最近阅读MySQL高性能,略有收获,好记忆不如烂笔头,记录一下。本期笔记主要是围绕高性能MySQL第六章查询性能优化。
整体结构
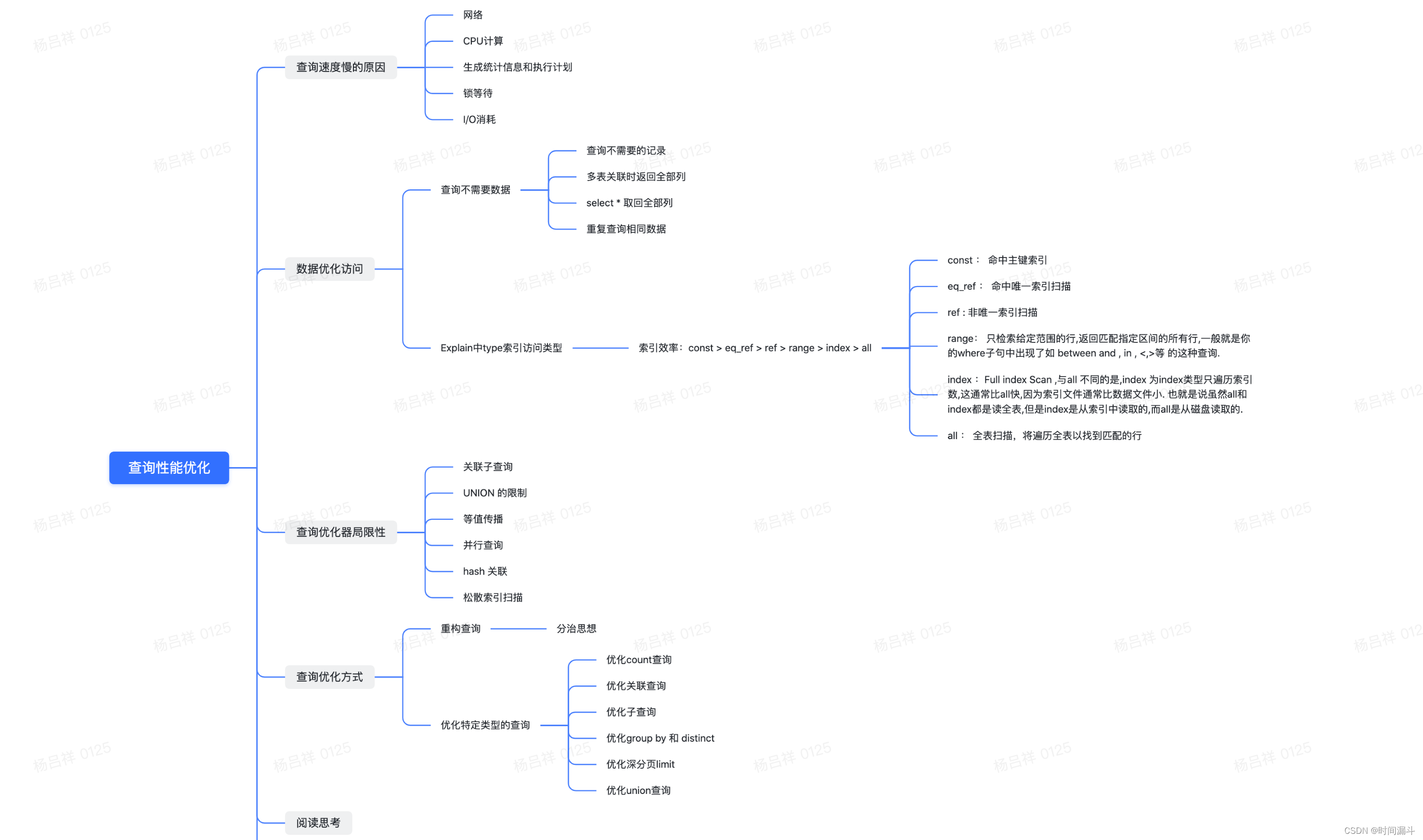
重点、亮点内容摘抄
第六章 查询性能优化
查询优化、索引优化、库表结构优化需要齐头并进,一个不落。在获得编写MySQL查询经验的同时,也将学习到何为高效的查询设计表和索引,也可以学习到优化库表结构时会影响到那些类型的查询。
本章从查询设计的一些基本原则开始,介绍一些查询优化的技巧以及MySQL优化器内部的机制,展示MySQL是如何执行查询的,如何改变一个查询的执行计划。
1. 查询执行的过程
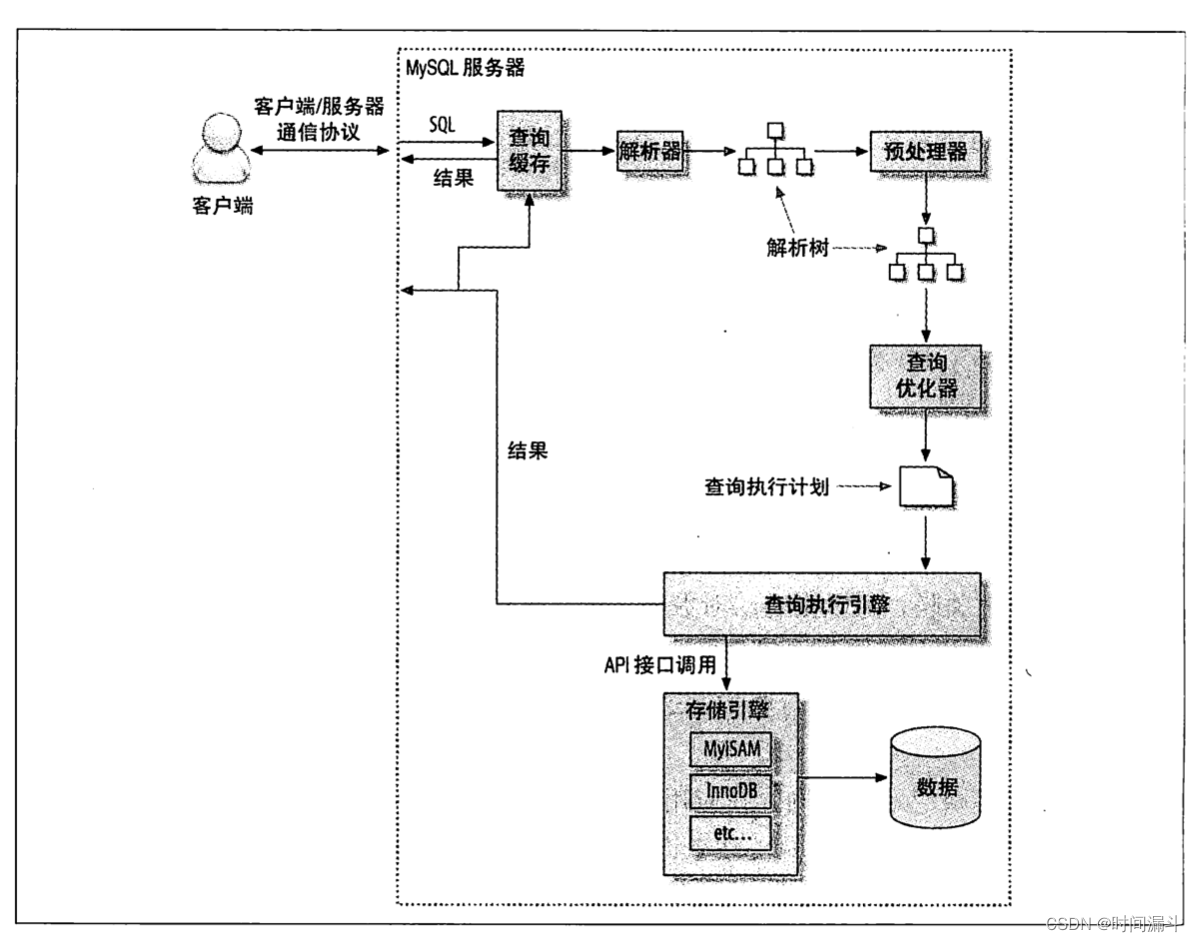
执行路径:
- 客户端发送查询请求
- 服务器检查是否有缓存,未命中缓存则进入下一阶段,命中则直接返回
- 服务器端解析 SQL ,预处理,优化器生成对应的执行计划
a. 解析器进行语法解析
b. 预处理:判断解析树是否合法,验证权限
c. 优化器生成执行计划:优化器基于成本模型做出认为的最优选择
- MySQL 认为的最优跟你想的最优可能不一样,并不一定是时间最短的查询
- 静态优化&动态优化 -> “编译时”优化&“运行时”优化
- 优化器优化类型:
- 重新定义关联表的顺序(驱动表)
- 外连接转为内连接
- 条件的等价转换
- 优化 count()
- 预估并转为常数表达式(关联查询时,根据第一层查询的结果预估第二层查询的类型,转为常数表达式类型)
- 覆盖索引扫描
- 子查询优化
- 提前终止查询(limit)
- 等值传播(连表健做条件时,条件可传播到两个表)
- in 查询 VS or 查询(MySQL 认为不等价,in 查询会先对列表做排序,再二分,Ologn 复杂度)
- MySQL 根据优化器生成的执行计划,调用存储引擎 API 执行查询
- 返回结果
2. 慢查询基础:优化数据访问
数据优化访问
- Select * 取回全部列
- select * 可以被允许,但永远不要忘记这样做的代价是什么。(在某些场景下 select * 能够简化代码,提高某些代码片段的复用性,但 select * 可能会带来额外的 IO、CPU、内存消耗)
- 需要扫描大量行却只返回少量行的情况
- 使用覆盖索引,避免回表
- 改变库表结构,比如使用单独的汇总结果表
- 重写 SQL
- 多表关联时返回了全部列
- 确认MySQL服务器层是否在分析大量超过需要的数据行。
- 响应时间:服务时间(执行的时间)+排队时间(IO等待、锁等待)
- 扫描的行数
- 返回的行数
用Explain中type确定索引类型
- 索引效率:const > eq_ref > ref > range > index > all
- const : 命中主键索引
- eq_ref : 命中唯一索引扫描
- ref : 非唯一索引扫描
- range: 只检索给定范围的行,返回匹配指定区间的所有行,一般就是你的where子句中出现了如 between and , in , <,>等 的这种查询.
- index :Full index Scan ,与all 不同的是,index 为index类型只遍历索引数,这通常比all快,因为索引文件通常比数据文件小. 也就是说虽然all和index都是读全表,但是index是从索引中读取的,而all是从磁盘读取的
- all : 全表扫描,将遍历全表以找到匹配的行
3. 查询优化器的局限
MySQL 查询优化器并不是银弹,在某些场景下查询优化器也具有局限性
- 关联子查询:where 条件中包含 in() 的子查询
- 建议:改写成内连查询
- 举例:select * from film where film_id IN (select film_id from film_actor where actor_id =1)
- 建议写法:select film.* from film INNER JOIN film_actor USING(film_id) where actor_id =1.
- UNION 的限制:有时候 MySQL 无法将查询条件从外层下推到内层, 这样导致原本能通过limit来限制部门返回结果的条件无法应用到内层查询的优化上。
- 举例:( select columnA, clolumnB from tableA order by create_time desc) union all ( select columnA,columnB from tableB order by create_time desc) limit 100;
- 建议写法:( select columnA,clolumnB from tableA order by create_time desc limit 100) union all ( select columnA,columnB from tableB order by create_time desc limit 100) limit 100;
- 等值传播:等值传递在某些场景下会带来较大的意想不到的性能损耗
- 等值传播:
在这里插入图片描述
- 等值传播:
- 举例:在连接查询中,查询条件中 in() 列表很大,如果优化器发现这个字段在 where、on、using 字句中可以等值传递,那么优化器会将该条件等值传递到关联的各个表中,导致每个表都需要做一次 in() 大列表的查询,带来额外的性能损耗
- 建议写法:改写 SQL,即使是单表查询,也不推荐一次 in() 的个数过多,因为那样会导致索引失效。
- 并行查询:MySQL 不支持并行查询。
- hash 关联:MySQL 不支持 hash 关联
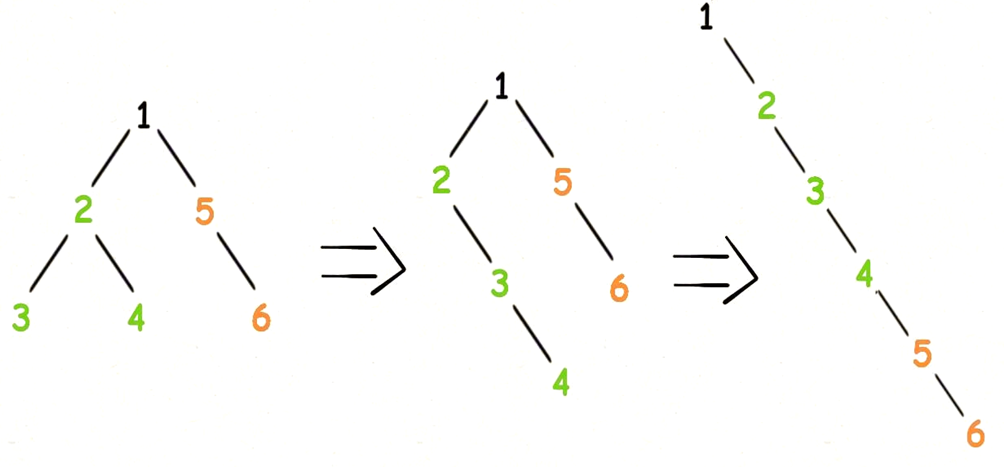
- 松散索引扫描:MySQL 目前不支持松散索引扫描
- MySQL 无法按照不连续的方式扫描一个索引,只支持按顺序扫描,以联合索引 (a,b) 为例,最左匹配原则,如果查询条件仅有字段 b,那字段 b 的查询无法使用到索引,只能全表扫描。
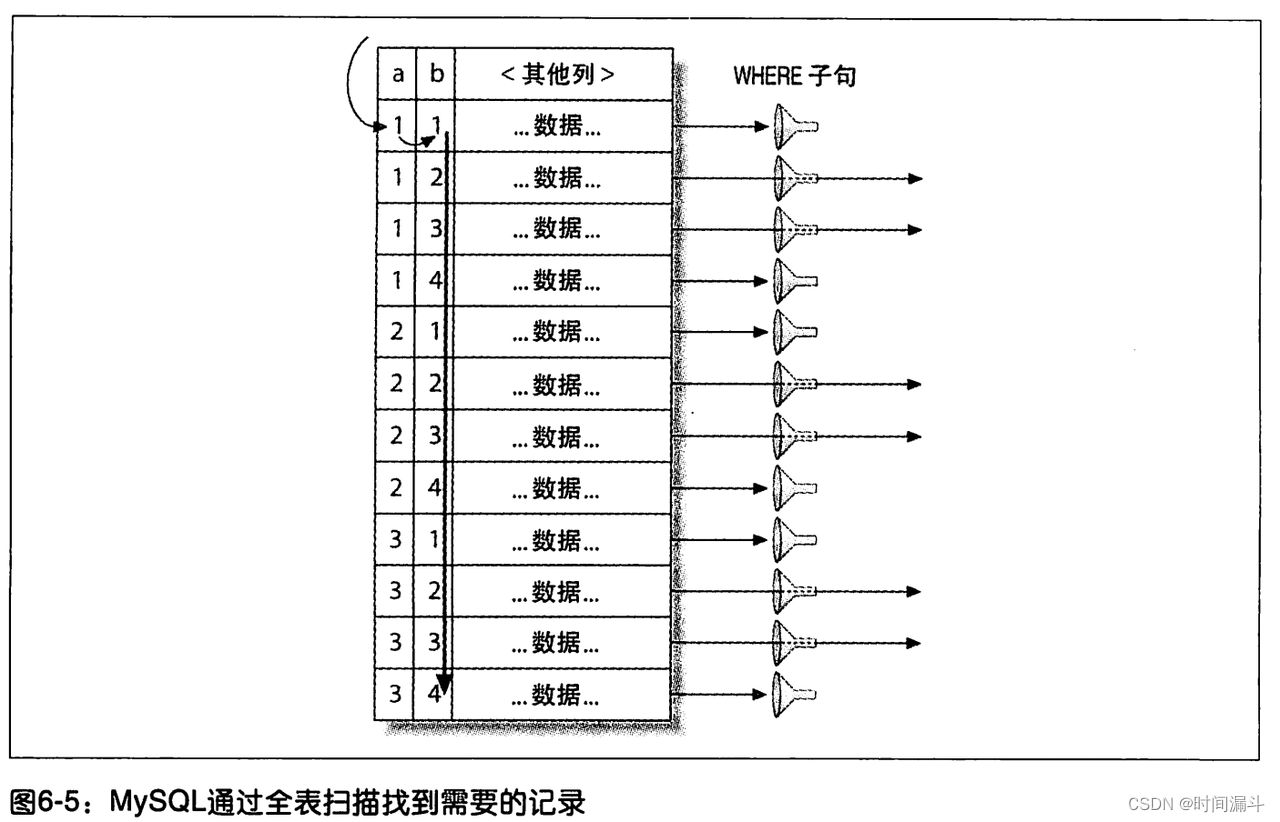
- 如果 MySQL 能支持跳跃查找(松散索引的查找方式,类似 oracle 的跳跃索引扫描),那它的额查询方式应该是类似下图
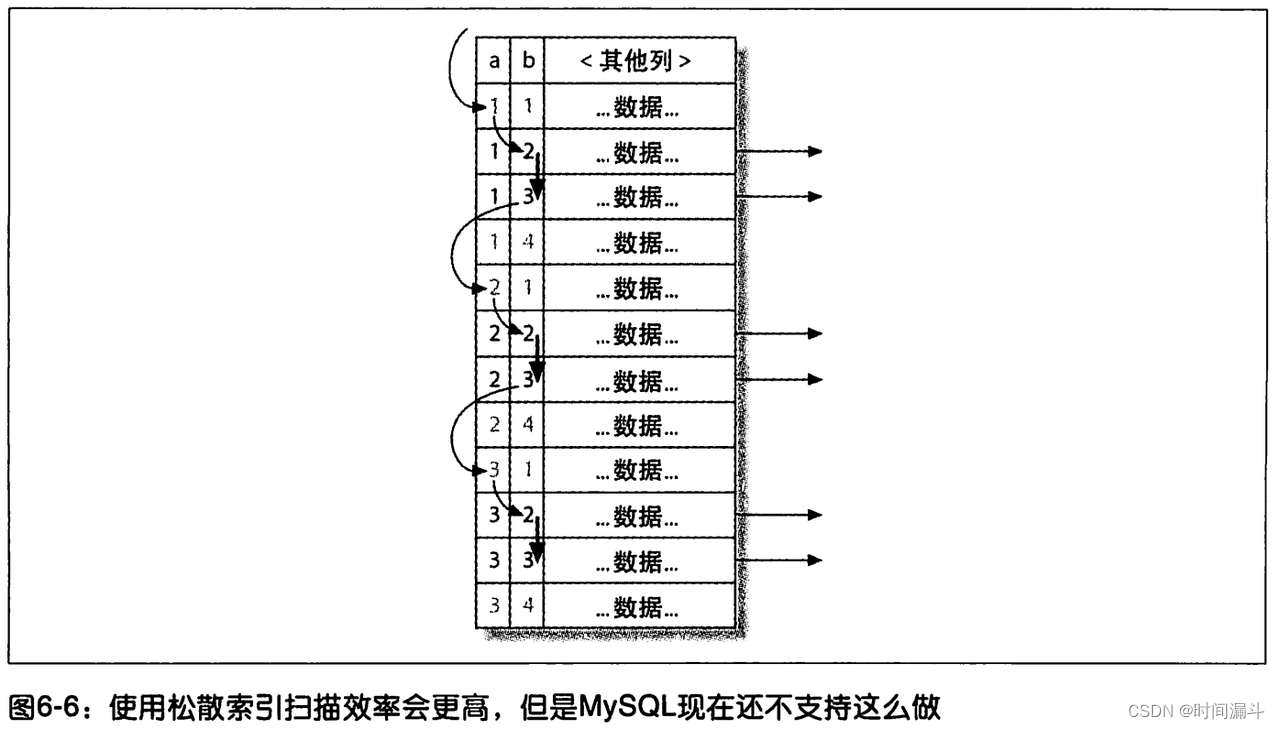
使那些在where条件中没有对目标索引的前导列指定查询条件但同时又对该 索引的非前导列指定了查询条件的目标SQL依然可以用上该索引,这就像是在扫描该索引时跳过了它的前导列,直接从该索引的非前导列开始扫描一样。
- MySQL 无法按照不连续的方式扫描一个索引,只支持按顺序扫描,以联合索引 (a,b) 为例,最左匹配原则,如果查询条件仅有字段 b,那字段 b 的查询无法使用到索引,只能全表扫描。
4. 查询优化方式
优化通常不只是从技术手段上进行优化,也包括从产品形态、系统交互等层面综合考虑,权衡后得出最优解。
-
重构查询(主要是分治的思想)
- 一个复杂查询可以拆分成多个简单查询
- 切分查询:使用索引字段分段查询
- 分解关联查询:拆分 join(有排序分页的 SQL 不适用)
-
优化特定类型的查询
- 优化count() 查询
- count(column) 统计的是该列值不为 NULL 的数量,count(*) 统计行数
- 某些情况下,“快速、精确和实现简单”三者只能满足其二(任何情况下都是在做权衡)
- 某些分页列表查询接口,需要展示总记录数,在总数量较大的情况下,不展示精确数量。如飞书审批在任务量超过99时展示 99+
- 优化关联查询
- 确保连表键有索引
- 确保 group by 和 order by 中只涉及到一个表中的列,这样 MySQL 才有可能使用索引来优化查询过程
- 优化子查询
- 建议尽可能使用关联查询代替子查询
- 优化 group by 和 distinct
- 建议使用索引进行优化
- 如果 group by 字段没有索引,MySQL 会用临时表或者文件排序来进行分组
- 优化 limit 分页
- 深分页问题:偏移量很大的情况下(如 select * from table limit 100000,10),mysql 需要查出100010条记录后只返回10条,偏移量越大,代价越高。
- 解法:
- 场景1:迁移数据场景,需要分页遍历某个大表所有数据,可对索引字段排序并做条件,可解( select * from table where columnA < ${lastMaxColumnAValue} order by columnA desc limit 10)
- 场景2:用户列表页,分支查询大量数据。可限制不允许随机翻页,仅支持顺序翻页,加上游标查询,可解。
- 优化 union 查询
- 写 SQL 时可以手动下推一些外层条件到子语句中(不一定普适,需要结合场景判断)
- 注意 union 和 union all 的区别,如果不是强要求去重,建议一定使用 union all,否则 MySQL 会对临时表做一次全表的 distinct。
阅读思考
- 日常工作中遇到的慢查询,大都可以根据慢查询的原理来映射到对应的场景上面(访问了不需要的数据、查询扫描行数过多、查询返回行数过多等),除此之外,因为 MySQL 回表访问数据的时候是按照行读取的,如果遇到表的字段比较多,导致一行数据分布在多个磁盘数据块(数据行存储分裂,访问时需要额外一次磁盘寻址IO),也会导致查询性能下降,这个也是我们在设计 Schema 时拒绝宽表的原因。
- 除了上述场景,5.4之后的 MySQL 中 BLOB 、TEXT 字段使用的是指针链式存储(访问时需要额外一次磁盘寻址IO),在有 BLOB 、TEXT 字段的表中查询数据,如果不是明确对 BLOB 、TEXT 字段有访问需求,需要特别注意不要查询 BLOB 、TEXT 字段。