Rule和RuleExecutor
SparkSQL中对LogicalPlan的解析、优化、还有物理执行计划生成都是分成一个个Rule进行的。
RuleExecutor是一个规则引擎,它收集Rule,并对plan按照rule进行执行。
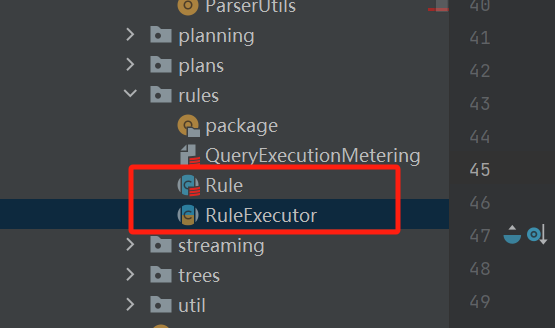
每一个Rule的实现类都要实现apply方法,具体逻辑都放在这个方法中。
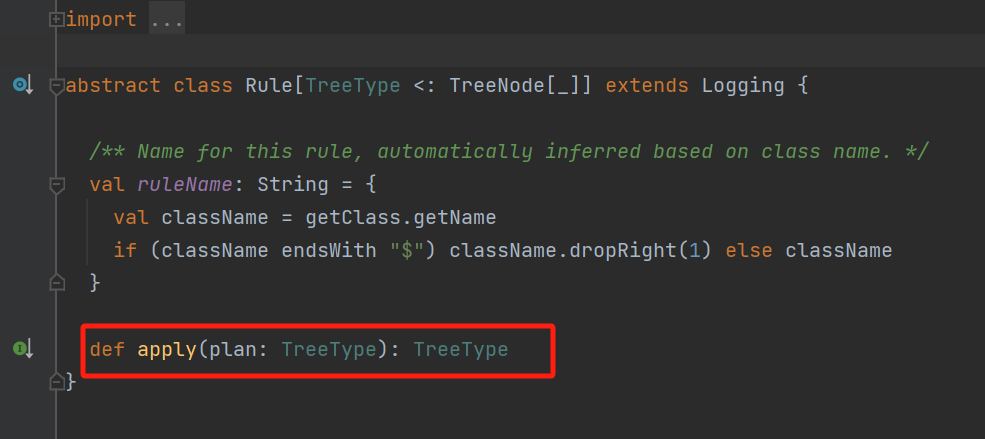
RuleExecutor核心是batches存放要执行的rule、execute执行batches的rule。
batches中有很多Batch对象。相同执行策略、相似功能的rule会生成一个Batch对象。
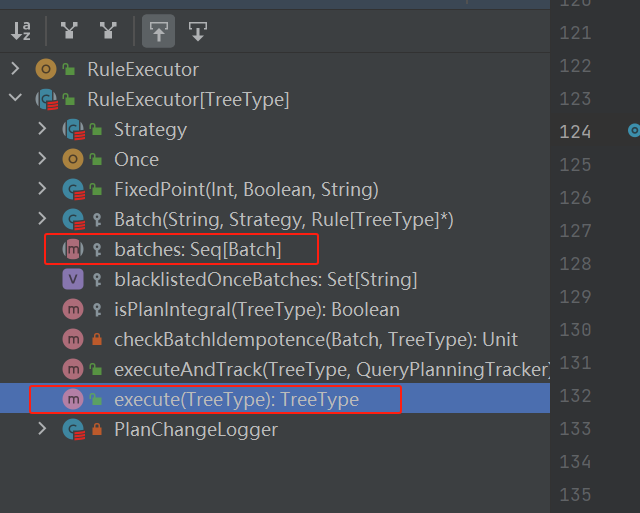

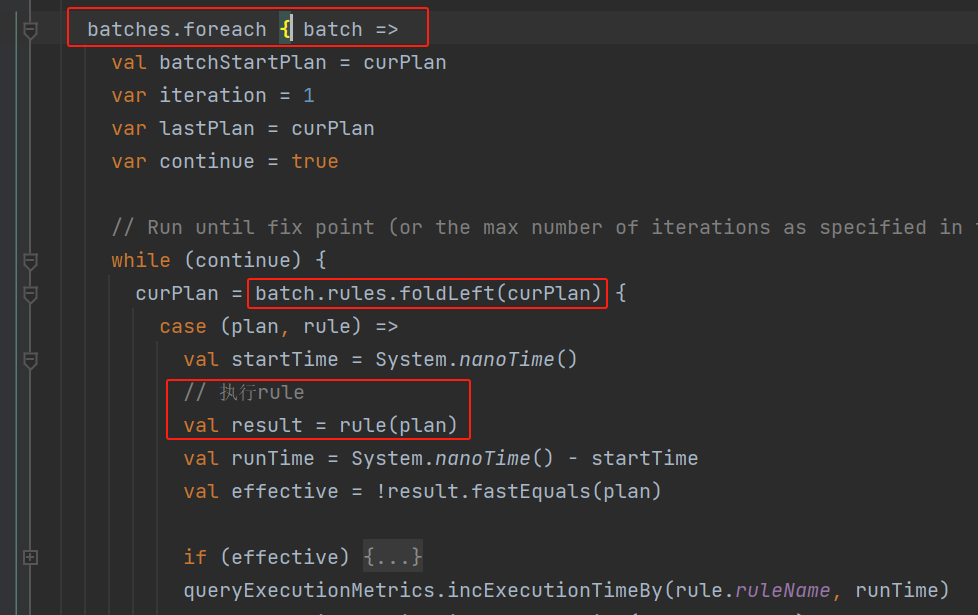
execute方法中按照batch和batch中的rule遍历执行。
Analyzed LogicalPlan
SQL示例:SELECT name FROM student WHERE age>18
在sql那里生成的plan是unresolved plan。调用Dataset的ofRows方法将plan传入。
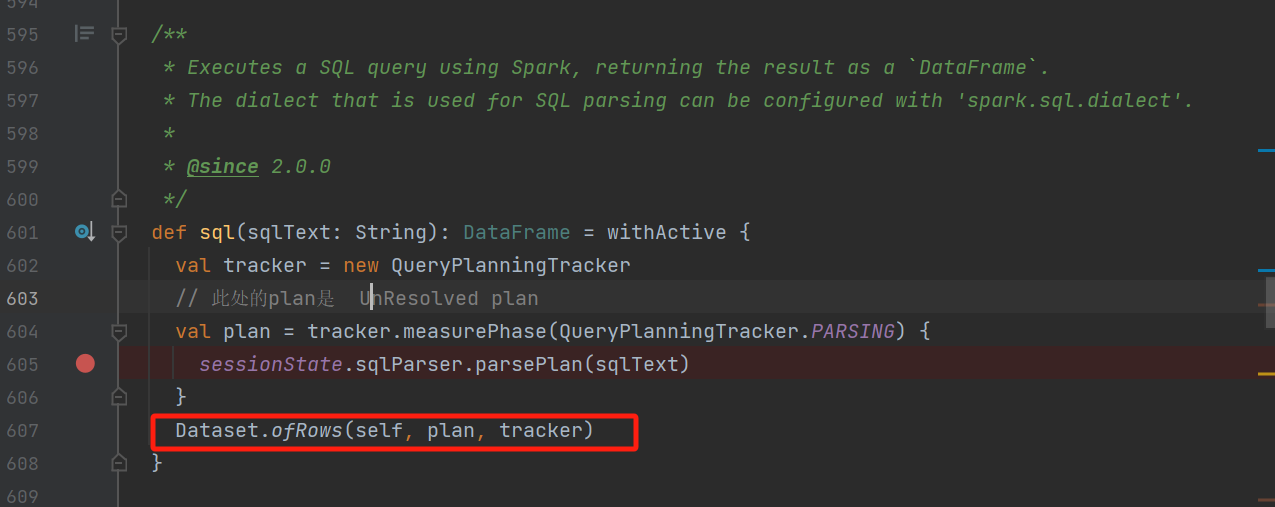
在ofRows方法中,创建了QueryExecution对象。
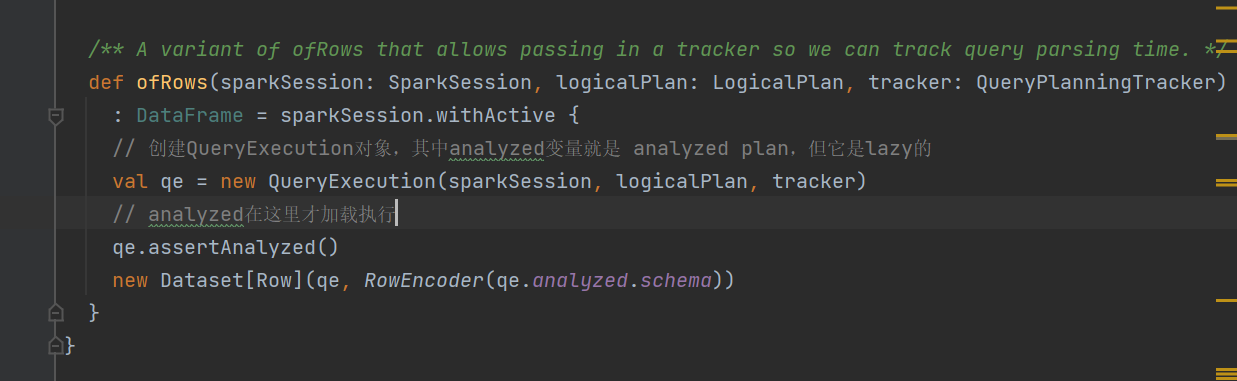
QueryExecution对象中logical是unresolved plan,analyzed是analyzed plan,optimizedPlan是optimized plan,sparkPlan是物理算子树、executedPlan是执行算子树、toRdd是转换后的RDD。除了logical是传入的变量,其余都是lazy懒加载,只有使用的时候才会赋值。
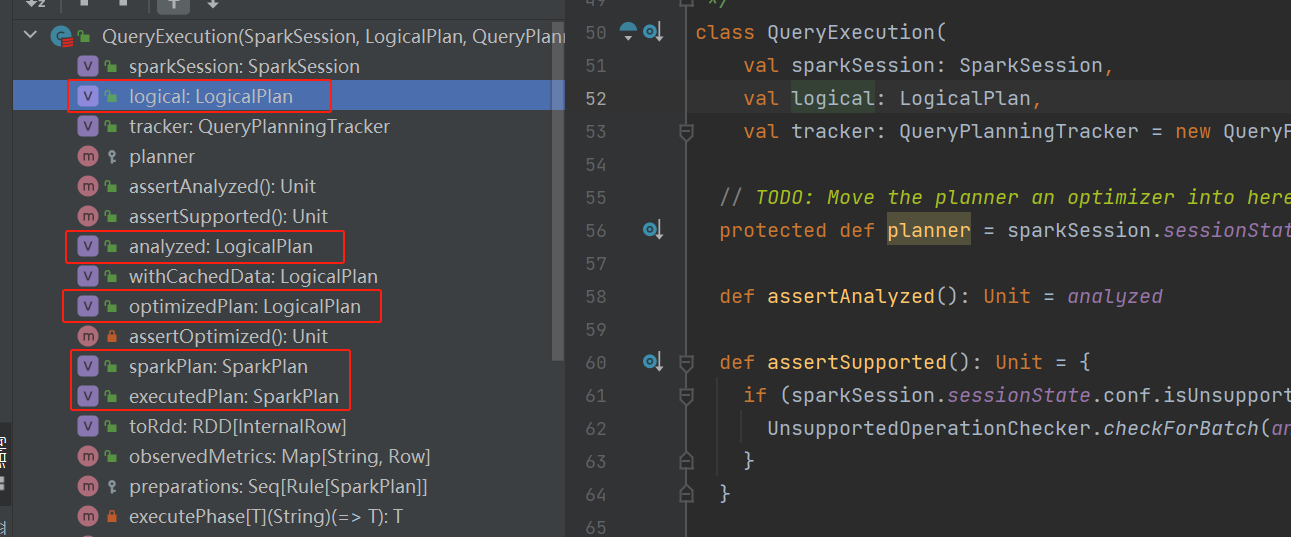
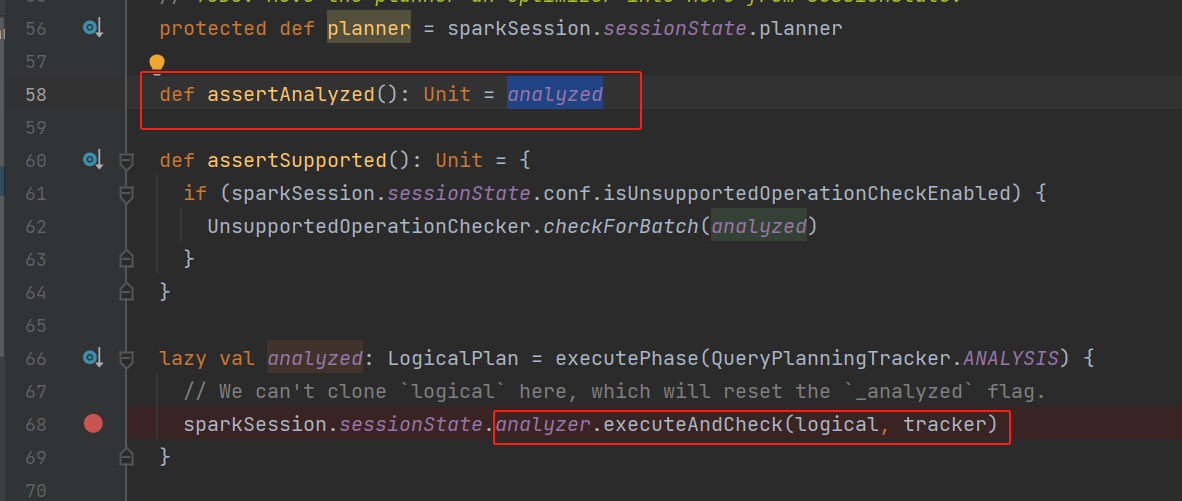
在ofRows方法中紧接着调用了assertAnalyzed方法,这里触发了analyzed的计算赋值。
核心方法是analyzer.executeAndCheck(logical, tracker)
Analyzer
Analyzer类提供逻辑查询计划分析,使用[[SessionCatalog]]中的信息将[[UnresolvedAttribute]]s和[[UnsolvedRelations]]转换为全类型对象。
executeAndCheck是plan analysis正式开始的地方。

executeAndTrack是调用的execute
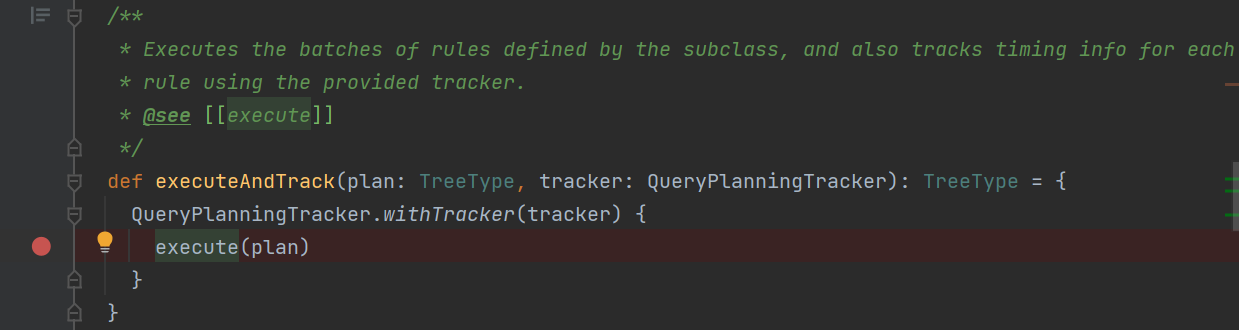
execute方法就是RuleExecutor中的方法。重点是Analyzer的batches变量中的rule。
可以看到batches中有很多rule.
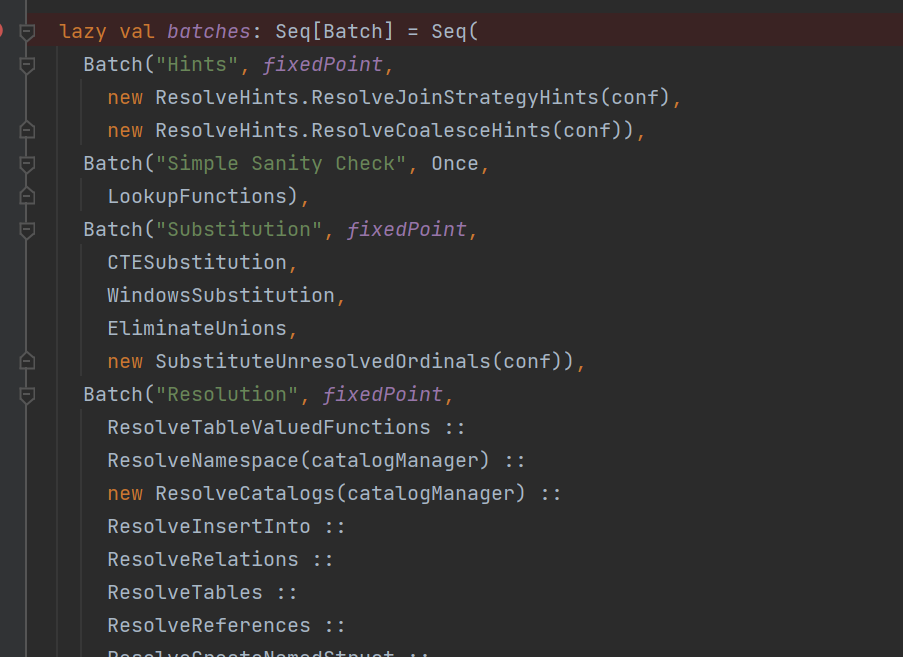
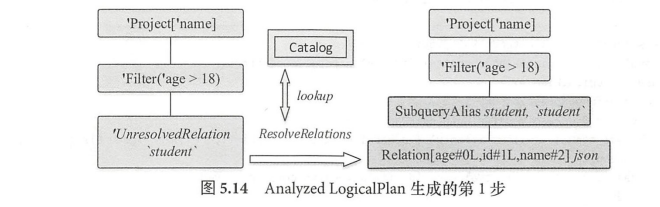
ResolveRelations示例
unresolved plan如下,ResolveRelations规则会执行处理unresolvedRelation。

apply方法中是ResolveTempViews是用来处理视图的
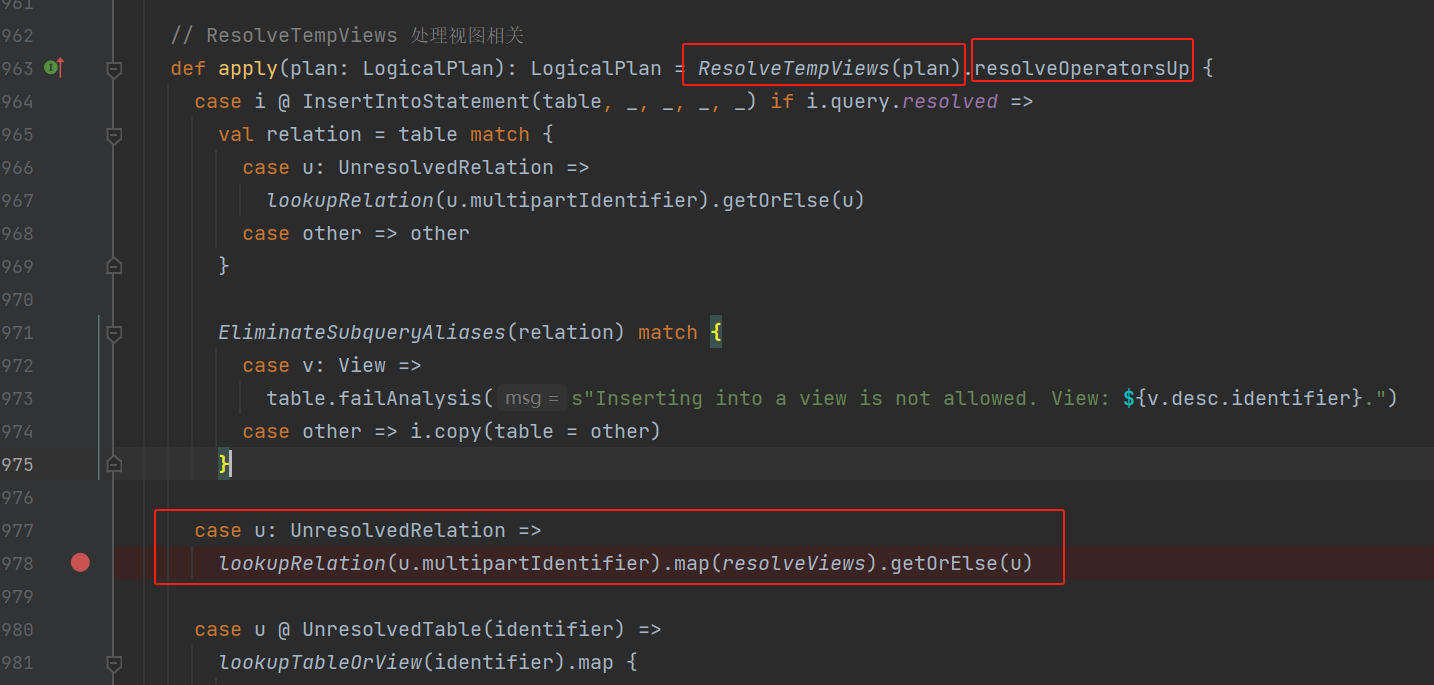
resolveOperatorsUp
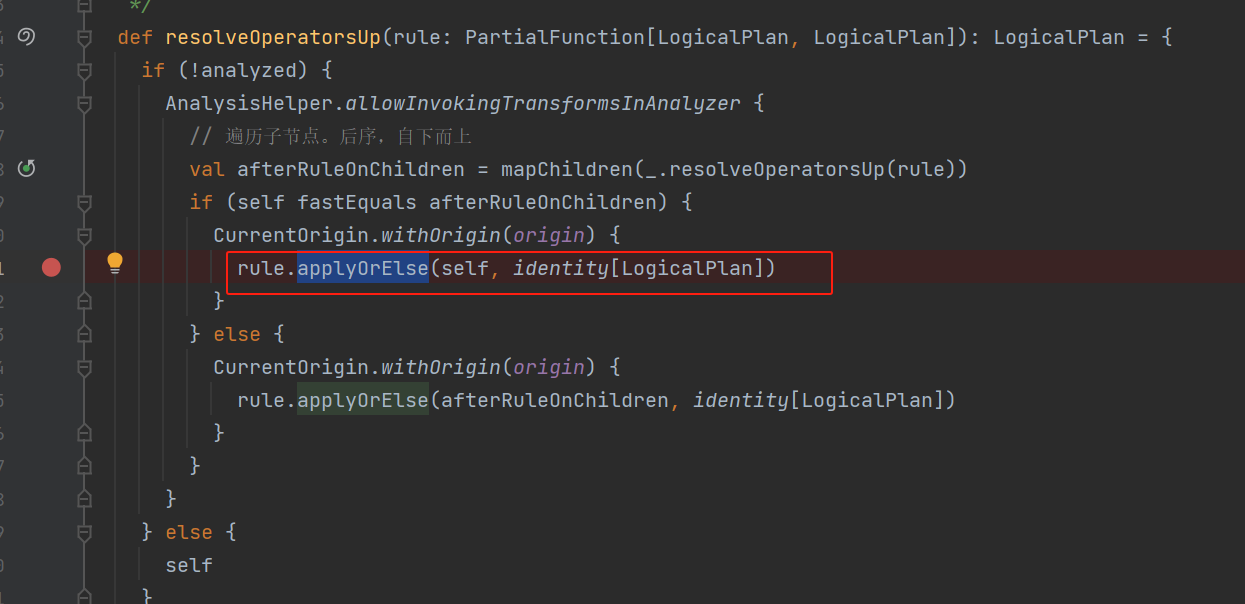
这个是后序自下而上进行遍历。调用rule的apply方法。
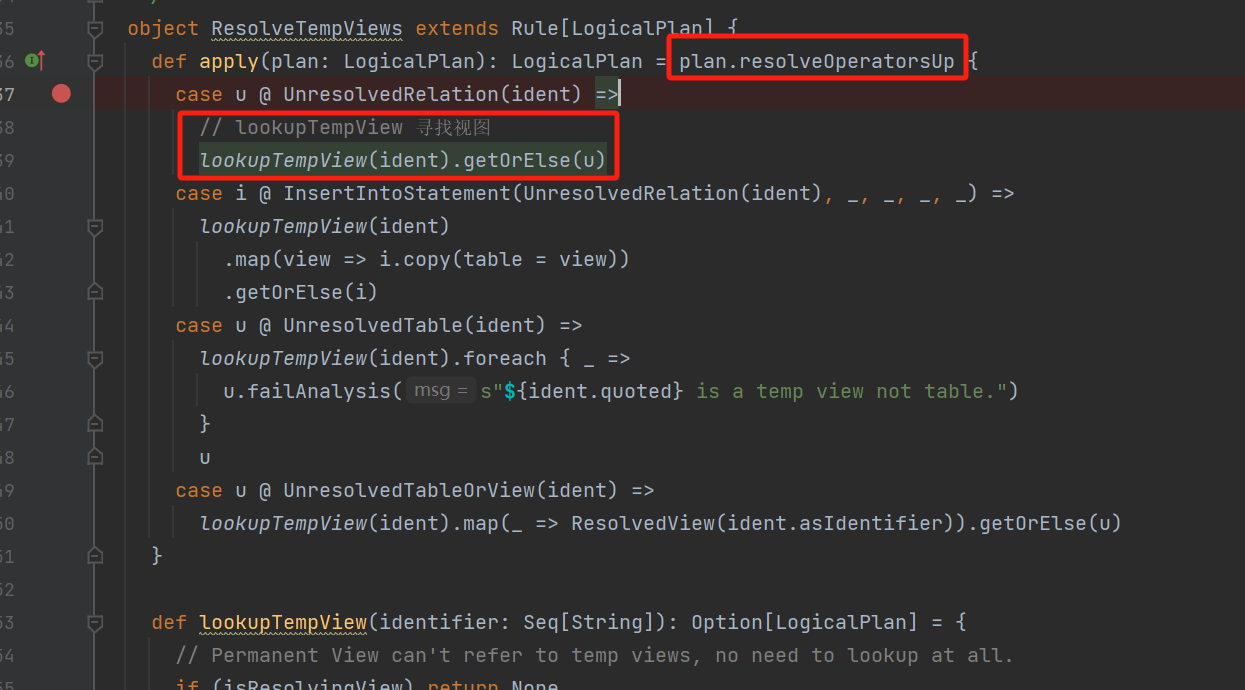
ResolveTempViews的apply方法,本例中没有视图,所以lookupTempView返回空,最后还是返回LogicalPlan(目前没变化)
因为还是UnresolvedRelation,所以执行lookupRelation方法后再执行resolveViews方法。
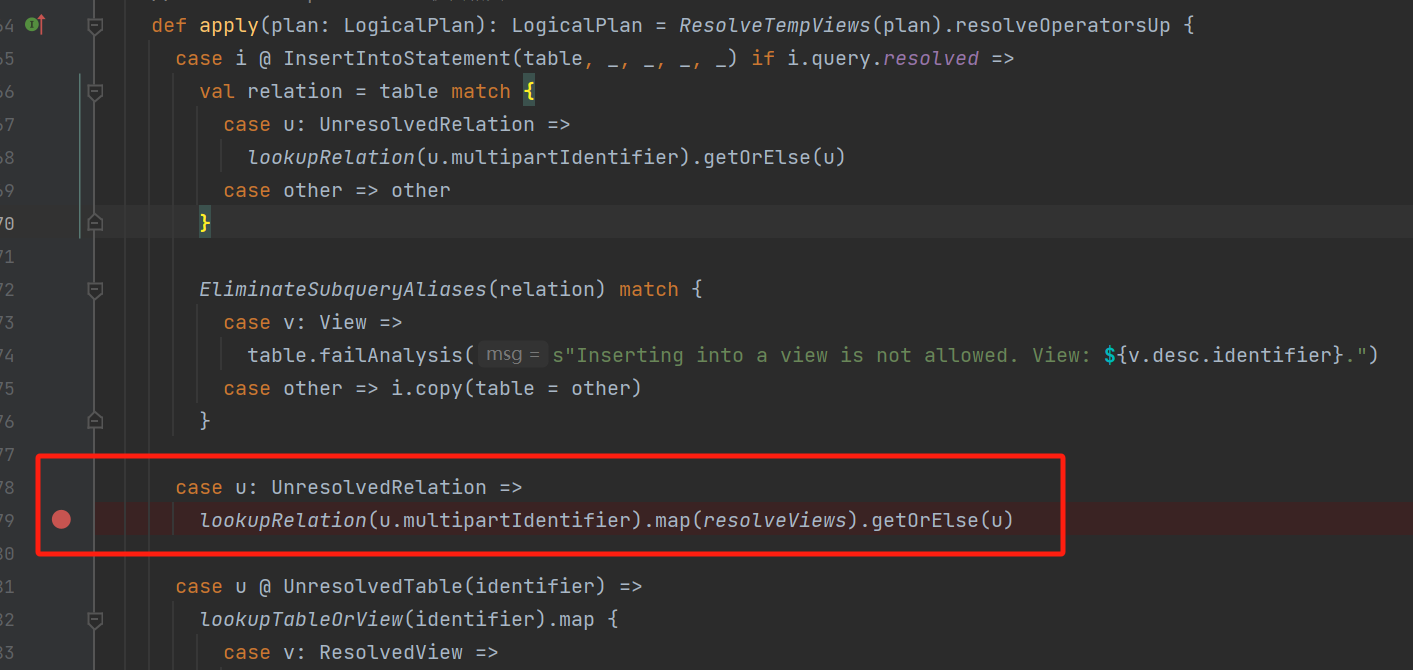
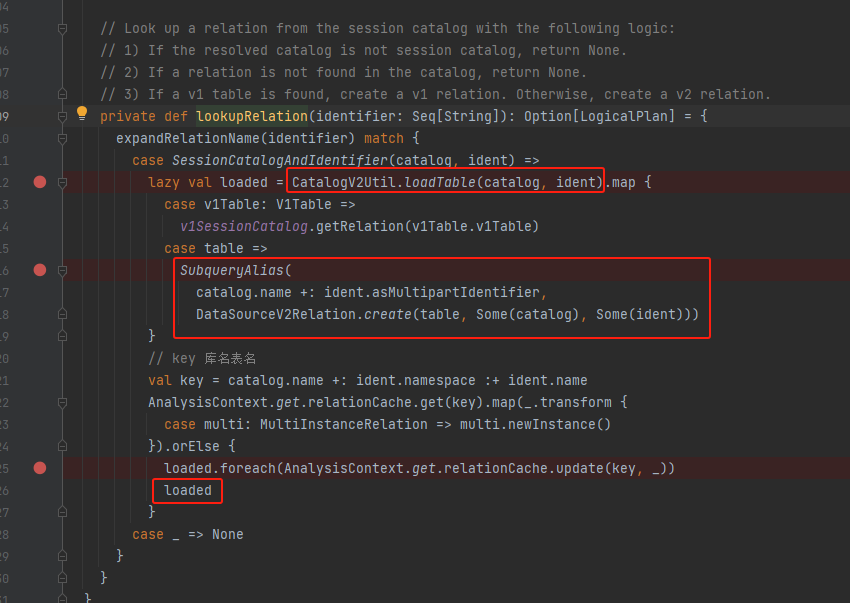
lookupRelation
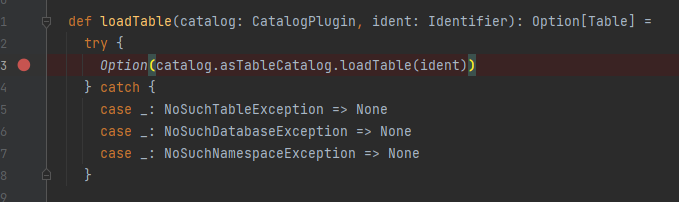
CatalogV2Util.loadTable是来获取表信息。从catalog中获取表,优先获取v1 table,否则取v2 table。
最后生成了SubqueryAlias里面包含DataSourceV2Relation.
处理完如下图:
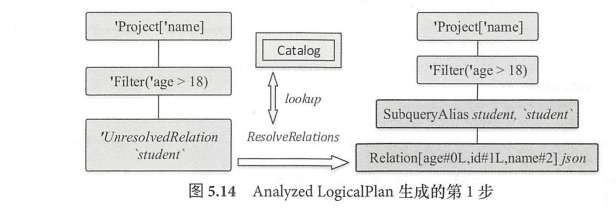
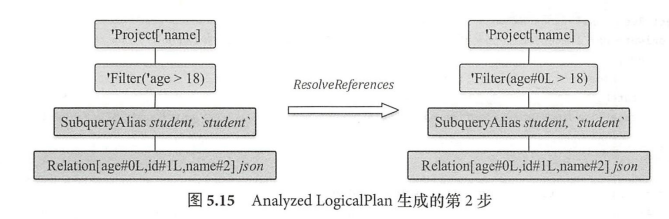
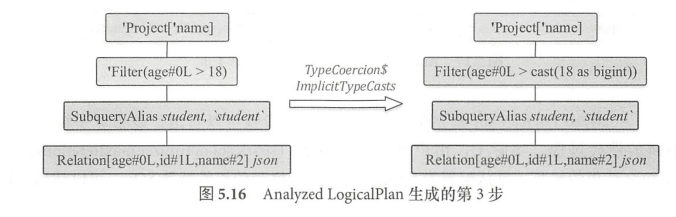
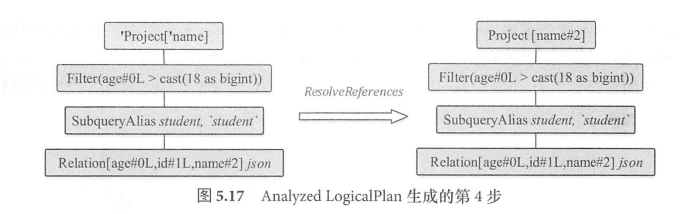
这里只是使用ResolveRelations处理了UnresolvedRelation.还有别的规则需要用来处理UnresolvedAttribute、常量等。处理方式跟ResolveRelations规则类似。

最后经过一系列规则后生成analyzed plan