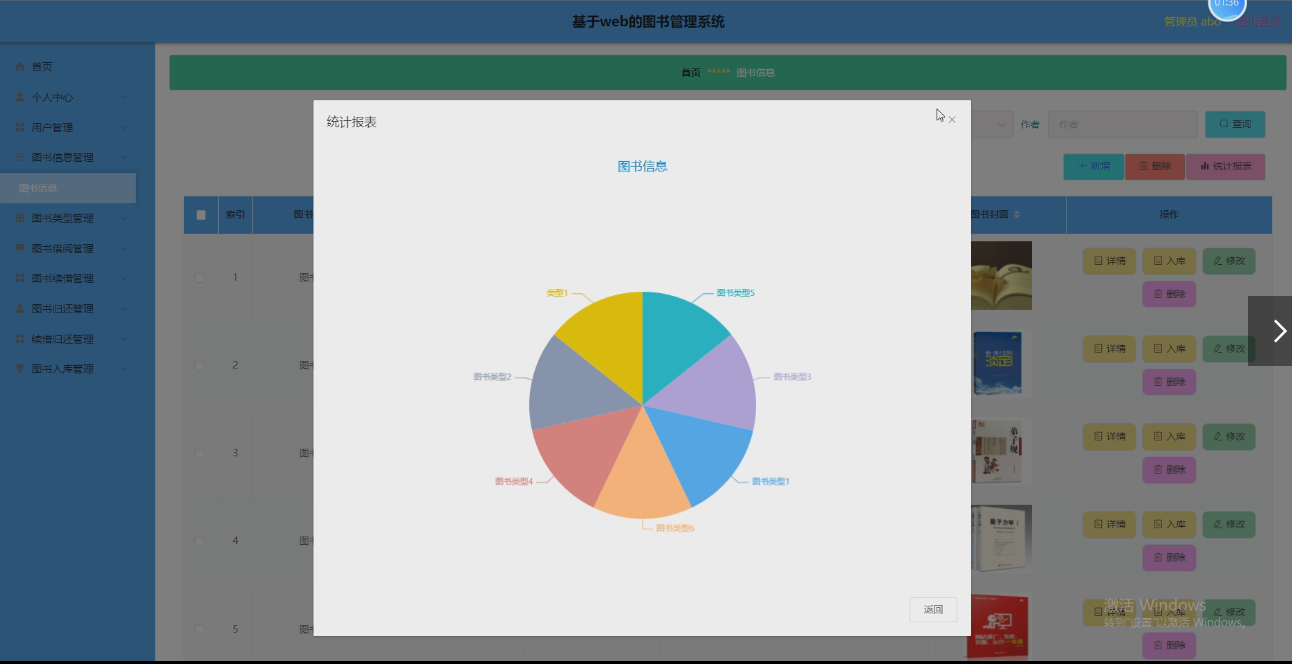
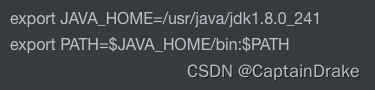
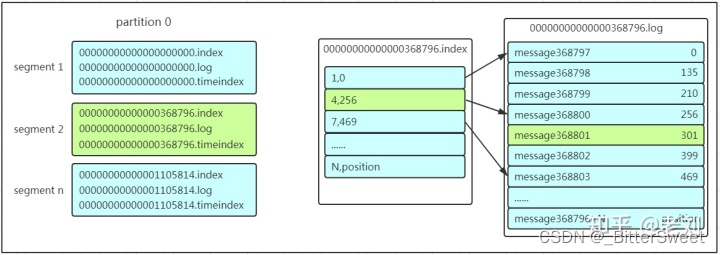
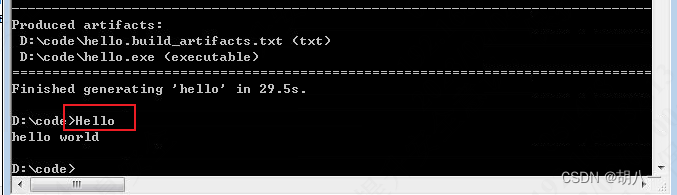
嗨嗨,大家晚上好 ~ 又来给你们分享小妙招啦
在python列表有重复元素时,可以有以下几种方式进行删除
觉得不错的话,赶紧学起来用用吧 !

直接遍历列表删除
l1 = [1, 1, 2, 2, 3, 3, 3, 3, 6, 6, 5, 5, 2, 2]
for el in l1:
if l1.count(el) > 1:
l1.remove(el)
print(l1)# 会漏删,因为删除一个元素后,后面的元素向前补位,导致紧跟的一个元素被跳过.
通过遍历索引删除
l1 = [1, 1, 2, 2, 3, 3, 3, 3, 6, 6, 5, 5, 2, 2]
for el in range(len(l1)): # 此时len(l1)已经确定,不会随着l1后面的变化而变化
if l1.count(l1[el]) > 1:
l1.remove(l1[el])
print(l1) # 会报错,因为删除元素后导致l1的长度变短了,但是for遍历的还是之前的索引长度,会导致索引超过范围而报错

通过遍历创建的切片来删除原列表
l1 = [1, 1, 2, 2, 3, 3, 3, 3, 6, 6, 5, 5, 2, 2]
for el in l1[:]:
if l1.count(el) > 1:
l1.remove(el) # 没有问题,可以去重,但是无法保留原有的顺序
print(l1)
用新列表记录需要保留的元素
l1 = [1, 1, 2, 2, 3, 3, 3, 3, 6, 6, 5, 5, 2, 2]
lst = []
for el in l1:
if lst.count(el) < 1:
lst.append(el)
print(lst) # 没有问题,也能保留原有顺序,但是创建了新列表
通过索引倒着删除
对此有疑问的可以点击文章末尾名片进行交流学习
l1 = [1, 1, 2, 2, 3, 3, 3, 3, 6, 6, 5, 5, 2, 2]
for el in range(len(l1)-1, -1, -1):
if l1.count(l1[el]) > 1:
l1.pop(el) # 没有问题,且保留原顺序
# l1.remove(l1[el]) # 没有问题,但是不能保留原有顺序
# del l1[el] # 这样则会保留原有顺序,小伙伴可以想一想为什么
print(l1)

通过递归函数删除
l1 = [1, 1, 2, 2, 3, 3, 3, 3, 6, 6, 5, 5, 2, 2]
def set_lst(lst):
for el in lst:
if lst.count(el) > 1:
lst.remove(el)
set_lst(lst) # 每次开辟一个新函数,判断上次被删除了一个元素后的列表
else: # 直到最后,列表里的元素都是一个,运行了else
return lst
print(set_lst(l1)) # 因为是从前面开始删除的,所以不保留原有顺序
'''
[1, 1, 2, 2, 3, 3, 3, 3, 6, 6, 5, 5, 2, 2]
[1, 2, 2, 3, 3, 3, 3, 6, 6, 5, 5, 2, 2]
[1, 2, 3, 3, 3, 3, 6, 6, 5, 5, 2, 2]
[1, 3, 3, 3, 3, 6, 6, 5, 5, 2, 2]
[1, 3, 3, 3, 6, 6, 5, 5, 2, 2]
[1, 3, 3, 6, 6, 5, 5, 2, 2]
[1, 3, 6, 6, 5, 5, 2, 2]
[1, 3, 6, 5, 5, 2, 2]
[1, 3, 6, 5, 2, 2]
[1, 3, 6, 5, 2] return lst = [1, 3, 6, 5, 2]
'''
毫无疑问set()是最方便的
l1 = [1, 1, 2, 2, 3, 3, 3, 3, 6, 6, 5, 5, 2, 2]
lst = list(set(l1))
print(lst)
就是以上的七种方式啦,如何还有其他的也欢迎大家在评论区补充哦!
好啦,今天的分享到这里就结束了 ~
对文章有问题的,或者有其他关于python的问题,可以在评论区留言或者私信我哦
觉得我分享的文章不错的话,可以关注一下我,或者给文章点赞(/≧▽≦)/
最后,对于刚开始学习python的宝子,我准备好了大量的电子书籍以及案例教程,有需要的可以点击文章末尾名片进行领取哦~





![[架构之路-98]:《软件架构设计:程序员向架构师转型必备》-8-确定关键性需求与决定系统架构的因素](https://img-blog.csdnimg.cn/img_convert/393dcbcd972b3b713dea58eb80f7d373.png)