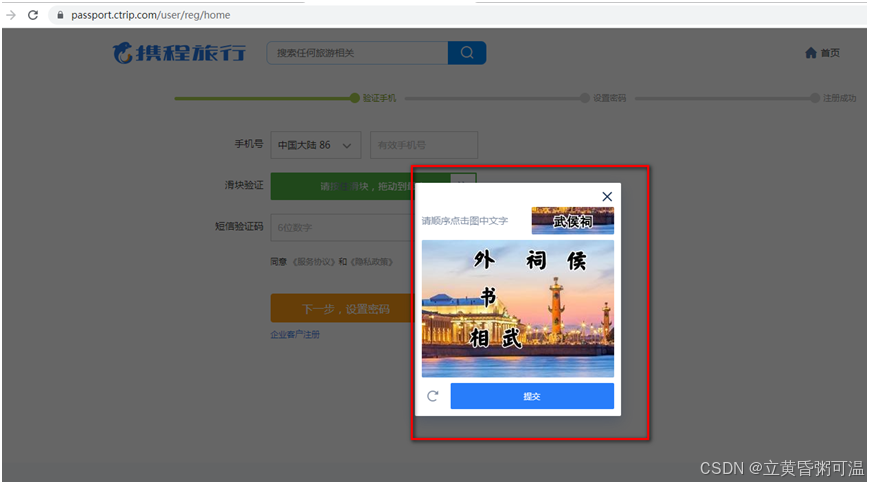
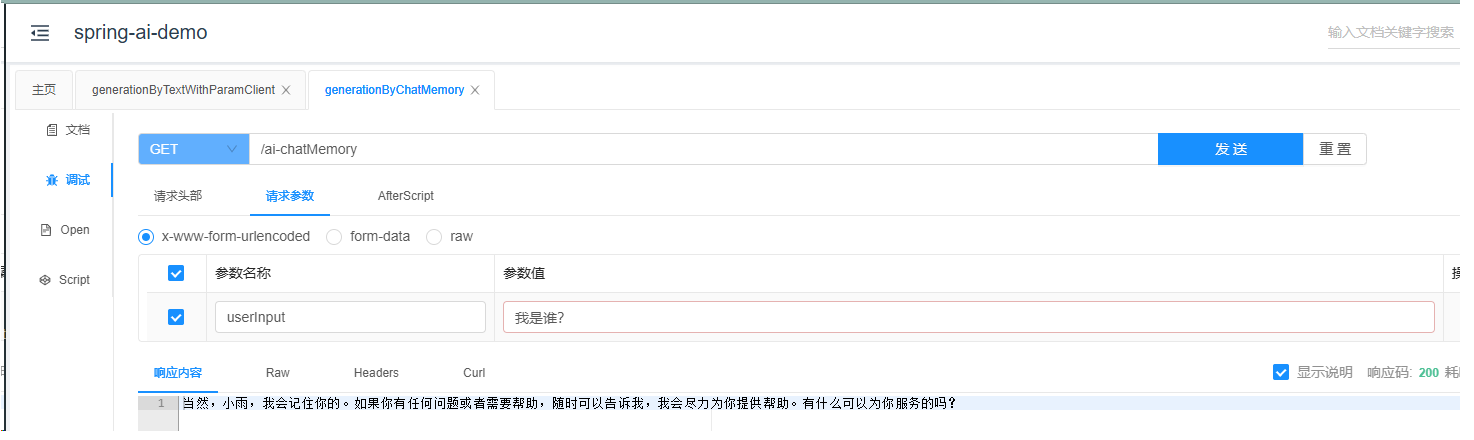
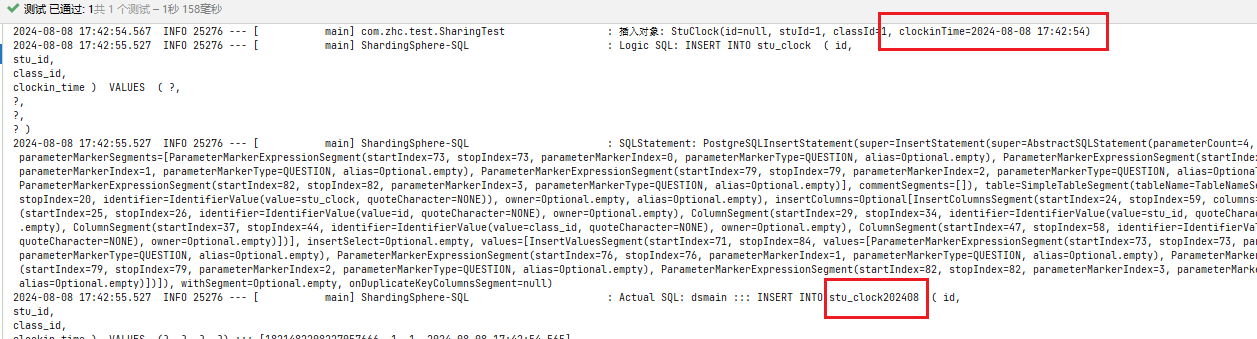
题目
给定一个整数数组nums,请找出数组中第K大的数,保证答案存在。其中,1 <= K <= nums数组长度。
示例 1:
输入:nums = [3, 2, 1, 5, 6, 4], K = 2
输出:5示例 2:
输入:nums = [50, 23, 66, 18, 72], K = 3
输出:50
快速选择算法
快速选择算法的基本思想是:通过一次划分操作,将数组分为两部分,使得一部分的所有元素都小于另一部分的所有元素;如果K正好位于划分点,则我们找到了答案;否则,我们只需要在较小的那一部分中继续寻找。使用快速选择算法求解本题的主要步骤如下。
1、选取一个基准元素pivot。
2、对数组进行划分,使得所有小于pivot的元素都在其左侧,所有大于pivot的元素都在其右侧。
3、根据pivot的位置,决定下一步的操作。
(1)如果pivot的位置正好是K-1,那么pivot就是我们要找的第K大的元素。
(2)如果pivot的位置大于K-1,那么我们需要在左侧子数组中继续查找。
(3)如果pivot的位置小于K-1,那么我们需要在右侧子数组中继续查找。
4、重复上述步骤,直到找到最终答案。
根据上面的算法步骤,我们可以得出下面的示例代码。
def partition(nums, left, right):
# 选择最右边的元素作为基准
pivot = nums[right]
i = left
for j in range(left, right):
if nums[j] < pivot:
nums[i], nums[j] = nums[j], nums[i]
i += 1
nums[i], nums[right] = nums[right], nums[i]
return i
def quickselect(nums, left, right, k):
if left == right:
return nums[left]
pivot_index = partition(nums, left, right)
# 判断基准的位置
if k == pivot_index + 1:
return nums[k - 1]
elif k < pivot_index + 1:
return quickselect(nums, left, pivot_index - 1, k)
else:
return quickselect(nums, pivot_index + 1, right, k)
def find_Kth_largest_element_by_quick_select(nums, k):
# 因为数组索引从0开始,而题目要求的是第k大的数,所以需要转换为第n-k+1小的数
n = len(nums)
return quickselect(nums, 0, n - 1, n - k + 1)
nums = [3, 2, 1, 5, 6, 4]
k = 2
print(find_Kth_largest_element_by_quick_select(nums, k))
nums = [50, 23, 66, 18, 72]
k = 3
print(find_Kth_largest_element_by_quick_select(nums, k))堆排序法
堆排序法的基本思想是:利用最小堆的性质来维护一个大小为K的堆,这样我们就可以在遍历数组的过程中不断更新这个堆,最终堆顶的元素就是我们要找的第K大的数。使用堆排序法求解本题的主要步骤如下。
根据上面的算法步骤,我们可以得出下面的示例代码。
1、导入heapq模块,使用它提供的heappush和heappop函数来操作堆。
2、创建一个大小为K的空堆。
3、遍历数组nums,对于每个元素x,进行以下操作。
(1)如果堆的大小小于K,则直接将x插入堆中。
(2)如果堆的大小等于K且x大于堆顶元素,则弹出堆顶元素,并将x插入堆中。
4、最终,堆顶元素即为第K大的元素。
import heapq
def find_Kth_largest_element_by_min_heap(nums, k):
# 创建一个大小为k的最小堆
min_heap = []
# 遍历数组中的每一个元素
for num in nums:
# 如果堆的大小小于k,则直接插入
if len(min_heap) < k:
heapq.heappush(min_heap, num)
# 如果堆已满并且当前元素比堆顶元素大,则替换堆顶元素
elif num > min_heap[0]:
heapq.heapreplace(min_heap, num)
# 堆顶元素即为第k大的元素
return min_heap[0]
nums = [3, 2, 1, 5, 6, 4]
k = 2
print(find_Kth_largest_element_by_min_heap(nums, k))
nums = [50, 23, 66, 18, 72]
k = 3
print(find_Kth_largest_element_by_min_heap(nums, k))总结
快速选择算法的时间复杂度平均情况下为O(n),最坏情况下(每次选择的基准都是最小或最大值时)为O(n^2)。由于最坏情况下的性能较差,一般需要随机化选择基准来避免最坏情况的发生。堆排序法的时间复杂度为O(n*logK),这是因为每次插入和删除操作的时间复杂度为O(logK),总共有n次操作。
总的来说,快速选择算法适用于大多数情况,特别是在K接近数组长度一半时。它不需要额外的存储空间(除了递归栈),而且通常情况下性能很好。堆排序法更适合于K相对于数组长度较小的情况,因为随着K的增加,性能会逐渐变差。另外,它需要额外的存储空间来维护堆。
💡 如果想阅读最新的文章,或者有技术问题需要交流和沟通,可搜索并关注微信公众号“希望睿智”。