系列文章目录
1.1 什么是DataWorks
1.2 功能特性
1.2.1 数据集成:全领域数据汇聚
1.2.3 数据建模:智能数据建模
1.2.4 数据分析:即时快速分析
1.2.5 数据质量:全流程的质量监控
1.2.6 数据地图:统一管理,跟踪血缘
1.2.7 数据服务:低成本快速发布API
1.2.8 开放平台:能力全面开放
1.2.9 迁移助手与迁云服务
1.3 各引擎使用说明
1.3.1 什么是MaxCompute
1.3.2 MaxCompute功能特性
1.3.3 DataWorks与MaxCompute的关系
文章目录
- 系列文章目录
- 前言
- 1.1 什么是DataWorks
- 1.2 功能特性
- 1.2.1 数据集成:全领域数据汇聚
- 1.2.3 数据建模:智能数据建模
- 1.2.4 数据分析:即时快速分析
- 1.2.5 数据质量:全流程的质量监控
- 1.2.6 数据地图:统一管理,跟踪血缘
- 1.2.7 数据服务:低成本快速发布API
- 1.2.8 开放平台:能力全面开放
- 1.2.9 迁移助手与迁云服务
- 1.3 各引擎使用说明
- 1.3.1 什么是MaxCompute
- 1.3.2 MaxCompute功能特性
- 1.3.3 DataWorks与MaxCompute的关系
前言
本文主要详解了DataWorks基本功能,为第一部分:
由于篇幅过长,分章节进行发布。
后续:
数据集成的使用
数据开发流程及操作
运维中心的使用
1.1 什么是DataWorks
DataWorks基于MaxCompute、Hologres、EMR、AnalyticDB、CDP等大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据开发治理平台。
产品架构:
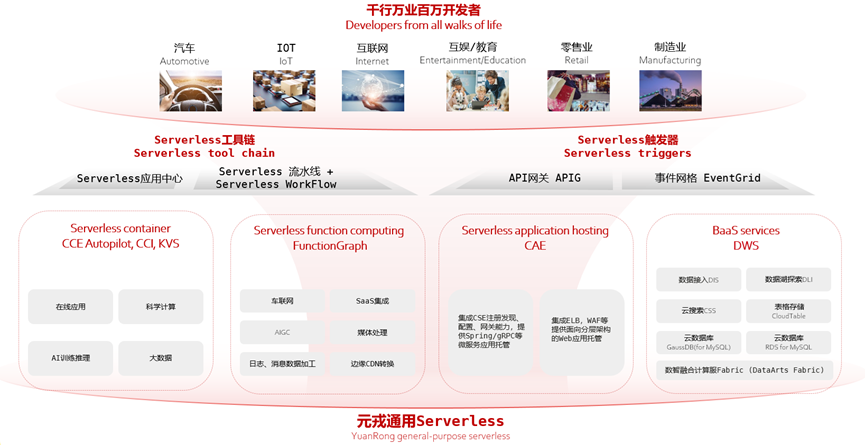
DataWorks十多年沉淀数百项核心能力,通过智能数据建模、全域数据集成、高效数据生产、主动数据治理、全面数据安全、数据分析服务六大全链路数据治理的能力,帮助企业治理内部不断上涨的“数据悬河”,释放企业的数据生产力。

发展历史:
从2009年产品立项开始,DataWorks与阿里巴巴业务共同发展,结合MaxCompute、Hologres等大数据计算引擎的能力,跨越多个技术阶段,支撑阿里巴巴数据中台与数据治理建设。目前阿里巴巴集团内DataWorks每天活跃用户数超过5万人,平均每3个人就有1个人使用DataWorks,支持300多个数据应用,服务100多个阿里巴巴集团事业部。

2015年DataWorks正式上云,将多年沉淀的大数据建设方法论产品化输出,服务阿里云上客户,通过不断迭代的产品能力,DataWorks正在与各行各业的客户与合作伙伴一起,通过全链路数据治理,管得好数据、用得好数据,让数据从低质低效向高质高效流动。

1.2 功能特性
1.2.1 数据集成:全领域数据汇聚
DataWorks的数据集成功能模块是稳定高效、弹性伸缩的数据同步平台,致力于提供复杂网络环境下、丰富的异构数据源之间高速稳定的数据移动及同步能力。
DataWorks数据集成支持离线同步、实时同步,以及离线和实时一体化的全增量同步。
1.2.2 数据开发与运维中心:数据加工
DataWorks的数据开发(DataStudio)是数据加工的开发平台,运维中心是智能运维平台,基于这两个功能模块,可以在DataWorks上规范、高效地构建和运维数据开发工作流。
开发流程:

可视化的开发界面:

支持通过拖拉拽的方式构建任务流程,在统一的界面进行数据开发和调度配置。
任务监控与定位处理:

1.2.3 数据建模:智能数据建模
智能数据建模是阿里云DataWorks自主研发的智能数据建模产品,沉淀了阿里巴巴十多年来数仓建模方法论的最佳实践,包含数仓规划、数据标准、维度建模及数据指标四大模块,帮助企业在搭建数据中台、数据集市建设过程中提升建模及逆向建模的能力,并通过数据建模快速构建企业数据资产。
功能概述:
智能数据建模产品包含数仓规划、数据标准、维度建模、数据指标四大产品模块。

数仓规划:数仓规划支持数仓分层、数据域、数据集市等的规划,支持设置模型设计空间,不同部门可共享一套数据标准和数据模型。
数据标准:数据标准字段标准、标准代码、度量单位、命名词典的定义,支持标准代码自动生成质量规则,落标检查不再难。
维度建模:维度建模支持逆向建模,解决现有数仓的建模冷启动难题,支持可视化数仓维度建模,支持通过Excel文件导入模型和通过FML(一种类SQL的DSL)快速构建模型,支持与数据开发DataStudio无缝打通,自动生成ETL代码。
数据指标:数据指标支持原子指标、派生指标的定义与构建,与维度建模无缝打通,可根据原子指标和不同维度批量创建派生指标。
1.2.4 数据分析:即时快速分析
数据分析支持基于个人视角的数据上传、公共数据集、表搜索与收藏、在线SQL取数、SQL文件共享、SQL查询结果下载及用电子表格进行大屏幕数据查看等产品功能。

1.2.5 数据质量:全流程的质量监控
DataWorks的全流程数据质量监控功能提供了35种预设表级别、字段级别和自定义的监控模板。
数据质量支持对常见大数据存储(MaxCompute、E-MapReduce Hive、Hologres等)进行质量校验。从完整性、准确性、有效性、一致性、唯一性和及时性等多个维度,配置质量监控规则。并可以将质量监控规则与调度节点进行关联,当任务运行完成后便会触发质量规则校验,帮助用户第一时间感知问题数据,按需设置规则的强弱来控制任务是否失败退出,从而避免脏数据影响扩大,有效降低数据恢复处理的时间成本和费用成本。
1.2.6 数据地图:统一管理,跟踪血缘
DataWorks的数据地图功能可以实现对数据的统一管理和血缘的跟踪。
数据地图以数据搜索为基础,提供表使用说明、数据类目、数据血缘、字段血缘等工具,帮助数据表的使用者和拥有者更好地管理数据、协作开发。

1.2.7 数据服务:低成本快速发布API
DataWorks的数据服务功能模块是灵活轻量、安全稳定的数据API构建平台,旨在为企业提供全面的数据共享能力,帮助用户从发布审批、授权管控、调用计量、资源隔离等方面实现数据价值输出及共享开放。
数据服务支持通过零代码或自助SQL的双模式,将各类数据源下的数据表生成数据API,同时支持函数计算来辅助加工API的请求参数及返回结果。
数据服务采用Serverless架构,用户无需关心运行环境等基础设施,即可将API服务一键发布至API网关。

1.2.8 开放平台:能力全面开放
DataWorks开放平台提供了全面的开放能力,可以实现深度的系统集成、自动化操作、流程定义、业务监控等,欢迎广大用户及合作伙伴,基于DataWorks的开放平台来实现行业化、场景化的数据应用和插件。
DataWorks开放平台提供开放API(OpenAPI)、开放事件(OpenEvent)、扩展程序(Extensions)等能力。
开放API(OpenAPI)
通过OpenAPI可以实现用户的自有应用与DataWorks的深度集成,例如实现批量创建任务、发布任务、运维任务等,提升大数据处理效率,减少人工操作成本。
开放事件(OpenEvent)
通过OpenEvent可以允许用户订阅DataWorks中的系统事件,实时获取并响应事件变化,例如订阅表变更事件实现对核心表的实时监控,订阅任务变更事件实现自定义实时任务监控大屏。
扩展程序(Extensions)
Extensions则是将OpenAPI和OpenEvent有机结合起来的服务级插件,通过Extensions允许用户对DataWorks中的流程控制进行自定义,例如用户可以自定义任务发布管控插件,从而对不符合规范和要求的任务进行拦截。
1.2.9 迁移助手与迁云服务
DataWorks迁移助手支持将开源调度引擎的作业迁移至DataWorks,支持作业跨云、跨Region、跨账号迁移,实现DataWorks作业快速克隆部署,同时DataWorks团队联合大数据专家服务团队,上线迁云服务,快速实现数据与任务的上云。
迁移助手与迁云服务主要功能包括:
任务上云:实现将开源调度引擎的作业搬迁至DataWorks上。
DataWorks迁移:实现DataWorks体系内的开发成果互相迁移。
1.3 各引擎使用说明
DataWorks支持3种引擎,分别是MaxCompute,EMR,Hologres,其中最常见的是MaxCompute,以下介绍则以DataWorks On MaxCompute来介绍。
1.3.1 什么是MaxCompute
MaxCompute是适用于数据分析场景的企业级SaaS(Software as a Service)模式云数据仓库,以Serverless架构提供快速、全托管的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使用户可以经济并高效地分析处理海量数据。
MaxCompute提供离线和流式数据的接入,支持大规模数据计算及查询加速能力,为用户提供面向多种计算场景的数据仓库解决方案及分析建模服务。MaxCompute还为用户提供完善的数据导入方案以及多种经典的分布式计算模型,用户可以不必关心分布式计算和维护细节,便可轻松完成大数据分析。
1.3.2 MaxCompute功能特性
计算:
MaxCompute向用户提供了多种经典的分布式计算模型,提供TB、PB、EB级数据计算能力,能够更快速的解决用户海量数据计算问题,有效降低企业成本。




存储:
表是MaxCompute的数据存储单元,MaxCompute中不同类型作业的操作对象(输入、输出)都是表;MaxCompute采用列压缩存储格式,通常情况下具备5倍压缩能力;MaxCompute数据存储格式全面升级为AliORC,具备更高存储性能。


1.3.3 DataWorks与MaxCompute的关系
DataWorks和MaxCompute进行了深度融合。
DataWorks为MaxCompute提供任务调度、元数据管理、数据治理、数据安全管控等能力,但任务计算、数据存储仍在MaxCompute中。标准模式工作空间下,DataWorks为不同环境绑定不同的MaxCompute项目,实现DataWorks开发环境与生产环境存储、资源等隔离。

DataWorks on MaxCompute的基本开发流程如下图: