博主简介:博主是一个大二学生,主攻人工智能领域研究。感谢缘分让我们在CSDN相遇,博主致力于在这里分享关于人工智能,C++,python,爬虫等方面的知识分享。如果有需要的小伙伴,可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。
专栏简介:本专栏致力于研究python爬虫的实战,涉及了所有的爬虫基础知识,以及爬虫在人工智能方面的应用。文章增加了JavaScript逆向,网站加密和混淆技术,AST还原混淆代码,WebAssembly,APP自动化爬取,Android逆向等相关技术。同时,为了迎合云原生发展,同时也增加了基于Kubernetes,Docker,Prometheus,Grafana等云原生技术的爬虫管理和运维解决方案。
订阅专栏
博主分享:给大家分享一句我很喜欢的话:“每天多一点努力,不为别的,值为日后,能够多一些选择,选择舒心的日子,选择自己喜欢的人!”


目录
正则表达式
匹配规则
函数进阶
1.match函数
search函数
findall函数
sub函数
compile函数
总结
httpx的使用
基础爬虫案例实战
准备工作
实验目的
代码实现
获取详情页URL
爬取详情页
源代码
总结
正则表达式
前面我们说了如何使用requests去获取网页的HTML代码,但是我们往往想要的是包含在这些代码中的资源,正则表达式是处理字符串的常用工具,在JAVA,C++等语言中均有他们的身影,有了正则表达式,可以很方便的处理很多事情。下面我们来看看正则表达式:
匹配规则
正则表达式中有很多的匹配规则,也就是我们说的他有他自己的语法。要想学好正则表达式,记住匹配规则是很重要的。
| 模式 | 描述 |
|---|---|
| \w | 匹配字母,数字即下划线字符 |
| \W | 匹配非字母,数字即下划线的字符 |
| \s | 匹配任意空白字符,等价于[\t\n\r\f] |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于[0~9] |
| \D | 匹配任意非数字的字符 |
| \A | 匹配字符串开头 |
| \z | 匹配到字符串结尾,加上换行符 |
| \Z | 匹配到字符串结尾,如果遇到换行符,则只匹配到换行符前一个字符 |
| \G | 匹配最后完成匹配的位置 |
| \n | 匹配换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配一行字符串的开头 |
| $ | 匹配一行字符串的结尾 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,可以匹配包括换行符的任意字符 |
| [...] | 用来表示一组字符,单独列出,例如[amk],匹配a,m或k。 |
| [^...] | 匹配不在[]中的字符,即表示除了里面的字符,其他的都可以。 |
| * | 匹配0个或多个表达式 |
| + | 匹配一个或多个表达式 |
| ? | 匹配0个或1个前面你定义的正则表达式片段,非贪婪方式 |
| {n} | 精确匹配n个前面的表达式 |
| {n,m} | 匹配n到m次由前面正则表达式定义的片段,贪婪方式 |
| a|b | 匹配a或b |
| () | 匹配括号内的表达式,也表示一个组 |
这个表中的东西很多,看完可能会出现记忆混乱,后买根据我提供的示例就很容易弄清了,python的强大在于它有很多库,当然,正则表达式也提供了一个库re。re中有很多的函数用来正则表达式匹配。下面我们认识一下他的函数。
函数进阶
1.match函数
match函数是一个常用的匹配方法,match方法会尝试从字符串的起始位置开始匹配正则表达式,如果匹配,就返回匹配结果,否则,返回None。
import re
str='Hello everyone,My name is chinese.My phonenumber is 1234567890 '
pattern='^Hello\s.{46}\d{10}'
result=re.match(pattern,str)
print(result.group())运行结果:
Hello everyone,My name is chinese.My phonenumber is 1234567890
当然,匹配方式不只有这些,还有其他方式。我们在代码中使用了group()和span()方法(这里没有用,后面会使用,先介绍),group()方法是输出匹配的内容,span()则是输出匹配的范围。
前面介绍该函数的时候,博主说该函数是从头开始匹配,如果我们开始匹配错误,后面匹配正确,那能不能的到结果?下面我们来看看:
import re
str='Hello word!I like you'
pattern='^word.\w{10}'
result=re.match(pattern,str)
print(result.span())
print(result.group())
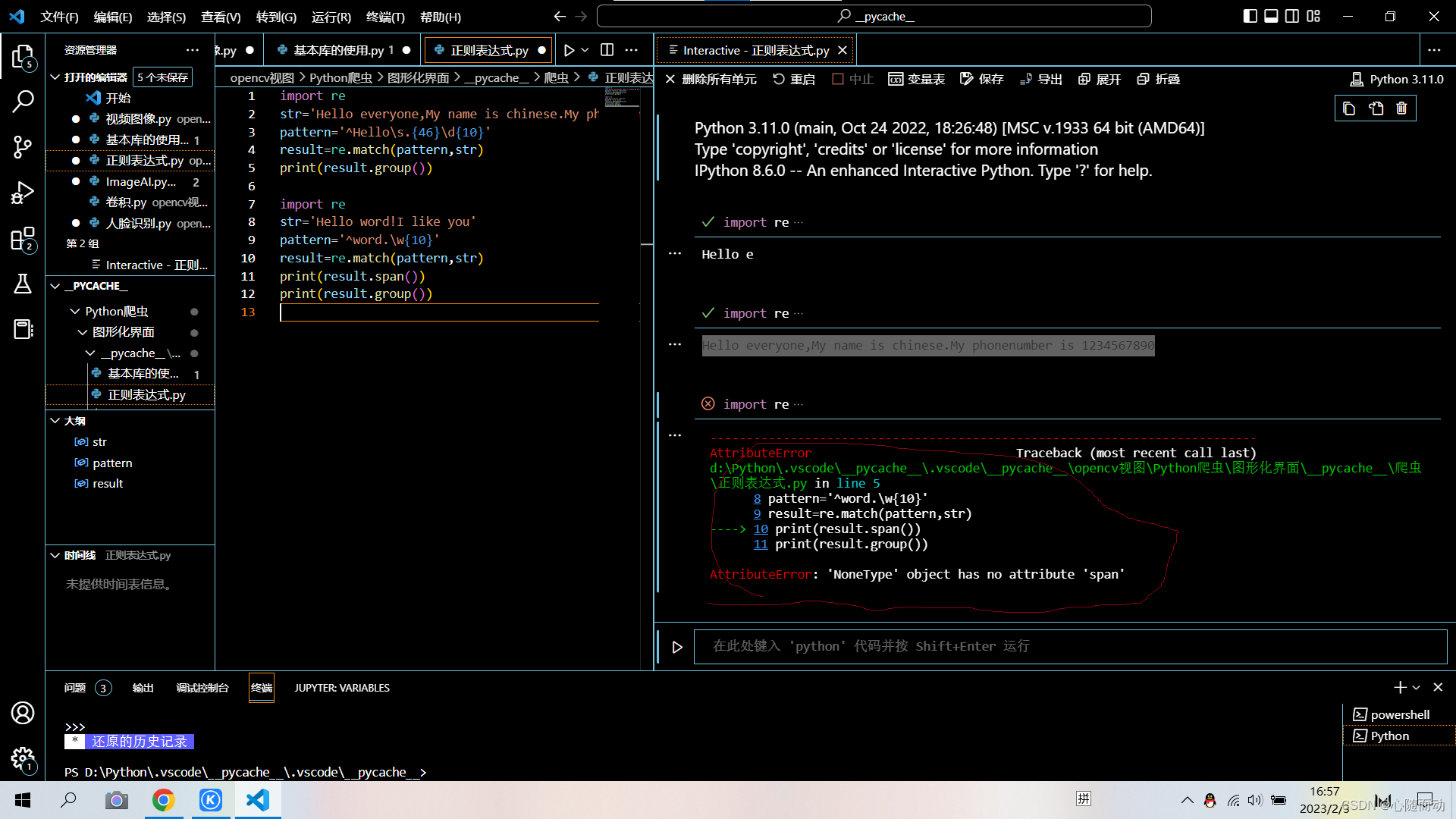
我们会发现匹配出了错误,虽然后面的匹配规则正确,但是开头匹配错误,所以这也是match函数的一大特性,为了,解决这一问题,re库也推出了其他的函数,后面会介绍。现在言归正传,如果说我们匹配后获得的内容不是我们想要的,也就是我们只想要其中的某个片段,我们又该如何选择?
import re
str='Hello 1234567 I like Word'
pattern='^Hello\s(\d+)'
result=re.match(pattern,str)
print(result.group())
print(result.group(1))
print(result.span())结果展示:
Hello 1234567
1234567
(0, 13)
根据结果我们可以知道group()是将所有的匹配结果都展现出来,group(1)则是将第一个()中的匹配法则所对应的内容展现出来。假如正则表达式中还有其他()包裹起来的内容,那么就用group(2),group(3)来输出。
通用匹配
上面我们用\d,\s等匹配法则来匹配,但是这样会显得很麻烦,不同的字符需要用不同的匹配法则,有没有什么简单的搭配?
我们这里认识以下通用匹配.*匹配。.表示匹配任意字符,*则表示无限次匹配前面的字符。所以他们在一起就可以匹配任意字符。
import re str='Hello 1234567 I like Word' pattern='^Hello.*Word$' result=re.match(pattern,str) print(result.group()) print(result.span())Hello 1234567 I like Word
(0, 25)
贪婪与非贪婪
上面介绍的通用匹配虽然很简单,但是如果我们要取中间的数字该怎么办,或者说要获取其中的某个片段,那我们用括号进行分组是否可以?
import re str='Hello 1234567 I like Word' pattern='^Hello.*(\d+).*Word$' result=re.match(pattern,str) print(result.group()) print(result.group(1)) print(result.span())Hello 1234567 I like Word
7
(0, 25)
根据运行代码结果展示,我们会发现只有一个7,这里就涉及到了贪婪和非贪婪匹配的问题,.*会一直匹配,直到最后一个或多个符合后面的匹配法则的字符。但是这样非常的不方便。如果想解决这个问题,那就使用.*?非贪婪匹配。
import re str='Hello 1234567 I like Word' pattern='.*?(\d+).*Word$' result=re.match(pattern,str) print(result.group()) print(result.group(1))Hello 1234567 I like Word
1234567
使用非贪婪是不是就很简单,不需要写太多。非贪婪在匹配的时候只会匹配0个或1个前面的字符匹配,他是尽可能的少匹配,而贪婪匹配则是尽可能多的匹配,就上面的例子,由于贪婪匹配后面是(\d+)表示至少有一个数字,所以也就只有一个7.而非贪婪匹配只要检测到后面的字符与匹配法则符合 就停止匹配,交给后面的匹配法则匹配。
但是要注意的是,如果在字符串后面,很可能出现无法匹配。
import re str='Hello 1234567 I like Word' pattern1='.*?(\d+)(.*?)' pattern2='.*?(\d+)(.*)' result1=re.match(pattern1,str) result2=re.match(pattern2,str) print(result1.group(2)) print('---------------') print(result2.group(2))---------------
I like Word
这时我们发现只有蝶绕个结果,第一个为空,这是因为第一个为空格,他是尽可能少匹配。后面没有匹配准则,他就不匹配。
修饰符
上面的字符串我们都没有换行,只是单独一行,那如果我们是多行匹配,那么会出现什么情况?
import re str='''Hello 1234567 I like Word ''' pattern2='.*?(\d+)(.*)' result2=re.match(pattern2,str) print('---------------') print(result2.group(2))
这个时候得到的结果是空,如果使用group()则会报错。而这个时候我们只需要加一个re.S就可以了。
result2=re.match(pattern2,str,re.S)
这里使用的re.S就是修饰符,除了这个还有其他的修饰符:
| 修饰符 | 描述 |
|---|---|
| re.I | 是匹配对大小写不敏感 |
| re.L | 实现本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响^,$匹配。 |
| re.S | 使匹配内容包括换行符在内的所有字符 |
| re.U | 根据Unicode字符集解析字符,会影响\w,\W,\b,\B |
| re.X | 该标志能够给你更灵活的格式,以便将正则表达式写得更清楚 |
转义匹配
我们知道正则表达式中定义了很多匹配模式,如.用于匹配除换行符以外的任意字符。但如果目标字符串里面就包含.这个字符,那该怎么办?
import re
content='(百度)www.baidu.com'
result=re.match('\(百度\)www\.baidu\.com',content)
print(result)当在目标字符串中遇到用作正则匹配模式的特殊字符时,在此字符前面加反斜杠\转义一下即可。例如\.就可以用来匹配.。
search函数
不知道看到这里的小伙伴是否还记得match函数的一个特性就是match函数的匹配是从第一个开始,也就是从头开始,也就是意味着一旦开头不匹配就会失败,前面已经做过实验了。有时候这样会很复杂,所以,python推出了search函数。
search函数是从字符串开头扫描,直到和匹配规则重合的字符串出现,然后返回第一个符合条件的字符串。
import re
str='Hello Word 123 Word 123 hujuijcbv'
content='\d+'
print(re.search(content,str).group())此时代码的返回结果就是123,但是字符串中有两个123,这里却只显示一个,原因就是search函数只返回第一个匹配的内容。由于HTML代码中有很多的节点,所以爬虫建议使用search函数,使用match函数工作量会非常大,消耗的时间也会多。综合以上,使用search函数较好。但是也有各例,具体情况具体分析。
findall函数
前面的search函数只能返回第一个匹配的字符串,如果我们要获取多个相同规则的字符串又该如何?这个时候就要用到findall函数。findall函数的返回值为列表类型,所以需要使用遍历的方式获取里面的内容:
import re str='Hello Word 123 Word 123 hujuijcbv,123 456!' content='\d+' result=re.findall(content,str) for x in result: print(x)123
123
123
456
sub函数
除了使用正则表达式提取信息,有时候还需要他来修改文本,虽然python中提供了replace函数,但是,这样很繁琐,re库中的sub函数就能很简单的实现:
例:将Hello Word 123 Word 123 hujuijcbv,123 456!字符串中的数字转换为感叹号或者去掉,我们怎么去操作?
import re str='Hello Word 123 Word 123 hujuijcbv,123 456!' content='\d+' result=re.sub(content,'!',str) print(result)Hello Word ! Word ! hujuijcbv,! !!
显然使用sub函数就很简单。sub函数的第一个参数是要改变的字符串或字符,第二个参数是用来替换要改变的的字符或字符串 ,第三个参数是原始字符串。
compile函数
前面讲的函数都是用来处理字符串的,compile函数则是用来处理正则表达式的,将字符串编译成正则表达式对象,以便在后面的匹配中重复使用。如下:
import re content1='2002 03 29 13:45' content2='2003 05 31 14:55' content3='2022 04 04 21:07' pattern='\d{2}:\d{2}' result1=re.sub(pattern,'',content1) result2=re.sub(pattern,'',content2) result3=re.sub(pattern,'',content3) print(result1,'\n',result2,'\n',result3)2002 03 29
2003 05 31
2022 04 04
利用compile函数可以构造一个正则表达式对象,这样会减少工作量,同时,也可以在构造对象的时候添加修饰符,这样就不用在函数中写了。后面的代码基本上就会这样去写。
总结
到此为止,正则表达式部分就介绍完毕,后面博主会写一些实例来巩固这些方法。
httpx的使用
前面我们介绍了urllib库和requests库,现在来说,掌握这两个库就可以爬很多的网站了,但是对于一些网站还是无能为力,这是为什么?我们前面讲过HTTP存在http1和HTTP2两个版本,目前urllib和requests库只支持爬取http1.1版本,不支持HTTP2版本。目前来说有hyper和httpx两个库支持爬取http2版本,相对来说,后者的功能更强大,博主也更喜欢后者,所以就介绍一下httpx的使用。
httpx模块不是python的内置模块,需要下载,如果直接使用命令安装,则也不支持http2版本。可以这样安装:
pip install "httpx[http2]" -i https://pypi.tuna.tsinghua.edu.cn/simple/
下载好后是不是就可以使用了?我们来验证一下:
import httpx
print(httpx.get('https://spa16.scrape.center').text)

我们发现报错了,这是由于httpx默认支持http1.1版本,这个时候需要我们手动打开http2版本:
#httpx的使用
import httpx
client=httpx.Client(http2=True)
response=client.get('https://spa16.scrape.center')
print(response.text)client对象
httpx中的很多的API都和requests中的相似,但是有一些requests中没有,比如client对象,可以和requests中的session类比学习。
import httpx with httpx.Client() as client: response=client.get('https://www.baidu.com') print(response) #等价于 import httpx client=httpx.Client() try: response=client.get('https://www.baidu.com') finally: client.close()注意:在客户端上启用的httpx支持http2版本并不意味着请求和响应都将通过http2.0版本传输,还得客户端和服务器都支持,如果客户端京仅连接到支持http1.1版本的服务器,那么相应的,httpx也必须改为http1.1。
支持异步请求
httpx还支持异步客户端请求(AsyncClient),支持python的async请求模式。写法如下:
import asyncio
import httpx
import nest_asyncio
nest_asyncio.apply()
async def fetch(url):
async with httpx.AsyncClient(http2=True) as client:
response=await client.get(url)
print(response.text)
if __name__=='__main__':
asyncio.get_event_loop().run_until_complete(fetch('https://www.httpbin.org/get'))由于博主使用的是VScode编译器,使用的式python内核,所以,这里直接使用异步请求是无法通过的,因为python本身就是不能进行事件循环的。所以有些编译器可以使用,博主这里不可以,就不展示运行结果了。
基础爬虫案例实战
准备工作
1.安装好python,以及涉及到的库。
2.了解python的多线程进程原理
此次要爬取的网页的地址:‘https://ssr1.scrape.center/’
实验目的
对前面所学的知识进行一个总结,巩固所学知识,为后面的学习做好铺垫。
代码实现
获取详情页URL
这里我们引入requests库来爬取页面,logging用来输出信息,re库用来实现正则表达式的解析。urljoin用来做URL拼接。
第一步,我们先定义日志输出级别和输出格式,以及BASE_URL为当前站点的根URL;TOTAL_PACE表示爬取的页面数量。
import logging
import requests
import re
from urllib.parse import urljoin
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s:%(message)s')
BASE_URL='https://ssr1.scrape.center'
TOTAL_PACE=10
第二步,我们实现页面爬取的方法
def scrape_page(url):
logging.info('scraping %s...',url)
try:
response=requests.get(url)
if response.status_code==200:
return response.text
logging.error('get invalid status code %s while scraping %s',response.status_code,url)
except requests.RequestException:
logging.error('error occurred while scraping %s',url,exc_info=True)
由于不仅要爬取列表页,还要爬取详情页,所以我们这里定义了一个较通用的防范,最终得到的是HTML源代码。
第三步,定义列表页爬取方法
#列表页爬取
def scrape_index(page):
index_url=f'{BASE_URL}/page/{page}'
return scrape_page(index_url)获取列表页后,下一步就是解析列表页:
第四步,解析列表页:
#解析列表
def parse_index(html):
pattern=re.compile('<a.*?href="(.*?)".*?class="name">')
items=re.findall(pattern,html)
if not items:
return[]
for item in items:
detail_url=urljoin(BASE_URL,item)
logging.info('get detail url %s',detail_url)
yield detail_url #生成器现在,所有的函数都已经实现,现在就是串用:
#主函数
def main():
for page in range(1,TOTAL_PACE):
index_html=scrape_index(page)
detail_urls=parse_index(index_html)
logging.info('detail urls %s',list(detail_urls))
if __name__=='__main__':
main()
第五步,运行

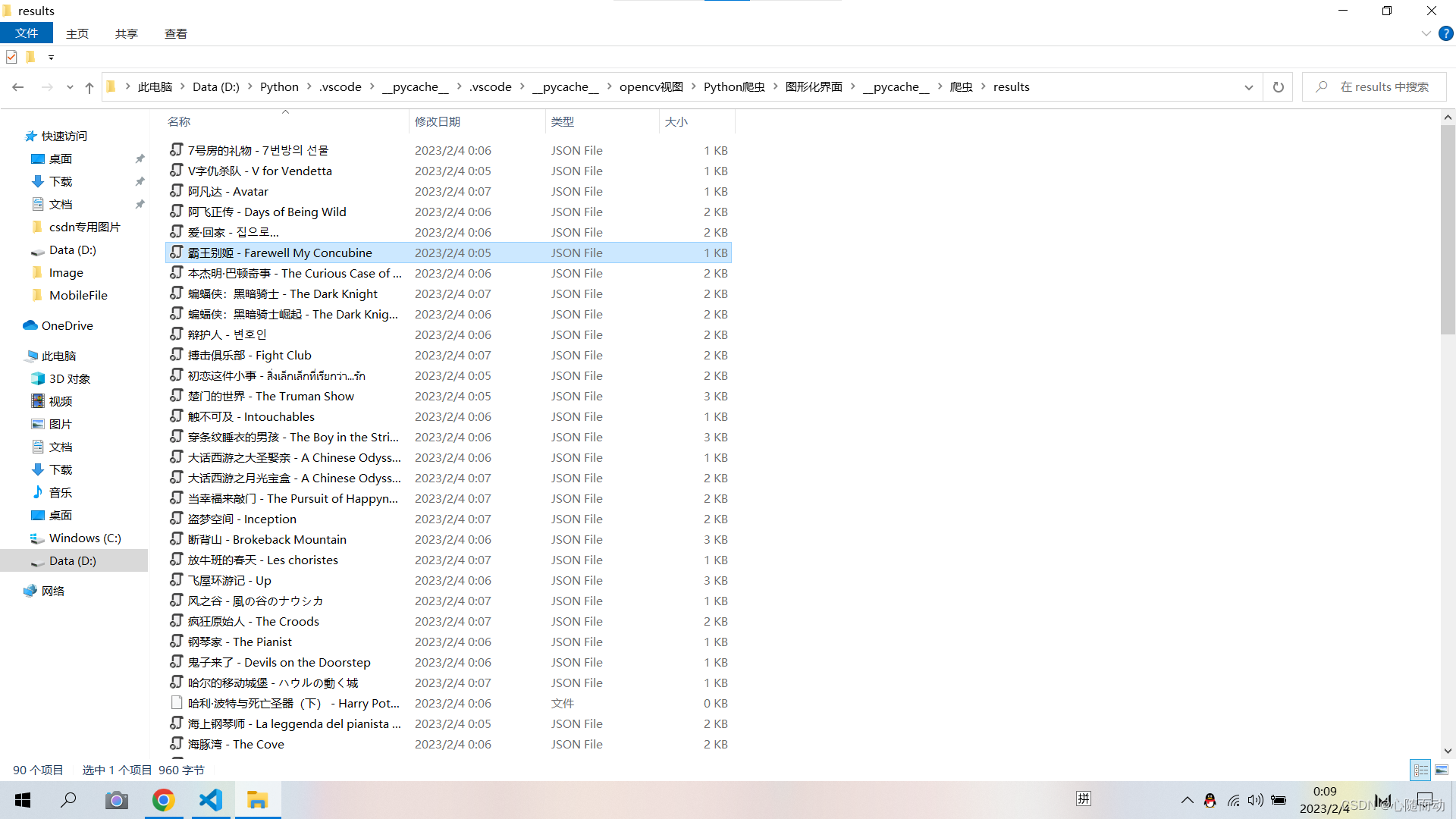
由于结果太多,这里就只展示一小部分,现在我们获得了每一页的详情页的URL,那么我们接下来要做的就是解析这些URL。
爬取详情页
观察每个子页面的代码,我们可以找出他们的特点,由于每个人的观察点不一样,所以这里就以博主的观察点为主:
定义一个详情页的爬取方法:
#定义一个详情页的爬取方法
def scrape_detail(url):
return scrape_page(url)然后就是对详情页进行解析:
#对详情页进行解析
def parse_detail(html):
cover_pattern=re.compile('class="item.*?<img.*?src="(.8?)".*?class="cover">',re.S)
name_pattern=re.compile('<h2.*?>(.*?)</h2>')
categories_pattern=re.compile('<button.*?category.*?<span>(.*?)\
</span>.*?</button>',re.S)
published_at_pattern=re.compile('(\d{4}-\d{2}-\d{2})\s?上映')
drama_pattern=re.compile('<div.*?drama.*?>.*?<p.*?>(.*?)</p>',re.S)
score_pattern=re.compile('<p.*?score.*?>(.*?)</p>',re.S)
cover=re.search(cover_pattern,html).group(1).strip() if re.search(cover_pattern,html) else None
name=re.search(name_pattern,html).group(1).strip() if re.search(name_pattern,html) else None
categories=re.findall(categories_pattern,html) if re.findall(categories_pattern,html) else []
published_at=re.search(published_at_pattern,html).group(1) if re.search(published_at_pattern,html) else None
drama=re.search(drama_pattern,html).group(1).strip() if re.search(drama_pattern,html) else None
score=float(re.search(score_pattern,html).group(1).strip() if re.search(score_pattern,html) else None)
return{
'cover':cover,
'name':name,
'categories':categories,
'published_at':published_at,
'drama':drama,
'score':score
}最后一步,保存数据。
#保存数据
RESULTS_DIR='results'
exists(RESULTS_DIR) or makedirs(RESULTS_DIR)
def save_data(data):
name=data.get('name')
data_path=f'{RESULTS_DIR}/{name}.json'
json.dump(data,open(data_path,'w',encoding='utf-8'),ensure_ascii=False,indent=2)到这里,所有的函数均已完成,现在就是组合起来使用:
源代码
#爬虫案例实战
import json
from os import makedirs
from os.path import exists
import logging
import requests
import re
from urllib.parse import urljoin
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s:%(message)s')
BASE_URL='https://ssr1.scrape.center'
TOTAL_PACE=10
#页面爬取
def scrape_page(url):
logging.info('scraping %s...',url)
try:
response=requests.get(url)
if response.status_code==200:
return response.text
logging.error('get invalid status code %s while scraping %s',response.status_code,url)
except requests.RequestException:
logging.error('error occurred while scraping %s',url,exc_info=True)
#列表页爬取
def scrape_index(page):
index_url=f'{BASE_URL}/page/{page}'
return scrape_page(index_url)
#解析列表
def parse_index(html):
pattern=re.compile('<a.*?href="(.*?)".*?class="name">')
items=re.findall(pattern,html)
if not items:
return[]
for item in items:
detail_url=urljoin(BASE_URL,item)
logging.info('get detail url %s',detail_url)
yield detail_url #生成器
#定义一个详情页的爬取方法
def scrape_detail(url):
return scrape_page(url)
#对详情页进行解析
def parse_detail(html):
cover_pattern=re.compile('class="item.*?<img.*?src="(.8?)".*?class="cover">',re.S)
name_pattern=re.compile('<h2.*?>(.*?)</h2>')
categories_pattern=re.compile('<button.*?category.*?<span>(.*?)\
</span>.*?</button>',re.S)
published_at_pattern=re.compile('(\d{4}-\d{2}-\d{2})\s?上映')
drama_pattern=re.compile('<div.*?drama.*?>.*?<p.*?>(.*?)</p>',re.S)
score_pattern=re.compile('<p.*?score.*?>(.*?)</p>',re.S)
cover=re.search(cover_pattern,html).group(1).strip() if re.search(cover_pattern,html) else None
name=re.search(name_pattern,html).group(1).strip() if re.search(name_pattern,html) else None
categories=re.findall(categories_pattern,html) if re.findall(categories_pattern,html) else []
published_at=re.search(published_at_pattern,html).group(1) if re.search(published_at_pattern,html) else None
drama=re.search(drama_pattern,html).group(1).strip() if re.search(drama_pattern,html) else None
score=float(re.search(score_pattern,html).group(1).strip() if re.search(score_pattern,html) else None)
return{
'cover':cover,
'name':name,
'categories':categories,
'published_at':published_at,
'drama':drama,
'score':score
}
#保存数据
RESULTS_DIR='results'
exists(RESULTS_DIR) or makedirs(RESULTS_DIR)
def save_data(data):
name=data.get('name')
data_path=f'{RESULTS_DIR}/{name}.json'
json.dump(data,open(data_path,'w',encoding='utf-8'),ensure_ascii=False,indent=2)
#主函数
def main():
for page in range(1,TOTAL_PACE):
index_html=scrape_index(page)
detail_urls=parse_index(index_html)
for detail_url in detail_urls:
detail_html=scrape_detail(detail_url)
data=parse_detail(detail_html)
logging.info('get detail data%s',data)
logging.info('saving data to json file')
save_data(data)
logging.info('data saved successfully')
if __name__=='__main__':
main()
结果展示:
总结
本篇文章讲解了正则表达式,以及如何去爬取网页上的有用信息,文末增加了一个示例,目的就是让大家更能理解知识。也希望这个案例能够让大家对爬虫有所认知和体会。