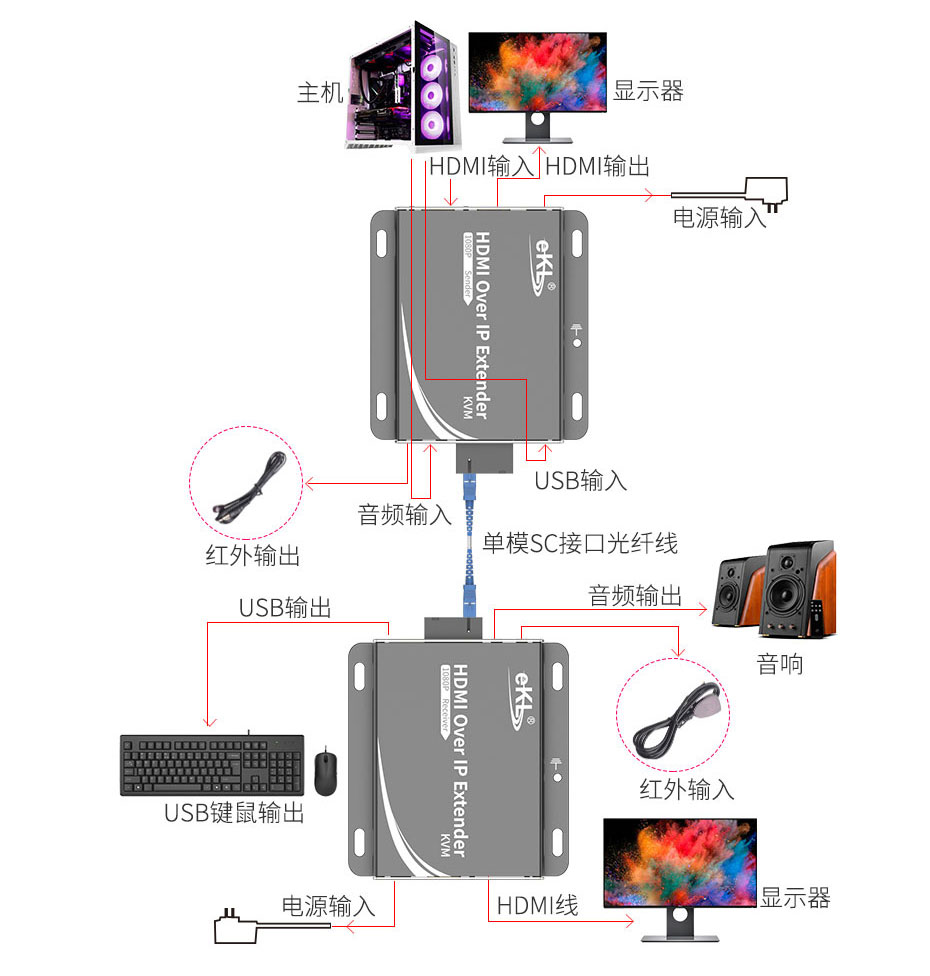
数据将是未来AI大模型竞争的关键要素
人工智能发展的突破得益于高质量数据的发展。例如,大型语言模型的最新进展依赖于更高质量、更丰富的训练数据集:与GPT-2相比,GPT-3对模型架构只进行了微小的修改,但花费精力收集更大的高质量数据集进行训练。ChatGPT与GPT-3的模型架构类似,并使用RLHF(来自人工反馈过程的强化学习)来生成用于微调的高质量标记数据。

人工智能领域以数据为中心的AI,即在模型相对固定的前提下,通过提升数据的质量和数量来提升整个模型的训练效果。提升数据集质量的方法主要有:添加数据标记、清洗和转换数据、数据缩减、增加数据多样性、持续监测和维护数据等。未来数据成本在大模型开发中的成本占比或将提升,主要包括数据采集,清洗,标注等成本。
图片以数据为中心的 AI:模型不变,通过改进数据集质量提升模型效果
AI大模型需要高质量、大规模、多样性的数据集
1)高质量:高质量数据集能够提高模型精度与可解释性,并且减少收敛到最优解的时间,即减少训练时长。
2)大规模:OpenAI 在《Scaling Laws for Neural Language Models》中提出 LLM 模型所遵循的“伸缩法则”(scaling law),即独立增加训练数据量、模型参数规模或者延长模型训练时间,预训练模型的效果会越来越好。
3)丰富性:数据丰富性能够提高模型泛化能力,过于单一的数据会非常容易让模型过于拟合训练数据。

数据集如何产生
建立数据集的流程主要分为 1)数据采集;2)数据清洗:由于采集到的数据可能存在缺失值、噪声数据、重复数据等质量问题;3)数据标注:最重要的一个环节;4)模型训练:模型训练人员会利用标注好的数据训练出需要的算法模型;5)模型测试:审核员进行模型测试并将测试结果反馈给模型训练人员,而模型训练人员通过不断地调整参数,以便获得性能更好的算法模型;6)产品评估:产品评估人员使用并进行上线前的最后评估。
数据采集
采集的对象包括视频、图片、音频和文本等多种类型和多种格式的数据。数据采集目前常用的有三种方式,分别为:1)系统日志采集方法;2)网络数据采集方法;3)ETL。
图片
数据清洗
数据清洗是提高数据质量的有效方法。由于采集到的数据可能存在缺失值、噪声数据、重复数据等质量问题,故需要执行数据清洗任务,数据清洗作为数据预处理中至关重要的环节,清洗后数据的质量很大程度上决定了 AI 算法的有效性。
图片
数据标注
数据标注是流程中最重要的一个环节。管理员会根据不同的标注需求,将待标注的数据划分为不同的标注任务。每一个标注任务都有不同的规范和标注点要求,一个标注任务将会分配给多个标注员完成。
图片
图片
模型训练与测试
最终通过产品评估环节的数据才算是真正过关。产品评估人员需要反复验证模型的标注效果,并对模型是否满足上线目标进行评估。
图片
主要大语言模型数据集
参数量和数据量是判断大模型的重要参数。2018 年以来,大语言模型训练使用的数据集规模持续增长。2018 年的 GPT-1 数据集约 4.6GB,2020 年的 GPT-3 数据集达到了 753GB,而到了 2021 年的 Gopher,数据集规模已经达到了 10,550GB。总结来说,从 GPT-1 到LLaMA 的大语言模型数据集主要包含六类:维基百科、书籍、期刊、Reddit 链接、CommonCrawl 和其他数据集。
维基百科
维基百科是一个免费的多语言协作在线百科全书。维基百科致力于打造包含全世界所有语言的自由的百科全书,由超三十万名志愿者组成的社区编写和维护。截至2023年3月,维基百科拥有332种语言版本,总计60,814,920条目。其中,英文版维基百科中有超过664万篇文章,拥有超4,533万个用户。维基百科中的文本很有价值,因为它被严格引用,以说明性文字形式写成,并且跨越多种语言和领域。一般来说,重点研究实验室会首先选取它的纯英文过滤版作为数据集。

书籍
书籍主要用于训练模型的故事讲述能力和反应能力,包括小说和非小说两大类。数据集包括ProjectGutenberg和Smashwords(TorontoBookCorpus/BookCorpus)等。ProjectGutenberg是一个拥有7万多本免费电子书的图书馆,包括世界上最伟大的文学作品,尤其是美国版权已经过期的老作品。BookCorpus以作家未出版的免费书籍为基础,这些书籍来自于世界上最大的独立电子书分销商之一的Smashwords。
期刊
期刊可以从ArXiv和美国国家卫生研究院等官网获取。预印本和已发表期刊中的论文为数据集提供了坚实而严谨的基础,因为学术写作通常来说更有条理、理性和细致。ArXiv是一个免费的分发服务和开放获取的档案,包含物理、数学、计算机科学、定量生物学、定量金融学、统计学、电气工程和系统科学以及经济学等领域的2,235,447篇学术文章。美国国家卫生研究院是美国政府负责生物医学和公共卫生研究的主要机构,支持各种生物医学和行为研究领域的研究,从其官网的“研究&培训”板块能够获取最新的医学研究论文。
WebText(来自Reddit链接)
Reddit链接代表流行内容的风向标。Reddit是一个娱乐、社交及新闻网站,注册用户可以将文字或链接在网站上发布,使它成为了一个电子布告栏系统。WebText是一个大型数据集,它的数据是从社交媒体平台Reddit所有出站链接网络中爬取的,每个链接至少有三个赞,代表了流行内容的风向标,对输出优质链接和后续文本数据具有指导作用。
Commoncrawl/C4
Commoncrawl是2008年至今的一个网站抓取的大型数据集。CommonCrawl是一家非盈利组织,致力于为互联网研究人员、公司和个人免费提供互联网副本,用于研究和分析,它的数据包含原始网页、元数据和文本提取,文本包含40多种语言和不同领域。重点研究实验室一般会首先选取它的纯英文过滤版(C4)作为数据集。
其他数据集
ThePile数据集:一个825.18GB的英语文本数据集,用于训练大规模语言模型。ThePile由上文提到的ArXiv、WebText、Wikipedia等在内的22个不同的高质量数据集组成,包括已经建立的自然语言处理数据集和几个新引入的数据集。除了训练大型语言模型外,ThePile还可以作为语言模型跨领域知识和泛化能力的广泛覆盖基准。其他数据集包含了GitHub等代码数据集、StackExchange等对话论坛和视频字幕数据集等。
多模态数据集
模态是事物的一种表现形式,多模态通常包含两个或者两个以上的模态形式,包括文本、图像、视频、音频等。多模态大模型需要更深层次的网络和更大的数据集进行预训练。过去数年中,多模态大模性参数量及数据量持续提升。
语音+文本
SEMAINE数据集:创建了一个大型视听数据库,作为构建敏感人工侦听器(SAL)代理的迭代方法的一部分,该代理可以使人参与持续的、情绪化的对话。高质量的录音由五台高分辨率、高帧率摄像机和四个同步录制的麦克风提供。录音共有150个参与者,总共有959个与单个SAL角色的对话,每个对话大约持续5分钟。固体SAL录音被转录和广泛注释:每个剪辑6-8个评分者追踪5个情感维度和27个相关类别。
图像+文本
COCO数据集:MSCOCO的全称是MicrosoftCommonObjectsinContext,起源于微软于2014年出资标注的MicrosoftCOCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。图像包括91类目标,328,000张图像和2,500,000个label。ConceptualCaptions数据集:图像标题注释数据集,其中包含的图像比MS-COCO数据集多一个数量级,并代表了更广泛的图像和图像标题风格。通过从数十亿个网页中提取和过滤图像标题注释来实现这一点。
ImageNet数据集:建立在WordNet结构主干之上的大规模图像本体。ImageNet的目标是用平均5,001,000张干净的全分辨率图像填充WordNet的80,000个同义词集中的大多数。这将产生数千万个由WordNet语义层次结构组织的注释图像。ImageNet的当前状态有12个子树,5247个同义词集,总共320万张图像。
LAION-400M数据集:LAION-400M通过CommonCrawl提取出随机抓取2014-2021年的网页中的图片、文本内容。通过OpenAI的Clip计算,去除了原始数据集中文本和图片嵌入之间预先相似度低于0.3的内容和文本,提供了4亿个初筛后的图像文本对样本。
图片
LAION-5B数据集:包含58.5亿个CLIP过滤的图像-文本对的数据集,比LAION-400M大14倍,是世界第一大规模、多模态的文本图像数据集,共80T数据,
图片
LanguageTable数据集:Language-Table是一套人类收集的数据集,是开放词汇视觉运动学习的多任务连续控制基准。
IAPRTC-12数据集:IAPRTC-12基准的图像集合包括从世界各地拍摄的2万张静态自然图像,包括各种静态自然图像的横截面。这包括不同运动和动作的照片,人物、动物、城市、风景和当代生活的许多其他方面的照片。示例图像可以在第2节中找到。每张图片都配有最多三种不同语言(英语、德语和西班牙语)的文本标题。
视频+图像+文本
YFCC100数据集:YFCC100M是一个包含1亿媒体对象的数据集,其中大约9920万是照片,80万是视频,所有这些都带有创作共用许可。数据集中的每个媒体对象都由几块元数据表示,例如Flickr标识符、所有者名称、相机、标题、标签、地理位置、媒体源。从2004年Flickr成立到2014年初,这些照片和视频是如何被拍摄、描述和分享的,这个集合提供了一个全面的快照。
图像+语音+文本
CH-SIMS数据集:CH-SIMS是中文单模态和多模态情感分析数据集,包含2,281个精细化的野外视频片段,既有多模态注释,也有独立单模态注释。它允许研究人员研究模态之间的相互作用,或使用独立的单模态注释进行单模态情感分析。
视频+语音+文本
IEMOCAP数据集:南加州大学语音分析与解释实验室(SAIL)收集的一种新语料库,名为“上的二元会话,这些标记提供了他们在脚本和自发口语交流场景中面部表情和手部动作的详细信息。语料库包含大约12小时的数据。详细的动作捕捉信息、激发真实情绪的交互设置以及数据库的大小使这个语料库成为社区中现有数据库的有价值的补充,用于研究和建模多模态和富有表现力的人类交流。