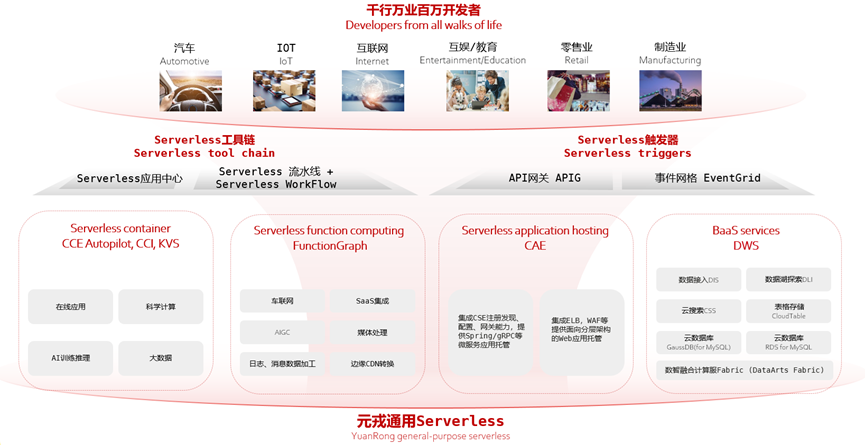
前言
这里要提到的是一个 之前碰到的一个 很令人诧异的查询, 主要是 和 group 查询有关系
查询如下, 按照常规理解, “select id from t_user_02 where name = 'jerry' group by age
” 会返回 两条数据, 然后 整个查询 会查询出两条数据
但是 结果很令人差异, 查询出了 四条数据
select *, 2, 2, 2 from t_user where id in (
select id from t_user_02 where name = 'jerry' group by age
);
测试数据表如下, t_user 和 t_user_02 完全一样, t_user_02 是由 t_user 复制而来
CREATE TABLE `t_user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(24) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8
测试数据如下

查询结果如下

正常实现业务的 sql 执行
对应的能够正确 实现业务的查询如下
select *, 2, 2, 2 from t_user where id in (
select max(id) from t_user_02 where name = 'jerry' group by age
);
这里整个流程 会分为 几个部分
1.执行 ” select age, max(id) from t_user_02 where name = 'jerry' group by age” 将结果输入临时表 tmp1
2.从 tmp1 中抽取 max(id) 字段, 将结果 汇总成为 tmp2
3.执行 “select *, 2, 2, 2 from t_user where id in $idList” 的条件查询
4.输出 “select *, 2, 2, 2 from t_user where id in $idList” 的执行结果
这里查询的主表是 t_user, 然后 这里是来 判断 id in ($idList) 的条件的地方 触发了
“select max(id) from t_user_02 where name = 'jerry' group by age” 的查询, 以及条件处理

子查询的执行1
子查询这边的执行 具体分成了两个阶段
第一个 qup_tab 查询对应于 “select age, max(id) from t_user_02 where name = 'jerry' group by age”
第二个 qup_tab 查询对应于 “select max(id) from (select age, max(id) from t_user_02 where name = 'jerry' group by age) as tmp”

获取 max(id) 列作为 临时表2

查询具体的数据表 只会执行一次, 持久化到临时表 tmp1 然后 后面是查询 临时表 tmp1 将 max(id) 列输出到 临时表 tmp2

查询 t_user_02 的 “where name = 'jerry'”

执行 group by 和 merge 处理如下, 对应于 “select max(id)” + “group by age”

这里是具体的数据调整的地方

数据更新 内容大致如下, 原来 age 121 对应的 max(id) 为 3, 如今更新为 5
最终 临时表中会有两条记录 ”age 121 -> max(id) 5”, ”age 21 -> max(id) 6”

临时表 tmp1 的名字

子查询的执行2
从 临时表 tmp1 中迭代记录, 这里是基于 上面的 tmp1 的查询结果进行迭代

将 “id 6” 输出到 临时表 tmp2

将 “id 5” 输出到 临时表 tmp2

主表的条件判断
这边第一个操作数为 t_user.id, 右侧操作数为 上面子查询临时表

显示根据 待查主键 1, 查询临时表
如果查询到, 则返回 true, 否则 返回 false

在临时表中查询到了 id 为 5

下游的 比较 t_user 中当前行的 id 和 临时表中查询到的 id 的比较, 判断 是否相同

主表中匹配到的结果的输出
这里是 id 为 5 的记录的输出

这里是 id 为 6 的记录的输出

异常的 sql 执行
我们这里的 问题sql查询如下
select *, 2, 2, 2 from t_user where id in (
select id from t_user_02 where name = 'jerry' group by age
);
从结果上来看 这个查询 是等价于
select *, 2, 2, 2 from t_user where id in (
select id from t_user_02 where name = 'jerry'
);
主驱动表是 t_user_02, 基于 row_search_mvcc 遍历 t_user_02

基于主键 来遍历 t_test, 这就是一个 典型的基于主键的 join 或者 基于主键in的子查询
至于 为什么会有这个转换?, 这里暂不深究, 应该就是在 解析的时候进行的处理

完