序言
卷积神经网络( CNN \text{CNN} CNN)作为深度学习领域的重要分支,凭借其强大的特征提取与学习能力,在图像和视频处理领域取得了显著成就。其结构化输出的特性,更是为复杂任务的解决提供了有力支持。本文旨在简要概述卷积神经网络的结构化输出机制,探讨其如何通过精细设计的网络架构,实现对输入数据的深度理解和高效处理。
结构化输出
- 卷积神经网络可以用于输出高维的结构化对象,而不仅仅是预测分类任务的类标签或回归任务的实数值。
- 通常这个对象只是一个张量,由标准卷积层产生。
- 例如,模型可以产生张量 S \bold{S} S,其中 S s , j , k S_{s,j,k} Ss,j,k是网络的输入像素 ( j , k ) (j,k) (j,k)属于类 i i i的概率。
- 这允许模型标记图像中的每个像素,并绘制沿着单个对象轮廓的精确掩模。
- 经常出现的一个问题是输出平面可能比输入平面要小,如基本卷积函数的变体篇 - 图例2所示。
- 用于对图像中单个对象分类的常用结构中,网络空间维数的最大减少来源于使用大步幅的池化层。
- 为了产生与输入大小相似的输出映射,我们可以避免把池化放在一起( Jain et al., 2007 \text{Jain et al., 2007} Jain et al., 2007)。
- 另一种策略是单纯地产生一张低分辨率的标签网格 ( Pinheiroand Collobert, 2014, 2015 \text{Pinheiroand Collobert, 2014, 2015} Pinheiroand Collobert, 2014, 2015)。
- 最后,原则上可以使用具有单位步幅的池化操作。
- 对图像逐个像素标记的一种策略是先产生图像标签的原始猜测,然后使用相邻像素之间的交互来修正该原始猜测。
- 重复这个修正步骤数次对应于在每一步使用相同的卷积,该卷积在深层网络的最后几层之间共享权重 ( Jain et al., 2007 \text{Jain et al., 2007} Jain et al., 2007)。
- 这使得在层之间共享参数的连续的卷积层所执行的一系列运算,形成了一种特殊的循环神经网络( Pinheiro and Collobert, 2014, 2015 \text{Pinheiro and Collobert, 2014, 2015} Pinheiro and Collobert, 2014, 2015)。
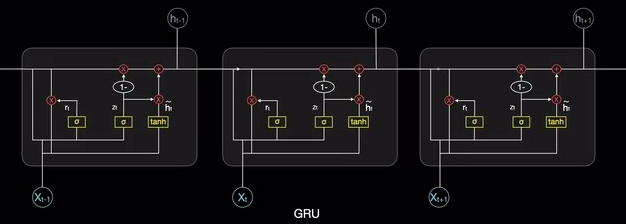
- 图例1给出了这样一个循环卷积网络的结构。
- 一旦对每个像素都进行了预测,可以使用各种方法来进一步处理这些预测,以便获得图像在区域上的分割 (
Briggman et al., 2009; Turaga et al., 2010; Farabet et al.,2013
\text{Briggman et al., 2009; Turaga et al., 2010; Farabet et al.,2013}
Briggman et al., 2009; Turaga et al., 2010; Farabet et al.,2013)。
- 一般的想法是假设大片相连的像素倾向于对应着相同的标签。图模型可以描述相邻像素间的概率关系。
- 或者,卷积网络可以被训练来最大化地近似图模型的训练目标 ( Ning et al., 2005; Thompson et al., 2014 \text{Ning et al., 2005; Thompson et al., 2014} Ning et al., 2005; Thompson et al., 2014)。
- 图例1:用于像素标记的循环卷积网络的示例。
-
用于像素标记的循环卷积网络的示例

-
说明:
- 输入是图像张量 X \bold{X} X,它的轴对应图像的行、列和通道(红,绿,蓝)。
- 目标是输出标签张量 Y ^ \hat{Y} Y^,它遵循每个像素的标签的概率分布。
- 该张量的轴对应图像的行、列和不同类别。并不是单次输出 Y ^ \hat{Y} Y^,循环网络通过使用 Y ^ \hat{Y} Y^的先前估计作为创建新估计的输入,来迭代地改善其估计。
- 相同的参数用于每个更新的估计,并且估计可以如我们所愿地被改善任意多次。
- 每一步使用的卷积核张量 U \bold{U} U,是用来计算给定输入图像的隐藏表示的。
- 核张量 V \bold{V} V用于产生给定隐藏值时标签的估计。
- 除了第一步之外,核 W \bold{W} W都对 Y ^ \hat{Y} Y^进行卷积来提供隐藏层的输入。
- 在第一步中,此项由零代替。
- 因为每一步使用相同的参数,所以这是一个循环网络的例子,如后续篇章:序列建模:循环和递归网络中所述。
-
总结
- 卷积神经网络的结构化输出,主要依赖于其独特的层级结构与算法设计。
- 从数据输入层开始, CNN \text{CNN} CNN通过卷积层提取图像或视频中的局部特征,这些特征在通过 ReLU \text{ReLU} ReLU等激活函数进行非线性变换后,被进一步传递到池化层进行降维与特征选择。
- 随后,全连接层将提取的高级特征整合为最终的输出向量或矩阵,以实现分类、检测、分割等多种任务。尤为重要的是, CNN \text{CNN} CNN通过卷积核的共享与滑动窗口机制,实现了对输入数据的全局感知与局部细节捕捉,从而能够生成具有高度结构化特征的输出。
- 此外,随着网络深度的增加与技术的不断创新, CNN \text{CNN} CNN在结构化输出方面的能力也在不断提升,为更广泛的应用场景提供了可能。
往期内容回顾
卷积神经网络 - 基本卷积函数的变体篇