Classify Leaves | Kaggle
上面是数据集
数据导入与数据处理
%matplotlib inline
import torch
from torch.utils import data as Data
import torchvision
from torch import nn
import torchvision.models as models
from IPython import display
import os
import pandas as pd
import random
import PIL
import numpy as np将标签转成类别
imgpath = os.getcwd()
trainlist = pd.read_csv(f"{imgpath}/train.csv")
num2name = list(trainlist["label"].value_counts().index)
random.shuffle(num2name)
name2num = {}
for i in range(len(num2name)):
name2num[num2name[i]] = i自定义数据集
class Leaf_data(Data.Dataset):
def __init__(self,path,train,transform=lambda x:x) -> None:
super().__init__()
self.path = path
self.transform = transform
self.train = train
if train:
self.datalist = pd.read_csv(f"{path}/train.csv")
else:
self.datalist = pd.read_csv(f"{path}/test.csv")
def __getitem__(self, index):
res = ()
tmplist = self.datalist.iloc[index,:]
for i in tmplist.index:
if(i=="image"):
res += self.transform(PIL.Image.open(f"{self.path}/{tmplist[i]}")),
else:
res += name2num[tmplist[i]],
if(len(res)<2):
res+= tmplist[i],
return res
def __len__(self)->int:
return len(self.datalist)准备工作
画图、计算loss、累加器函数等,再之前文章中已经介绍过的,不必一句一句弄明白
def try_gpu():
if(torch.cuda.device_count()>0):
return torch.device('cuda')
return torch.device('cpu')
def accuracy(y_hat, y): #@save
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1) #找出输入张量(tensor)中最大值的索引
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
def evaluate_accuracy(net, data_iter): #@save
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
class Accumulator: #@save
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
import matplotlib.pyplot as plt
from matplotlib_inline import backend_inline
def use_svg_display():
"""使⽤svg格式在Jupyter中显⽰绘图"""
backend_inline.set_matplotlib_formats('svg')
def set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend):
"""设置matplotlib的轴"""
axes.set_xlabel(xlabel)
axes.set_ylabel(ylabel)
axes.set_xscale(xscale)
axes.set_yscale(yscale)
axes.set_xlim(xlim)
axes.set_ylim(ylim)
if legend:
axes.legend(legend)
axes.grid()
class Animator: #@save
"""在动画中绘制数据"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# 增量地绘制多条线
if legend is None:
legend = []
use_svg_display()
self.fig, self.axes = plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
import time
class Timer: #@save
"""记录多次运行时间"""
def __init__(self):
self.times = []
self.start()
def start(self):
"""启动计时器"""
self.tik = time.time()
def stop(self):
"""停止计时器并将时间记录在列表中"""
self.times.append(time.time() - self.tik)
return self.times[-1]
def avg(self):
"""返回平均时间"""
return sum(self.times) / len(self.times)
def sum(self):
"""返回时间总和"""
return sum(self.times)
def cumsum(self):
"""返回累计时间"""
return np.array(self.times).cumsum().tolist()模型构建或载入
如果是第一次训练则可以下载再ImageNet上预训练好的resnet18或者更大的模型,如果之前已经训练有保存好的模型则可以接着训练
model_path = 'pre_res_model.ckpt'
def save_model(net):
torch.save(net.state_dict(),model_path)
def init_weight(m):
if type(m) in [nn.Linear,nn.Conv2d]:
nn.init.xavier_normal_(m.weight)
model_path = 'pre_res_model.ckpt'
first_train = False
if first_train:
net = torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.IMAGENET1K_V1)
net.fc = nn.Linear(in_features=512, out_features=len(name2num), bias=True)
net.fc.apply(init_weight)
else:
net = models.resnet18()
net.fc = nn.Linear(in_features=512, out_features=len(name2num), bias=True)
net.fc.apply(init_weight)
model_weights = torch.load(model_path)
net.load_state_dict(model_weights)
net.to(try_gpu())
lr = 1e-4
parames = [parame for name,parame in net.named_parameters() if name not in ["fc.weight","fc.bias"]]
trainer = torch.optim.Adam([{"params":parames},
{"params":net.fc.parameters(),"lr":lr*10}],lr=lr)
LR_con = torch.optim.lr_scheduler.CosineAnnealingLR(trainer,1,0)
loss = nn.CrossEntropyLoss(reduction='none')模型训练
控制一批的训练
def train_batch(X,y,net,loss,trainer,devices):
if isinstance(X,list):
X = [x.to(devices) for x in X]
else:
X = X.to(devices)
y = y.to(devices)
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred,y)
l.sum().backward()
trainer.step()
LR_con.step()
return l.sum(),accuracy(pred,y)
多个epoch
def train(train_data,test_data,net,loss,trainer,num_epochs,device = try_gpu()):
best_acc = 0
timer = Timer()
plot = Animator(xlabel="epoch",xlim=[1,num_epochs],legend=['train loss','train acc','test loss'],ylim=[0,1])
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = Accumulator(4)
for i, (features, labels) in enumerate(train_data):
timer.start()
l, acc = train_batch(
features, labels, net, loss, trainer, device)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
test_acc = evaluate_accuracy_gpu(net, test_data,device=device)
if(test_acc>best_acc):
save_model(net)
best_acc = test_acc
plot.add(epoch + 1, (metric[0] / metric[2], metric[1] / metric[3], test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print()
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(device)}')
print(f"best acc {best_acc}")
return metric[0] / metric[2],metric[1] / metric[3],test_acctransfroms和dataloader
batch = 128
num_epochs = 4
norm = torchvision.transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
augs = torchvision.transforms.Compose([
torchvision.transforms.Resize(224),
torchvision.transforms.RandomHorizontalFlip(p=0.5),
torchvision.transforms.ToTensor(),norm
])
train_data,valid_data = Data.random_split(
dataset=Leaf_data(imgpath,True,augs),
lengths=[0.8,0.2]
)
train_dataloder = Data.DataLoader(train_data,batch,True)
valid_dataloder = Data.DataLoader(valid_data,batch,True)
训练
train(train_dataloder,valid_dataloder,net,loss,trainer,num_epochs)1-4轮:

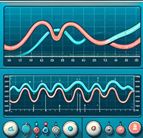
这个就是接着训练的,每次训练四轮 :

继续接着训练,这里到了第12轮:

接着训练,现在到了20轮,基本上再训练个10轮应该还是能把精度再更进一步提一提的。

这张图片是早上训练10个epoch后的四个epoch,可以看到结果相当不错。

提交
net.load_state_dict(torch.load(model_path))
augs = torchvision.transforms.Compose([
torchvision.transforms.Resize(224),
torchvision.transforms.ToTensor(),norm
])
test_data = Leaf_data(imgpath,False,augs)
test_dataloader = Data.DataLoader(test_data,batch_size=64,shuffle=False)
res = pd.DataFrame(columns = ["image","label"],index=range(len(test_data)))
net = net.cpu()
count = 0
for X,y in test_dataloader:
preds = net(X).detach().argmax(dim=-1).numpy()
preds = pd.DataFrame(y,index=map(lambda x:num2name[x],preds))
preds.loc[:,1] = preds.index
preds.index = range(count,count+len(y))
res.iloc[preds.index] = preds
count+=len(y)
print(f"loaded {count}/{len(test_data)} datas")
res.to_csv('mysubmission.csv', index=False)小结
- resnet18作为一个40M的模型,训练这个200M的数据集是没有问题的,基本没有过拟合或者欠拟合
- 在ImageNet上预训练好的resnet18,将最后一层改为176个类别输出,这样的迁移学习效果是非常好的
- 要学会模型载入与保存,这样可以不断训练出更好的模型
- 数据预处理对于不熟悉python的人来说可能是最耗时的一部分