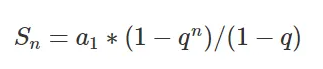目录
一.nn.Module
二.优化器类
三.损失函数
四.在GPU上运行代码
五.常见的优化算法
1.梯度下降算法
2.动量法:
3.AdaGrad
4.RMSProp
六.Pytorch中的数据加载
1.数据集类
2.迭代数据集
2.Pytorch自带的数据集
一.nn.Module
nn.Modul是torch.nn提供的一个类,是pytorch中我自定义网格的一个基类,注意:
1.__init__需要调用super方法,继承父类的属性和方法
2.farward方法必须实现,用来定义我们的网络的向前计算的过程
3.这个类里面有一些已经定义好的模型。比如nn.Linear线性模型,也被称为全链接层,传入的参数为输入的数量和输出的数量(nn.Linear(输入的数量,输出的数量))。
4.这个类中已经定义好了__call_方法,也就是在使用自定义的模型的时候主要传入数据,内部会自动调用forward方法
举个栗子:
import torch
from torch import nn
class Module(nn.Module):
def __init__(self):
# 继承nn.Module中的属性和方法
super(Module, self).__init__()
# 创建一个y=wx+b形式的模型,这个是nn.Module里面自带的模型
self.linear = nn.Linear(1, 1)
def forward(self, x):
# 调用上面创建好的模型
out = self.linear(x)
return out
x = torch.rand([50, 1])
print(type(x))
model = Module()
predict = model(x)
print(predict)二.优化器类
1.优化器可以理解为torch为我们封装来更新参数的方法,比如创建的随机梯度下降每次都要跟新的梯度等等。
2.优化器类由torch.optim提供
比如要使用SGD方法:torch.optim.SGD(参数, 学习率)
3.参数可以使用model.parameters()来获取,这个方法是获取模型中所有requires_grad=True的参数
4.优化类的使用方法:1.实例话,2.所有参数的梯度置为0,3.反向传播计算梯度,4.更新参数
optimizer=optim.SGD(model.parameters(),lr=1e-3) # 实例话
optimizer.zero_grad() # 将梯度置为0
loss.backworad() # 计算梯度
optimizer.step() # 更新模型中的参数三.损失函数
torch中也封装许多计算损失函数的方法
1.均方误差:nn.MSELoss()
2.交叉熵损失:nn.CrossEntropyLoss()
import torch
from torch import nn,optim
class Module(nn.Module):
def __init__(self):
# 继承nn.Module中的属性和方法
super(Module, self).__init__()
# 创建一个y=wx+b形式的模型,这个是nn.Module里面自带的模型
self.linear = nn.Linear(1, 1)
def forward(self, x):
out = self.linear(x)
return out
x=torch.rand([50,1])
y_true=x*3+1
model=Module()
criterion=nn.MSELoss()
optimizer=optim.SGD(model.parameters(),lr=1e-3)
for i in range(3000):
y_predict=model(x)
loss=criterion(y_true,y_predict)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%200==0:
print(loss)
# 模型评估
model.eval() # 设置模型为预测模式
predict=model(x) # 计算已经训练过后的模型的预测值
predict=predict.data.numpy() # 将数据转化为numpy形式打印
print(predict)当我们自定义模型时,模型会有训练模式,和预测模式。当我们的训练集和测试集的数据一样的时候着两个模式没区别,但是不一样的时候我们就要切换了
四.在GPU上运行代码
当模型太大,数据太多的时候,为了加快训练速度,那么就要使用到GPU了
1.判断GPU是否可用:torch.cuda.is_available()
torch.device("cuda:0" if torch.cuda.is_available() else "cpu")2.把模型参数和数据转化为cuda的类型
model.to(device)
x_true.to(device)3.在GPU上计算的结果也为cuda的数据类型,需要转化为numpyhuo
import torch
from torch import nn,optim
class Module(nn.Module):
def __init__(self):
# 继承nn.Module中的属性和方法
super(Module, self).__init__()
# 创建一个y=wx+b形式的模型,这个是nn.Module里面自带的模型
self.linear = nn.Linear(1, 1)
def forward(self, x):
out = self.linear(x)
return out
# 判断能否用GPU
device=torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 创建数据并将数据转化为cuda类型
x=torch.rand([50,1])
x.to(device)
y_true=x*3+1
y_true.to(device)
# 创建模型对象
model=Module().to(device)
# 实例化损失函数
criterion=nn.MSELoss()
# 实例化优化器
optimizer=optim.SGD(model.parameters(),lr=1e-3)
# 开始迭代
for i in range(3000):
# 计算当前预测值
y_predict=model(x)
# 计算当前损失
loss=criterion(y_true,y_predict)
# 将梯度置为0
optimizer.zero_grad()
# 计算梯度
loss.backward()
# 更新参数
optimizer.step()
if i%200==0:
print(loss)
# 模型评估
model.eval() # 设置模型为预测模式
predict=model(x) # 计算已经训练过后的模型的预测值
predict=predict.detach().numpy() # 将数据转化为numpy形式打印
print(predict)五.常见的优化算法
1.梯度下降算法
在前面的机器学习阶段的时候详细讲过
梯度下降算法:对所有样本进行迭代,好处是效果最好,但是速度很漫,尤其是深度学习中数据都是非常大的情况下
随机梯度下降:为了改善训练熟读过慢的问题·,从样本中随机抽出一组,训练后按梯度更新一次,然后在抽一组,在更新一次,如此反复。对于每次都要将所有样本一起计算的训练速度提升了很多
小批量梯度下降算法:每次从样本中随机抽取一小批进行训练,而不是一组,这样即保证了效果又保证了速度
2.动量法:
对于上面的随机梯度下将算法(SGD),虽然算法又很好的速度,但是效果来说还是差了一点,在下降的时候SGD总是在最优点的附近徘徊,不能到最优点。而且SGD需要挑选一个合适的学习率,如果选择的学习率太小,会导致算法收敛的太慢,学习率太大会导致每次跨的步伐太大而跳过最优点。而动量法就是用来解决这类问题的。

history表示上一次的梯度,gradent表示现在的梯度
相当于每次在进行参数更新的时候,都会将之前的速度考虑进来,每个参数在各方向上的移动幅度不仅取决于当前的梯度,还取决于过去各个梯度在各个方向上是否一致,如果一个梯度一直沿着当前方向进行更新,那么每次更新的幅度就越来越大,如果一个梯度在一个方向上不断变化,那么其更新幅度就会被衰减,这样我们就可以使用一个较大的学习率,使得收敛更快,同时梯度比较大的方向就会因为动量的关系每次更新的幅度减少
本质上说,动量法就仿佛我们从高坡上推一个球,小球在向下滚动的过程中积累了动量,在途中也会变得越来越快,最后会达到一个峰值,对应于我们的算法中就是,动量项会沿着梯度指向方向相同的方向不断增大,对于梯度方向改变的方向逐渐减小,得到了更快的收敛速度以及更小的震荡。
3.AdaGrad
Adagrad优化算法就是在每次使用一个 batch size 的数据进行参数更新的时候,算法计算所有参数的梯度,那么其想法就是对于每个参数,初始化一个变量 s 为 0,然后每次将该参数的梯度平方求和累加到这个变量 s 上,然后在更新这个参数的时候,学习率就变为:

首先η为初始学习率,这里的 ϵ是为了数值稳定性而加上的,因为有可能 s 的值为 0,那么 0 出现在分母就会出现无穷大的情况,通常 ϵ 取 10的负10次方,这样不同的参数由于梯度不同,他们对应的 s 大小也就不同,所以上面的公式得到的学习率也就不同,这也就实现了自适应的学习率。
是白了就是自动更新学习率达到自适应
4.RMSProp
RMSProp(Root Mean Square Propagation)是一种自适应学习率的优化算法,主要用于深度学习中的参数更新。旨在解决 Adagrad 算法在深度学习训练过程中学习率逐渐减小直至无法进一步学习的问题。
Adagrad 算法通过累积历史梯度的平方来调整每个参数的学习率,从而实现对频繁更新参数的惩罚和对不频繁更新参数的鼓励。然而,Adagrad 也存在一个问题:随着参数更新的累积,学习率会越来越小,最终导致学习过程提前结束。RMSProp 通过引入一个衰减系数来解决这个问题,使得历史信息能够指数级衰减,从而避免了学习率持续下降的问题。

其中,⊙ 表示元素乘积,β 是衰减系数(通常设置为 0.9),用于控制历史信息的衰减速度,ϵ 是为了避免除以 0 的小常数(通常设置为 1 e − 8 )。
六.Pytorch中的数据加载
1.数据集类
在torch中提供了数据集的基类torch.utils.data.Dataset,继承这个基类,可用非常快速的实现对数据的加载
在我们自定义数据集类的过程中,需要继承Dataset类,还需要实现两个方法
1.__len__方法,能够全局的获取数据个数
2.__getitem__方法,能通过索引的方法获取数据,比如dataset[1],dataset[2]
from torch.utils.data import Dataset, DataLoader
import pandas as pd
data_path = '数据的路径'
# 创建数据集类
class CifarDataset(Dataset):
def __init__(self):
# 读取数据
lines = open(data_path, 'r')
# 将数据转化为DataFrame类型
self.data = pd.DataFrame(lines)
def __getitem__(self, index):
# 通过索引切片获取自己读取
single_item = self.data.iloc[index, :]
return single_item
def __len__(self):
# 返回数据长度
return self.data.shape[0]2.迭代数据集
读取数据后出来获得数据以外还有,批处理数据,打乱数据(方便随机),使用多线程并行加载数据等,而DataLoader中就提供了这些方法,只要加入几个参数就可以了
from torch.utils.data import Dataset, DataLoader
import pandas as pd
data_path = '数据的路径'
# 创建数据集类
class CifarDataset(Dataset):
def __init__(self):
# 读取数据
lines = open(data_path, 'r')
# 将数据转化为DataFrame类型
self.data = pd.DataFrame(lines)
def __getitem__(self, index):
# 通过索引切片获取自己读取
single_item = self.data.iloc[index, :]
return single_item
def __len__(self):
# 返回数据长度
return self.data.shape[0]
dataset=CifarDataset()
# batch_size:传入batch的大小,常用128,256等等
# shuffle:是否打乱数据
# num_workers:加载数据的线程数
data_loader=DataLoader(dataset=dataset,batch_size=10,shuffle=True,num_workers=2)
for data in data_loader:
print(data)2.Pytorch自带的数据集
pytorch中自带的数据集由两个上层api提供,torchvision和torchtext
torchvision提供了对图片数据处理相关的api和数据
torchtext提供了对文本数据处理相关的api和数据
需要使用的时候直接:torchvision.datasets.(需要的数据)。或者torchtext.datasets.(需要的数据)