note
- 关于图深度学习算法的简单回顾:
- 一开始是经典的word2vec(以skip-gram为例,先取周围词随机初始化的embedding,进行平均池化后与中心词embedding进行点积)通过周围词预测中心词(多分类任务),不断迭代得到每个词embedding;
- deepwalk随机游走生成节点序列,然后还是用w2v生成embedding;而Node2vec仅是多了控制游走方向的参数;
- GCN:基础公式为 H l + 1 = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H l w l ) \boldsymbol{H}^{l+1}=\sigma\left(\widetilde{\boldsymbol{D}}{ }^{-\frac{1}{2}} \widetilde{\boldsymbol{A}} \widetilde{\boldsymbol{D}}^{-\frac{1}{2}} \boldsymbol{H}^l \boldsymbol{w}^l\right) Hl+1=σ(D −21A D −21Hlwl),学习 w l {w}^l wl参数,其中用自连邻接矩阵A撇是为了防止在邻接矩阵中无法区分”自身节点“和”无连接节点“;然后通过消息传递(如sum pooling操作)得到下一层节点embedding。
- 图采样GraphSAGE:由于图结构数据中,节点与节点之间有依赖关系,所以不能像普通深度学习一样进行循环小批量训练,GraphSAGE通过小批量采样原有大图的子图高效训练;类似的PinSAGE也是铜鼓哦随机游走经过的高频节点生成子图。
- SR-GNN是中科院提出的一种基于会话序列建模的推荐系统,首次将GNN应用于会话推荐。
- 会话是指用户的交互过(每个会话表示一次用户行为和对应的服务,所以每个用户记录都会构建成一张图),会话序列是专门表示一个用户过往一段时间的交互序列。 一般是指用户在30min内的点击浏览行为,作为一个会话。
- SR-GNN利用了Attention机制来获取序列中每一个Item对于序列中最后一个Item v n ( s 1 ) v_n\left(s_1\right) vn(s1) 的attention score, 然后将其加权求和。
- 基于会话的推荐是以往比较常用的一种推荐方式,包括循环神经网络、马尔科夫链等。两个缺点:
- 当一个会话中用户的行为数量稀疏时,这种方法较难捕获用户的行为表示。
- 物品之前的转移模式在会话推荐中是十分重要的特征,但RNN和马尔科夫过程只对相邻的两个物品的单项转移向量进行建模,而忽略了会话中其他的物品。
- 一般来说序列召回输入的是用户的行为序列(用户交互过的item id的列表),需要预测的是用户下一个时刻可能点击的top-k个item。两个步骤:
- 把用户的行为序列抽取成一个用户的表征向量;
- 然后和Item的向量通过一些ANN的方法来进行快速的检索,从而筛选出和用户表征向量最相似的top-k个Item。
| GRU4rec | SRGNN |
|---|---|
| 序列模型,只考虑上一节点到当前节点的过渡关系 | 图模型,考虑更复杂的过渡关系,包括若干出点和入点与当前节点的联系 |
| 仅考虑用户的当前兴趣 | 使用Attention机制,考虑用户的当前兴趣和整体兴趣 |
| 循环次数由序列长度决定 | 循环次数是个超参,SRGNN默认为1 |
| 有负采样,pairwise loss(BPR、TOP1) | 没有负采样,pointwise loss(NLL) |
| minibatch,代码比较复杂 | data augmentation,实现比较简单(但序列长度较长时不适用于RNN) |
文章目录
- note
- 一、论文解读
- 1.0 Session-based推荐
- 1.1 论文核心方法
- 1.2 构建Session Graph
- 1.3 通过GNN学习Item的向量表征
- 1.4 生成User向量表征
- 二、代码实践
- 2.1 继承Dataset类的SequenceDataset
- 2.2 SR-GNN模型定义
- 2.3 其他部分
- 时间安排
- Reference
一、论文解读

论文链接:https://arxiv.org/abs/1811.00855
1.0 Session-based推荐
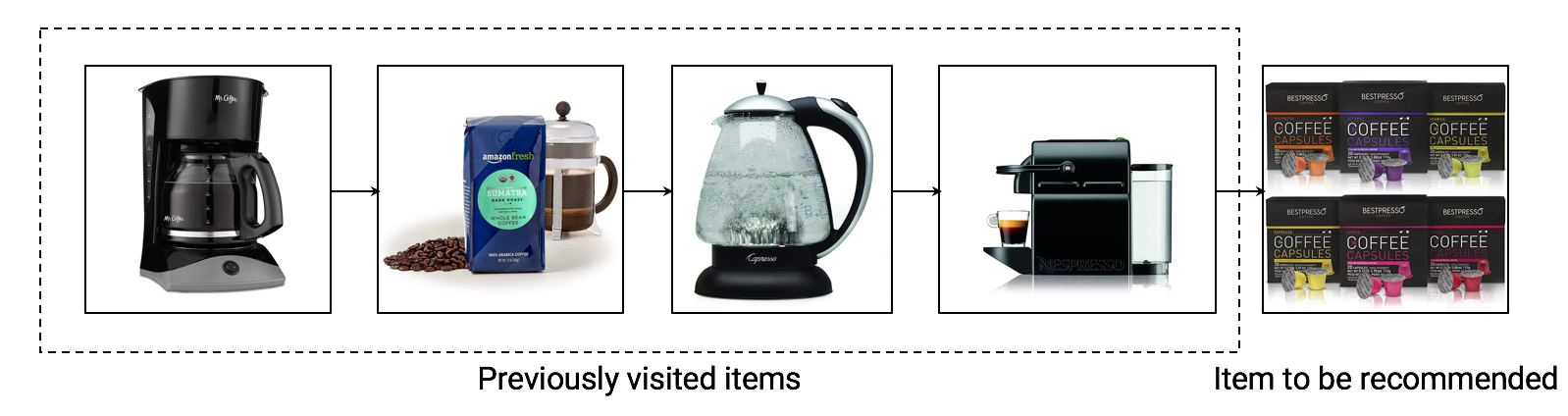
1.1 论文核心方法
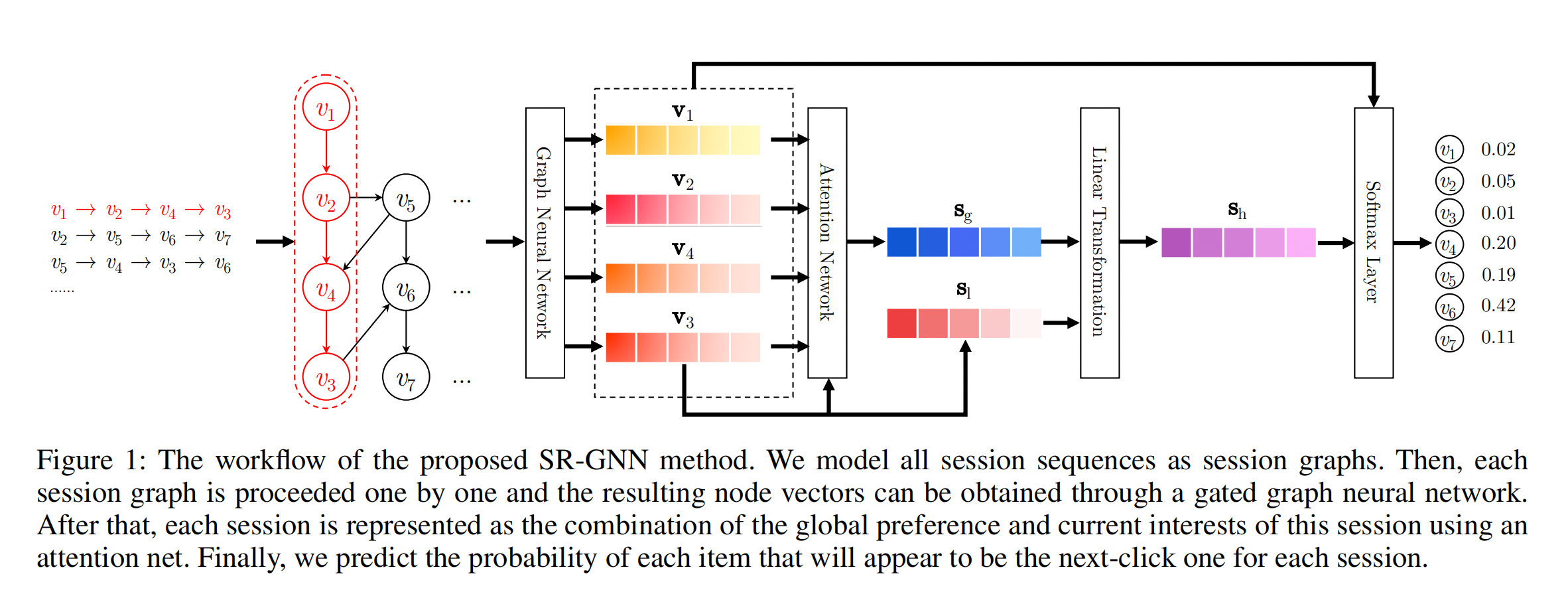
对输入的用户的行为序列提取出用户的向量表征进行了如下的处理:
- 将用户的行为序列构造成 Session Graph
- 通过GNN来对所得的 Session Graph进行特征提取,得到每一个Item的向量表征
- 在经过GNN提取Session Graph之后,我们需要对所有的Item的向量表征进行融合,以此得到User的向量表征,在得到了用户的向量表征之后,我们就可以按照序列召回的思路来进行模型训练/模型验证了。
1.2 构建Session Graph
首先需要根据用户的行为序列来进行构图, 这里是针对每一条用户的行为序列都需要构建一张图, 构图的方法也非常简单, 我们这里将其视作是有向图, 如果
v
2
v_2
v2 和
v
1
v_1
v1 在用户的行为序列里面是相邻的, 并且
v
2
v_2
v2 在
v
1
v_1
v1 之后, 则我们连出一条从
v
2
v_2
v2 到
v
1
v_1
v1 的边, 按照这个规则我们可以构建出一张图。 (下面是论文中给的样例图)。

在完成构图之后, 我们需要使用变量来存储这张图, 这里用
A
s
A_s
As来表示构图的结果, 这个矩阵是一个
(
d
,
2
d
)
(d, 2 d)
(d,2d) 的矩阵, 其分为一个
(
d
,
d
)
(d, d)
(d,d) 的 Outing矩阵和一个
(
d
,
d
)
(d, d)
(d,d) 的Incoming矩阵对于Outing矩阵,直接去数节点向外伸出去的边的条数,如果节点向外伸出的节点数大于 1 , 则进行归一化操作 (例如节点
v
2
v_2
v2 向外伸出了两个节点
v
3
,
v
4
v_3, v_4
v3,v4 ,则节点
v
2
v_2
v2 到节点
v
3
,
v
4
v_3, v_4
v3,v4 的值都为
0.5
)
\left.0.5\right)
0.5) 。Incoming矩阵同理。

在搞GNN经常使用networkx对一些边集生成有向图:
import networkx as nx
import matplotlib.pyplot as plt
edges = [(1, 2), (1, 5), (2, 4), (4, 3), (3, 1)]
# 1. 初始化有向图
G = nx.DiGraph()
# 2. 通过边集加载数据
G.add_edges_from(edges)
# 3. 打印所有节点
print(G.nodes)
# 4. 打印所有边
print(G.edges)
# 5. 画图
nx.draw(G)
# 6.显示
plt.show()

1.3 通过GNN学习Item的向量表征
如何从图中学习到Item的向量表征:
- 这里设 v i t v_i^t vit 表示在第 x \mathrm{x} x 次GNN迭代后的item i的向量表征;
- A s , i ∈ R 1 × 2 n A_{s, i} \in R^{1 \times 2 n} As,i∈R1×2n 表示 A s A_s As 矩阵中的 第 i i i 行, 即代表着第 i i i 个item的相关邻居信息。
则我们这里通过公式(1)来对其邻居信息进行聚合, 这里主要通过矩阵
A
s
,
i
A_{s, i}
As,i 和用户的序列
[
v
1
t
−
1
,
…
,
v
n
t
−
1
]
T
∈
R
n
×
d
\left[v_1^{t-1}, \ldots, v_n^{t-1}\right]^T \in R^{n \times d}
[v1t−1,…,vnt−1]T∈Rn×d 的乘法进行聚合的, 不过要注意这里的公式写的不太严谨, 实际情况下两个
R
1
×
2
n
R^{1 \times 2 n}
R1×2n 和
R
n
×
d
R^{n \times d}
Rn×d 的矩阵是无法直接做乘法的,在代码实现中,是将矩阵 A分为in和out两个矩阵分别和用户的行为序列进行乘积的。
a
s
,
i
t
=
A
s
,
i
[
v
1
t
−
1
,
…
,
v
n
t
−
1
]
T
H
+
b
(1)
a_{s, i}^t=A_{s, i}\left[v_1^{t-1}, \ldots, v_n^{t-1}\right]^T \mathbf{H}+b \tag{1}
as,it=As,i[v1t−1,…,vnt−1]TH+b(1)
'''
A : [batch,n,2n] 图的矩阵
hidden : [batch,n,d] 用户序列的emb
in矩阵:A[:, :, :A.size(1)]
out矩阵:A[:, :, A.size(1):2 * A.size(1)]
inputs : 就是公式1中的 a
'''
input_in = paddle.matmul(A[:, :, :A.shape[1]], self.linear_edge_in(hidden)) + self.b_iah
input_out = paddle.matmul(A[:, :, A.shape[1]:], self.linear_edge_out(hidden)) + self.b_ioh
# [batch_size, max_session_len, embedding_size * 2]
inputs = paddle.concat([input_in, input_out], 2)
在得到公式(1)中的
a
s
,
i
t
a_{s, i}^t
as,it 之后, 根据公式(2)(3)计算出两个中间变量
z
s
,
i
t
,
r
s
,
i
t
z_{s, i}^t, r_{s, i}^t
zs,it,rs,it 可以简单的类比LSTM, 认为
z
s
,
i
t
,
r
s
,
i
t
z_{s, i}^t, r_{s, i}^t
zs,it,rs,it 分别是遗忘门和更新门。
z
s
,
i
t
=
σ
(
W
z
a
s
,
i
t
+
U
z
v
i
t
−
1
)
∈
R
d
(2)
z_{s, i}^t=\sigma\left(W_z a_{s, i}^t+U_z v_i^{t-1}\right) \in R^d \tag{2}
zs,it=σ(Wzas,it+Uzvit−1)∈Rd(2)
r
s
,
i
t
=
σ
(
W
r
a
s
,
i
t
+
U
r
v
i
t
−
1
)
∈
R
d
(3)
r_{s, i}^t=\sigma\left(W_r a_{s, i}^t+U_r v_i^{t-1}\right) \in R^d \tag{3}
rs,it=σ(Wras,it+Urvit−1)∈Rd(3)
注意:我们在计算
z
s
,
i
t
,
r
s
,
i
t
z_{s, i}^t, r_{s, i}^t
zs,it,rs,it 的逻辑是完全一样的, 唯一的区别就是用了不同的参数权重而已. 在得到公式(2)(3)的中间变量之后,我们通过公式(4)计算出更新门下一步更新的特征, 以及根据公式(5)来得出最终结果
v
i
t
∼
=
tanh
(
W
o
a
s
,
i
t
+
U
o
(
r
s
,
i
t
⊙
v
i
t
−
1
)
)
∈
R
d
(4)
\begin{gathered} v_i^{t^{\sim}}=\tanh \left(W_o a_{s, i}^t+U_o\left(r_{s, i}^t \odot v_i^{t-1}\right)\right) \in R^d \tag{4} \end{gathered}
vit∼=tanh(Woas,it+Uo(rs,it⊙vit−1))∈Rd(4)
v i t = ( 1 − z s , i t ) ⊙ v i t − 1 + z s , i t ⊙ v i t ∼ ∈ R d (5) \begin{gathered} v_i^t=\left(1-z_{s, i}^t\right) \odot v_i^{t-1}+z_{s, i}^t \odot v_i^{t^{\sim}} \in R^d \tag{5} \end{gathered} vit=(1−zs,it)⊙vit−1+zs,it⊙vit∼∈Rd(5)
- 公式(4)实际上是计算了在第 x \mathrm{x} x 次 GNN层的时候的Update部分,也就是 v i t ∼ v_i^{t^{\sim}} vit∼ ;
- 在公式(5)中通过遗忘门 z s , i t z_{s, i}^t zs,it 来控制第次GNN更新 时, v i t − 1 v_i^{t-1} vit−1 和 v i t ∼ v_i^{t^{\sim}} vit∼ 所占的比例。这样就完成了 GNN部分的item的表征学习。
- 这里在写代码的时候要注意, 对于公式(3)(4)(5), 我们仔细观察, 对于 a s , i t , v i t − 1 a_{s, i}^t, v_i^{t-1} as,it,vit−1 这两个变量而言, 每个变量都和三个矩阵进行了相乘, 这里的计算逻辑相同, 所以将 W a , U v W a, U v Wa,Uv 当作一次计算单元, 在公式(3)(4)(5)中, 均涉及了一次这样的操作, 所以我们可以将这三次操作放在一起做, 然后在将结果切分为 3 份, 还原三个公式, 相关代码如下:
'''
inputs : 公式(1)中的a
hidden : 用户序列,也就是v^{t-1}
这里的gi就是Wa,gh就是Uv,但是要注意这里不该是gi还是gh都包含了公式3~5的三个部分
'''
# gi.size equals to gh.size, shape of [batch_size, max_session_len, embedding_size * 3]
gi = paddle.matmul(inputs, self.w_ih) + self.b_ih
gh = paddle.matmul(hidden, self.w_hh) + self.b_hh
# (batch_size, max_session_len, embedding_size)
i_r, i_i, i_n = gi.chunk(3, 2) # 三个W*a
h_r, h_i, h_n = gh.chunk(3, 2) # 三个U*v
reset_gate = F.sigmoid(i_r + h_r) #公式(2)
input_gate = F.sigmoid(i_i + h_i) #公式(3)
new_gate = paddle.tanh(i_n + reset_gate * h_n) #公式(4)
hy = (1 - input_gate) * hidden + input_gate * new_gate # 公式(5)
1.4 生成User向量表征
在通过GNN获取了Item的嵌入表征之后,, 剩下的就是讲用户序列的多个Item的嵌入表征融合成一个整体的序列的嵌入表征。
这里SR-GNN首先利用了Attention机制来获取序列中每一个Item对于序列中最后一个Item
v
n
(
s
1
)
v_n\left(s_1\right)
vn(s1) 的attention score, 然后将其加权求和,其具体的计算过程如下
a
i
=
q
T
σ
(
W
1
v
n
+
W
2
v
i
+
c
)
∈
R
1
s
g
=
∑
i
=
1
n
a
i
v
I
∈
R
d
\begin{gathered} a_i=\mathbf{q}^T \sigma\left(W_1 v_n+W_2 v_i+c\right) \in R^1 \\ s_g=\sum_{i=1}^n a_i v_I \in R^d \end{gathered}
ai=qTσ(W1vn+W2vi+c)∈R1sg=i=1∑naivI∈Rd
在得到
s
g
s_g
sg 之后,我们将
s
g
s_g
sg 与序列中的最后一个Item信息相结合,得到最终的序列的嵌入表征:
s
h
=
W
3
[
s
1
;
s
g
]
∈
R
d
s_h=W_3\left[s_1 ; s_g\right] \in R^d
sh=W3[s1;sg]∈Rd
'''
seq_hidden : 序列中每一个item的emb
ht : 序列中最后一个item的emb,就是公式6~7中的v_n(s_1)
q1 : 公式(6)中的 W_1 v_n
q2 : 公式(6)中的 W_2 v_i
alpha : 公式(6)中的alpha
a : 公式(6)中的s_g
'''
seq_hidden = paddle.take_along_axis(hidden,alias_inputs,1)
# fetch the last hidden state of last timestamp
item_seq_len = paddle.sum(mask,axis=1)
ht = self.gather_indexes(seq_hidden, item_seq_len - 1)
q1 = self.linear_one(ht).reshape([ht.shape[0], 1, ht.shape[1]])
q2 = self.linear_two(seq_hidden)
alpha = self.linear_three(F.sigmoid(q1 + q2))
a = paddle.sum(alpha * seq_hidden * mask.reshape([mask.shape[0], -1, 1]), 1)
user_emb = self.linear_transform(paddle.concat([a, ht], axis=1))
二、代码实践
2.1 继承Dataset类的SequenceDataset
这里的hist_mask_list是像transformer一样的mask处理序列长短不一致的问题。
class SeqnenceDataset(Dataset):
def __init__(self, config, df, phase='train'):
self.config = config
self.df = df
self.max_length = self.config['max_length']
self.df = self.df.sort_values(by=['user_id', 'timestamp'])
self.user2item = self.df.groupby('user_id')['item_id'].apply(list).to_dict()
self.user_list = self.df['user_id'].unique()
self.phase = phase
def __len__(self, ):
return len(self.user2item)
def __getitem__(self, index):
if self.phase == 'train':
user_id = self.user_list[index]
item_list = self.user2item[user_id]
hist_item_list = []
hist_mask_list = []
k = random.choice(range(4, len(item_list))) # 从[8,len(item_list))中随机选择一个index
# k = np.random.randint(2,len(item_list))
item_id = item_list[k] # 该index对应的item加入item_id_list
if k >= self.max_length: # 选取seq_len个物品
hist_item_list.append(item_list[k - self.max_length: k])
hist_mask_list.append([1.0] * self.max_length)
else:
hist_item_list.append(item_list[:k] + [0] * (self.max_length - k))
hist_mask_list.append([1.0] * k + [0.0] * (self.max_length - k))
return paddle.to_tensor(hist_item_list).squeeze(0), paddle.to_tensor(hist_mask_list).squeeze(
0), paddle.to_tensor([item_id])
else:
user_id = self.user_list[index]
item_list = self.user2item[user_id]
hist_item_list = []
hist_mask_list = []
k = int(0.8 * len(item_list))
# k = len(item_list)-1
if k >= self.max_length: # 选取seq_len个物品
hist_item_list.append(item_list[k - self.max_length: k])
hist_mask_list.append([1.0] * self.max_length)
else:
hist_item_list.append(item_list[:k] + [0] * (self.max_length - k))
hist_mask_list.append([1.0] * k + [0.0] * (self.max_length - k))
return paddle.to_tensor(hist_item_list).squeeze(0), paddle.to_tensor(hist_mask_list).squeeze(
0), item_list[k:]
def get_test_gd(self):
self.test_gd = {}
for user in self.user2item:
item_list = self.user2item[user]
test_item_index = int(0.8 * len(item_list))
self.test_gd[user] = item_list[test_item_index:]
return self.test_gd
2.2 SR-GNN模型定义

class GNN(nn.Layer):
def __init__(self, embedding_size, step=1):
super(GNN, self).__init__()
self.step = step
self.embedding_size = embedding_size
self.input_size = embedding_size * 2
self.gate_size = embedding_size * 3
self.w_ih = self.create_parameter(shape=[self.input_size, self.gate_size])
self.w_hh = self.create_parameter(shape=[self.embedding_size, self.gate_size])
self.b_ih = self.create_parameter(shape=[self.gate_size])
self.b_hh = self.create_parameter(shape=[self.gate_size])
self.b_iah = self.create_parameter(shape=[self.embedding_size])
self.b_ioh = self.create_parameter(shape=[self.embedding_size])
self.linear_edge_in = nn.Linear(self.embedding_size, self.embedding_size)
self.linear_edge_out = nn.Linear(self.embedding_size, self.embedding_size)
def GNNCell(self, A, hidden):
input_in = paddle.matmul(A[:, :, :A.shape[1]], self.linear_edge_in(hidden)) + self.b_iah
input_out = paddle.matmul(A[:, :, A.shape[1]:], self.linear_edge_out(hidden)) + self.b_ioh
# [batch_size, max_session_len, embedding_size * 2]
inputs = paddle.concat([input_in, input_out], 2)
# gi.size equals to gh.size, shape of [batch_size, max_session_len, embedding_size * 3]
gi = paddle.matmul(inputs, self.w_ih) + self.b_ih
gh = paddle.matmul(hidden, self.w_hh) + self.b_hh
# (batch_size, max_session_len, embedding_size)
i_r, i_i, i_n = gi.chunk(3, 2)
h_r, h_i, h_n = gh.chunk(3, 2)
reset_gate = F.sigmoid(i_r + h_r)
input_gate = F.sigmoid(i_i + h_i)
new_gate = paddle.tanh(i_n + reset_gate * h_n)
hy = (1 - input_gate) * hidden + input_gate * new_gate
return hy
def forward(self, A, hidden):
for i in range(self.step):
hidden = self.GNNCell(A, hidden)
return hidden
SRGNN部分如下,用到上面的GNN Class,同时和之前说的一样,经过attention的
s
g
s_g
sg 与序列中的最后一个Item信息相结合,得到最终的序列的嵌入表征:
s
h
=
W
3
[
s
1
;
s
g
]
∈
R
d
s_h=W_3\left[s_1 ; s_g\right] \in R^d
sh=W3[s1;sg]∈Rd

该user embedding:
s
h
s_h
sh和item embedding内积计算score(如上图所示),使用交叉熵损失函数:
z
^
i
=
s
h
⊤
v
i
.
\hat{\mathbf{z}}_i=\mathbf{s}_{\mathrm{h}}^{\top} \mathbf{v}_i .
z^i=sh⊤vi.
y
^
=
softmax
(
z
^
)
,
\hat{\mathbf{y}}=\operatorname{softmax}(\hat{\mathbf{z}}),
y^=softmax(z^),
对于每个会话图,交叉熵损失函数定义为:
L
(
y
^
)
=
−
∑
i
=
1
m
y
i
log
(
y
^
i
)
+
(
1
−
y
i
)
log
(
1
−
y
^
i
)
\mathcal{L}(\hat{\mathbf{y}})=-\sum_{i=1}^m \mathbf{y}_i \log \left(\hat{\mathbf{y}}_i\right)+\left(1-\mathbf{y}_i\right) \log \left(1-\hat{\mathbf{y}}_i\right)
L(y^)=−i=1∑myilog(y^i)+(1−yi)log(1−y^i)
class SRGNN(nn.Layer):
r"""SRGNN regards the conversation history as a directed graph.
In addition to considering the connection between the item and the adjacent item,
it also considers the connection with other interactive items.
Such as: A example of a session sequence(eg:item1, item2, item3, item2, item4) and the connection matrix A
Outgoing edges:
=== ===== ===== ===== =====
\ 1 2 3 4
=== ===== ===== ===== =====
1 0 1 0 0
2 0 0 1/2 1/2
3 0 1 0 0
4 0 0 0 0
=== ===== ===== ===== =====
Incoming edges:
=== ===== ===== ===== =====
\ 1 2 3 4
=== ===== ===== ===== =====
1 0 0 0 0
2 1/2 0 1/2 0
3 0 1 0 0
4 0 1 0 0
=== ===== ===== ===== =====
"""
def __init__(self, config):
super(SRGNN, self).__init__()
# load parameters info
self.config = config
self.embedding_size = config['embedding_dim']
self.step = config['step']
self.n_items = self.config['n_items']
# define layers and loss
# item embedding
self.item_emb = nn.Embedding(self.n_items, self.embedding_size, padding_idx=0)
# define layers and loss
self.gnn = GNN(self.embedding_size, self.step)
self.linear_one = nn.Linear(self.embedding_size, self.embedding_size)
self.linear_two = nn.Linear(self.embedding_size, self.embedding_size)
self.linear_three = nn.Linear(self.embedding_size, 1, bias_attr=False)
self.linear_transform = nn.Linear(self.embedding_size * 2, self.embedding_size)
self.loss_fun = nn.CrossEntropyLoss()
# parameters initialization
self.reset_parameters()
def gather_indexes(self, output, gather_index):
"""Gathers the vectors at the specific positions over a minibatch"""
# gather_index = gather_index.view(-1, 1, 1).expand(-1, -1, output.shape[-1])
gather_index = gather_index.reshape([-1, 1, 1])
gather_index = paddle.repeat_interleave(gather_index,output.shape[-1],2)
output_tensor = paddle.take_along_axis(output, gather_index, 1)
return output_tensor.squeeze(1)
def calculate_loss(self,user_emb,pos_item):
all_items = self.item_emb.weight
scores = paddle.matmul(user_emb, all_items.transpose([1, 0]))
return self.loss_fun(scores,pos_item)
def output_items(self):
return self.item_emb.weight
def reset_parameters(self, initializer=None):
for weight in self.parameters():
paddle.nn.initializer.KaimingNormal(weight)
def _get_slice(self, item_seq):
# Mask matrix, shape of [batch_size, max_session_len]
mask = (item_seq>0).astype('int32')
items, n_node, A, alias_inputs = [], [], [], []
max_n_node = item_seq.shape[1]
item_seq = item_seq.cpu().numpy()
for u_input in item_seq:
node = np.unique(u_input)
items.append(node.tolist() + (max_n_node - len(node)) * [0])
u_A = np.zeros((max_n_node, max_n_node))
for i in np.arange(len(u_input) - 1):
if u_input[i + 1] == 0:
break
u = np.where(node == u_input[i])[0][0]
v = np.where(node == u_input[i + 1])[0][0]
u_A[u][v] = 1
u_sum_in = np.sum(u_A, 0)
u_sum_in[np.where(u_sum_in == 0)] = 1
u_A_in = np.divide(u_A, u_sum_in)
u_sum_out = np.sum(u_A, 1)
u_sum_out[np.where(u_sum_out == 0)] = 1
u_A_out = np.divide(u_A.transpose(), u_sum_out)
u_A = np.concatenate([u_A_in, u_A_out]).transpose()
A.append(u_A)
alias_inputs.append([np.where(node == i)[0][0] for i in u_input])
# The relative coordinates of the item node, shape of [batch_size, max_session_len]
alias_inputs = paddle.to_tensor(alias_inputs)
# The connecting matrix, shape of [batch_size, max_session_len, 2 * max_session_len]
A = paddle.to_tensor(A)
# The unique item nodes, shape of [batch_size, max_session_len]
items = paddle.to_tensor(items)
return alias_inputs, A, items, mask
def forward(self, item_seq, mask, item, train=True):
if train:
alias_inputs, A, items, mask = self._get_slice(item_seq)
hidden = self.item_emb(items)
hidden = self.gnn(A, hidden)
alias_inputs = alias_inputs.reshape([-1, alias_inputs.shape[1],1])
alias_inputs = paddle.repeat_interleave(alias_inputs, self.embedding_size, 2)
seq_hidden = paddle.take_along_axis(hidden,alias_inputs,1)
# fetch the last hidden state of last timestamp
item_seq_len = paddle.sum(mask,axis=1)
ht = self.gather_indexes(seq_hidden, item_seq_len - 1)
q1 = self.linear_one(ht).reshape([ht.shape[0], 1, ht.shape[1]])
q2 = self.linear_two(seq_hidden)
# attention机制
alpha = self.linear_three(F.sigmoid(q1 + q2))
a = paddle.sum(alpha * seq_hidden * mask.reshape([mask.shape[0], -1, 1]), 1)
# attention_emb + last_item_emb
user_emb = self.linear_transform(paddle.concat([a, ht], axis=1))
loss = self.calculate_loss(user_emb,item)
output_dict = {
'user_emb': user_emb,
'loss': loss
}
else:
alias_inputs, A, items, mask = self._get_slice(item_seq)
hidden = self.item_emb(items)
hidden = self.gnn(A, hidden)
alias_inputs = alias_inputs.reshape([-1, alias_inputs.shape[1],1])
alias_inputs = paddle.repeat_interleave(alias_inputs, self.embedding_size, 2)
seq_hidden = paddle.take_along_axis(hidden, alias_inputs,1)
# fetch the last hidden state of last timestamp
item_seq_len = paddle.sum(mask, axis=1)
ht = self.gather_indexes(seq_hidden, item_seq_len - 1)
q1 = self.linear_one(ht).reshape([ht.shape[0], 1, ht.shape[1]])
q2 = self.linear_two(seq_hidden)
alpha = self.linear_three(F.sigmoid(q1 + q2))
a = paddle.sum(alpha * seq_hidden * mask.reshape([mask.shape[0], -1, 1]), 1)
user_emb = self.linear_transform(paddle.concat([a, ht], axis=1))
output_dict = {
'user_emb': user_emb,
}
return output_dict

其实如果为了更加方便写GNN,也可以直接使用pyg或dgl框架(GNN模型的GNN layer部分完成message function、aggregation function、update function,如上图),关于pyg的下载需要三个东西:
import os
if 'IS_GRADESCOPE_ENV' not in os.environ:
!pip install torch-scatter -f https://data.pyg.org/whl/torch-1.10.0+cu113.html
!pip install torch-sparse -f https://data.pyg.org/whl/torch-1.10.0+cu113.html
!pip install torch-geometric
2.3 其他部分
Pipeline、基于Faiss的向量召回、基于TSNE的Item Embedding分布可视化,和task2内容相同,略。但是评估指标可以参考如下图,Precision@K和Recall@K的分子都相同(推荐了且用户有交互的item数),但是Precision@K的分母是所有推荐的item数。

时间安排
| 任务信息 | 截止时间 | 完成情况 |
|---|---|---|
| 11月14日周一正式开始 | ||
| Task01:Paddle开发深度学习模型快速入门 | 11月14、15、16日周三 | 完成 |
| Task02:传统序列召回实践:GRU4Rec | 11月17、18、19日周六 | 完成 |
| Task03:GNN在召回中的应用:SR-GNN | 11月20、21、22日周二 | 完成 |
| Task04:多兴趣召回实践:MIND | 11月23、24、25、26日周六 | |
| Task05:多兴趣召回实践:Comirec-DR | 11月27、28日周一 | |
| Task06:多兴趣召回实践:Comirec-SA | 11月29日周二 |
Reference
[1] GNN在召回中的应用:SR-GNN
论文:Session-based Recommendation with Graph Neural Networks
链接:https://arxiv.org/abs/1811.00855
[2] https://arxiv.org/pdf/2106.05081
[3] https://ojs.aaai.org/index.php/AAAI/article/download/3804/3682
[4] https://www.ijcai.org/proceedings/2019/0547.pdf
[5] https://arxiv.org/pdf/2107.03813
[6] https://arxiv.org/pdf/1911.11942.pdf
[7] recbole的序列推荐模型复现
[8] Deep Learning for Matching in Search and Recommendation.李航,何向南
[9] 推荐系统之深度召回模型综述(PART III).NewBeeNLP
[10] 推荐系统总结之深度召回模型(中).一块小蛋糕
[11] 推荐广告搜索zhihu专栏.一块小蛋糕
[12] SR-GNN开源代码
[13] https://github.com/RUCAIBox/RecBole/blob/master/recbole/model/sequential_recommender/srgnn.py
[14] https://sxkdz.github.io/research/SR-GNN/
[15] 图神经网络及其自监督学习.清华AI TIME
[16] SR-GNN代码分析
[17] 图神经网络库 PyTorch Geometric(PYG)
[18] 推荐场景中召回模型的演化过程. 京东大佬
[19] SR-GNN论文解读并附代码分析
[20] 【论文精读】门控图神经网络GGNN及SRGNN
[21] Evaluating A Real-Life Recommender System, Error-Based and Ranking-Based
[22] CS224W助教: Session-based Recommendation Using SR-GNN
[23] CS224W: Machine Learning with Graphs.Stanford / Fall 2021
[24] SRGNN代码注释详细版:userbehavioranalysis/SR-GNN-Chinese_Comment_edition
[25] Recommender Systems with GNNs in PyG







![[附源码]java毕业设计社区空巢老人关爱服务平台](https://img-blog.csdnimg.cn/913996e7bf4c457690aa092fb7a15065.png)

![[计算机毕业设计]知识图谱的检索式对话系统](https://img-blog.csdnimg.cn/632f16aceeee4be6a8443d20fb0be8d8.png)