前言
尽管Python最近成为了编程语言的首选,但是Java在人工智能领域的地位同样不可撼动,得益于强大的Spring框架。随着人工智能技术的快速发展,我们正处于一个创新不断涌现的时代。从智能语音助手到复杂的自然语言处理系统,人工智能已经成为了现代生活和工作中不可或缺的一部分。在这样的背景下,Spring AI 项目迎来了发展的机遇。尽管该项目汲取了Python项目如LangChain和LlamaIndex的灵感,但Spring AI并不是简单的移植。该项目的初衷在于推进生成式人工智能应用程序的发展,使其不再局限于Python开发者。
Spring AI 的核心理念是提供高度抽象化的组件,作为开发AI应用程序的基础。这些抽象化组件具备多种实现,使得开发者能够以最少的代码改动便捷地交换和优化功能模块。
具体而言,Spring AI 提供了支持多种主流模型提供商的功能,包括OpenAI、Microsoft、Amazon、Google和Hugging Face。支持的模型类型涵盖了从聊天机器人到文本生成、图像处理、语音识别等多个领域。而其跨模型提供商的可移植API设计,不仅支持同步和流式接口,还提供了针对特定模型功能的灵活选项。
此外,Spring AI 还支持将AI模型输出映射为POJO,以及与主流矢量数据库提供商(如Apache Cassandra、Azure Vector Search、MongoDB Atlas等)无缝集成的能力。其功能不仅局限于模型本身,还包括了数据工程中的ETL框架和各种便利的函数调用,使得开发AI应用程序变得更加高效和可靠。
快速实战
本期实战是我们的第一篇,旨在通过快速展示Spring AI项目,让大家了解它的优点和特性。为了方便大家使用,我还将本期的源代码提交到了仓库中,并加入了swagger-ui的API调用界面,使得使用起来更加便捷。如果你对此感兴趣,欢迎前往查看star。同时,我也会持续维护这个项目,确保它始终保持活跃。
仓库地址:GitHub - StudiousXiaoYu/spring-ai-demo: 专门演示官方spring-ai的各种用法,仅供学习参考~
项目生成
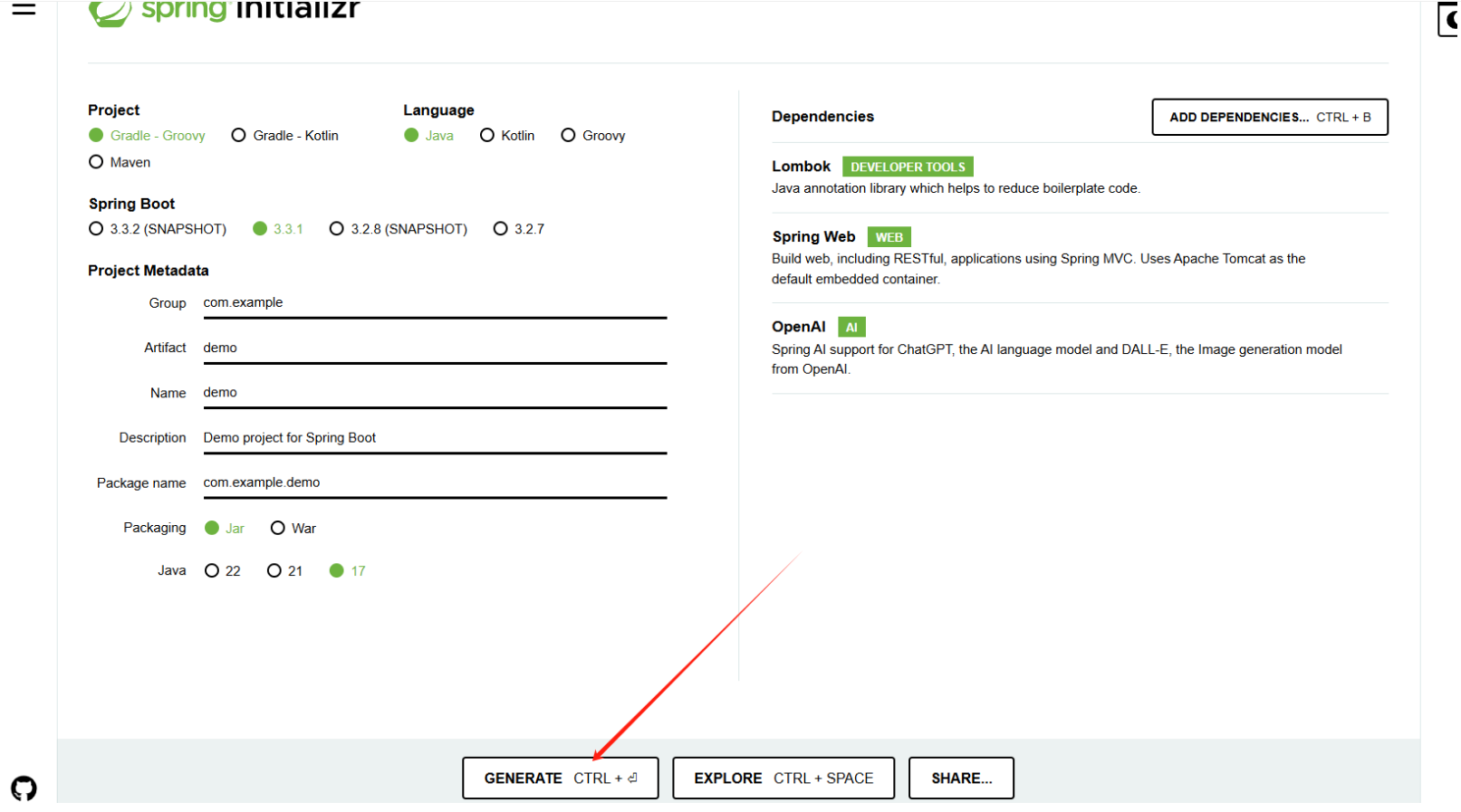
当我们开始时,首先需要创建一个项目结构。我们可以前往官方网站,快速生成Spring AI的依赖并创建项目。
聊天模型
在大型模型中,聊天模型扮演着至关重要的角色。那么,SpringAI是如何对其进行封装的呢?本期主要着重展示如何有效利用Spring AI的ChatClient,特别是在本示例中应用Spring AI的智能聊天模型。
日志级别
在这个过程中,如果想要查看请求的细节日志,务必将日志级别调整至DEBUG,具体操作如下:

模型配置
当我们使用一个模型时,必须首先在项目中加入相关的依赖,加入依赖后还需要在配置文件中填写相应的配置信息。

注入model
那么模型可以自动注入,我们可以直接使用它。在本期演示中,我们将展示三种自定义模型的注入方式,具体如下:
private final ChatClient myChatClientWithSystem;
private final ChatClient myChatClientWithParam;
/**
* 可以选择自动注入、也可以在方法内自定义,此客户端无系统文本
*/
private final ChatClient chatClient;
public MyController(ChatClient.Builder chatClientBuilder, MyChatClientWithSystem myChatClient, MyChatClientWithParam myChatClientWithParam) {
this.chatClient = chatClientBuilder.build();
this.myChatClientWithSystem = myChatClient.client();
this.myChatClientWithParam = myChatClientWithParam.client();
}好的,让我来解释一下这三种情况:
-
chatClient:这是默认的自动注入的ChatClient,不需要任何条件。
-
myChatClientWithParam:这是一个注入系统文本并带有参数的ChatClient。
-
myChatClientWithSystem:这是一个注入带有系统文本的ChatClient。
好的,第一种情况不需要处理,我们只需要通过配置类简单配置下面两种ChatClient。
@Configuration
class Config {
@Bean
MyChatClientWithSystem myChatClientWithSystem(ChatClient.Builder builder) {
MyChatClientWithSystem build = MyChatClientWithSystem.builder()
.client(builder.defaultSystem("你是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。身兼掘金优秀作者、腾讯云内容共创官、阿里云专家博主、华为云云享专家等多重身份。")
.build()).build();
return build;
}
@Bean
MyChatClientWithParam myChatClientWithParam(ChatClient.Builder builder) {
MyChatClientWithParam build = MyChatClientWithParam.builder()
.client(builder.defaultSystem("你是{user}。")
.build()).build();
return build;
}
}简单文本回答
首先,让我们先来讨论一些简单的问答。
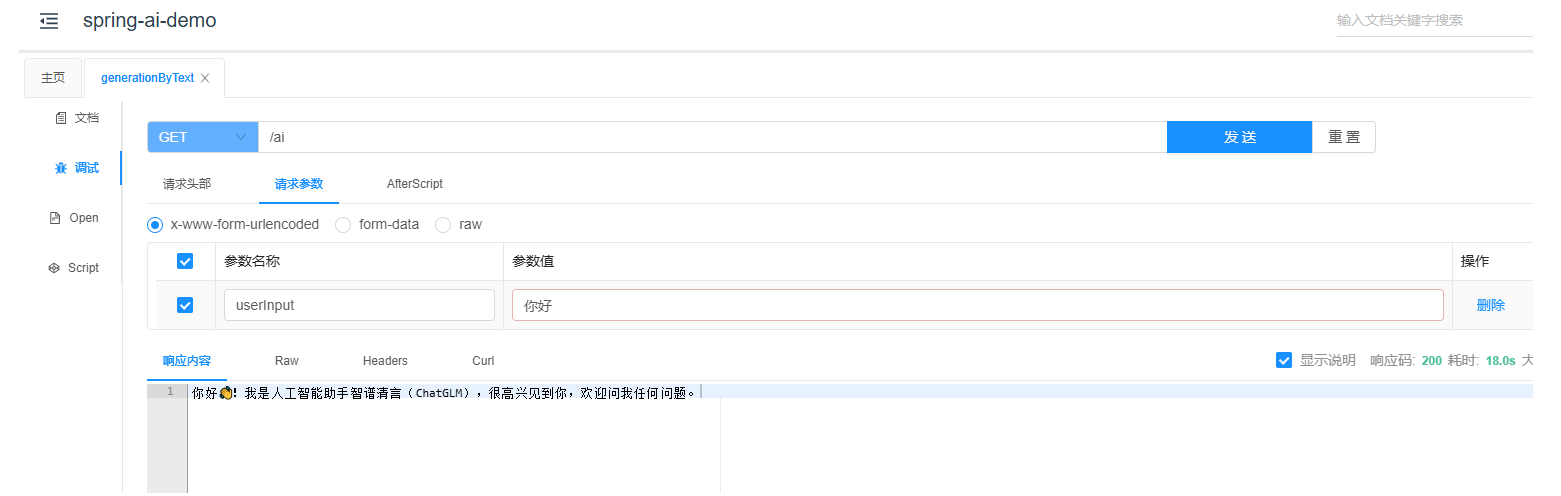
@GetMapping("/ai")
String generationByText(String userInput) {
return this.chatClient.prompt()
.user(userInput)
.call()
.content();
}在这段简练代码中,已经实现了各种封装和交互,为了更好地演示,我们来展示一下:
封装回答实体对象
大家都知道Java是一种面向对象的编程语言,因此在加入人工智能技术时,为了满足业务需求,将对象纳入其中是不可或缺的。那么,如何让人工智能的回答能够被Spring框架自动封装到对象中呢?让我们来探讨一下:
定义一个对象记录类:一个记录类(Record Class)的定义,名为 ActorFilms。用于封装相关字段记录类自动实现了 toString()、equals()、hashCode() 和 getter 方法,使得对象的字符串表示、相等性比较和哈希计算变得简单。你可以直接使用 actorFilms.toString()、actorFilms.equals(anotherActorFilms) 和 actorFilms.hashCode()。
public record ActorFilms(String actor, List<String> movies) {
} @GetMapping("/ai-Entity")
ActorFilms generationByEntity() {
ActorFilms actorFilms = chatClient.prompt()
.user("Generate the filmography for a random actor.")
.call()
.entity(ActorFilms.class);
return actorFilms;
}可以看到,只需简单地将entity设置为ActorFilms。接下来,我们需要检查返回的对象是否符合预期。
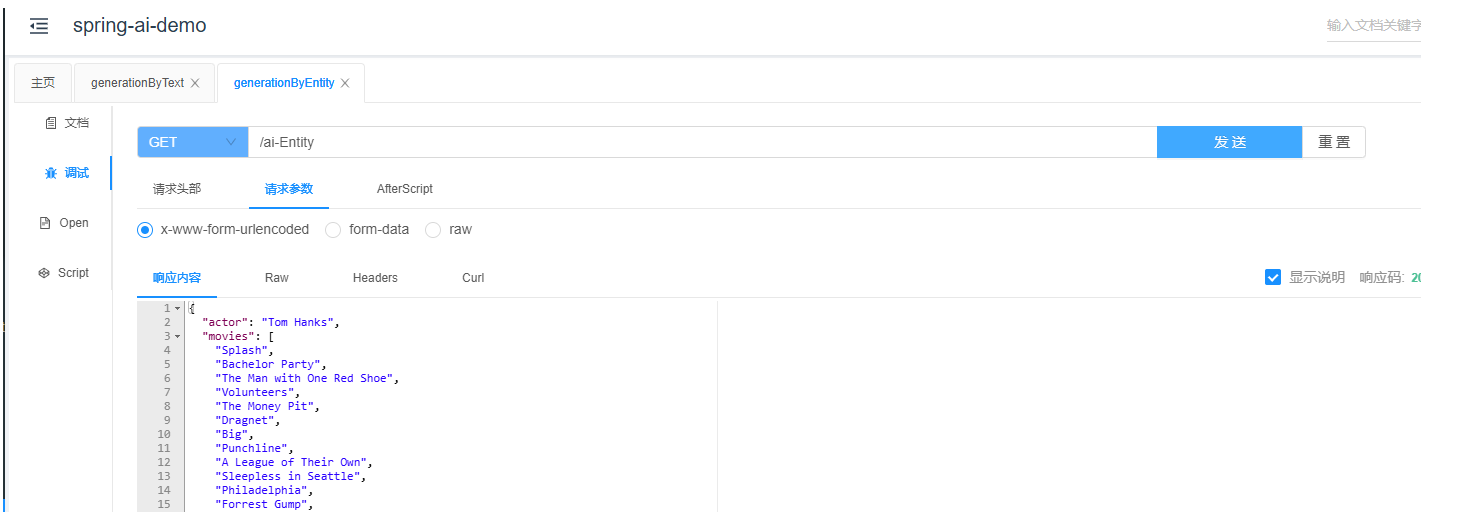
当用户输入信息后,系统返回一个实体类型的回答。这种实体类型的回答之所以能够被封装,是因为在发送信息时,系统不仅仅发送了用户输入的文本,还在其后添加了额外的信息。Generate the filmography for a random actor.\r\nYour response should be in JSON format.\r\nDo not include any explanations, only provide a RFC8259 compliant JSON response following this format without deviation.\r\nDo not include markdown code blocks in your response.\r\nRemove the ```json markdown from the output.\r\nHere is the JSON Schema instance your output must adhere to:\r\n```{\r\n \"$schema\" : \"https://json-schema.org/draft/2020-12/schema\",\r\n \"type\" : \"object\",\r\n \"properties\" : {\r\n \"actor\" : {\r\n \"type\" : \"string\"\r\n },\r\n \"movies\" : {\r\n \"type\" : \"array\",\r\n \"items\" : {\r\n \"type\" : \"string\"\r\n }\r\n }\r\n }\r\n}```\r\n因此,当后续返回的数据为大型模型时,例如{"actor": "Emily Blunt", "movies": ["Edge of Tomorrow", "A Quiet Place", "The Devil Wears Prada", "Sicario", "Mary Poppins Returns"]},这样一来Spring就可以帮我将其自动封装起来了。
封装回答列表实体对象
当我们需要返回一个列表而不是一个对象时,可以轻松地利用Spring AI的封装功能来实现。让我们来看看如何操作:
@GetMapping("/ai-EntityList")
List<ActorFilms> generationByEntityList() {
List<ActorFilms> actorFilms = chatClient.prompt()
.user("Generate the filmography of 5 movies for Tom Hanks and Bill Murray.")
.call()
.entity(new ParameterizedTypeReference<List<ActorFilms>>() {
});
return actorFilms;
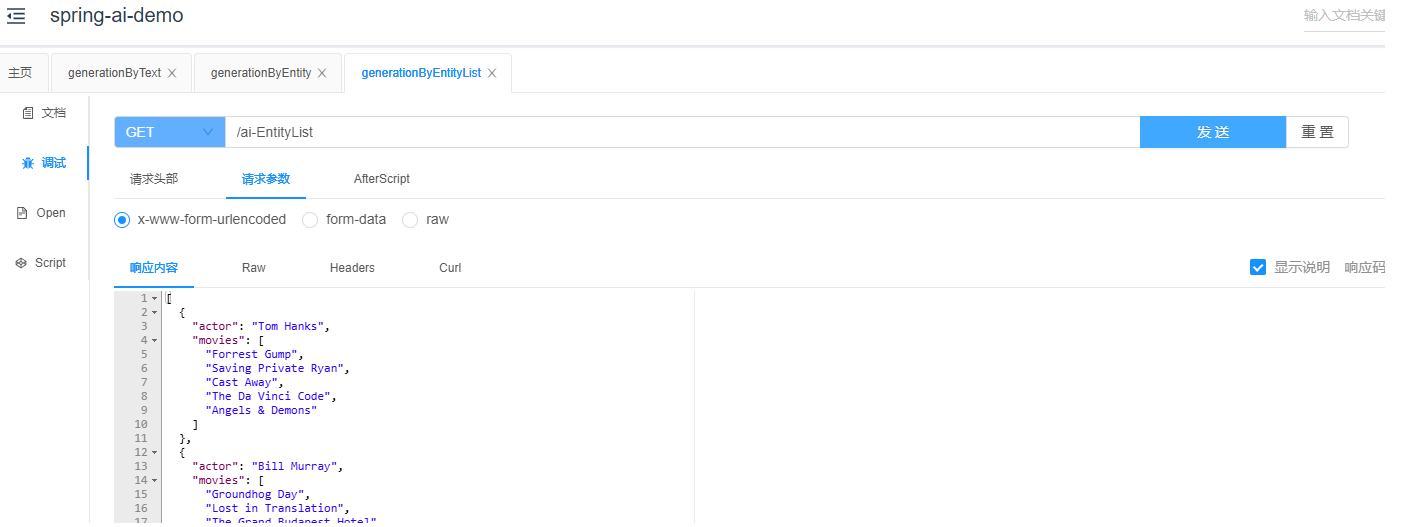
}接使用ParameterizedTypeReference对象即可。为了让Spring能够自动封装返回结果,发送信息时也包含了返回格式信息作为提示。现在我们来查看演示的结果。
流式回答
在前面展示的示例中,大型模型一次性完成回答并将其全部输出给用户。然而,前端无法实现打字机效果,因此我们决定采用流式回答的方式来进行演示。
@GetMapping("/ai-streamWithParam")
Flux<String> generationByStreamWithParam() {
var converter = new BeanOutputConverter<>(new ParameterizedTypeReference<List<ActorFilms>>() {
});
Flux<String> flux = this.chatClient.prompt()
.user(u -> u.text("""
Generate the filmography for a random actor.
{format}
""")
.param("format", converter.getFormat()))
.stream()
.content();
String content = flux.collectList().block().stream().collect(Collectors.joining());
List<ActorFilms> actorFilms = converter.convert(content);
log.info("actorFilms: {}", actorFilms);
return flux;
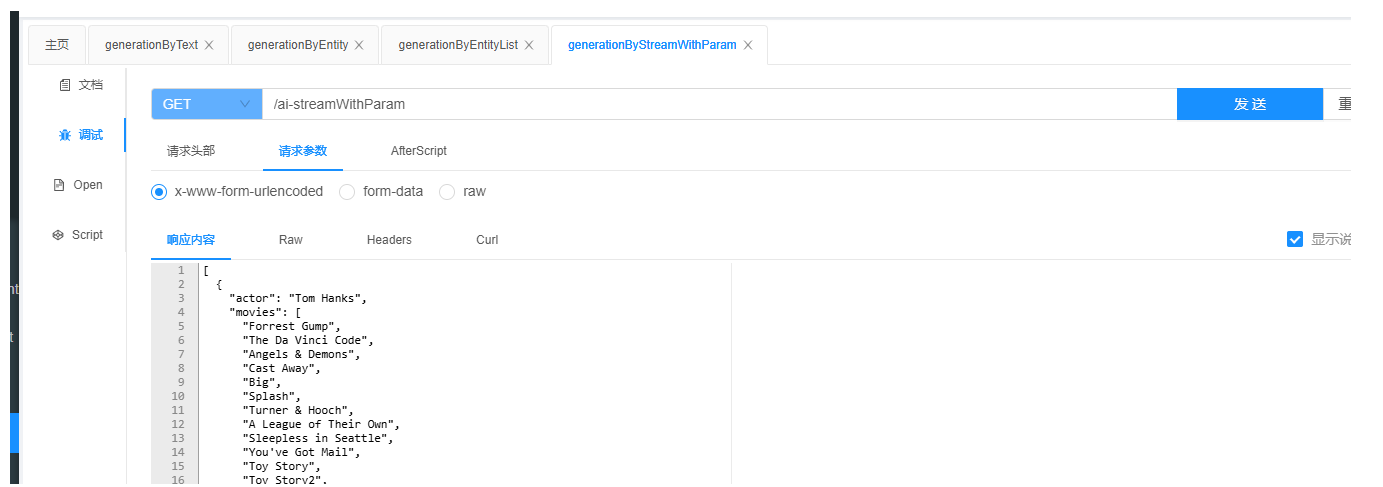
}为了演示用户信息中的参数传递,我对流式回答进行了一个阻塞操作。如果不需要的话,可以将其删除。另外,由于我需要封装一个列表对象,所以进行了阻塞操作。实际上,这与上面提到的一样,即在问答中直接定义了大模型返回的格式。好的,我们来看一下返回结果。
带有系统信息的client
这次我们将演示客户端的配置。在对话中,我们知道有三种身份标识:system、user、assistant。至今,我们尚未展示系统身份标识,但之前我们已经定义了系统形式的客户端。因此,这次我们将直接使用它:
@GetMapping("/ai-withSystemClient")
Map<String, String> generationByTextWithSystemClient(String message) {
return Map.of("completion", myChatClientWithSystem.prompt().user(message).call().content());
}这段代码非常简单,只需使用ChatClient即可。用户输入后,会返回一个Map类型的回答,其中key为"completion",对应的value为回答内容。让我们一起来看一下结果吧。
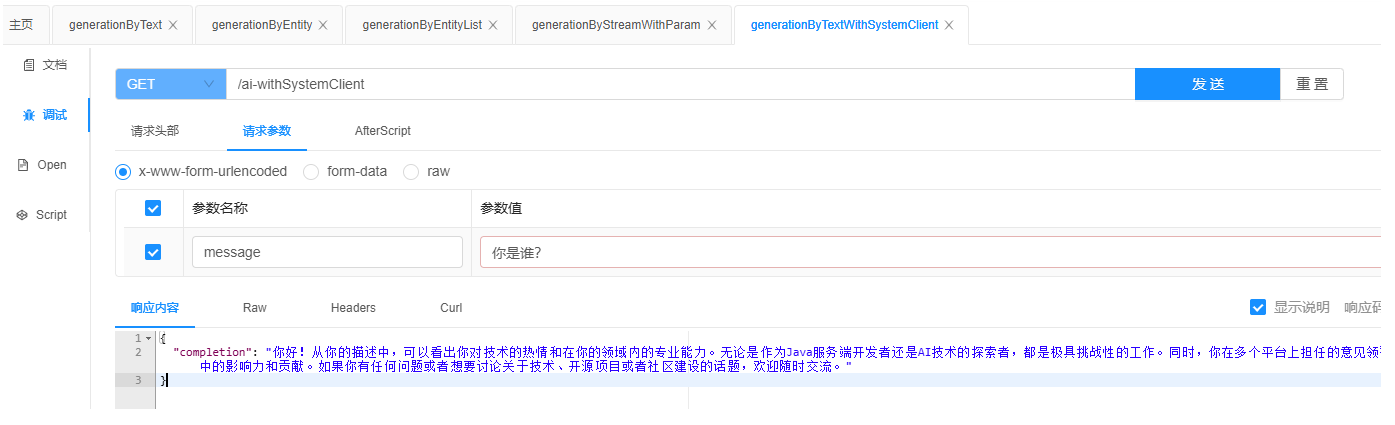
可以看出,实际上他已经将我的system信息包含在内了。
带有参数信息的client
当您需要演示带有参数的情况时,您可以考虑以下方法:在用户输入后,返回一个Map类型的回答,其中包含键值对,键为"completion",值为相应的回答。在实际业务场景中,参数是不可避免的,因此这种演示方式可以更好地展示人工智能的适用性。让我们继续探讨这一点:
@GetMapping("/ai-withParamClient")
Map<String, String> generationByTextWithParamClient(String message, String user) {
return Map.of("completion", myChatClientWithParam.prompt().system(sp ->sp.param("user",user)).user(message).call().content());
}这里也是很简单的一句话,所以我们看下效果:
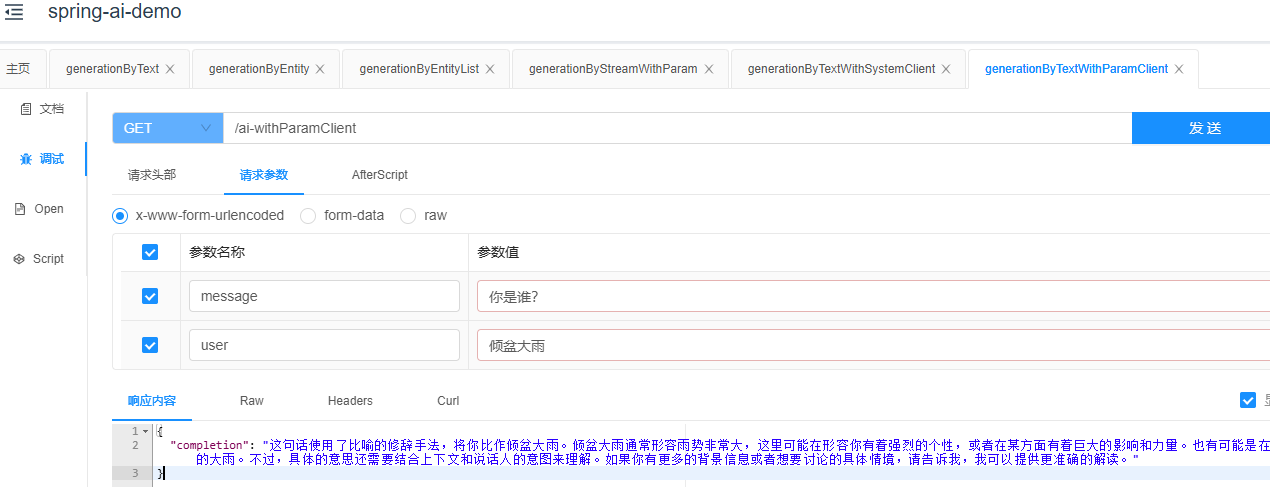
如果您对回答感到困惑,我们可以查看后台传输日志,以了解传输的参数详情。

可以注意到,实际上我们已经成功将参数设置完成。
聊天历史
在最后一个主要的业务场景中,每个人都会有自己的聊天记录。我们不能一直进行无状态的对话,这样会显得很不智能。因此,必须要有聊天记录的功能。虽然Spring AI尚未完全确定如何封装这部分功能,但已经提供了一个简单的对象类供我们调用。让我们来看一下:
@GetMapping("/ai-chatMemory")
String generationByChatMemory(HttpServletRequest request, String userInput) {
String sessionId = request.getSession().getId();
chatMemory.add(sessionId, new UserMessage(userInput));
String content = this.chatClient.prompt()
.advisors(new MessageChatMemoryAdvisor(chatMemory))
.user(userInput)
.call()
.content();
chatMemory.add(sessionId, new AssistantMessage(content));
return content;
}实际上,在这种情况下,我们需要自行创建并维护一个聊天历史对象。因此,每次进行聊天前和聊天后,我们都应该将所需的信息添加到该对象中,然后直接使用它。让我们来看一下这种做法的效果:
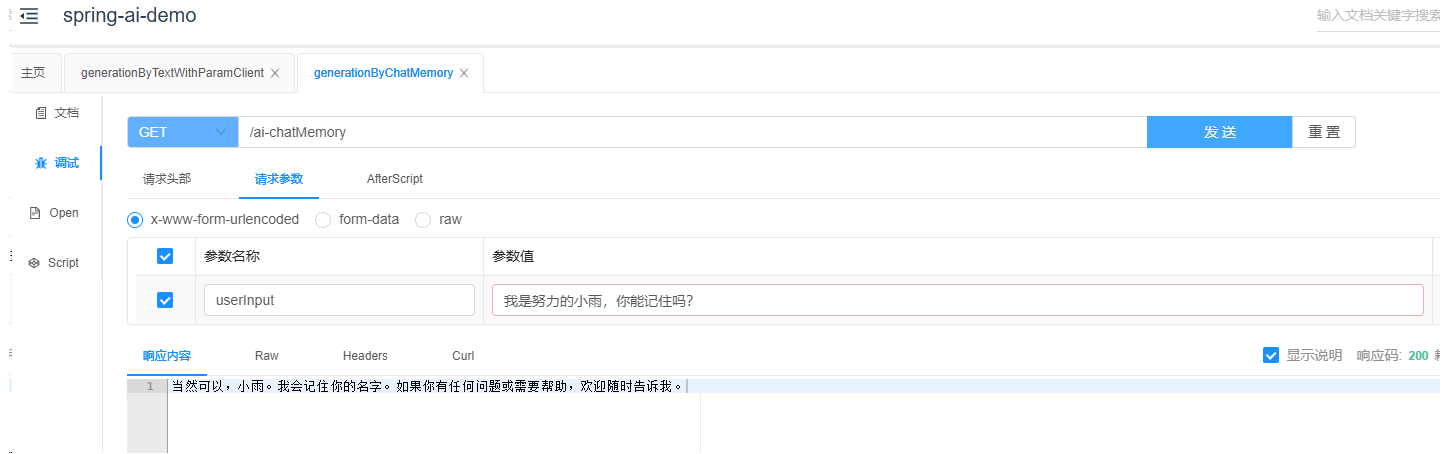
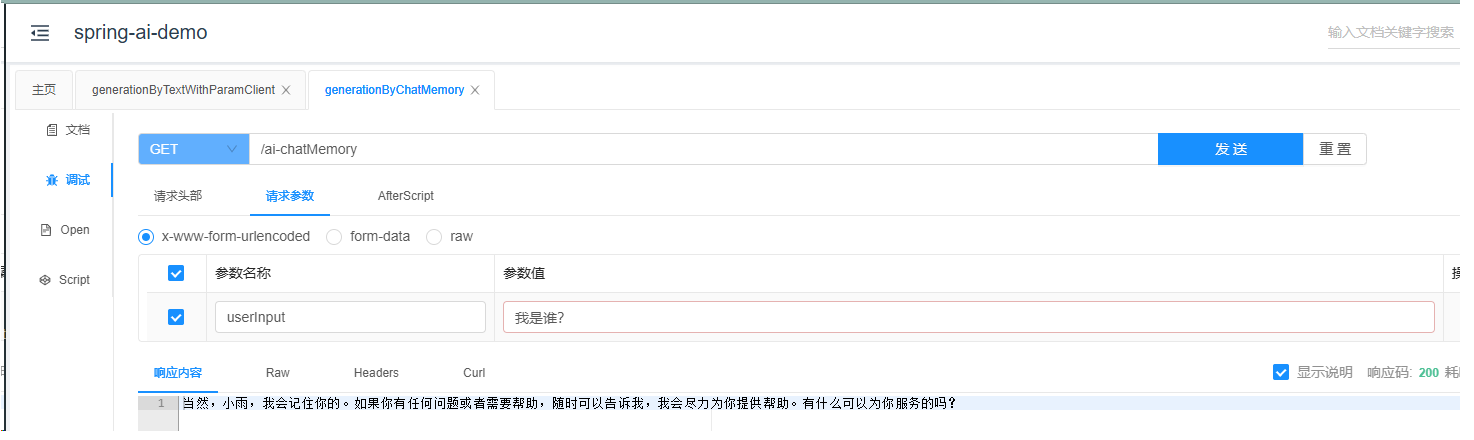
可以看到,实际上在这里已经将历史记录一并呈现了出来。
总结
通过本文的介绍,我们深入了解了Spring AI项目的优势和特性,以及在实际应用中的快速实战示例。Spring AI作为一个高度抽象化的人工智能应用程序开发框架,为开发者提供了便捷的模型支持、灵活的功能模块交换和优化能力。它不仅能将AI模型输出映射为POJO,还能与主流矢量数据库提供商无缝集成,从而显著提升开发AI应用程序的效率和可靠性。
与Python相比,Java在企业级应用和大型系统中具有显著优势。Java语言的静态类型和严格的编译时检查使得代码更加健壮和易于维护,尤其适合需要高度可靠性和长期支持的项目。同时,Java生态系统的成熟度和广泛应用确保了开发者可以轻松找到丰富的库和工具支持,加速开发周期并降低项目风险。
希望本文能为您对Spring AI项目的理解和应用提供帮助,同时也欢迎您关注和使用这个项目,持续关注更新和维护。让我们一起见证人工智能技术的不断进步和应用!
文章转载自:努力的小雨
原文链接:https://www.cnblogs.com/guoxiaoyu/p/18284842
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构