问题引入
上一节我们学习了贪心的基本概念、基本思路以及证明方法,下面我们一起来学习区间类贪心类问题,这里我们学习的重点依然是贪心的策略和证明。
算法原理区间贪心:
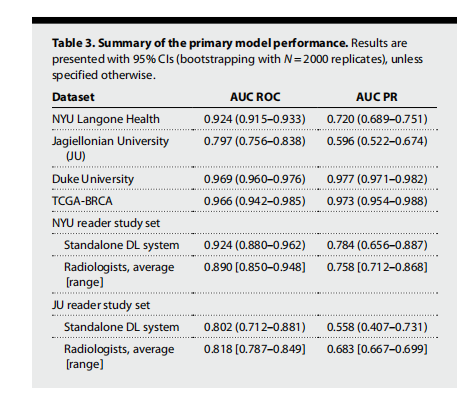
是指在区间上做贪心。区间贪心一般都是按左端点或者右端点排序,大胆假设,小心求证。当你觉得是贪心题的时候,千万不要轻易相信题目给的样例,尽量多找几组例子试试,样例验证成功后最好还要证明贪心算法是否成立。
例题引入凌乱的拓拓快noip了,拓拓同学很紧张!现在各大oj上有n个比赛,每个比赛的开始、结束的时间点是知道的。拓拓同学认为,参加越多的比赛,noip就能考的越好(假的)。所以,他想知道他最多能参加几个比赛。由于拓拓同学是个蒟蒻,如果要参加一个比赛必须善始善终,而且不能同时参加2个及以上的比赛。他想知道自己最多能参加几个比赛。输入数据不超过10610 6 。【问题分析】如果所有的比赛时间不冲突,那么就可以全部参加了,但并没有这么简单。如果两个比赛时间冲突,要分情况看待,冲突的比赛关系我们分成以下两种情况讨论(其他的比赛冲突都能转化成这两种情况)。
如下图所示:

(a) 一个比赛被另一个包含:两个比赛冲突,选择比赛1,因为比赛1先结束,这样后续比赛被占用时间的可能就少一些。
(b) 一个比赛和另一个比赛相交:还是选择比赛1,理由同上。最先选择参加哪一场比赛呢?根据分析,应该选择参加最先结束的那一场比赛。接下来,要选择能够参加的比赛中,最早结束的比赛(既然已经决定参加上一场比赛,那么所有和上一场冲突的比赛都不能参加了),直到没有比赛可以参加为止。这样可以保证不管在什么时间点之前,能够参加的比赛的数量都是最多的。因此贪心算法成立。这就是证明贪心算法的另一种方法:数学归纳法。每一步的选择都是到当前为止的最优解,一直到最后一步就成为了全局最优解。代码如下:
#include <bits/stdc++.h>
using namespace std;
int n, ans, finish; //finish记录上一次结束的比赛时间
struct contest{
int l, r; //l比赛开始时间,r比赛结束时间
} c[1000010];
bool cmp(contest a, contest b){ //按照结束时间从小到大排序
return a.r < b.r;
}
int main()
{
cin >> n;
for(int i=1;i<=n;i++){
cin >>c[i].l >> c[i].r;
}
sort(c+1, c+n+1, cmp);
for(int i=1;i<=n;i++){
//保证上一次比赛结束的时间 <= 第i场比赛的开始时间
if(finish <= c[i].l){
ans++;
finish = c[i].r; //更新比赛结束的时间
}
}
cout << ans;
return 0;
}
本题中将所有比赛的结束时间排序,然后依次进行贪心:
如果能够参加这场比赛,就报名;如果这场比赛和上一场参加的比赛冲突,就放弃。 常见的区间贪心类问题一般可以分成四种不同的题型,下面我们一起来探讨下这四种经典的区间贪心模型。
经典模型一:区间选点问题
【例题1】 给定N(N≤ 1 0 5 10 5 )个闭区间[ 𝑎 𝑖 a i, 𝑏 𝑖 b i](闭区间是指包含左右两个端点的区间),请你在数轴上选择尽量少的点,使得每个区间内至少包含一个选出的点。输出选择的点的最小数量。位于区间端点上的点也算作区间内。( − 1 0 9 −10 9 ≤ 𝑎 𝑖 a i≤ 𝑏 𝑖 b i≤ 1 0 9 10 9 ) 【问题分析】 因为不方便展示同一数轴上的区间,所以把区间上下平移了。举例如下:

上述图片是给定了8个区间,分别编号1~8,应该如何选择我们的策略呢?
以下为两个区间之间可能的3种关系。(1)如果只有两个区间3区间和4区间,我们必须选择两个点使得每个区间内至少包含一个点;(2)如果只有两个区间1区间和2区间,那么我们肯定选择在1区间和2区间重合的部分放点;(3)如果只有两个区间6和7区间,我们还是选择在两个区间重合的地方放点。那么我们是是优先选择点在区间中间位置?还是优先选择点在区间开始位置?亦或是选择点在区间结束位置?很明显,我们应该尽量选择重合区间结束的位置,因为这样才能保证选择的点也能尽量在后面的区间中。思路:按右端点从小到大排序,然后顺次遍历这些区间,每次选取当前区间的右端点,然后略过含这个右端点的区间,直到遍历到下一个不含这个点的区间,再取这个区间的右端点,以此类推。证明:假设ans是最优解(正确答案),cnt是可行解(贪心答案),显然有ans≤cnt。反证法证明ans≥cnt。我们将这cnt个点所在那些区间取出来,显然它们是不相交的(若相交,则贪心求解的是cnt-1个点),得出最多有cnt个两两不相交的区间,覆盖每个区间至少需要cnt个点。因此ans≥cnt。综上ans=cnt,证明完毕。代码如下:
#include <bits/stdc++.h>
using namespace std;
struct Range {
int l, r;
} range[100010];
bool cmp(Range a, Range b) { // 按照右端点从小到大排序
return a.r < b.r;
}
int main() {
int n, ans = 0, ed = INT_MIN; //ed表示上一个点的位置
cin >> n;
for (int i = 0; i < n; i++) {
cin >> range[i].l >> range[i].r;
}
sort(range, range + n, cmp);
for (int i = 0; i < n; i++) {
if (range[i].l > ed) {
ed = range[i].r; // 在当前区间的右端点放一个点
ans ++ ;
}
}
cout << ans;
}
经典模型二:最大不相交区间数量问题
【例题2】给定N个闭区间[𝑎𝑖a i ,𝑏𝑖b i ],请你在数轴上选择若干区间,使得选中的区间之间互不相交(包括端点)。输出可选取区间的最大数量。(数据范围和上一题一致)【问题分析】有以下三种策略:① 优先选择区间长度较小的?② 优先选择开始位置靠前的?③ 优先选择结束位置靠前的?大胆假设:选择右端点最靠前的区间,这样可能对后面区间的影响最小。证明:假设ans是最优解(正确的答案),表示最多不相交区间的数量;cnt是可行解,表示用贪心算法求出cnt个不相交的区间,显然有ans≥cnt。反证法证明ans≤cnt。假设ans>cnt,由最优解的含义知,最多有ans个不相交的区间,因此至少需要ans个点才能覆盖所有区间,而根据贪心算法知,只需cnt个点就能覆盖全部区间,且cnt<ans,这与上面分析“至少需要ans个点才能覆盖所有区间”相矛盾,故ans≤cnt。综上所述ans=cnt。思路:首先将每个区间按照右端点从小到大进行排序。ed表示当前放置在数轴上的点的位置,开始初始化为无穷小,表示没有放置,此时数轴上没有点之后依次遍历排序好的区间。如果区间的左端点大于当前放置点的位置,说明当前点无法覆盖区间,则把点的位置更新成该区间的右端点,表示在该区间的右端点放置一个新的点,同时更新点的个数。代码如下:
#include <bits/stdc++.h>
using namespace std;
struct Range {
int l, r;
} range[100010];
bool cmp(Range a, Range b) {
return a.r < b.r;
}
int main() {
int n, ans = 0, ed = INT_MIN;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> range[i].l >> range[i].r;
}
sort(range, range + n, cmp);
for (int i = 0; i < n; i++) {
if (range[i].l > ed) {
ed = range[i].r;
ans ++ ;
}
}
cout << ans;
}
我们会发现,和上一题的代码一样。为什么最大不相交区间数等同于最少区间点数呢?因为如果几个区间能被同一个点覆盖,说明他们相交了,所以有几个点就是有几个不相交区间。
经典模型三:区间分组问题
【例题3】给定N个闭区间[𝑎𝑖a i ,𝑏𝑖b i ],请你将这些区间分成若干组,使得每组内部的区间两两之间(包括端点)没有交集,并使得组数尽可能小。输出最小组数。(数据范围同上)【问题分析】按照之前两题的经验,我们大胆假设:右端点排序。但是你稍作思考就会想到:假设有如下图所示的4个区间,按照右端点排序是1、2、3、4,进行分组得到的结果


因此按照右端点排序会找到一个反例,假设不成立。接下来我们考虑左端点排序行不行?思路:左端点排序,从前往后处理每个区间,判断能否将其放到某个现有的组中。如果不存在,则开新组放入,如果存在,则放进该组并更新该组的最大右端点。证明:假设ans是最优解,表示最少需要ans个组;cnt是可行解,表示算法找到cnt个组,显然有ans≤cnt。反证法证明ans≥cnt。考虑在开辟第cnt个组的过程:算法此时已经开辟了cnt−1个组,组内区间两两不相交,组间区间有交集,且当前遍历区间的左端点均小于各组所有区间中最大的右端点,即当前遍历的区间一定与各组区间相交,此时必须要开辟新的组放入新的区间,因此至少需要cnt个组,即ans≥cnt。综上所述ans=cnt。代码如下:
#include <bits/stdc++.h>
using namespace std;
struct Range {
int l, r;
} range[100010];
int arr[100010], idx;
bool cmp(Range a, Range b) { //按照左端点排序
return a.l < b.l;
}
int main() {
int n;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> range[i].l >> range[i].r;
}
sort(range, range + n, cmp);
for (int i = 0; i < n; i++) { // n个区间
bool f = 1; // 默认需要开辟新空间
for (int j = 0; j < idx; j++) {
if (arr[j] < range[i].l) { // 第i个区间可以放到第j组
arr[j] = range[i].r; // 放到第j组,更新j组的右端点
f = 0;
break;
}
}
if (f) { //f是1,需要开辟新空间
arr[idx] = range[i].r;
idx++;
}
}
cout << idx;
}
在代码求解最小组数时用了双重for循环,时间复杂度为O(n2),提交代码可能会超时。可以用二叉堆(优先队列)优化程序,时间复杂度变为O(nlogn),由于还没讲过这种数据结构,我们还是以理解贪心的思路为主。
经典模型四:区间覆盖问题
【例题4】给定N个闭区间[𝑎𝑖a i ,𝑏𝑖b i ]以及一个线段区间[s,t],请你选择尽量少的区间,将指定线段区间完全覆盖。输出最少区间数,如果无法完全覆盖则输出−1。【问题分析】如下图所示,我们来分析这一题的思路

对于线段区间[s,t],最多的选法就是全部选择,得到答案5个区间。但是题目要求最少的区间数覆盖掉[s,t],所以我们可以选择[a1,b1]、[a3,b3]、[a5,b5],答案就是最少的区间数3个。为什么不选[a2,b2]呢,很明显我们选择[a1,b1]会更好。为什么不选[a4,b4]呢,很明显[a3,b3]和[a5,b5]已经覆盖掉[a4,b4]了。我们可以这样考虑求解过程,当选择了[a1,b1],此时我们将线段区间的s更新为b1;然后再去选择下一个可选的区间[a3,b3],继续将s更新为b3;这时[a4,b4]与[a5,b5]都能覆盖[s,t](的一部分),按照上述规则,我们优先选择b更靠后的区间[a5,b5],最终得到答案3个。于是我们可以大胆假设:首先将所有区间按左端点从小到大排序,之后从前往后依次枚举每个区间,在所有能覆盖start的区间中选择右端点最大的区间,并将start更新成右端点的最大值。证明思路正确性(选学):假设ans是最优解,表示最少需要ans个区间;cnt是可行解,表示算法找到cnt个区间满足覆盖,显然有ans≤cnt。采用反证法证明ans≥cnt。假设最优解由k个区间组成,各区间按右端点从小到大排序,右端点依次记为a1,a2,…,ak,显然一定有t≤ak,否则最优解没有覆盖到线段区间[s,t]的右端点t,不满足覆盖条件;同理,假设算法求得m(m>k)个区间,各区间按右端点从小到大排序,右端点依次记为b1,b2,…,bk,…,bm,显然一定有bk<t≤bm。t≤bm是为了满足覆盖条件;bk<t是因为bk不是最后一个区间的端点,如果bk≤t,则:考虑最优解和贪心算法各自获得的第1个区间的右端点a1和b1,由于贪心算法选取右端点距离起点s最大的区间,故一定有a1≤b1;贪心算法又以b1为起点,找一个右端点距离b1最大的区间,最优解选取的第2个区间的右端点a2不可能超过b2,否则存在一个区间的长度a2−a1大于b2−b1,这与贪心算法矛盾,故一定有a2≤b2;同理一定有ak≤bk,由于bk<t,故ak<t,这说明最优解没有覆盖线段区间[s,t],矛盾;故ans≥cnt。综上所述ans=cnt。代码如下:
#include <bits/stdc++.h>
using namespace std;
struct Range {
int l, r;
} range[100010];
bool cmp(Range a, Range b) { // 按照左端点从小到大排序
return a.l < b.l;
}
int main() {
int n, s, t, ans = 0;
cin >> s >> t >> n;
for (int i = 0; i < n; i++) {
cin >> range[i].l >> range[i].r;
}
sort(range, range + n, cmp);
for (int i = 0; i < n; i++) { //第16行
// maxr表示所有包含s的区间中右端点的最大值
int maxr = INT_MIN, j;
for (j = i; j < n && range[j].l <= s; j++) { //第19行
maxr = max(maxr, range[j].r);
}
// 中间某次覆盖不了 或者 所有区间的最右边都<t,均为无解
if (maxr < s || (i == n - 1 && maxr < t)) {
ans = -1;
break;
}
ans++;
if (maxr >= t) { //得到解
break;
}
s = maxr; //更新区间起点为当前选择区间的右端点
i = j - 1; //19行j++和将执行的16行i++会多加1,所以下标变为j-1
}
cout << ans;
}
注意理解i=j-1这一行。因为19行跳出循环的时候j++会多算一次,实际上结束19行的for循环后我们选择的是第j-1个区间,之后可以从第j个区间开始选,但是16行的i++会在i=j-1赋值后执行一遍,所以这里赋值为j-1。兵无常势,水无常形,贪心算法非常考验同学们的思维。学习贪心算法没有固定的程序模板,因此请看官们记住贪心的学习方法:大胆假设,小心求证;多练习,多思考,多总结。