模拟一次XFS故障
在平常处理问题时经常会遇到文件系统损坏的问题,有时候是日志里面出现了报错但文件系统还是可以读写,有时候是文件系统已经无法读写了

分析下不同现象的原因和一些可能出现的情况。
通过直接修改块存储损坏文件系统
1、制作一个xfs文件系统,创建时会打印块大小bsize 4096和 inode大小iszie 512,如果是已经存在的xfs可以通过xfs_info /dev/nvme1n1查看
#mkfs.xfs /dev/nvme1n1
meta-data=/dev/nvme1n1 isize=512 agcount=16, agsize=163840 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1 bigtime=1 inobtcount=1
data = bsize=4096 blocks=2621440, imaxpct=25
= sunit=1 swidth=1 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=16384, version=2
= sectsz=512 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
2、查看inode信息
[root@ip-172-31-35-68 mnt]# ls -Rli
.:
total 0
131 drwxr-xr-x. 2 root root 22 Aug 6 05:24 testxfs
./testxfs:
total 0
132 -rw-r--r--. 1 root root 0 Aug 6 05:24 testfile
3、计算inode132的便宜量
-
计算 inode 132 在 inode 表中的偏移量:
inode_offset = inode_number * inode_size inode_offset = 132 * 512 = 67584 bytes -
计算 inode 132 所在的块号:
block_number = inode_offset / block_size block_number = 67584 / 4096 = 16 blocks -
计算 inode 132 在块内的偏移量:
offset_within_block = inode_offset % block_size offset_within_block = 67584 % 4096 = 2048 bytes=0x800 bytes因此,inode 132 在第 16 个块内的偏移量为 2048 字节。
查看一下indeo 132的信息core.magic = 0x494e ,magic 字段通常用于标识文件系统结构的类型。每种不同的结构都有一个唯一的 magic 数值,用于快速验证该结构的类型和一致性。magic 针对不同类型的元数据永远不会变
[root@ip-172-31-35-68 /]# xfs_db -r /dev/nvme1n1
xfs_db> inode 132
xfs_db> p
core.magic = 0x494e
core.mode = 0100644
core.version = 3
core.format = 2 (extents)
.......
4、现在来尝试修改magic来损坏文件系统
# 读取第16个block内容,拷贝到block_data_16.bin文件
dd if=/dev/nvme1n1 of=block_data_16.bin bs=4096 count=1 skip=16
#按照之前的记录16个block 的2048个字节是indoe 132,转换为16进制是0x800,修改block_data_16.bin的0x800位(hexedit/xdd)的magic0x494e为0x0043
#dd回磁盘
dd if=block_data_16.bin of=/dev/nvme1n1 bs=4096 count=1 seek=16
#检查修改是否成功
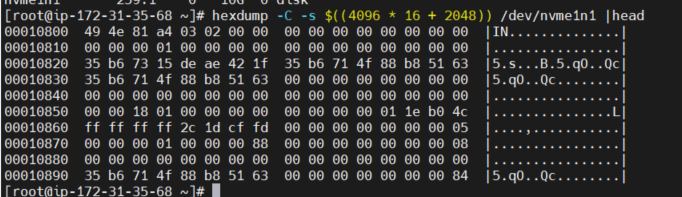
hexdump -C -s $((4096 * 16 + 2048)) /dev/nvme1n1 |head
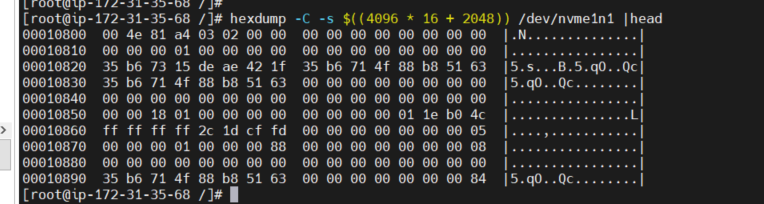
修改完成后访问还是没有问题,这是因为只要访问过一次在内存中就会保存inode信息,不需要重新读取,但当内存里面没有了(内存回收/重新启动等),则无法访问

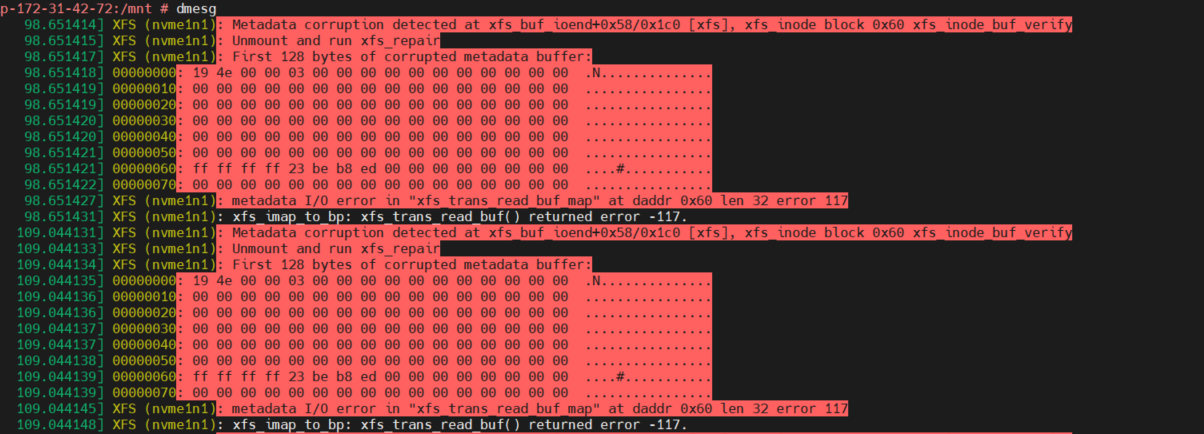
5、重新挂载时候会报错mount: /mnt: mount(2) system call failed: Structure needs cleaning. 通过dmesg日志中的记录可以看到在xfs_inode这个block的的magic已经为0x004e,校验失败导致文件系统需要修复,这是因为mount的时候会进行redo log,当redo loge时发现内存中的元数据与文件系统中的元数据不一致导致mount时的校验不通过
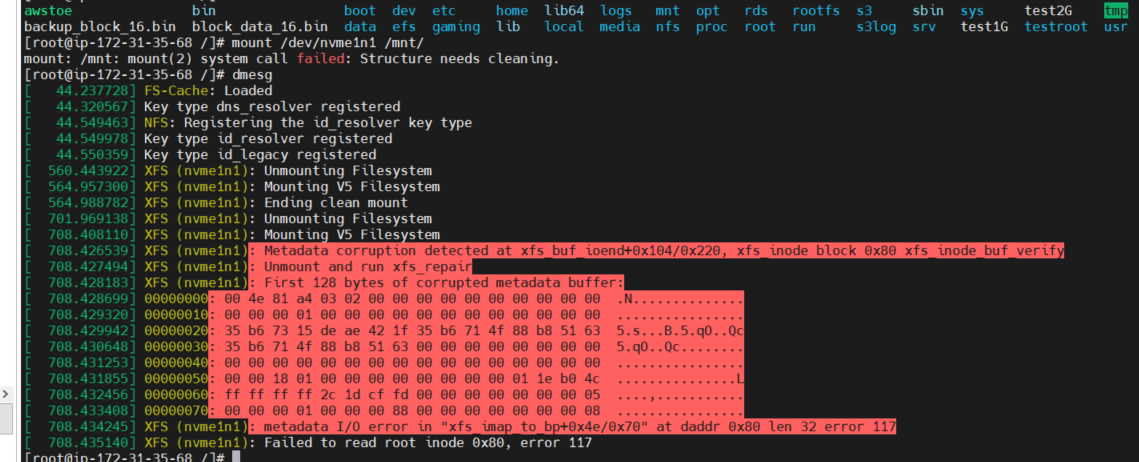
XFS标准修复流程
修复,xfs有一套标准的修复步骤,不过需要按照恰当的步骤来进行恢复,否则造成的损失难以挽回。
#备份整个文件系统,这一步保证如果接下来的步骤出现问题,仍然有重来的机会。
创建snapshot/dd
#重新mount 整个文件系统。这一步极度容易忽略。如果直接用xfs_repair 进行修复,则无法充分利用日志信息。日志信息中包含有因为断电而没有完整进行的操作。重新mount 文件系统,系统会在mount 时重新执行那些因为断电而没有完整进行的操作。执行mount 完成后,等待几秒,等待这些操作真正落盘.完成后尝试xfs_repair 修复,修复前可通过xfs_repair -n 先查看修复内容,并保留截图以供后续问题排查。
mount /dev/nvme1n1 /mnt/
umount /mnt
xfs_repair -n /dev/nvme1n1 > /tmp/xfs_repair.log 2>&1
xfs_repair /dev/nvme1n1
#修复时会将操作打印文件系统的错误,例如检查到文件系统的inode块损坏,和文件偏移等信息
Metadata corruption detected at 0x5634a0011d66, xfs_inode block 0x80/0x4000
bad CRC for inode 132
bad magic number 0x4e on inode 132
bad CRC for inode 132, will rewrite
bad magic number 0x4e on inode 132, resetting magic number
cleared inode 132
#如果无法修复的话可能需要丢弃日志进行修复
xfs_repair -L /dev/nvme1n1
完整的修复日志如下:
[root@ip-172-31-35-68 /]# xfs_repair /dev/nvme1n1
Phase 1 - find and verify superblock...
- reporting progress in intervals of 15 minutes
Phase 2 - using internal log
- zero log...
- 06:10:26: zeroing log - 16384 of 16384 blocks done
- scan filesystem freespace and inode maps...
- 06:10:26: scanning filesystem freespace - 16 of 16 allocation groups done
- found root inode chunk
Phase 3 - for each AG...
- scan and clear agi unlinked lists...
- 06:10:26: scanning agi unlinked lists - 16 of 16 allocation groups done
- process known inodes and perform inode discovery...
- agno = 15
- agno = 0
Metadata corruption detected at 0x5634a0011d66, xfs_inode block 0x80/0x4000
bad CRC for inode 132
bad magic number 0x4e on inode 132
bad CRC for inode 132, will rewrite
bad magic number 0x4e on inode 132, resetting magic number
cleared inode 132
- agno = 1
- agno = 2
- agno = 3
- agno = 4
- agno = 5
- agno = 6
- agno = 7
- agno = 8
- agno = 9
- agno = 10
- agno = 11
- agno = 12
- agno = 13
- agno = 14
- 06:10:26: process known inodes and inode discovery - 64 of 64 inodes done
- process newly discovered inodes...
- 06:10:26: process newly discovered inodes - 16 of 16 allocation groups done
Phase 4 - check for duplicate blocks...
- setting up duplicate extent list...
- 06:10:26: setting up duplicate extent list - 16 of 16 allocation groups done
- check for inodes claiming duplicate blocks...
- agno = 0
- agno = 1
- agno = 4
- agno = 5
- agno = 6
- agno = 8
- agno = 9
- agno = 10
- agno = 11
- agno = 12
- agno = 13
- agno = 14
- agno = 15
- agno = 2
- agno = 7
- agno = 3
- 06:10:26: check for inodes claiming duplicate blocks - 64 of 64 inodes done
Phase 5 - rebuild AG headers and trees...
- 06:10:26: rebuild AG headers and trees - 16 of 16 allocation groups done
- reset superblock...
Phase 6 - check inode connectivity...
- resetting contents of realtime bitmap and summary inodes
- traversing filesystem ...
- traversal finished ...
- moving disconnected inodes to lost+found ...
Phase 7 - verify and correct link counts...
- 06:10:26: verify and correct link counts - 16 of 16 allocation groups done
done
修复完成后我们可以看到indoe 132的magic已经修复完成了