率。

主要结果:表7显示了VideoPrism与领域专家模型和最先进的方法在科学领域的计算机视觉基准上的比较。使用共享冻结编码器的通用ViFMs实现的性能与针对特定任务定制的领域特定模型相当或更好。特别是,VideoPrism通常表现最佳,并且用基础规模模型就超过了领域专家模型。扩展到大规模模型在所有数据集上进一步提高了性能。这些结果表明,ViFMs有潜力显著加速各个领域的视频分析。
研究团队还进行了消融研究,旨在评估VideoPrism背后的主要驱动力,包括收集预训练数据的策略和努力,以及通过两阶段预训练框架、全局蒸馏和令牌洗牌改进掩蔽自动编码的预训练方法的有效性。
首先,在较小规模的公共可用语料库(总共1.5亿个视频片段)上训练视频-文本对比基线,包括WTS-70M、YT-Temporal-180M和InternVid。然后,逐步向基线添加主要组件(更大的预训练数据、两阶段训练、损失和令牌洗牌),以观察模型性能的演变。还尝试将对比损失与掩蔽自动编码在一个阶段中结合,以突出两阶段训练流程的有效性。

消融结果:图4展示了消融结果,观察到在运动丰富的SSv2和外观驱动的K400上性能演变轨迹不同。VideoPrism在SSv2上的一致改进表明了数据策划和模型设计努力对于促进视频中的运动理解的有效性。尽管对比基线在K400上已经取得了竞争性结果,但提出的全局蒸馏和令牌洗牌进一步提高了准确性。
VideoPrism的一个局限性是它在预训练中使用了带有噪声的文本的视频语料库。这种噪声文本可能不完整且有偏见,可能会影响模型性能。另外长视频理解仍然是一个挑战,因为目前的焦点是作为VideoPrism输入采样16帧的短视频片段。未来的工作可以利用编码器作为长视频理解系统的一部分。虽然研究团队提倡冻结骨干网络的评估,但有些场景更有利于端到端微调和参数高效适应。尽管存在这些局限性,结果表明VideoPrism对一系列现实世界视频理解任务的潜在影响。
论文链接:https://arxiv.org/abs/2402.13217