目录
续:通信 4 种情况
应用场景
1. 自定义 shell 管道
1. 包含头文件
2. 解析命令函数
详细步骤
3. 执行命令函数
4. 主函数
总结
2. 使用管道实现一个简易版本的进程池
代码结构
代码实现
channel.hpp
tasks.hpp
main.cc
子进程读取任务,重定向
选择进程
主函数
退出任务
测试和观察
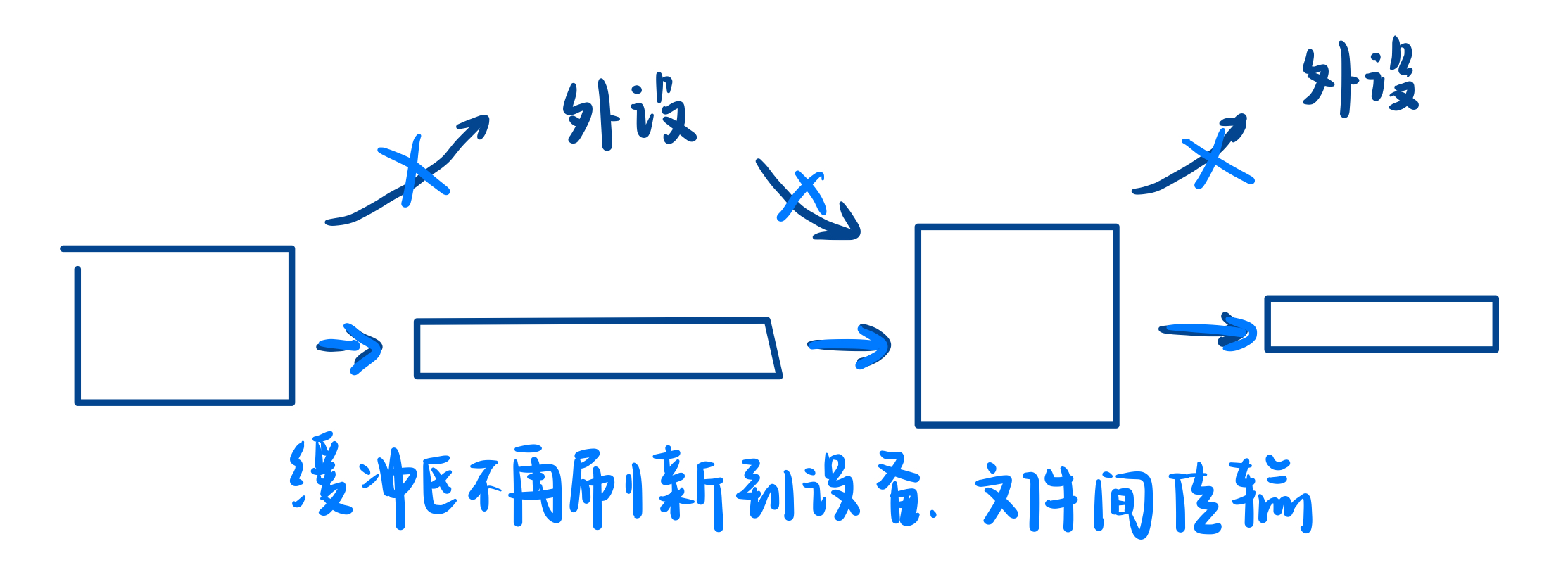
续:通信 4 种情况
- 读写段正常,管道如果为空,读端就要阻塞
- 读写端正常,管道如果被写满,写端就要阻塞
- 读端正常读,写端关闭,读端就会读到 0,表面读到了文件(pipe)结尾,不会被阻塞
父进程等待子进程(Z)退出,测试 n=0;
4.写端是正常写入,读端关闭了的情况呢?
操作系统就要杀掉正在写入的进程,如何干掉?通过信号杀掉
os 是不会做低效,浪费等类似的工作的。如果做了,就是操作系统的 bug
让子进程写入父进程读取是几号信号?代码没跑完,程序出异常了

结论:管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,让write进程退出。
查看 信号可以发现

应用场景
这个管道和我们之前学到的知识,哪些是有关系的呢?
- 都是 bash 的子进程,匿名管道
cat test.txt | head -10 | tail -5
sleep 666666 | sleep 7777 | sleep 88888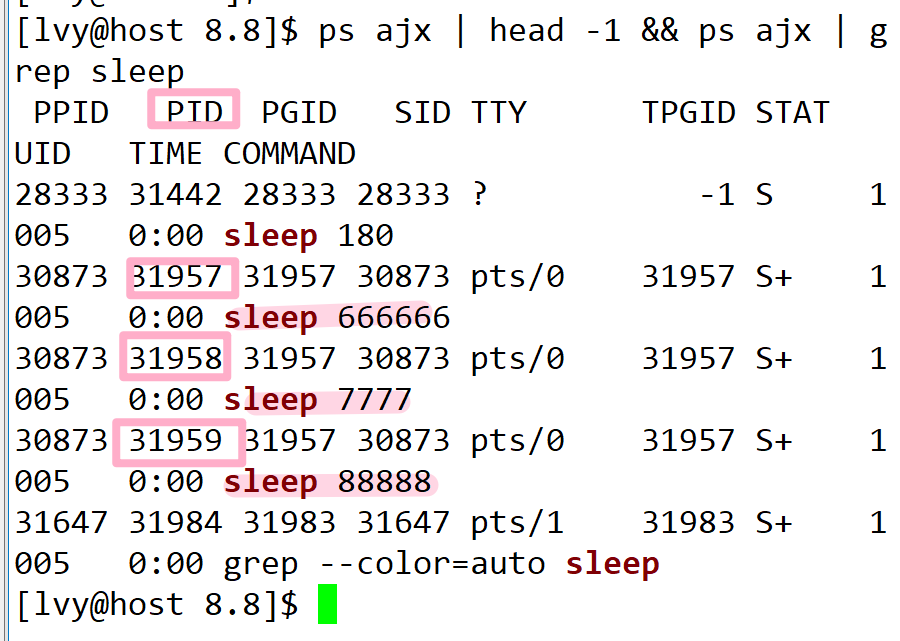
观察 pid 可以发现,具有血缘关系
- 我们想让我们的 shell 支持 | 管道,代码该如何写?
1. 自定义 shell 管道
三步:切割 读取 重定向
例如实现:支持单个管道 ls -a -l | wc -l
思路:
0.分析输入的命令行字符串,获取有多少个 l ,命令打散多个子命令字符串
1.malloc 申请空间,pipe 先申请多个管道
2. 循环创建多个子进程,每一个子进程的重定向情况。
- 最开始,输出重定向,1->指定的一个管道的写端,
- 中间:输入输出重定向,0 标准输入重定向到上一个管道的读端,1 标准输出重定向到下一根管道的写端
- 最后一个:输入重定向,将标准输入重定向到最后一个管道的读端
3.分别让不同的子进程执行不同的命令--exec* --exec* 不会影响该进程曾经打开的文件,不会影响预先设置好的管道重定向
这段代码是一个简单的管道实现,用于连接多个命令并将它们的输出串联起来。下面是分块解释每部分代码的含义:
1. 包含头文件
#include <iostream>
#include <vector>
#include <string>
#include <sstream>
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <cstring>
#include <cerrno>2. 解析命令函数
void parseCommand(const string& command, vector<string>& cmds) {
istringstream stream(command);
string cmd;
while (getline(stream, cmd, '|')) {
cmds.push_back(cmd);
}
}- 接收一个字符串
command,并将其拆分为由|符号分隔的命令列表。 - ❓ 使用
istringstream来从字符串中读取命令。 - 将每个命令添加到
cmds向量中。
解答:
istringstream 类是 C++ 标准库中的一个类,它提供了一个类似文件流的接口来从字符串中读取数据。在这个 parseCommand 函数中,istringstream 被用来从一个包含多个命令的字符串中读取各个命令,并将它们存储在一个 vector<string> 容器中。
下面是 parseCommand 函数的详细解释:
void parseCommand(const string& command, vector<string>& cmds) {
istringstream stream(command); // 创建一个 istringstream 对象
string cmd;
while (getline(stream, cmd, '|')) { // 读取命令直到遇到 '|' 字符
cmds.push_back(cmd); // 将命令添加到 cmds 向量中
}
}详细步骤
- 创建
istringstream对象:
istringstream stream(command);这一行代码创建了一个 istringstream 对象 stream,并将字符串 command 作为构造函数的参数传入。这意味着 stream 现在可以像处理文件一样处理这个字符串。
- 读取命令:
while (getline(stream, cmd, '|')) {
// ...
}这里使用 getline 函数从 stream 中读取数据。getline 的第三个参数是分隔符,这里设置为 '|',这意味着 getline 将读取直到遇到 '|' 字符为止的内容作为一个命令。
-
getline(stream, cmd, '|'):
-
-
stream: istringstream 对象。cmd: 用来存储读取到的命令的字符串。'|': 用作分隔符的字符。
-
- 存储命令:
cmds.push_back(cmd);当 getline 读取到一个命令后,该命令会被存储在 cmd 字符串中,然后将其添加到 cmds 向量中。
- 循环继续:
while循环会一直执行,直到getline无法再从stream中读取到更多数据为止。这意味着当getline遇到最后一个命令之后的'|'或者到达字符串的结尾时,循环就会结束。
3. 执行命令函数
void executeCommand(const string& cmd, int inputFd, int outputFd) {
istringstream stream(cmd);
vector<char*> args;//获取命令段
string arg;
while (stream >> arg) {
char* cstr = new char[arg.size() + 1];
strcpy(cstr, arg.c_str());
args.push_back(cstr);
}
args.push_back(NULL);
if (inputFd != 0) {
dup2(inputFd, 0);
close(inputFd);
}
if (outputFd != 1) {
dup2(outputFd, 1);
close(outputFd);
}
// 添加 sleep 以便观察进程状态
sleep(1);
execvp(args[0], args.data());
perror("execvp failed");
exit(EXIT_FAILURE);
}- 接收一个命令字符串
cmd,一个输入文件描述符inputFd和一个输出文件描述符outputFd。 - 使用
istringstream从cmd中读取命令参数。 strcpy(cstr, arg.c_str());将命令参数转换为 C 风格的字符串数组。- 重定向标准输入和输出文件描述符。
- 使用
execvp函数执行命令。 - 如果
execvp失败,则打印错误消息并退出。
4. 主函数
int main() {
string command = "ls -a -l | wc -l";
vector<string> cmds;
parseCommand(command, cmds);
int numPipes = cmds.size() - 1;//计算需要管道数量
int pipefds[2 * numPipes];//利用管道数组创建管道
for (int i = 0; i < numPipes; ++i) {
if (pipe(pipefds + i * 2) == -1) {
perror("pipe failed");
exit(EXIT_FAILURE);
}
}
for (int i = 0; i <= numPipes; ++i) {
pid_t pid = fork();
if (pid == -1) {
perror("fork failed");
exit(EXIT_FAILURE);
} else if (pid == 0) {
if (i != 0) {
dup2(pipefds[(i - 1) * 2], 0);
}
if (i != numPipes) {
dup2(pipefds[i * 2 + 1], 1);
}
for (int j = 0; j < 2 * numPipes; ++j) {
close(pipefds[j]);
}
// 添加 sleep 以便观察进程状态
sleep(1);
executeCommand(cmds[i], 0, 1);
}
}
for (int i = 0; i < 2 * numPipes; ++i) {
close(pipefds[i]);
}
// 添加 sleep 以便观察进程状态
sleep(1);
for (int i = 0; i <= numPipes; ++i) {
wait(NULL);
}
return 0;
}❓ 父进程是如何实现对多个子进程和管道数组进行管理的?
- 创建管道:父进程首先计算出需要创建的管道数量,然后使用
pipe函数为数组pipefds创建管道数组。 - 创建子进程:父进程使用一个循环来创建多个子进程,每个子进程都负责执行命令数组
cmds中的一个命令。 - 重定向子进程的输入输出:在每个子进程中,根据其在管道数组中的位置,使用
dup2来重定向其标准输入输出到对应的管道。如果子进程不是第一个,它的标准输入会重定向到前一个管道的读端;如果子进程不是最后一个,它的标准输出会重定向到当前管道的写端。 - 关闭不需要的管道描述符:在每个子进程中,关闭所有不需要的管道描述符,防止子进程读取或写入错误的管道。
- 执行命令:子进程调用
executeCommand函数来执行其对应的命令。 - 关闭父进程中的管道描述符:在所有子进程创建完毕后,父进程关闭所有管道描述符。
- 等待子进程结束:父进程使用循环调用
wait函数来等待所有子进程结束。
以下是管理子进程和管道数组的详细步骤:
关闭所有管道描述符: 在子进程中,通过循环关闭所有 pipefds 中的管道描述符,确保子进程只使用需要的管道描述符。
- cpp复制
for (int j = 0; j < 2 * numPipes; ++j) {
close(pipefds[j]);
}在父进程中,在所有子进程创建之后,也关闭所有管道描述符。
cpp复制
for (int i = 0; i < 2 * numPipes; ++i) {
close(pipefds[i]);
}总结
- 首先解析命令字符串,将它分割成一系列单独的命令。
- 然后创建所需的管道,并为每个命令创建一个子进程。
- 每个子进程执行一个命令,并使用管道连接命令的输出。
- 最终输出是最后一个命令的结果。
这个程序模拟了 shell 中管道的工作原理,允许你将多个命令的输出串联起来处理。
问题:

解决:
- 替换
nullptr为NULL:
args.push_back(NULL);- 包含头文件以确保
perror被正确声明:
#include<stdio.h>
#include<errno.h>
2. 使用管道实现一个简易版本的进程池
通过使用管道实现父进程和子进程之间的通信。该进程池可以执行不同的任务,人选择任务,父进程通过管道向子进程发送任务,子进程执行收到的任务。
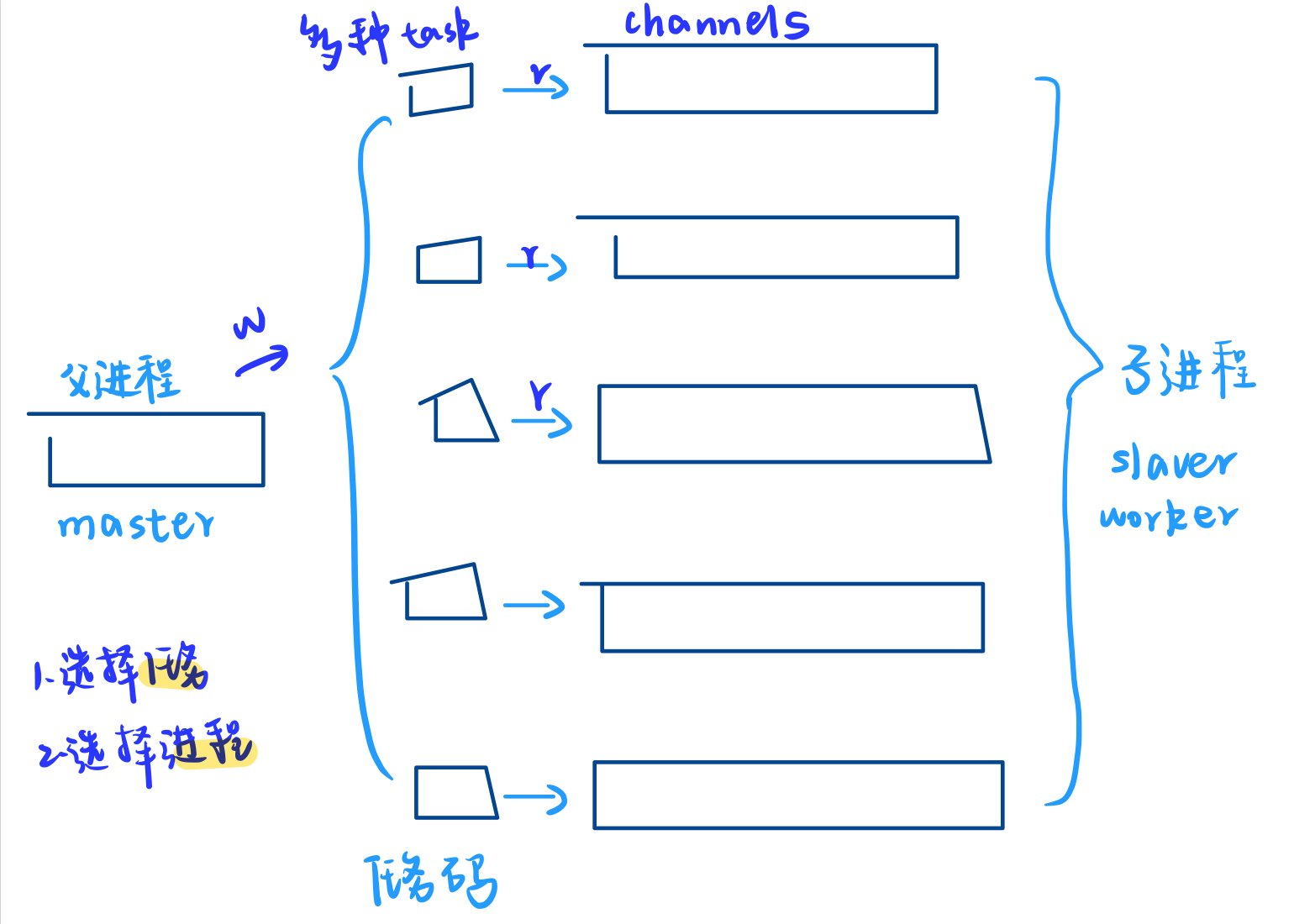
代码结构
- channel 类:用于保存子进程的信息,包括命令管道、子进程 PID 和子进程名称。
- 任务函数:定义一些任务供子进程执行。
- slaver 函数:子进程执行的函数,等待从管道读取任务并执行。
- 初始化进程池:创建子进程和管道,并保存子进程信息到 channels 向量中。
- 控制子进程:父进程选择任务并将任务发送给子进程。
- 退出任务:关闭管道并等待子进程退出。
代码实现
channel.hpp
建立好了父进程和子进程之间的通道:先写类再用容器
- channel 类:
-
channel类用于存储子进程的信息,包括管道写端文件描述符_cmdfd,子进程 PID_slaverid和子进程名称_processname。
#pragma once
#include <string>
#include <vector>
#include <iostream>
#include <unistd.h>
#include <sys/wait.h>
#include <cassert>
class channel {
public:
channel(int cmdfd, int slaverid, const std::string &processname)
: _cmdfd(cmdfd), _slaverid(slaverid), _processname(processname) {}
public:
int _cmdfd; // 发送任务的文件描述符
pid_t _slaverid; // 子进程的PID
std::string _processname; // 子进程的名字 -- 方便我们打印日志
};tasks.hpp
命名规范:
- 输入:const &
- 输出:*
- 输入输出:&
- 任务函数:
-
- 定义了一些任务函数 (
task1,task2,task3,task4),这些函数表示子进程可以执行的不同任务。 LoadTask函数通过vector<task_t> *tasks将这些任务加载到tasks动态数组中。
- 定义了一些任务函数 (
#pragma once
#include <iostream>
#include <vector>
typedef void (*task_t)();
void task1() {
std::cout << "lol 刷新日志" << std::endl;
}
void task2() {
std::cout << "lol 更新野区,刷新出来野怪" << std::endl;
}
void task3() {
std::cout << "lol 检测软件是否更新,如果需要,就提示用户" << std::endl;
}
void task4() {
std::cout << "lol 用户释放技能,更新用的血量和蓝量" << std::endl;
}
void LoadTask(std::vector<task_t> *tasks) {
tasks->push_back(task1);
tasks->push_back(task2);
tasks->push_back(task3);
tasks->push_back(task4);
}注意对函数指针的设置 typedef void (*task_t)(); ,便于后续生成任务码
main.cc
- slaver 函数:
- 子进程在
slaver函数中运行,等待从标准输入(由管道重定向)读取任务码,并执行相应的任务。
- 初始化进程池:
InitProcessPool函数创建管道和子进程,并将子进程的信息保存到channels向量中。每个子进程在创建后会关闭不需要的管道端,确保每个子进程只有一个写端。
- 控制子进程:
ctrlSlaver函数由父进程运行,显示菜单并根据用户输入选择任务和子进程,将任务码通过管道发送给子进程。
- 退出任务:
QuitProcess函数关闭管道并等待所有子进程退出。
前备芝士:
为什么要设置缓冲区 | slab 分派器?
slab 分派器是一种内存管理技术,用于高效地分配和释放小块内存,减少系统调用,系统调用是有成本的,(如内存分配)需要从用户空间切换到内核空间,
任务码和管道:使用管道和任务码来选择性地调用子进程,实现进程间通信和任务调度。
后缀解释:
- .cc:C++源文件。
- .hpp:C++头文件,包含了声明,有时也包含定义,因为这里没有使用库。
管道使用:在管道中,父进程写入数据,子进程选择读取,实现不同进程间共享数据。
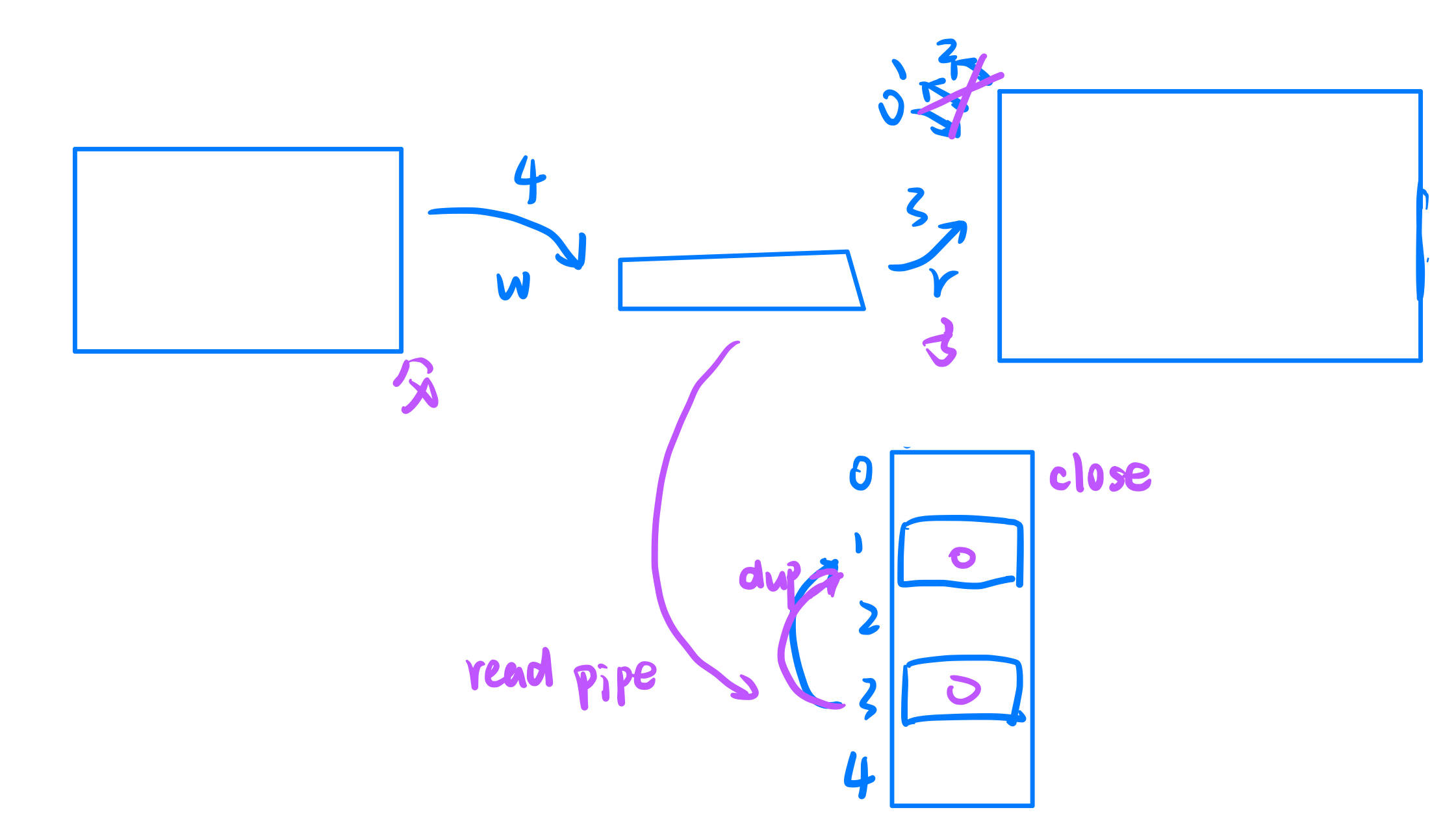
子进程读取任务,重定向
#include <iostream>
#include <vector>
#include <string>
#include <unistd.h>
#include <sys/wait.h>
#include <functional>
#include <cassert>
#include <cstdlib>
#include <ctime>
#include "channel.hpp"
#include "tasks.hpp"
void slaver(const std::vector<task_t> &tasks) {
while (true) {
int cmdcode = 0;
int n = read(0, &cmdcode, sizeof(int)); // 从标准输入读取命令码
if (n == sizeof(int)) {
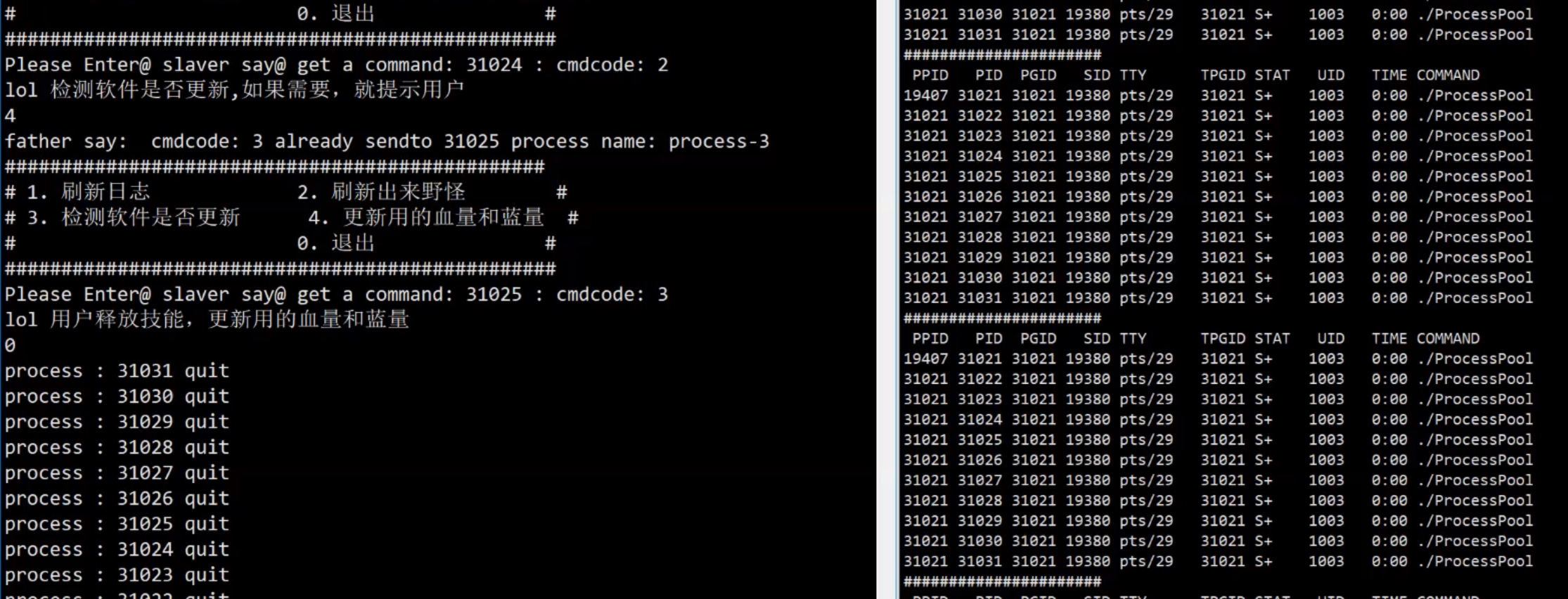
std::cout << "slaver say@ get a command: " << getpid() << " : cmdcode: " << cmdcode << std::endl;
if (cmdcode >= 0 && cmdcode < tasks.size()) {
tasks[cmdcode]();
}
}
if (n == 0) break; // 父进程关闭写端,子进程退出
}
}
void InitProcessPool(std::vector<channel> *channels, const std::vector<task_t> &tasks, int processnum) {
std::vector<int> oldfds;
for (int i = 0; i < processnum; i++) {
int pipefd[2];
int n = pipe(pipefd);
assert(!n);
pid_t id = fork();
if (id == 0) { // child process
std::cout << "child: " << getpid() << " close history fd: ";
for (auto fd : oldfds) {
std::cout << fd << " ";
close(fd);
}
std::cout << std::endl;
close(pipefd[1]);
dup2(pipefd[0], 0); // 重定向子进程的读端
close(pipefd[0]);
slaver(tasks);
exit(0);
} else { // parent process
close(pipefd[0]);
std::string name = "process-" + std::to_string(i);
channels->push_back(channel(pipefd[1], id, name));
oldfds.push_back(pipefd[1]);
sleep(1);
}
}
}
void Menu() {
std::cout << "################################################" << std::endl;
std::cout << "# 1. 刷新日志 2. 刷新出来野怪 #" << std::endl;
std::cout << "# 3. 检测软件是否更新 4. 更新用的血量和蓝量 #" << std::endl;
std::cout << "# 0. 退出 #" << std::endl;
std::cout << "#################################################" << std::endl;
}
批注:
close(pipefd[1]);
dup2(pipefd[0], 0);
选择进程
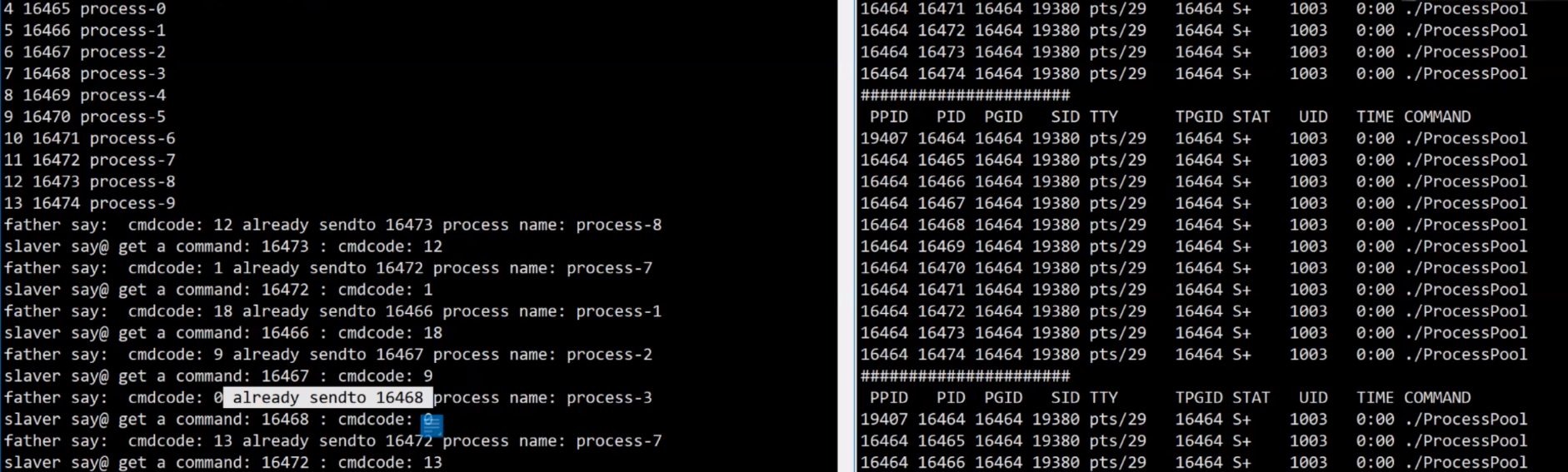
轮询发送的实现
void ctrlSlaver(const std::vector<channel> &channels)
{
int which = 0;
// int cnt = 5;
while(true)
{
int select = 0;
Menu();
std::cout << "Please Enter@ ";
std::cin >> select;
if(select <= 0 || select >= 5) break;
// select > 0&& select < 5
// 1. 选择任务
// int cmdcode = rand()%tasks.size();
int cmdcode = select - 1;
// 2. 选择进程
// int processpos = rand()%channels.size();
std::cout << "father say: " << " cmdcode: " <<
cmdcode << " already sendto " << channels[which]._slaverid << " process name: "
<< channels[which]._processname << std::endl;
// 3. 发送任务
write(channels[which]._cmdfd, &cmdcode, sizeof(cmdcode));
which++;
which %= channels.size();
// cnt--;
// sleep(1);
}
}子进程被唤醒,收到了任务
主函数
void QuitProcess(const std::vector<channel> &channels) {
for (const auto &c : channels) {
close(c._cmdfd);
waitpid(c._slaverid, nullptr, 0);
}
}
int main() {
srand(time(nullptr) ^ getpid() ^ 1023);
std::vector<task_t> tasks;
LoadTask(&tasks);
int processnum = 4;
std::vector<channel> channels;
InitProcessPool(&channels, tasks, processnum);
ctrlSlaver(channels, tasks);
QuitProcess(channels);
return 0;
}❓ 为什么要埋种子
srand(time(nullptr)^getpid()^1023);?实现负载均衡
调用 srand() 函数并传递一个种子值,可以初始化随机数生成器,使得每次运行程序时生成的随机数序列
- 安全性:如果随机数生成器没有设置种子,攻击者可以预测随机数序列,这可能会带来安全风险。
- 多样性:在需要不同结果的情况下(如游戏、模拟、负载均衡等),设置种子可以确保每次运行都有不同的体验或结果。

任务是在人输入时选择的,经常需要系统随机选择来实现均衡
整个过程:任务先和子进程挂上钩,父进程通过对任务的转化读取子进程
补充:
在 C++ 的 <functional> 头文件中,包含了许多预定义的函数对象和函数适配器。以下是一些算术运算函数对象:
-
std::plus<T>:执行加法。std::minus<T>:执行减法。std::multiplies<T>:执行乘法。std::divides<T>:执行除法。std::modulus<T>:执行取模运算。std::negate<T>:执行取反运算。
监控会发现:父端不同文件的写,字段都是 3 读取
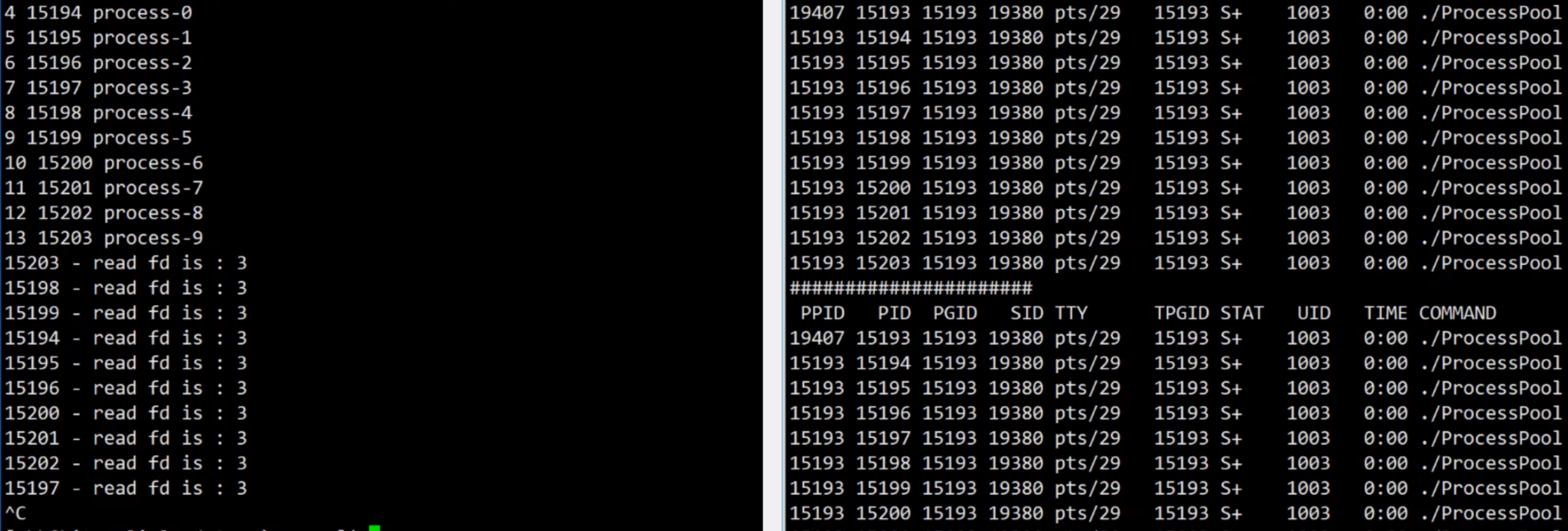
退出任务
重点:解决 子进程之间有互相通信的能力 这一问题
在使用管道进行通信的情况下,如果子进程之间未妥善处理管道的文件描述符,可能会导致子进程之间的意外通信和退出的混乱。解决:
关闭文件描述符:父进程首先关闭所有子进程的写端管道,这样,当子进程在尝试读取管道时会发现到达文件末端,从而退出(因为管道的写端关闭,读取操作会返回 0 表示文件结束)。

测试和观察
问题:

解决:
根据错误信息,我们需要进行以下修改:
- 使用正确的类型定义:在
for循环中需要指定变量的类型。 - 引入缺失的头文件:如
<string>中的to_string成员。 - 解决
nullptr问题:使用NULL替代nullptr,因为nullptr是 C++11 及之后的特性。 - 启用 C++11 标准:大多数编译器默认设置为 C++98,需要手动启用 C++11。
首先,我们在编译时启用 C++11 标准:
shCopy code
g++ -std=c++11 -o mypipe main.cc通过这些步骤,可以测试简易进程池的功能并观察进程的运行情况。