如何在用户输入模糊的情况下获得近乎完美的 LLM 性能

欢迎来到雲闪世界。你认为用户会向 LLM 提出完美的问题,这是大错特错。如果我们不直接执行,而是细化用户的问题,结果会怎样?这就是查询转换。
我们开发了一款应用程序,让用户可以查询我公司曾经制作的所有文档。这些文档包括 PPT、项目提案、进度更新、可交付成果、文档等。这款应用程序非常了不起,因为过去许多此类尝试都以失败告终。感谢 RAG,这次它非常有希望。
我们做了一个演示,每个人都很兴奋地使用它。最初的推出是针对一小部分选定的员工。但我们注意到,结果并不太令人兴奋。
这项技术有望彻底改变我们的工作方式。但大多数用户只试用了几次,之后就再也没有使用过。他们放弃这款应用,就好像它是小学生的玩具项目一样。
日志显示结果令人满意。但是,我们与使用该应用的真实用户进行了交谈,以确定真正的问题。我们学到的经验教训促使我们思考查询翻译技术,以克服用户输入中的歧义。
以下是一个示例情况。
一位用户对我们建议客户“XYZ”收购的时尚相关企业感兴趣。他输入的是:“XYZ 合伙人进行了哪些时尚相关收购?”该应用程序搜索了我们可交付的 PPT,并列出了十几家公司。然而,这份名单与用户的预期相差太大。XYZ 合伙人已经收购了(比如说)7 家时尚商店。但我们得到的名单只有 4 家。这位用户也是一名测试人员,他很清楚有多少次收购。
难怪人们不再使用该工具。但由于逐步淘汰的推广技术,失去的信任是可以逆转的。
我们对应用进行了一系列更改以解决此问题。一项重要更新是查询翻译。
这篇文章旨在介绍我们不同的查询翻译技术,但不会深入介绍。例如,其中一些技术可以与提示技术(如小样本提示和思维链)相结合,以获得更好的结果。不过,这些技术留待以后的另一篇文章再讲。
让我们逐一探索这些技术。但在此之前,这是一个基本的 RAG 示例。
基本 RAG 示例
所有 RAG 应用程序都至少有一个数据库,通常是一个向量存储和一个语言模型。RAG 背后的基本思想很简单。在 LLM 利用其先验知识回答用户的问题之前,它会在数据库中搜索上下文信息并生成更准确的响应。
下图说明了最简单的 RAG 应用程序。

基本 RAG 应用程序工作流程 — 图片由作者提供。
在简单的 RAG 应用程序中,仅存在与您的 LLM 模型的一次通信。这可以是OpenAI GPT 模型、Cohere,甚至是您本地托管的模型。
以下代码实现了图中的步骤。我们将以此为基础,构建本文中的其他技术。
# 这是为了安全地加载我们的秘密
from dotenv import load_dotenv
load_dotenv()
# 1. 加载内容
# -----------------------------------------
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=( "https://docs.djangoproject.com/en/5.0/topics/performance/" ,),
bs_kwargs= dict (
parse_only=bs4.SoupStrainer(
id = "docs-content"
)
),
)
doc_content = loader.load()
# 2. 索引
# -----------------------------------------
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size= 1000 , chunk_overlap= 200
)
docs = text_splitter.split_documents(doc_content)
vector_store = Chroma.from_documents(documents=docs, embedding=OpenAIEmbeddings())
trieser = vector_store.as_retriever()
# 3. LLM
# -----------------------------------------
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature= 0.5 )
# 4. RAG Chain
# -----------------------------------------
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
prompt = """
在以下上下文中回答问题:
{context}
问题:{question}
"""
prompt_template = ChatPromptTemplate.from_template(prompt)
chain = (
{ “上下文”:检索器,“问题”:RunnablePassthrough()}
| prompt_template
| llm
| StrOutputParser()
)
# 5. 调用链
# -----------------------------------------
response = chain.invoke(
“我如何提高网站速度?”,
)
打印(响应)
在上面的代码中,我们使用了基于 Web 的加载器从 Django 的文档页面加载页面并将其存储在 Chroma 矢量存储中。除了文档页面,您还可以尝试不同的网页、本地文本文件、PDF 等。
由于我们没有使用复杂的检索技术,因此我们将检索器直接传递到最终的 RAG 链。在后续技术中,我们将传递另一个检索器链而不是检索器本身。本文的其余部分是关于我们如何构建检索链。
后退提示
生成与更广泛的背景不矛盾的一致答案。
后退提示与基本 RAG 非常相似。我们不会向用户询问初始问题,而是使用更广泛的问题从数据库中检索文档。
较宽泛的问题比具体的问题能捕捉到更多的背景信息。因此,最终的 LLM 可以为用户提供更多有用的信息,且不会与更广泛的背景相矛盾。
当初始查询过于具体和详细但缺乏整体视图时,这通常很有用。
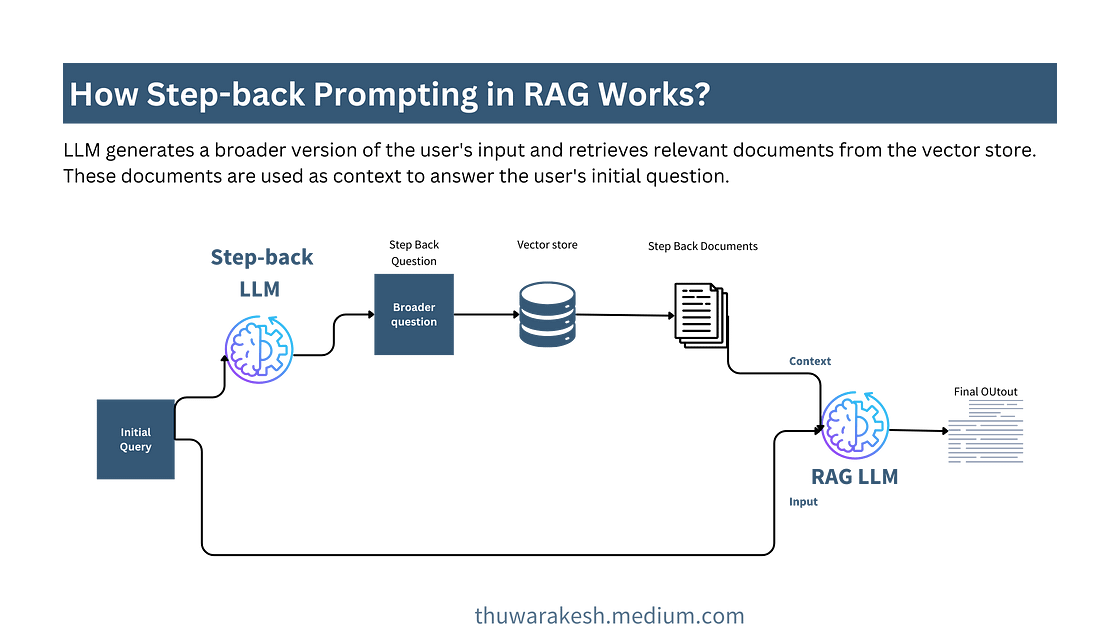
后退提示工作流程——图片由作者提供。
以下是后退提示的代码实现。请注意,我们使用了不同的代码,在基本 RAG 示例中,我们传递了一个检索器本身。
# 4. RAG 链
# -----------------------------------------
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 4.1 后退提示
step_back_prompt = """
你是一位专业软件工程师。
你的任务是将给定的问题改写成更通用的形式,以便于回答。
# 示例 1
问题:如何提高 Django 性能?
输出:哪些因素会影响 Web 应用程序性能?
# 示例 2
问题:如何在 Django 中优化浏览器缓存?
输出:有哪些不同的缓存选项?
问题:{question}
输出:
“""
step_back_prompt_template = ChatPromptTemplate.from_template(step_back_prompt)
retrieval_chain = step_back_prompt_template | llm | StrOutputParser() |检索器
# 4.2 RAG chain
prompt = """
在以下上下文中回答问题。
您的回答应全面,且不与以下上下文相矛盾。
如果上下文与问题无关,请说“我不知道”:
{context}
问题:{question}
"""
prompt_template = ChatPromptTemplate.from_template(prompt)
rag_chain = (
{ "context" : retrieval_chain, "question" : RunnablePassthrough()}
| prompt_template
| llm
| StrOutputParser()
)
对于更广泛背景至关重要的申请,后退提示很有帮助。法学硕士将对相关问题提供一致的答案。
HyDE(假设文档嵌入)
利用相关来源生成内容丰富的答案
HyDE 是一种近期流行的文档检索技术。其理念是利用 LLM 的先验知识生成文档。然后,该文档从向量存储中检索相关上下文。
HyDE 的一个很好的用例是,当用户经常使用外行术语来描述问题,但向量存储中的信息非常技术性时。此外,LLM 的描述有更多关键字来检索相关信息。
例如,像“提高 Django 性能的 10 种方法”这样的查询将提供一个全面的答案,其中包括成本影响、缓存、压缩等。
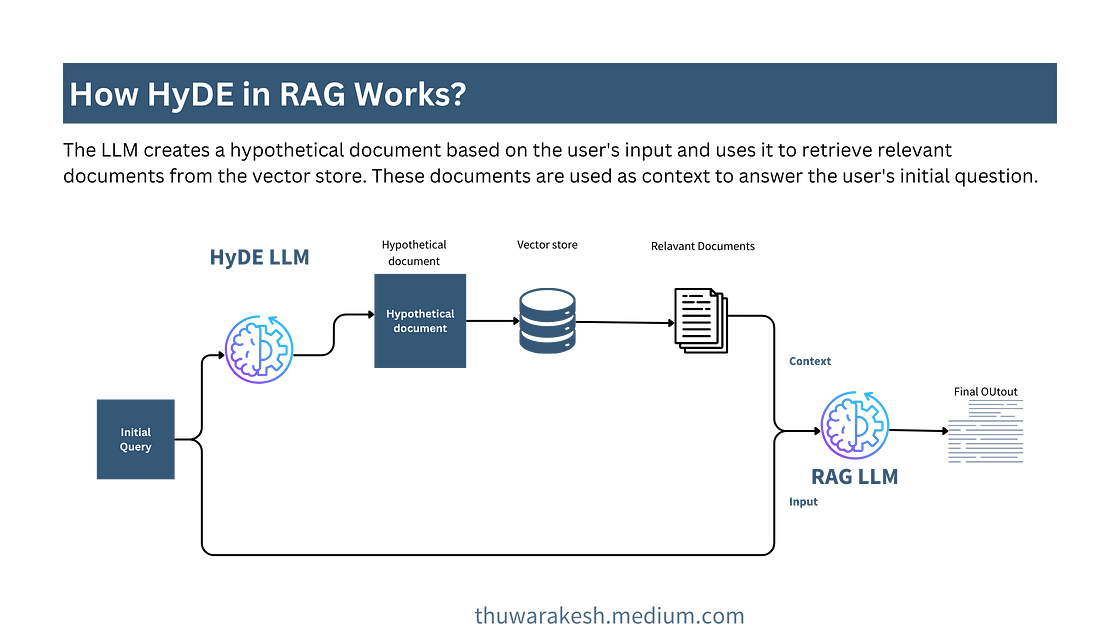
HyDE 文档检索过程——图片由作者提供。
以下是上图的代码实现。这次,我仅提供了使用 HyDE 重新创建检索链的代码片段。
# 4.1 HyDE 提示
hyde_prompt = """
你是一个 AI 语言助手。
你的任务是生成下面问题的更宽泛版本。
通过这样做,你将帮助用户获得更多信息。
不要解释这个问题。只提供更宽泛的版本。
问题:{question}
输出:
"""
hyde_prompt_template = ChatPromptTemplate.from_template(hyde_prompt)
retrieval_chain = hyde_prompt_template | llm | StrOutputParser() | trieser
多查询
检索更多文档,克服距离基础,类似地搜索并获得更多相关答案。
多查询是一种有助于解决向量存储中基于距离的搜索问题的技术。大多数向量存储使用余弦相似度来检索向量化文档。只要文档具有一定的相似度,此方法就很有效。但是,当不存在基于距离的相似度时,检索过程将失败。
在多查询方法中,我们要求 LLM 创建同一查询的多个版本。例如,像“如何加速 Django 应用程序”这样的查询将被转换为另一个版本,“如何提高基于 Django 的 Web 应用程序的性能?”这些查询一起将从向量存储中检索更多相关文档。
作为中间步骤,我们必须在将这些文档传递给最终的 RAG-LLM 之前获取一份唯一的文档列表。这是因为很有可能不止一个查询会检索相同的文档。将它们全部与重复项一起传递将毫无意义地达到 LLM 的标记阈值。
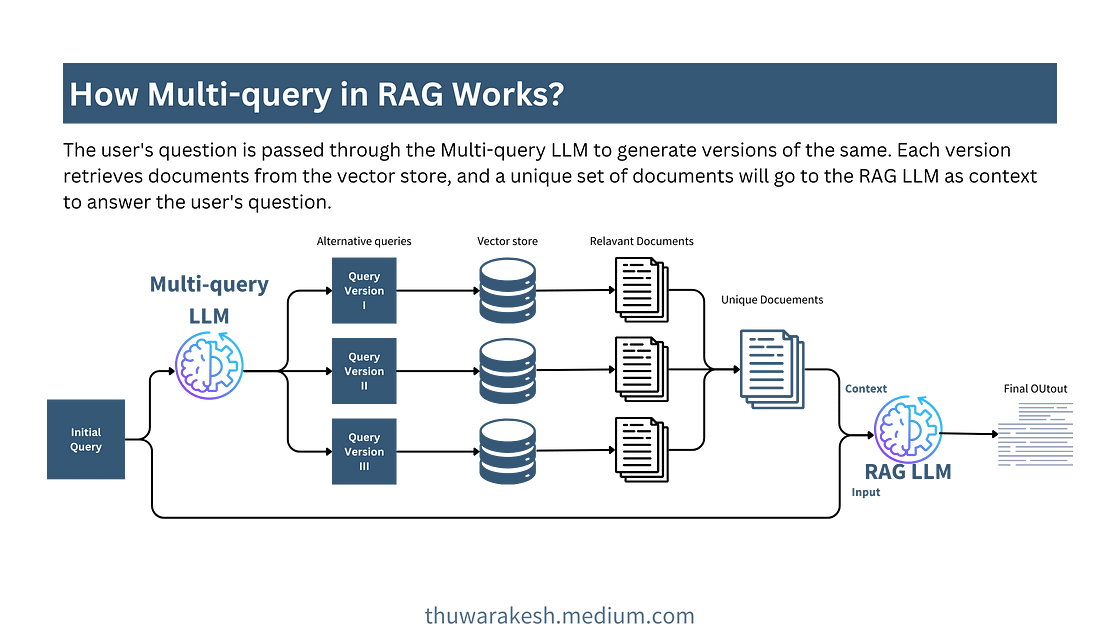
多查询检索工作流程——图片由作者提供。
代码实现还增加了一个对文档进行重复数据删除的功能。其余部分与其他方法相同。
from langchain.load import loads, dumps
def get_unique_documents(documents: list[list]) -> list:
# 展平列表列表,并将每个 Document 转换为字符串
flattened_docs = [dumps(doc) for sublist in documents for doc in sublist]
# 获取唯一文档
unique_docs = list(set(flattened_docs))
# 返回
return [loads(doc) for doc in unique_docs]
# 4.1 多查询提示
multi_query_prompt = "" "
你是一个 AI 语言模型助手。
你的任务是创建五个版本的用户问题,以从向量数据库中获取文档。
通过提供对用户问题的多种视角,你的目标是帮助用户克服基于距离的相似性搜索的一些限制。
给出这些备选问题,每个问题占一行。
问题:{question}
输出:
" ""
multi_query_prompt_template = ChatPromptTemplate.from_template(multi_query_prompt)
retrieval_chain = (
multi_query_prompt_template
|llm
|StrOutputParser()
|(lambda x:x.split( “\n” ))
|retriever.map()
|get_unique_documents
)
RAG融合
更多相关文档在答案中发挥更重要的作用
RAG 融合类似于文档检索前端的多查询。我们再次要求 LLM 生成初始查询的不同版本。然后我们针对这些版本分别检索文档并将它们组合起来。
然而,在合并和去重文档的同时,我们也会根据文档的相关性对它们进行排序。以下是 RAG 融合过程的示意图。
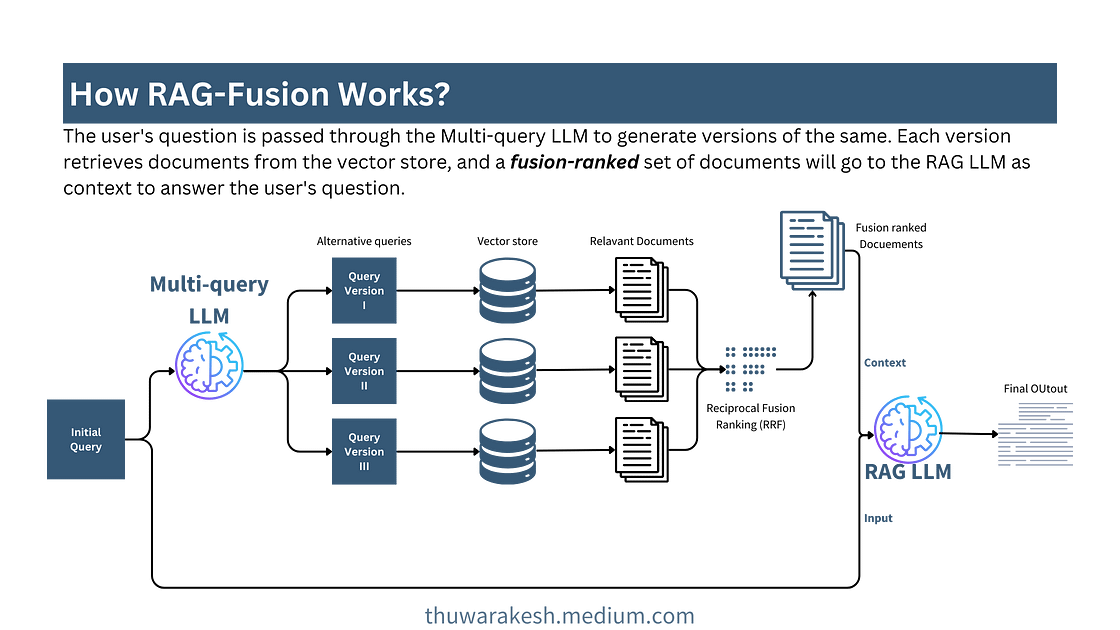
RAG-fusion 工作流程——图片由作者提供。
我们不只是进行重复数据删除,还使用排名系统对文档进行排序。互易融合排名 (RRF) 是一种对文档进行排名的巧妙方法。
如果多个查询版本将同一文档检索为最相关文档,则 RRF 会将其排名靠前。如果特定文档仅出现在其中一个查询版本中,并且相似度较低,则 RRF 会将该文档排名靠后。这样,我们就可以获取更相关的信息并对其进行优先排序。
def reciprocal_rank_fusion ( results: list [ list ], k= 60 ):
""" Reciprocal_rank_fusion 采用多个排名文档列表
和 RRF 公式中使用的可选参数 k """
fused_scores = {}
for docs in results:
for rank, doc in enumerate (docs):
doc_str = dumps(doc)
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
previous_score = fused_scores[doc_str]
fused_scores[doc_str] += 1 / (rank + k)
reranked_results = [
(loads(doc), score)
for doc, score in sorted (fused_scores.items(), key= lambda x: x[ 1 ], reverse= True )
]
return reranked_results
# 4.1 RAG-fusion 提示
multi_query_prompt = """
你是一个 AI 语言助手。
你的任务是生成 5 个不同版本的用户问题。
通过这样做,你正在帮助用户克服基于距离的相似性搜索的局限性。
提供这些以换行符分隔的备选问题。
问题:{question}
输出:
"""
multi_query_prompt_template = ChatPromptTemplate.from_template(multi_query_prompt)
retrieval_chain = (
multi_query_prompt_template
| llm
| StrOutputParser()
| ( lambda x: x.split( "\n" ))
| trieser. map ()
| reciprocal_rank_fusion
)
分解
在回答复杂问题时,让 LLM 将其分解成各个部分并逐步构建答案。
有些情况下,最好不要直接回答。解决更复杂任务的一个好方法是将问题分解成几个部分,然后分别回答。
这不仅仅是一种 LLM 技术,对吧?
是的,我们在查询分解中尝试将初始问题分解为多个子问题。回答这些子问题将为回答初始查询提供一些零碎信息。
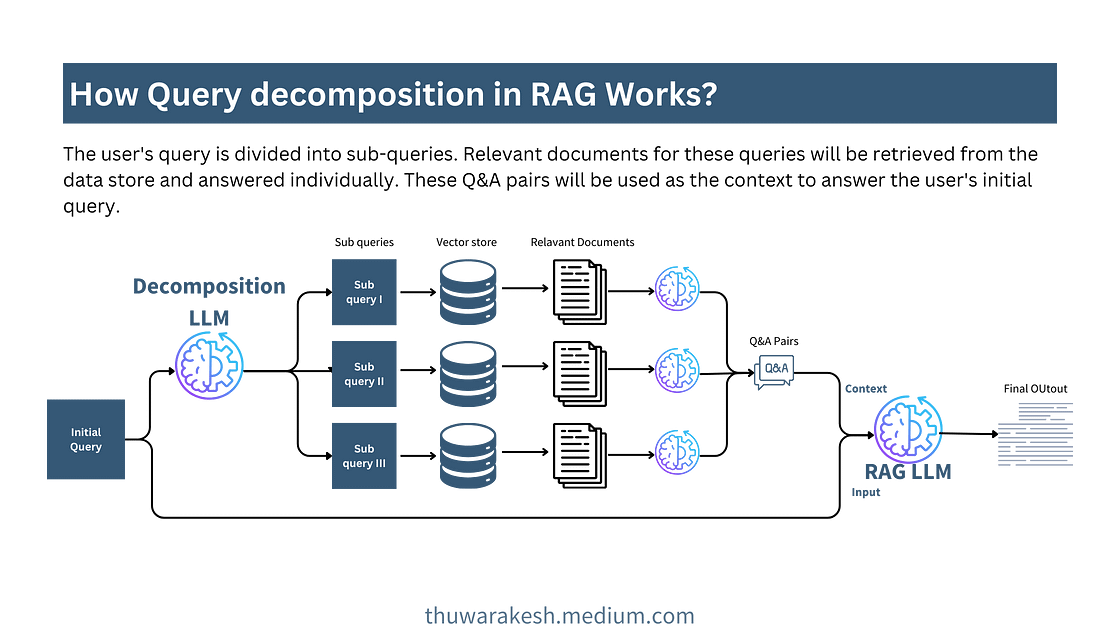
RAG 中的查询分解——图片由作者提供。
正如您在图中看到的,我们检索每个子问题的相关文档并分别回答它们。然后我们将这些问题和答案对传递给最终的 RAG-LLM。LLM 现在拥有更详细的信息来解决复杂问题。
# 4.1分解提示
decomposition_template = "" "你是一个AI语言助手。
你的任务是将以下问题分解为5个子问题。
通过这样做,你正在帮助用户逐步构建最终答案。
提供用换行符分隔的这些备选问题。
原问题:{question}
输出:
" ""
decomposition_prompt_template = ChatPromptTemplate.from_template (decomposition_template) def
query_and_combine ( questions: list[ str ]) -> str :
print (questions) qa_pairs
= []
for q in questions:
r = basic_rag_chain.invoke ( q)
qa_pairs.append ( (q, r))
qa_pairs_str = "\n" .join ([f "Q: {q}\nA: {a}" for q , a in qa_pairs]). strip()打印(qa_pairs_str)返回qa_pairs_str retrieval_chain =( { “question”:RunnablePassthrough()} | decomposition_prompt_template | llm | StrOutputParser() |(lambda x:x.split ( “ \n”)) | query_and_combine )
最后的想法
从演示应用程序到生产有许多步骤。其中一个不可避免的步骤是查询翻译。
我们解决的问题复杂程度不同。需要考虑用户不完善的查询。应该解决检索过程的缺陷。这些都需要考虑。
没有单一的正确方法来选择最佳的查询转换技术。在实际应用中,您可能需要结合多种技术才能获得所需的输出。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)
#aws CLI cheat sheet #aws cli Debug #aws cli get S3 object #aws cli login with access key #aws cli to download from s3 #aws command line download from s3 #homebrew install aws cli#aws sdk get caller identity #aws s3 cli get object #aws s3 put object#aws s3 headobject#aws s3 put-object #aws s3 sync vs cp