接上文你的新进程是如何被内核调度执行到的?(上)
四、新进程加入调度
进程在 copy_process 创建完毕后,通过调用 wake_up_new_task 将新进程加入到就绪队列中,等待调度器调度。
//file:kernel/fork.c
long do_fork(...)
{
//复制一个 task_struct 出来
struct task_struct *p;
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
//子任务加入到就绪队列中去,等待调度器调度
wake_up_new_task(p);
...
}
今天我们可以来展开看看 wake_up_new_task 执行时具体都发生了什么。新进程是如何加入到 CPU 运行队列 (struct rq)中的,我们来展开详细看看。
//file:kernel/sched/core.c
void wake_up_new_task(struct task_struct *p)
{
//4.1 为进程选择一个合适的CPU
set_task_cpu(p, select_task_rq(p, SD_BALANCE_FORK, 0));
//4.2 将进程添加到活动进程集合
rq = __task_rq_lock(p);
activate_task(rq, p, 0);
...
}
wake_up_new_task 主要做了两件事,一是选择一个合适 CPU,二是将进程添加到所选的 CPU 的任务队列中。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
4.1 选择合适的 CPU 运行队列
前面我们讲到,每个 CPU 核都有一个对应的运行队列 runqueue (struct rq)。所以新进程在加入调度前的第一件事就是选择一个合适的运行队列。然后使用该任务队列中,并等待调度。
要稍微注意的是,在 set_task_cpu(p, select_task_rq(p, SD_BALANCE_FORK, 0)) 这一行代码中包含对两个函数的调用。
-
select_task_rq 是选择一个合适的 CPU(运行队列)
-
set_task_cpu 是使用选择好的 CPU
在讲选择运行队列之前,我们先简单回顾一下 CPU 里的缓存。

CPU 同一个物理核上的两个逻辑核是共享一组 L1 和 L2 缓存的。整颗物理 CPU 上所有的核心共享同一组 L3。每一级 Cache 的访问耗时都差别非常大,L1 大约是 1 ns 多一些,L2 大约是 2 ns 多,L3 大约 4 - 8 ns。而内存耗时在最坏的随机 IO 情况下可以达到 30 多 ns。
了解了 CPU 的物理结构以及各级缓存的性能差异,你就大概能弄明白选择 CPU 的核心目的了。CPU 调度是在缓存性能和空闲核心两个点之间做权衡。同等条件下会尽量优先考虑缓存命中率,选择同 L1/L2 的核,其次会选择同一个物理 CPU 上的(共享 L3),最坏情况下去选择另外一个物理 CPU 上的核心。
选择运行队列 select_task_rq 这个函数有点复杂。但是理解了上面这个逻辑后,相信你理解起来就会容易很多。
//file:kernel/sched/core.c
static inline
int select_task_rq(struct task_struct *p, int sd_flags, int wake_flags)
{
int cpu = p->sched_class->select_task_rq(p, sd_flags, wake_flags);
...
return cpu;
}
在本文的第三节中我们提到了 fork 出来的新进程的 sched_class 使用的是公平调度器 fair_sched_class,回忆一下这个结构体的定义。
//file:kernel/sched/fair.c
const struct sched_class fair_sched_class = {
...
.select_task_rq = select_task_rq_fair,
.migrate_task_rq = migrate_task_rq_fair,
...
}
所以上面的 p->sched_class->select_task_rq 这一句实际是进入到了 fair_sched_class 的 select_task_rq_fair 方法里,通过公平调度器实现的选择任务队列的来选择的。
//file:kernel/sched/fair.c
static int
select_task_rq_fair(struct task_struct *p, int sd_flag, int wake_flags)
{
// 当前 CPU
int cpu = smp_processor_id();
// 上一次执行的 CPU
int prev_cpu = task_cpu(p);
// 快速路径选择
new_cpu = select_idle_sibling(p, prev_cpu);
goto unlock;
// 慢速路径选择
group = find_idlest_group(sd, p, cpu, load_idx);
new_cpu = find_idlest_cpu(group, p, cpu);
.......
}
为了方便你理解,我把 select_task_rq_fair 源码精简处理后,只留下了关键逻辑。这个函数一开始就获得了当前 CPU(创建新进程的进程所使用的 CPU)和上一次运行的 CPU(新进程暂时还没有)。接下来就是两个关键逻辑:一是快速路径选择,二是慢速路径选择。
在快速路径选择中,主要的策略就是考虑共享 cache 且 idle 的 CPU。优先选择任务上一次运行的CPU,其次是唤醒任务的 CPU。总之就是尽量考虑 cache 性能。
如果快速路径没选到,那就进入慢速路径。首选选出负载最小的组(find_idlest_group),然后再从该组中选出最空闲的 CPU(find_idlest_cpu)。
当进入到慢速路径以后,会导致进程下一次执行的时候跑的别的核、甚至是别的物理 CPU 上,这样以前跑热的 L1、L2、L3 就都失效了。用户进程过多地发生这种漂移会对性能造成影响。当然内核在极力地避免。如果你想强行干掉漂移,可以试试 taskset 命令。
至于 set_task_cpu 的逻辑比较简单,主要就是把选到的 CPU 设置到新创建出来的进程 task_struct 上。
4.2 将进程添加到活动进程集合
在选择完 CPU 后,下一步就是将新创建出来的进程添加到该 CPU 对应的运行队列 (struct rq) 中。
//file:kernel/sched/core.c
void wake_up_new_task(struct task_struct *p)
{
//4.1 为进程选择一个合适的CPU
set_task_cpu(p, select_task_rq(p, SD_BALANCE_FORK, 0));
//4.2 将进程添加到活动进程集合
rq = __task_rq_lock(p);
activate_task(rq, p, 0);
...
}
经过 set_task_cpu 设置后,新进程taskstruct 指针 p 上已经记录了下一次要使用的 CPU 号。调用 __task_rq_lock 函数的作用就是将新进程 p 要使用的 CPU 的运行队列 struct rq 给找出来,并给它加个锁防止冲突。
接着调用 activate_task 将新进程添加到该 CPU 运行队列中去。

来查看其源码。
//file: kernel/sched/core.c
void activate_task(struct rq *rq, struct task_struct *p, int flags)
{
......
enqueue_task(rq, p, flags);
}
static void enqueue_task(struct rq *rq, struct task_struct *p, int flags)
{
......
p->sched_class->enqueue_task(rq, p, flags);
}
回忆完全公平调度器 fair_sched_class 对象。
//file:kernel/sched/fair.c
const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
...
.select_task_rq = select_task_rq_fair,
.migrate_task_rq = migrate_task_rq_fair,
...
}
可见 p->sched_class->enqueue_task 实际调用的是 enqueue_task_fair。经过 enqueue_task_fair => enqueue_entity ==> __enqueue_entity,最终插入到红黑树中等待调度。
//file:kernel/sched/fair.c
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
struct rb_node **link = &cfs_rq->tasks_timeline.rb_node;
struct rb_node *parent = NULL;
...
//插入到红黑树中
rb_insert_color(&se->run_node, &cfs_rq->tasks_timeline);
}
五、调度时机
前面我们讲述的过程全部是新进程创建发生的事情,新进程还没有真正被调度。触发调度器开始选择进程并上 CPU 开始运行的时机有很多。我们就以咱们前面文章讲过的同步阻塞时机为例。
在同步阻塞网络编程模型下,如果 socket 上没有收到数据,或者收到不足够多,则调用 sk_wait_data 把当前进程阻塞掉,让出 CPU 并调度运行队列中的其它进程进行。
我们现在假设就有某一个进程发生了这样的阻塞。sk_wait_data 依次会调用 sk_wait_event、schedule_timeout,然后到达调度的核心函数 schedule。我们来看看它的核心实现 __schedule。
//file: kernel/sched/core.c
static void __sched __schedule(void)
{
......
//取出当前 CPU 及其任务队列
cpu = smp_processor_id();
rq = cpu_rq(cpu);
//5.1 获取下一个待执行任务
next = pick_next_task(rq);
//5.2 执行上下文切换到新进程上
context_switch(rq, prev, next);
......
}
在这个函数中把当前 CPU 的任务队列取了出来,接着获取下一个待运行的任务,再执行上下文切换到新进程上来运行。接下来我们分两个小节单独来看下。
5.1 获取下一个待执行任务
是如何获取下一个待执行任务的呢?我们来看下 pick_next_task 的实现。
//file: kernel/sched/core.c
static inline struct task_struct *
pick_next_task(struct rq *rq)
{
p = fair_sched_class.pick_next_task(rq);
...
}
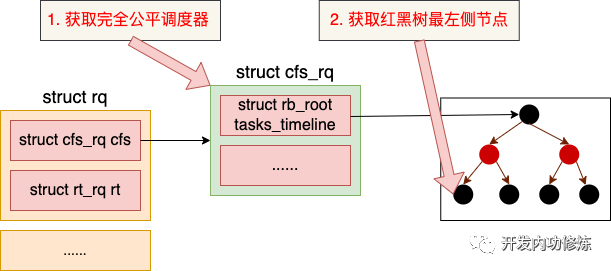
因为大部分都是普通进程,所以大概率会执行到 fair_sched_class.pick_next_task 函数中,也就是 pick_next_task_fair 函数中。该函数其实就是从当前任务队列的红黑树节点将运行虚拟时间最小的节点(最左侧的节点)选出来而已。

//file: kernel/sched/fair.c
static struct task_struct *pick_next_task_fair(struct rq *rq)
{
//获取完全公平调取器
struct cfs_rq *cfs_rq = &rq->cfs;
//从完全公平调取器红黑树中选择一个进程
se = pick_next_entity(cfs_rq);
...
}
这样,下一个待运行的进程就被选出来了。
5.2 执行上下文切换到新进程上
选出来待运行的新进程以后,接着就需要执行进程上下文切换,把新进程的运行状态给切换上来。
//file:kernel/sched/core.c
static inline void
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
//准备新旧两个进程的地址空间
struct mm_struct *mm, *oldmm;
mm = next->mm;
oldmm = prev->active_mm;
//执行地址空间切换
switch_mm(oldmm, mm, next);
//执行栈和寄存器切换
switch_to(prev, next, prev);
......
}
当前进程上下文切换完成的时候,新进程终于可以得以运行了!
六、总结
好了,我们把今天的文章的内容总结一下。
一个进程从 fork 创建出来到最后真正能获得 CPU 并进行运行,中间有很多的内核逻辑需要处理,我把它分成了这么几个步骤供你更容易地理解。
第一,每个 CPU 核都有一个运行队列。为了支持不同的调度需求,运行队列是由实时调度器、完全公平调取器等多种调度器组成。

第一,是进程在 fork 的时候会选择自己的调取器,用户进程一般都是用完全公平调度器(fair_sched_class)。
第二,进程创建完前会综合考虑缓存友好性以及空闲状况,选择一个 CPU 运行队列出来,并将新进程添加到该队列中。
第三,内核有很多的时机来触发调度。我们文中举了同步阻塞网络 IO 放弃 CPU 时调取新进程运行的例子。在放弃 CPU 前会从当前 CPU 的运行队列获取一个进程出来,上下文切换后运行之。
我们再回到开篇的问题:
问题一:进程不主动释放 CPU 的话,每次调度最少能运行多久?
在完全公平调度器中,出于减少频繁切换进程所带来的成本考虑,一个进程一旦被分配到 CPU 就会持续运行相对较长的一段时间,避免频繁的进程上下文切换导致的性能损耗。这段时间的最小值由 sched_min_granularity_ns 这个内核参数来控制,单位是 ns (纳秒) 。例如下面这个配置的最短运行时间是 10 ms。
# sysctl -a | grep min_granularity
kernel.sched_min_granularity_ns = 10000000
当然了,如果进程因为等待网络、磁盘等资源时主动放弃 CPU 那另算。
问题二:进程的 nice 值代表的是优先级吗,高优先级是否能抢占低优先级的 CPU ?
在实时任务如 migration 内核线程中,是按优先级调度的。优先级强调的是抢占,高优先级比低优先级有优先获得 CPU 的权利。
但是对于用户进程来讲,一般都采用的完全公平调度器来进行 CPU 资源的分配。在这种调取器中,其 nice 其实是一个权重的概念。权重高的进程获得的 CPU 比例会相对高一些。但不是实时抢占。









![[附源码]java毕业设计社区生鲜仓库管理系统](https://img-blog.csdnimg.cn/37d2bc34298f4ffe8b61d18d1d188d9e.png)