尽管大语言模型在最近今年发展十分迅速,但是相关的综述却相对比较落后。本文是由中国人民大学教授Wayne Xin Zhao等人前几天刚公开的关于大语言模型的综述,论文正文部分共32页,包含了416个参考文献。内容十分详实。
这份大模型综述我已经打包好了,还有完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
 本文将简单介绍一下这篇综述。本文综述了LLMs最近在四个主要方面的研究进展,包括预训练(如何预训练能力强的LLM)、适应调整(如何从有效性和安全性两个方面有效地调整预训练的LLM)、应用(如何使用LLMs解决各种下游任务)和能力评估(如何评估LLMs的能力和现有的经验结果)。文章彻底梳理了文献,并总结了LLMs的关键发现、技术和方法。
本文将简单介绍一下这篇综述。本文综述了LLMs最近在四个主要方面的研究进展,包括预训练(如何预训练能力强的LLM)、适应调整(如何从有效性和安全性两个方面有效地调整预训练的LLM)、应用(如何使用LLMs解决各种下游任务)和能力评估(如何评估LLMs的能力和现有的经验结果)。文章彻底梳理了文献,并总结了LLMs的关键发现、技术和方法。
- 现有的大模型的总体情况概览
- 现有大模型使用的语料统计
- 现有大模型使用的库(开源软件)
- 现有大模型预训练数据源比例
- 预训练大模型典型的数据预处理流程
- 现有大模型使用的架构和训练细节
现有的大模型的总体情况概览
文章的第一部分为我们总结了最近今年发布的大模型。如下图所示。
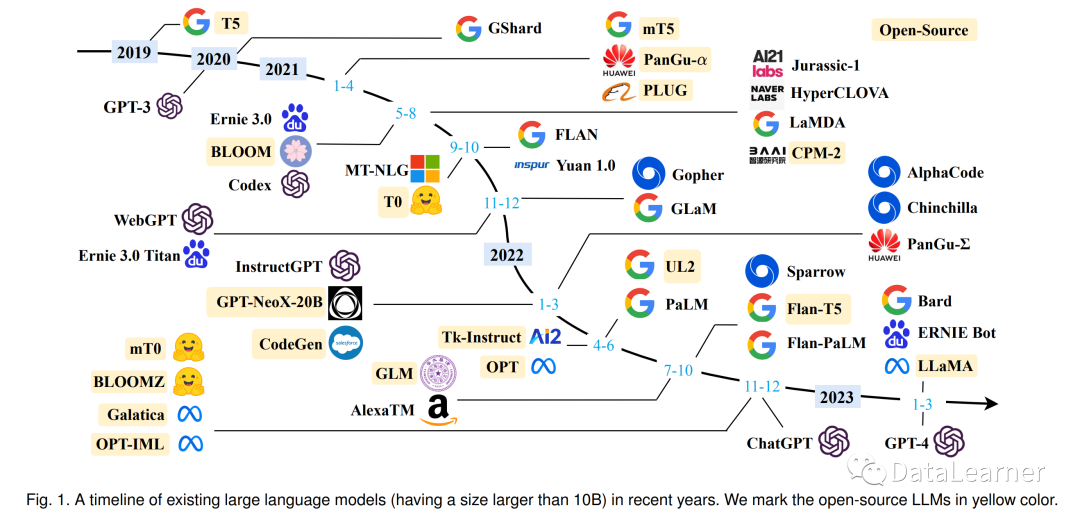
其中黄色的部分是开源的模型。可以看到,所谓的OpenAI其实基本上没有开源的模型,反而是Meta、Google开源的模型较多。而2021年之后,各家发布的模型也开始增多,其中一眼望去,Google(包括DeepMind)发布的模型相当多(尽管似乎影响力不够)。
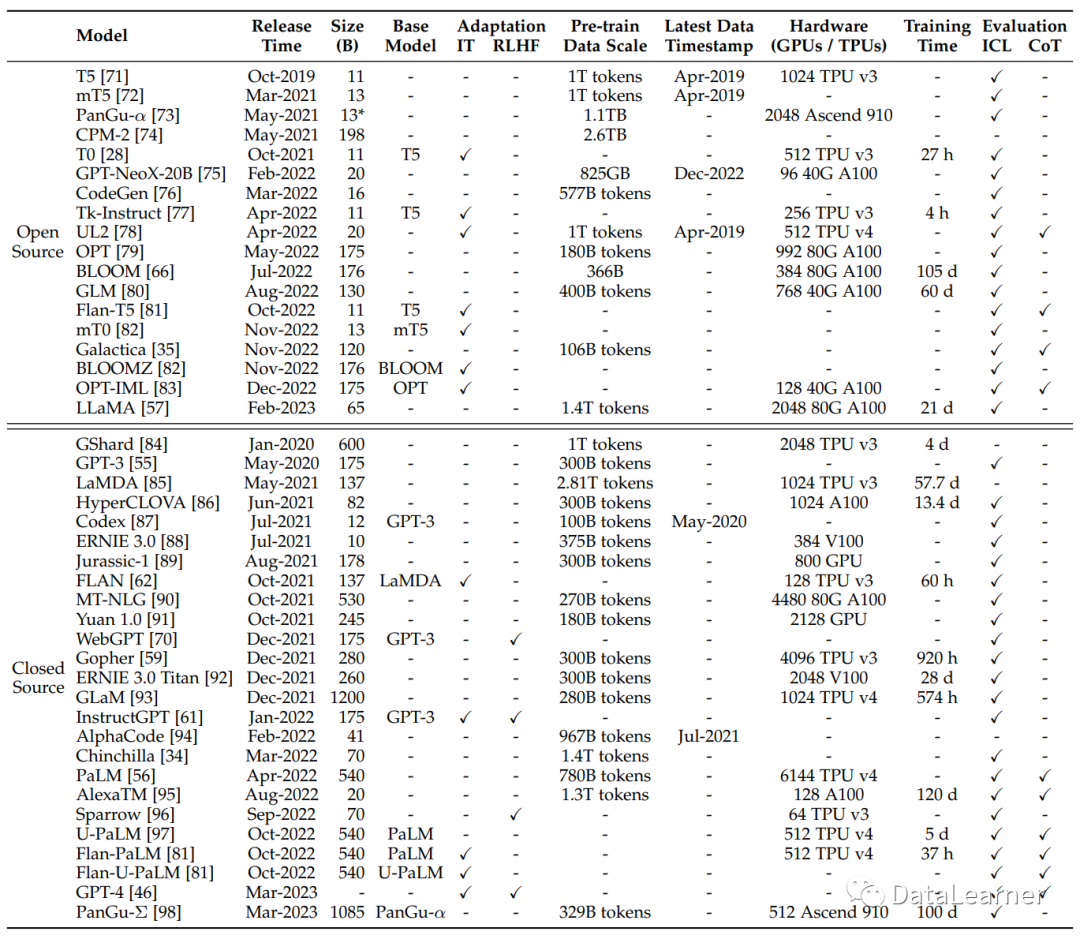
下图是所有的模型统计结果:
现有大模型使用的语料统计
当前大模型使用的语料大多数是公开数据集,包括BookCorpus、CommonCrawl、Reddit Links、Wikipedia等都是常用的数据集。下图总结了现有模型使用的数据集情况:
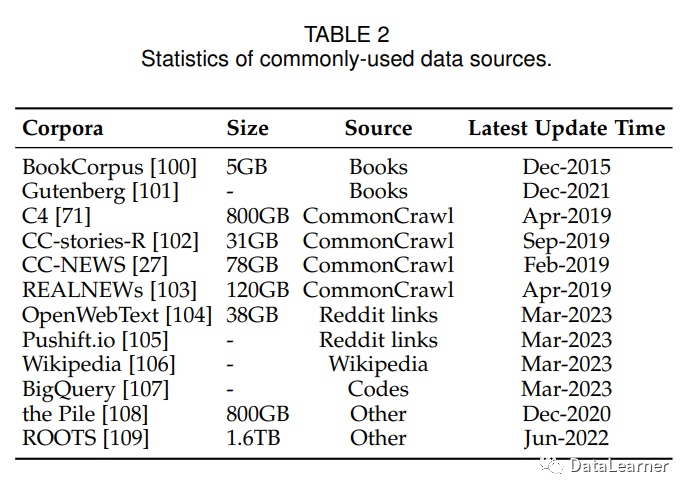
从图中可以看出,LLMs不再依赖单一的语料库,而是利用多个数据源进行预训练。因此,现有研究通常混合几个现成的数据集(例如C4、OpenWebText和Pile),然后进行进一步的处理以获得预训练语料库。此外,为了训练适应于特定应用程序的LLMs,从相关来源(例如维基百科和BigQuery)提取数据以丰富预训练数据中的相应信息也非常重要。
现有大模型使用的库(开源软件)
在这部分中,论文简要介绍了一系列可用于开发LLM的库。
- Transformers 是一个使用Transformer架构构建模型的开源Python库,由Hugging Face开发和维护。它具有简单且用户友好的API,使得使用和自定义各种预训练模型以及数据集处理和评估工具变得容易。它是一个强大的库,拥有庞大而活跃的用户和开发者社区,他们定期更新和改进模型和算法。
- DeepSpeed是由微软开发的基于PyTorch的深度学习优化库,已被用于训练多个LLM,如GPT-Neo和BLOOM [66]。它提供各种分布式训练的优化技术,如内存优化(ZeRO技术)、梯度检查点和管道并行。此外,它还提供了微调和评估这些模型的API。
- Megatron-LM 是由NVIDIA开发的基于PyTorch的深度学习库,用于训练大规模语言模型。它还提供了丰富的分布式训练优化技术,包括模型和数据并行、混合精度训练、FlashAttention和梯度检查点。这些优化技术可以显著提高训练效率和速度,实现跨GPU和机器的高效分布式训练。
- JAX 是由Google Brain开发的高性能机器学习Python库,允许用户在具有硬件加速支持(GPU或TPU)的数组上轻松执行计算。它支持在各种设备上进行计算,并提供了几个方便的功能,如即时编译加速和自动批处理。
- Colossal-AI是由EleutherAI开发的用于训练大规模语言模型的深度学习库。它是建立在JAX之上的,支持用于训练的优化策略,如混合精度训练和并行处理。最近,基于LLaMA [57],使用Colossal-AI开发了名为ColossalChat [119] 的ChatGPT模型,公开发布了两个版本(7B和13B)。
- BMTrain [120] 是由OpenBMB开发的高效库,用于以分布式方式训练具有大规模参数的模型,其强调代码简单性、低资源占用和高可用性。BMTrain已经将几个常见的LLM(例如Flan-T5 [81]和GLM [80])整合到其ModelCenter中,开发人员可以直接使用这些模型。
- FastMoE [121] 是MoE(即专家混合)模型的专用训练库。它是建立在PyTorch之上的,其设计优先考虑了效率和用户友好性。FastMoE简化了将Transformer模型转换为MoE模型的过程,并在训练期间支持数据并行和模型并行。
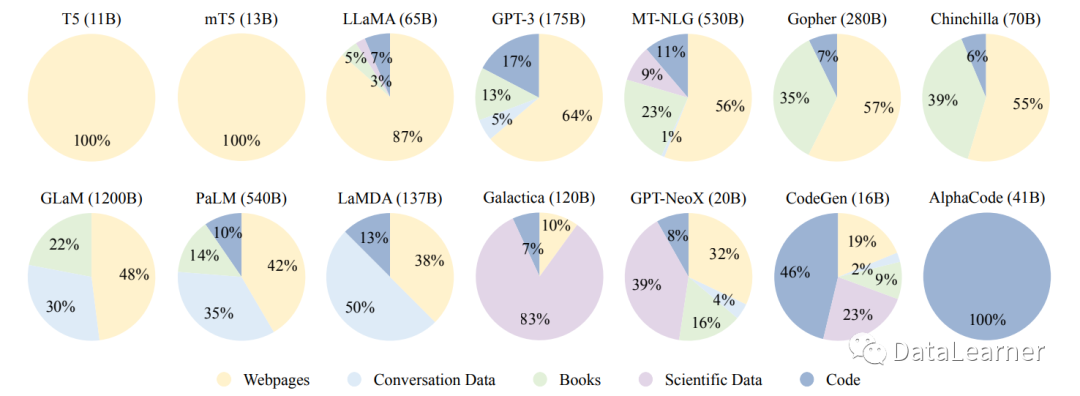
现有大模型预训练数据源比例
为了开发一款能力强大的LLM,收集来自各种数据源的大量自然语言语料库是关键。现有的LLM主要利用各种公共文本数据集的混合作为预训练语料库。下图显示了几个现有LLM的预训练数据来源的分布情况。
预训练大模型典型的数据预处理流程
在收集大量文本数据后,必须对其进行预处理以构建预训练语料库,尤其是去除噪音、冗余、无关和潜在有害数据,这可能会极大地影响LLM的容量和性能。在本部分中,作者回顾了详细的数据预处理策略,以提高收集到的数据质量。预处理LLM的预训练数据的典型流程已在下图中说明。

现有大模型使用的架构和训练细节
由于Transformer架构具有出色的可并行性和容量,因此已成为开发各种LLM的事实上的主干,使得将语言模型扩展到数千亿甚至万亿个参数成为可能。一般来说,现有LLM的主流架构可以大致分为三种主要类型,即编码器-解码器、因果解码器和前缀解码器。
下图展示了主流大模型采用的模型架构。
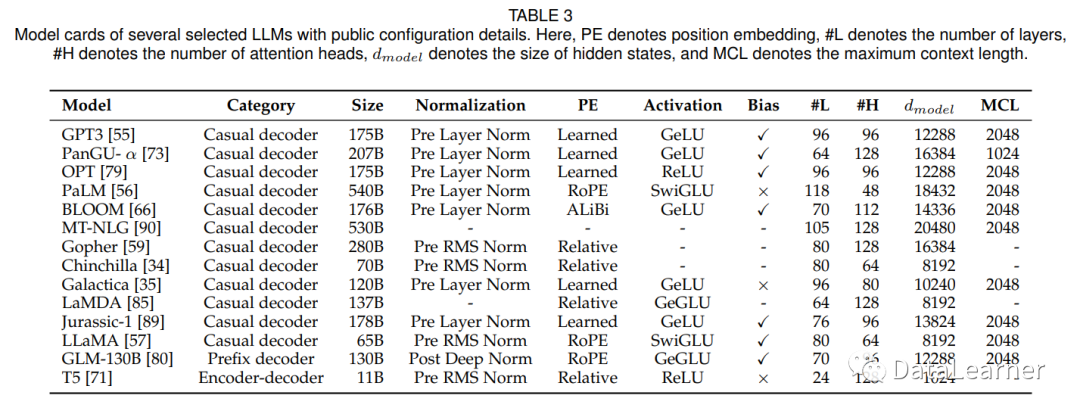
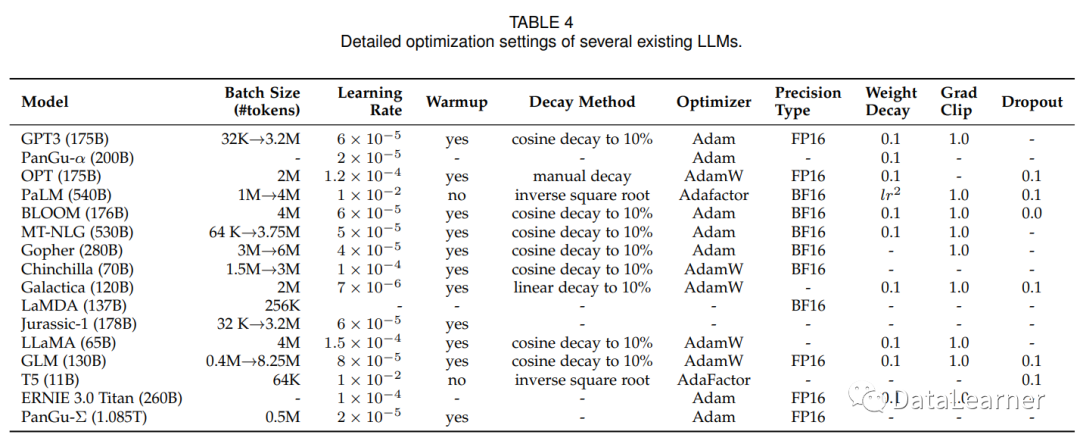
表格四展示了主流模型的一些训练细节,包括批次大小、学习速率等。
这部分论文包含了很多其它的结论,我们不一一列举。
这份大模型综述我已经打包好了,还有完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】