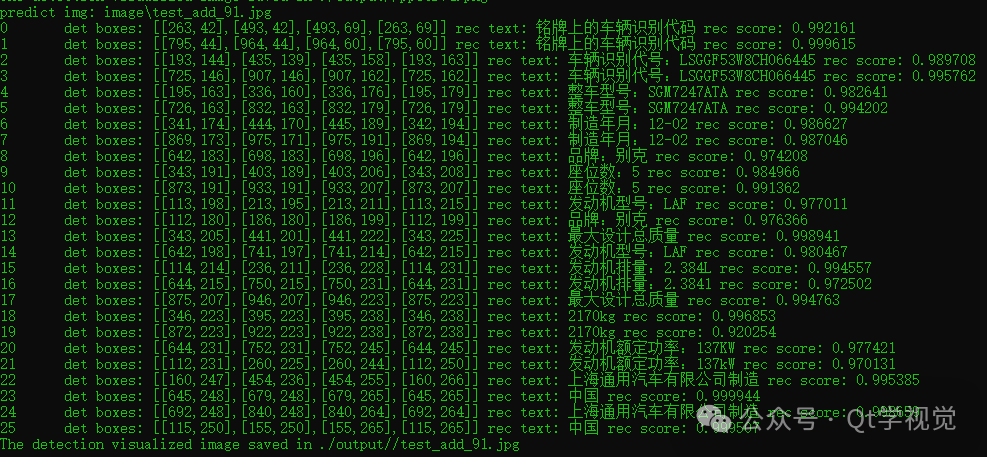
paper:DeepViT: Towards Deeper Vision Transformer
official implementation:https://github.com/zhoudaquan/dvit_repo
出发点
尽管浅层ViTs在视觉任务中表现优异,但随着网络深度增加,性能提升变得困难。研究发现,这种性能饱和的主要原因是注意力崩溃问题,即在深层变压器中,attention map逐渐变得相似,导致feature map在顶层趋于一致,从而限制了模型的表示学习能力。本文旨在研究如何有效地加深ViT模型,并提出了一种新的自注意力机制Re-attention来解决这个问题。
创新点
- 注意力崩溃问题的提出与分析:首次提出并深入分析了注意力崩溃问题,发现这是导致深层ViT模型性能饱和的主要原因。
- Re-attention机制:提出了一种简单但有效的Re-attention机制,通过在不同注意力头之间交换信息,以增加不同层的注意力图的多样性。该方法在计算和内存开销上几乎可以忽略不计。
- 性能提升:通过替换现有ViT模型中的多头自注意力(MHSA)模块,成功训练了具有32个Transformer block的深层ViT模型,在ImageNet上的Top-1分类准确率提高了1.6%。
方法介绍
由于deep CNNs的成功,作者也系统研究了随深度变化ViT性能的变化,其中hidden dimension和head数量分别固定为384和12,然后堆叠不同数量的Transformer block(从12到32),结果如图1所示,可以看到,随着模型深度的增加,分类精度提升缓慢,饱和速度较快,且达到24个block后,性能不再有提升。

之前在CNN中也存在这个问题,但随着残差连接的提出,该问题得到了解决。而ViT和CNN的最大区别就在于self-attention机制,因此作者研究了自注意力或者更具体的说是生成的attention map随着网络深度的增加是如何变化的。作者计算了不同层的attention map之间的相似性来衡量注意力图的变化,如下

其中 \(M^{p,q}\) 是 \(p\) 层和 \(q\) 层注意力图之间的余弦相似度矩阵,每个元素 \(M^{p,q}_{h,t}\) 表示head \(h\) 和 token \(t\) 的相似度。
根据式(2),作者在ImageNet上训练了一个包含32个block的ViT,并研究了attention map之间的相似度,结果如图3(a)所示,可以看到,在第17个block之后,注意力图之间的相似度超过了比例超过了90%。这表示后面学习到的attention map是相似度,Transformer block可能退化为一个MLP。

为了理解attention collapse是如何影响ViT的性能的,作者进一步研究了它是如何影响更深层网络的特征学习的。因此作者也绘制出了随网络深度变化feature map之间的相似度变化曲线,如图4(left)所示,可以看到feature map的变化曲线和attention map的变化曲线比较相似,这一结果表明,注意力崩溃是导致ViT模型non-scalable的原因。

Re-Attention
在实验过程中,作者发现来自同一block不同head之间的attention map的相似度很小,如图3(c)所示。这表明来自同一自注意力层的不同head关注输入token的不同方面。基于此观察,作者提出建立cross-head通信来重新生成attention map。
具体来说,通过动态地聚合来自不同head的注意力图来生成一组新的注意力图。作者定义了一个可学习的变换矩阵 \(\Theta \in\mathbb{R}^{H\times H}\) 并用它来混合不同head的注意力图,具体如下

其中 \(\Theta\) 和注意力图 \(\mathbf{A}\) 沿head维度相乘,Norm是归一化函数用来减少层之间的方差,\(\Theta\) 是端到端可学习的。
实验结果
如图1所示,在将ViT中的self-attention换成Re-Attention后得到的DeepViT,随着网络深度的增加并没有像ViT那样过早的出现性能饱和,而是继续提升。
如图8(a)所示,Re-Attention的相邻block注意力图的相似度显著降低。

作者定义了DeepViT-S和DeepViT-L,具体配置如下,其中split ratio表示不用Re-Attention和使用Re-Attention的block数的比例,如图3(a)所示,只有在网络的深层注意力图和特征图之间的相似度才会变高,因此没必要在所有层的block中都使用Re-Attention。

和其它SOTA模型在ImageNet上的性能对比如下所示

代码解析
Re-Attention的实现如下,其中 \(\Theta\) 是通过卷积定义的,归一化采用的BN。
class ReAttention(nn.Module):
"""
It is observed that similarity along same batch of data is extremely large.
Thus can reduce the bs dimension when calculating the attention map.
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., expansion_ratio=3,
apply_transform=True, transform_scale=False):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.apply_transform = apply_transform
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
if apply_transform:
self.reatten_matrix = nn.Conv2d(self.num_heads, self.num_heads, 1, 1)
self.var_norm = nn.BatchNorm2d(self.num_heads)
self.qkv = nn.Linear(dim, dim * expansion_ratio, bias=qkv_bias)
self.reatten_scale = self.scale if transform_scale else 1.0
else:
self.qkv = nn.Linear(dim, dim * expansion_ratio, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, atten=None):
B, N, C = x.shape
# x = self.fc(x)
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
if self.apply_transform:
attn = self.var_norm(self.reatten_matrix(attn)) * self.reatten_scale
attn_next = attn
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x, attn_next