目录
摘要 1
Abstract 2
第1章 绪论 3
1.1 研究背景 3
1.2 研究目的和意义 4
1.2.1 研究目的 4
1.2.2 研究意义 6
1.3 国内外研究现状分析 7
1.3.1 国内研究现状 7
1.3.2 国外研究现状 9
1.4 研究内容 11
第2章 Hadoop技术及相关组件介绍 12
2.1 HDFS的工作原理及特点介绍 12
2.2 MapReduce原理及特点介绍 14
2.3 hive的基本概念 15
2.3.1 分区分桶的概念 16
2.4 sqoop的基本概念 17
2.5 MySQL的基本概念 18
第3章 Hadoop部署及其各类组件的安装 19
3.1 搭建Hadoop环境系统 19
3.1.1 Hadoop的部署 19
3.2 相关组件的安装 21
3.2.1 安装hive数据仓库 21
3.2.2 安装MySQL数据库 22
3.2.3 安装sqoop组件 22
第4章 实现过程 23
4.1 数据获取及介绍 23
4.2 MapReduce数据预处理 24
4.3 数据上传到hdfs 29
4.4 建立数据库表与分区数据导入 30
4.5 Hive统计分析 32
4.5.1 PV指标介绍以及统计 32
4.5.2 注册用户数指标介绍与统计 33
4.5.3 独立IP数指标介绍与统计 34
4.5.4 跳出用户数指标介绍与统计 35
4.5.5 数据表汇总 36
4.6 数据导出与数据展示 38
4.6.1 MySQL创建表格 38
4.6.2 Sqoop将hive表导入mysql 38
4.7 可视化展示 40
第5章 总结与分析 43
5.1 创新之处 43
5.2 不足之处 44
参考文献 44

本文研究并应用了一种基于Hadoop的网络流量分析系统。该项目首先将网络流量数据上传至HDFS分布式文件系统,接着利用MapReduce框架进行数据预处理。通过Hive进行大数据分析,我们可以对网络流量的各项关键指标进行详细统计,包括访问量(PV)、独立IP数、用户注册数以及跳出率等。最后,通过Sqoop将分析结果导出至MySQL数据库,并利用Python构建了可视化界面,使用户能够更加直观地理解分析结果。

本项目采用Hadoop分布式计算框架,有效解决了海量网络流量数据的处理问题。通过MapReduce进行数据预处理,可以显著减少数据量,并完成初步的数据清洗和过滤。在Hive中进行大数据分析时,通过编写复杂的SQL查询语句,我们能够迅速获取所需数据,并对其进行深度统计分析。

本研究的网络流量分析系统能够快速、准确地获取网络流量的关键指标,帮助企业更好地了解用户行为,从而优化网络运营策略,提升用户体验。此外,本项目的数据导出和可视化功能,为用户提供了更加便捷、直观的数据展示方式,使得分析结果更易于理解和应用。

综上所述,本项目展示了一种基于Hadoop的高效、精确的网络流量分析方法,为企业决策和网络运营提供了强有力的数据支持。


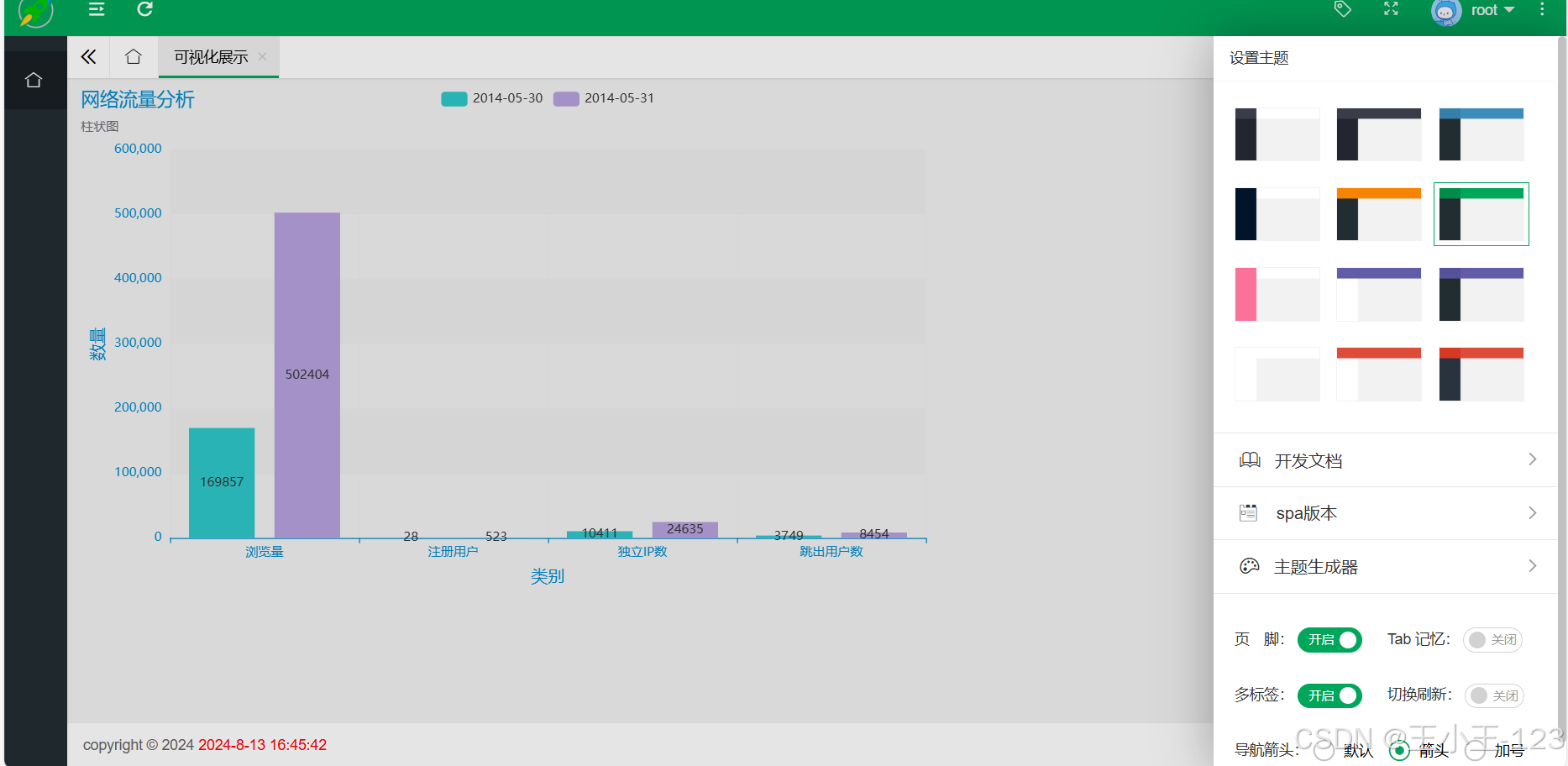
随着互联网的飞速发展,网络流量的规模和复杂性不断增加。无论是电商平台、社交媒体,还是各类在线服务,海量的数据不断生成,如何有效地分析和利用这些数据成为企业提升竞争力的关键。网络流量分析不仅能够帮助企业了解用户行为和偏好,还能及时发现潜在的网络安全威胁,优化网络资源的配置,提高用户体验。因此,网络流量分析系统在当今的数字化时代显得尤为重要。
后续的内容可以私信博主获取
每文一语
不断成长