文章目录
- 第一题(二叉树度结点的计算)
- 第二题(平衡查找二叉树)
- 第三题(堆的插入)
- 第四题(哈希表的查找)
- 第五题(大数排序)
第一题(二叉树度结点的计算)
若一棵二叉树具有12个度为2的结点,6个度为1的结点,则度为0的结点个数是()
A 10
B 11
C 13
D 不确定
n0=n2+1,所以度为0的个数为12+1=13
C
第二题(平衡查找二叉树)
下列各树形结构中,哪些是平衡二叉查找树:
A
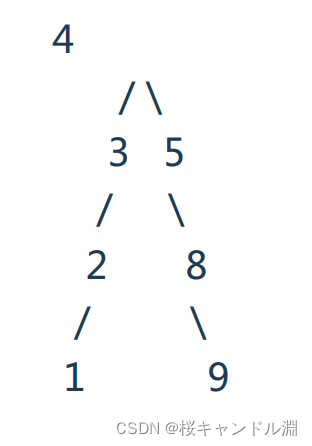
B

C
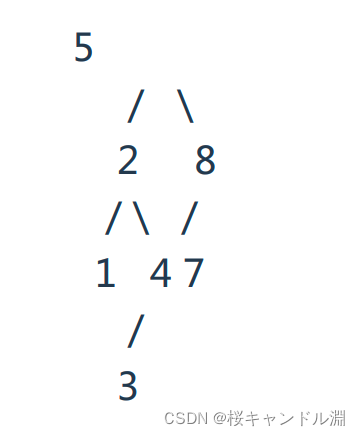
D
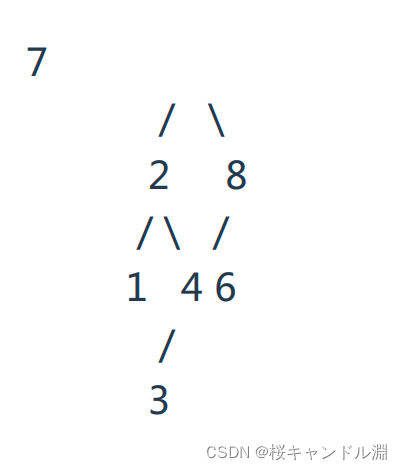
A:是二叉查找树,但是平衡因子大于了1,
B:7的那个节点的平衡因子为-2,大于了1
D:右树中的6小于了7,不是二叉搜索树
C
第三题(堆的插入)
已知关键字序列5,8,12,19,28,20,15,22是最小堆,插入关键字3,调整后得到的最小堆是()
A 3,8,12,5,20,15,22,28,19
B 3,5,12,19,20,15,22,8,28
C 3,12,5,8,28,20,15,22,19
D 3,5,12,8,28,20,15,22,19
然后我们就得到了我们的结果
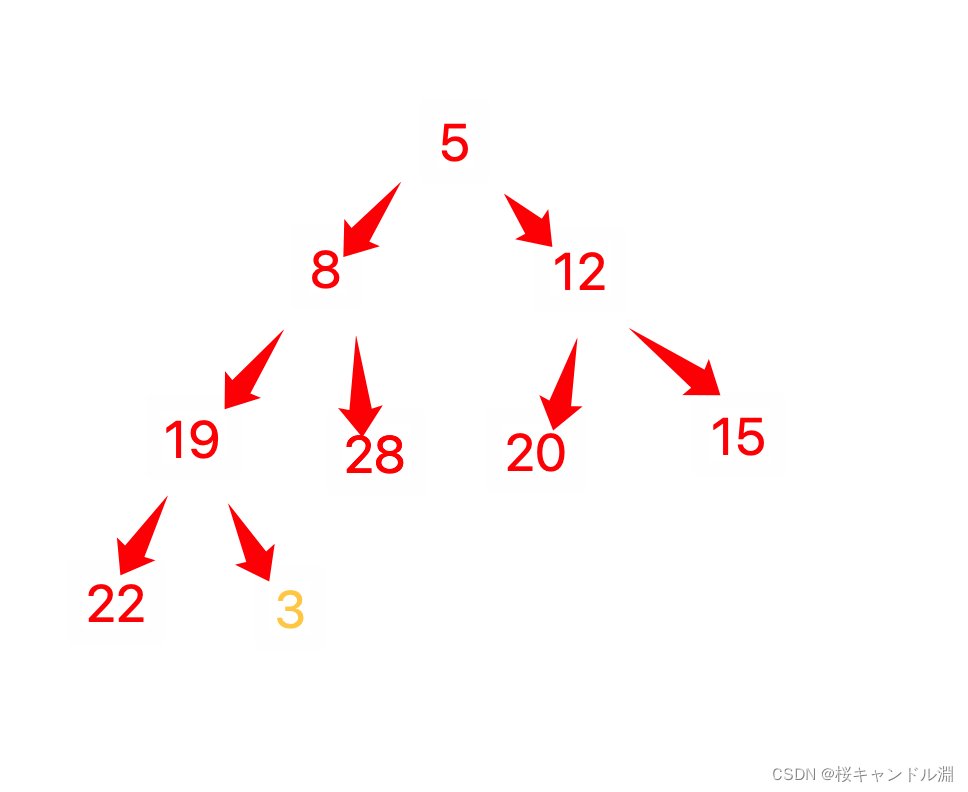
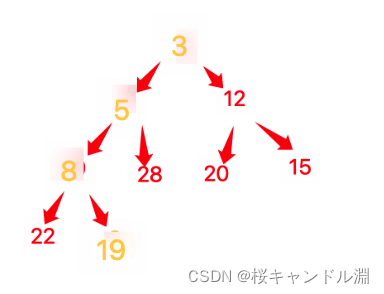
D
第四题(哈希表的查找)
采用哈希表组织100万条记录,以支持字段A快速查找,则()
A 理论上可以在常数时间内找到特定记录
B 所有记录必须存在内存中
C 拉链式哈希曼最坏查找时间复杂度是O(n)
D 哈希函数的选择跟A无关
A:这么多的数据,会存在很多冲突,我们无法保证在常数的时间内查找到。
B:如果数据量非常大,我们需要借助外部的存储设备
C:拉链式的哈希就是一个顺序表+链表的结构,最坏的情况是这100万个数据全部都冲突了,也就是我们的数据全部都存在一个哈希桶的链表中,也就是变成了链表的查找的时间复杂度,也就是O(n)
正确
D:与A有关,如果是整数的话,我们可以直接除留余数法,但是如果是字符串,我们还需要将其转换成key值,再进行映射
C
第五题(大数排序)
假设你只有100Mb的内存,需要对1Gb的数据进行排序,最合适的算法是()
A 归并排序
B 插入排序
C 快速排序
D 冒泡排序
归并排序可以实现外部排序。比方说将1GB的数据分成好几个文件,然后两两归并,从而减少需要导入内存的文件大小,解决内存空间小,数据量大的问题。
A






![[附源码]java毕业设计双学位在线考试系统](https://img-blog.csdnimg.cn/c2195cc5590f478585405eb4c1d34ebb.png)

![[附源码]SSM计算机毕业设计远程教育系统JAVA](https://img-blog.csdnimg.cn/32e6ba7a20844e3a8bf698e18154dd1f.png)