目录
- 基本数据类型,引用数据类型,String
- 引用拷贝
- 对象拷贝
- 浅拷贝
- 深拷贝
- 原型模式
基本数据类型,引用数据类型,String
这里为了更好的理解栈,堆的指向关系,Java传值,传引用问题,我找来一个题可以练习一下:
public class Application {
public static void main(String[] args) throws CloneNotSupportedException {
ReferenceOrValue referenceOrValue = new ReferenceOrValue();
// 测试基本数据类型
int a=0;
referenceOrValue.changeValue1(a);
System.out.println(a);
// 测试引用类型
Person person = new Person();
person.setNum(0);
referenceOrValue.changeValue2(person);
System.out.println(person);
//测试String类型
String str="abc";
referenceOrValue.changeValue3(str);
System.out.println(str);
}
}
class ReferenceOrValue{
public void changeValue1(int num){
num=100;
}
public void changeValue2(Person person){
person.num=100;
}
public void changeValue3(String str){
str="xxx";
}
}
@Data
class Person{
public int num;
}
结果:

思考:为什么是这样的结果?
首先,要明白基本数据类型有哪些? Java8大基本数据类型:byte,short,int,long,float,double,char,boolean,其他都为引用类型。
基本数据类型在作为参数时传递的是值,引用参数类型在参数传递时传递的是地址。
回到题目中
- 向changeValue1()函数中传递的是基本数据类型,将0作为值向函数中传递(相当于int的一个副本),但在函数中将变量设置为100,此100只在函数中有效所以不会影响到外面。
- 向changeValue2()函数中传递的是引用类型,将对象的地址向函数中传递(相当于本身),在函数中已经将此地址的值修改,虽然没有将此变量向外暴露出去,但内存值已经发生改变
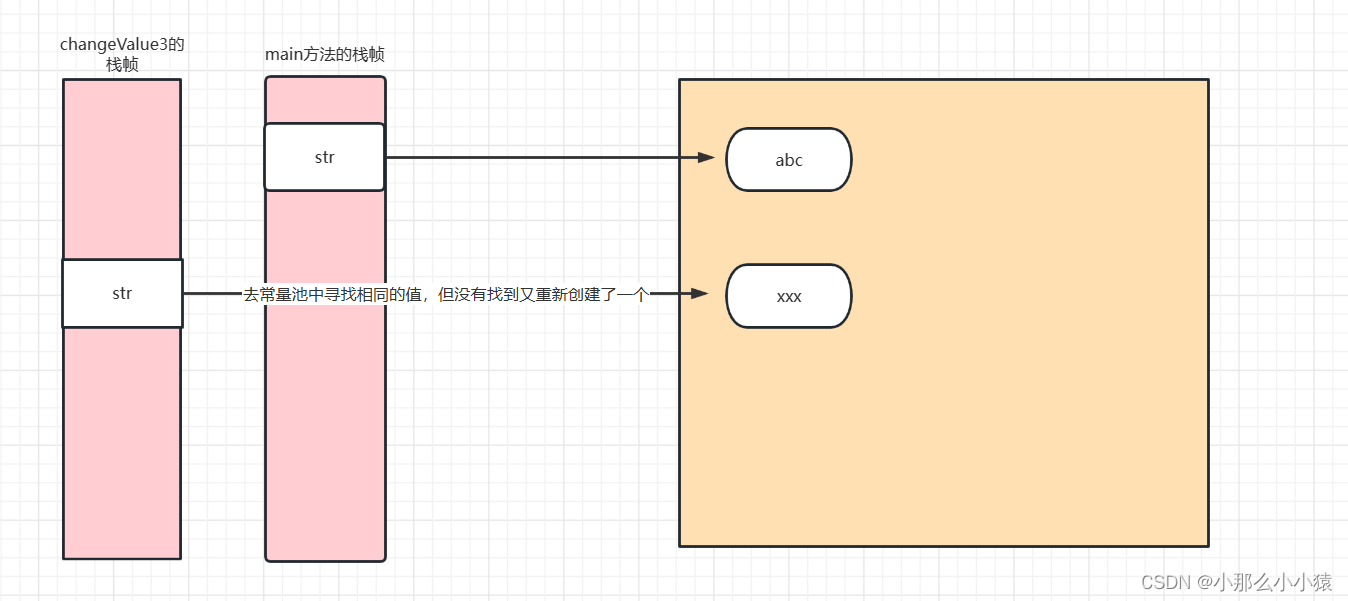
- 向changeValue3()函数中传递的是String类型,
String类型也是引用类型,之所以单拿出来是因为它比较特殊。传递的是引用,在方法内此引用的内存的地址被改为"xxx"按理说,最后输出变量的值应该为"xxx",但结果却不是这样,这就是String类型特殊的地方,这是为什么呢?
String在JVM的方法区的元空间有一个常量池,在对String变量赋值时,原则就是在常量池去寻找相同的值,有则引用,没有则创建。在方法中,“xxx”在元空间并不存在,(元空间中只存在"abc")所以,就会在常量池重新开辟一个地址,然后在str指向新的地址,但函数内的str只在函数内有效,原str指向的内容并未被破坏,因此值依然为abc。
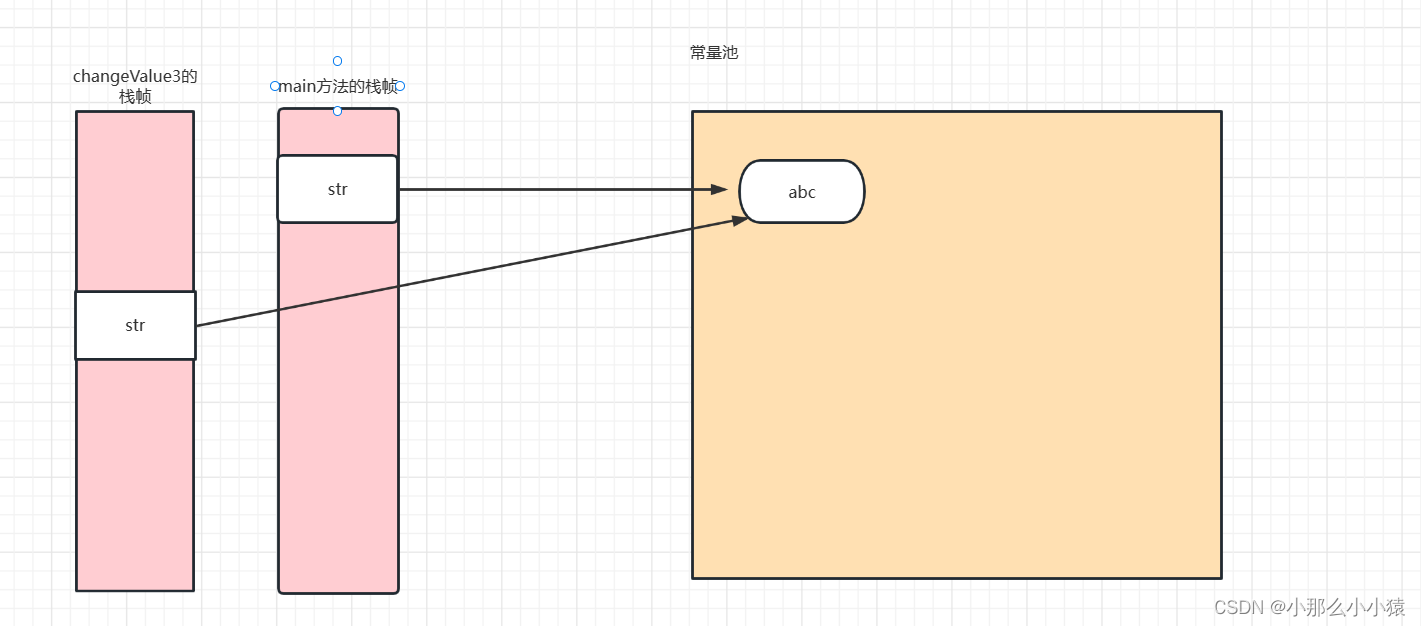
思考:如果改成这样,那么底层的引用关系是怎样的呢?

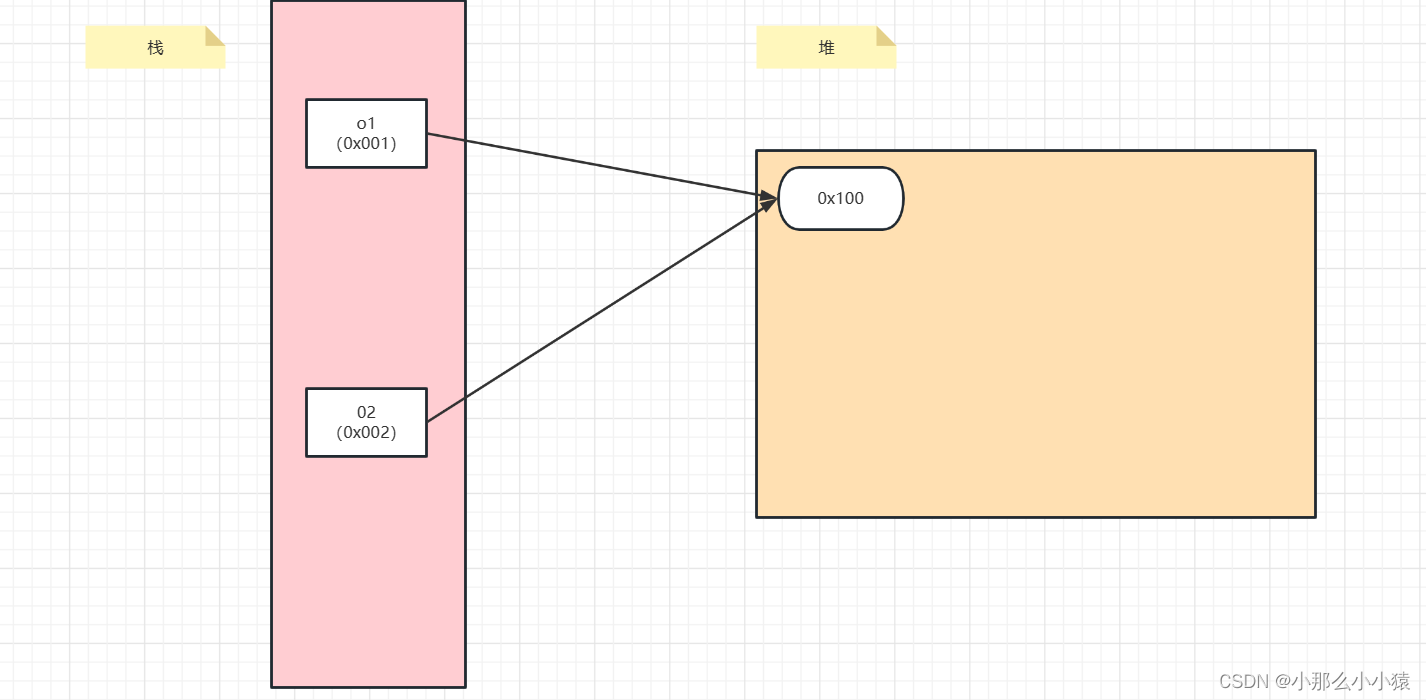
引用拷贝
引用拷贝是直接复制栈中指向堆内存的地址,例如:Object o1=new Object(),左边的变量在栈空间的地址为0x001,右边对象在堆空间的地址为 0x100,这时进行引用复制,Object o2=o1,这时没有进行new,在栈空间开辟了一个新地址 0x002,但堆内存还是之前的0x100。这时,如果我操作o2,堆内存的数据就会发生变化,这时,同样指向此堆空间的还有o1对象,因此o1的数据也会发生变化。
代码演示:(这里使用lombok只为简化代码,对结果没有影响)

结果:
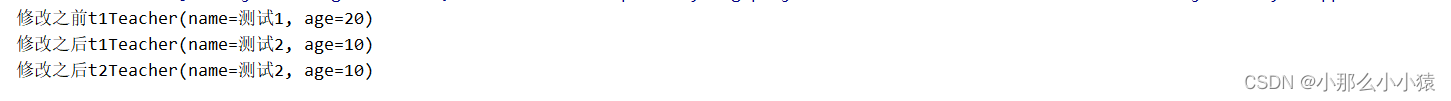
可以证明:在复制了原对象进行引用拷贝后,修改副本但原对象却发生变化,可以证明只是栈空间进行了复制,引用同一个堆空间。
对象拷贝
对象拷贝包括深拷贝与浅拷贝。都是重新在堆空间又开辟了一个空间,但拷贝的深度不同。概括来说:深拷贝就是将对象中包含的其他对象也开辟堆空间进行拷贝,浅拷贝只开辟空间重新存储此对象的中的信息,至于此对象中的其他对象采用的是引用拷贝。
注意:无论是神拷贝还是浅拷贝 类都需要实现 Cloneable 接口,重写Clone()方法
浅拷贝
浅拷贝只需要要考虑要复制的对象,而不会关心对象中的其他对象。
如图:这是在对象中不含有其他对象的浅拷贝,拷贝后,原型与副本是两个独立的空间,对副本的修改不会影响到原型对象

代码演示:
public class Application {
public static void main(String[] args) throws CloneNotSupportedException {
Teacher t1 = new Teacher().setName("老师1").setAge(100);
Teacher t2 = (Teacher) t1.clone();
System.out.println("复制后的副本"+t2);
t1.setName("测试");
System.out.println("修改后的原型"+t1);
System.out.println("原型修改后的副本"+t2);
}
}
@Data
@Accessors(chain = true)
@ToString
class Teacher implements Cloneable{
private String name;
private int age;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
结果:

思考:如果对象中不含有其他对象,那浅拷贝与深拷贝的效果岂不是一样?
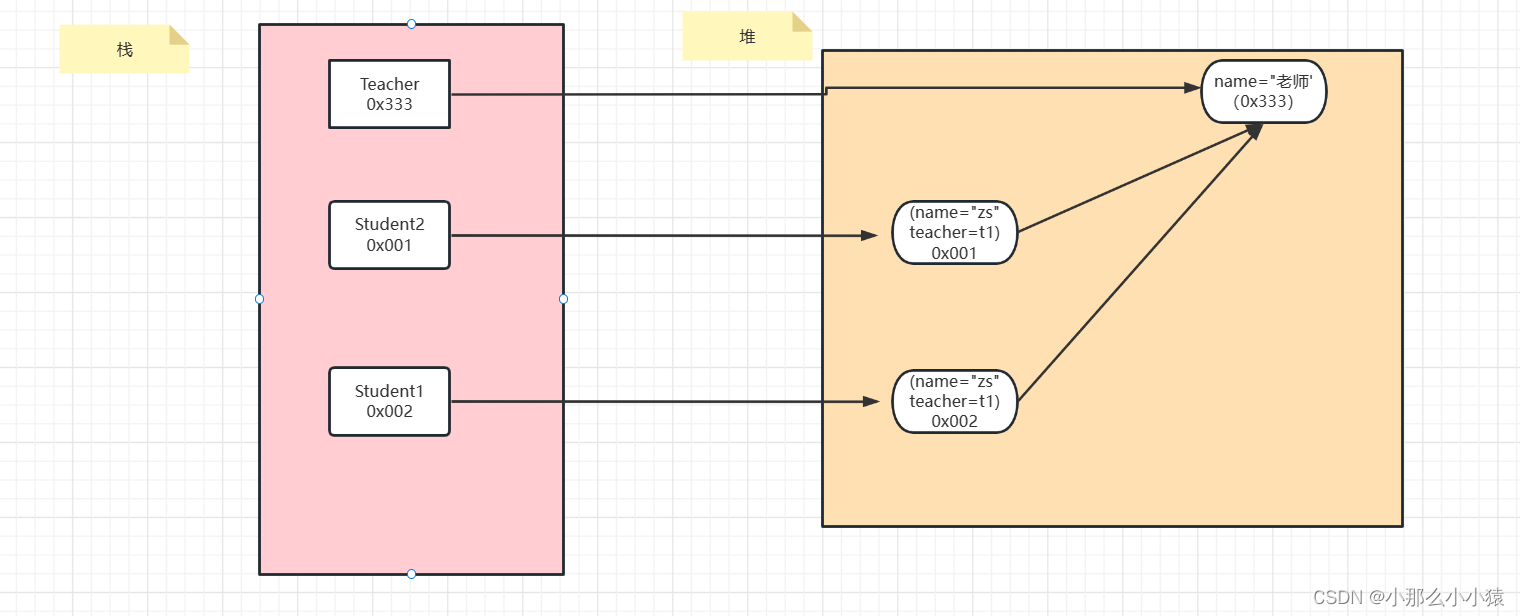
思考:其他类的对象作为此类的属性,那么其他类的对象发生修改,此类会不会发生修改?或者或,属性的值是使用的是原对象堆空间还是一个新堆空间?
是原对象的堆空间,对原对象发生改动,会影响到类中作为属性的对象
代码演示:

如图:浅拷贝对象中含有其他对象的情况
代码演示:
public class Application {
public static void main(String[] args) throws CloneNotSupportedException {
Teacher teacher = new Teacher().setName("老师1").setAge(100);
Student s1 = new Student().setName("学生1").setAge(20).setTeacher(teacher);
Student s2=s1.clone();
s1.getTeacher().setName("原型中属性对象发生修改");
System.out.println("复制后 原型修改为"+s1);
System.out.println("复制 并原型修改后 副本"+s2);
}
}
@Data
@Accessors(chain = true)
@ToString
class Teacher{
private String name;
private int age;
}
@Data
@Accessors(chain = true)
@ToString
class Student implements Cloneable{
private String name;
private int age;
private Teacher teacher;
@Override
protected Student clone() throws CloneNotSupportedException {
return (Student)super.clone();
}
}
结果:复制了原型后,对副本发生改动

- 思考:
如果对原型对象的name属性发生修改,副本的name属性会不会发生修改?或者说,clone()后的String类型数据,是深拷贝还是浅拷贝?
因为是浅拷贝,不是引用拷贝,对象中基本数据数据类型会被重新复制到一个独立的堆空间中,由于name是String类型,虽然不是基本数据类型,但String在方法区有常量池,由属性指向它的地址。那按照引用对象的常理说,原型与副本都是保存的name的地址空间,如果在原型中将name的值改变,由于指向同一块地址,副本的name值也应该改变。但String特别不同的是,如果将原型将name值修改,并不会将在原地址修改,而是又重新开辟一个地址存放修改的值,然后再重新指向这个新地址。这样,原型和副本的String类型指向的地址就会不相同,任何一方的String值修改都不会影响到另一方。 - 思考:
在这个例子中,如果我直接去修改Teacher对象的name,原型与副本中Teacher属性会不会发生改变?
由于原型和副本指向的是同一个Teacher对象地址,原型修改,Teacher对象自己修改,副本修改,任何一方修改值都会影响到其他两方。
深拷贝
递归拷贝,将这个对象中所有其他对象也拷贝一份在堆空间中独立存储。深拷贝相比于浅拷贝速度较慢并且花销较大。
如图:
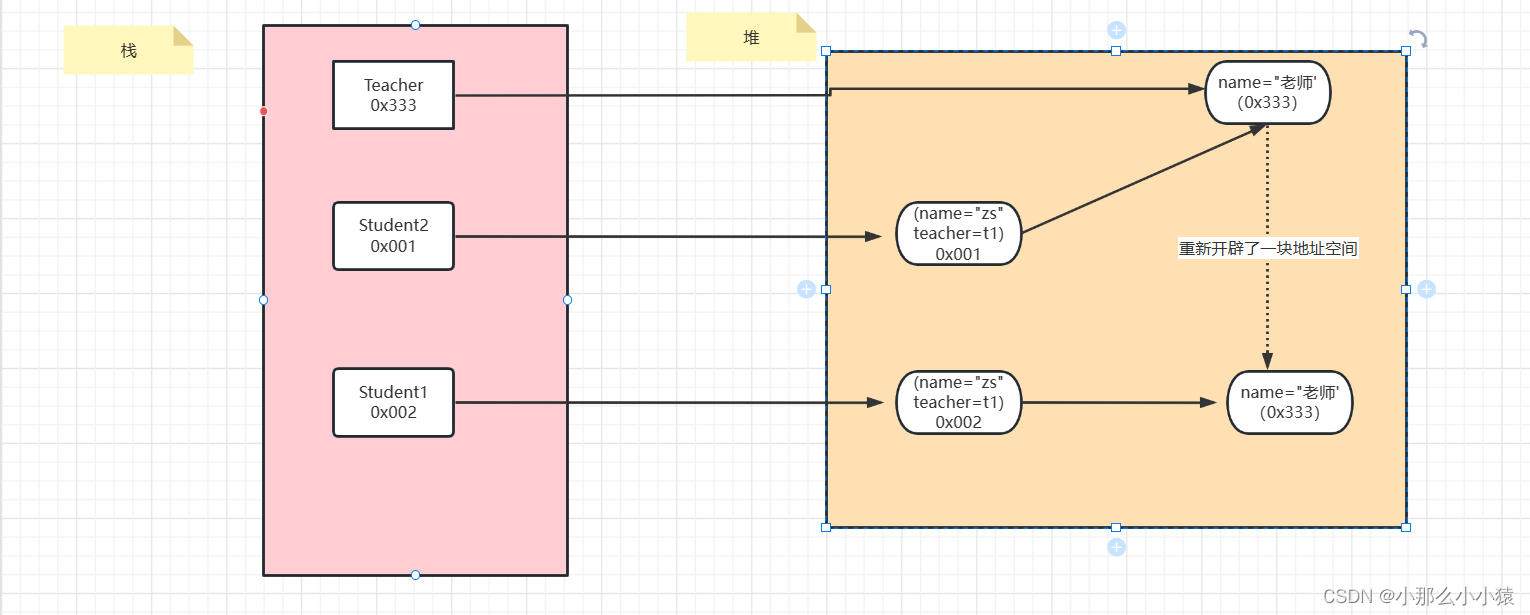
代码演示:深拷贝具体怎样拷贝,需要在clone()方法中定义,并不是一味的将所有引用对象都复制一份,也可以自己选择性的复制。
public class Application {
public static void main(String[] args) throws CloneNotSupportedException {
Teacher teacher = new Teacher().setName("老师1").setAge(100);
Student s1 = new Student().setName("学生1").setAge(20).setTeacher(teacher);
Student s2=s1.clone();
teacher.setName("测试");
System.out.println(s1);
System.out.println(s2);
}
}
@Data
@Accessors(chain = true)
@ToString
class Teacher implements Cloneable{
private String name;
private int age;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
@Data
@Accessors(chain = true)
@ToString
class Student implements Cloneable{
private String name;
private int age;
private Teacher teacher;
@Override
protected Student clone() throws CloneNotSupportedException {
Teacher teacher = (Teacher) this.teacher.clone(); //注意:这里指定了对Teacher属性的引用进行复制 ,要求teacher属性也要实现Cloneable接口
Student student = (Student) super.clone(); // 再重新将复制出的,设置给副本对象student
student.setTeacher(teacher);
return student;
}
}
结果:对Teacher修改没有影响到深拷贝的对象。

思考:如果这时这样互换会发生什么?为什么这样?
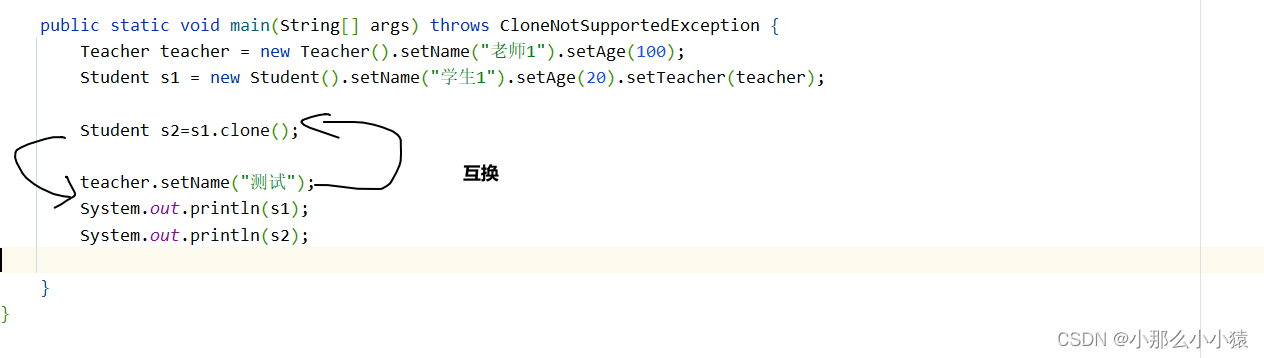
结果:
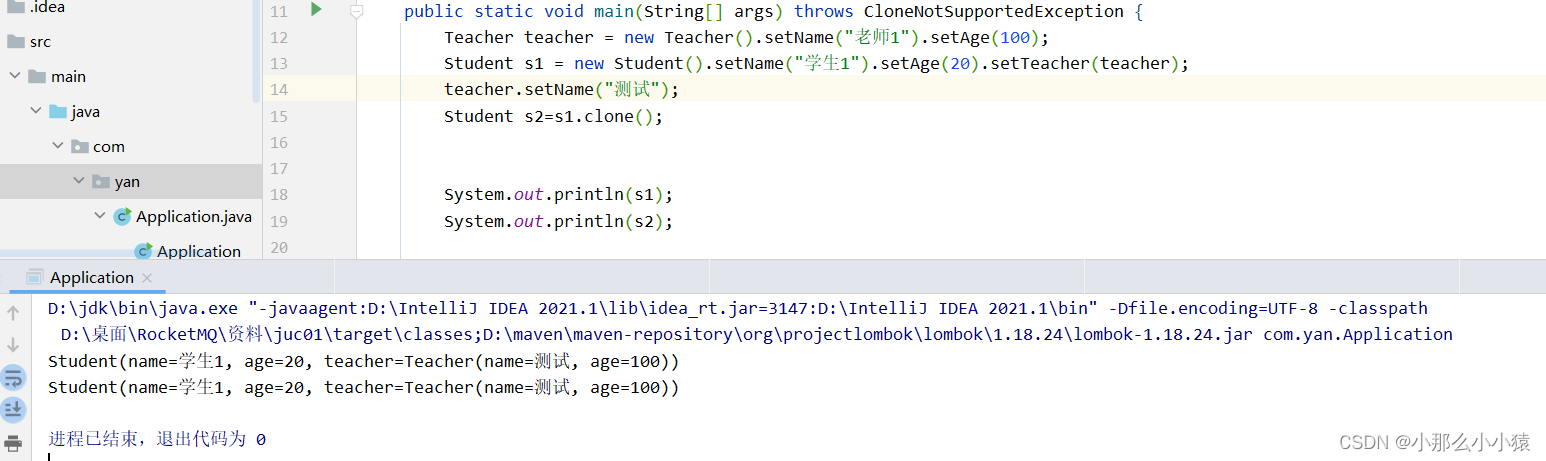
因为在拷贝原型作为副本时,是以原型当前状态作为拷贝的,在原型拷贝前其引用的对象name属性已经发生了改变,这时在进行拷贝,副本中拷贝来的也是改变后的数据
原型模式
原型模式第一件事想到的就是克隆,就在原来的基础上直接复制出和它一模一样的出来。假设这里有一份原型文件,从原型A复制出文件a,文件b,文件c。对这a,b,c三个文件任意的修改都不会影响到原型文件。
原型模式的好处有哪些呢?
如果原型对象是从数据库中查取出来的,那么如果再想去在获取这个相同的对象,就需要再次查询一次数据库。那如果有1次,100次呢?因此可以从原对象拷贝。至于是深拷贝还是浅拷贝要根据实际情况,上面已经介绍,这里不再赘述。
克隆出一个对象虽然也占据了堆内存的空间(相互不会干扰的原因),但相比于重新new再恢复至原型状态少了很多步骤,效率更高。
思考:为什么要从原型对象中拷贝,而不是直接拿原型来使用?这样不是更加节省资源吗 ?
如果全局中的对象不是进行拷贝获取的,而是从栈复制一份原对象在堆空间的地址。如果在一个地方,对原型对象发生了修改,全部的对象都将发生修改。
原型模式是创建模式的一种,它的核心就是在多处使用同一个对象时,为了防止对原对象的修改使得全局对象发生变化,将原型保护起来,按照原型克隆出一个个副本去使用。就像博物馆为了防止原物的损坏,通常会一比一做出多个模型去展示,这样既能通过模型知道到原型的样子,而且即使模型坏了也不会影响到原型和其他模型。那为什么不直接再造一个相同的原物呢?肯定是创建一个原物的难度要远远大于克隆一个原物啊。因此,原型模式有以下几个使用场景:
- 资源优化场景:
类的初始化相较于克隆一个对象要花费更多的资源。 - 安全问题:
创建一个新的对象需要更多的权限,或者说想要恢复至原对象数据有权限问题 - 一个对象被多个修改者修改
一个对象可能被多处使用,而在使用时可能会对对象发生修改,而如果多个对象间是引用指向的是堆空间中同一块地址,那么全局使用的此对象都将发生变化。如果不想发生变化,创建新对象再赋值由耗费资源。这时就可以使用原型模式
原型模式通常要配合工厂模式使用,原型模式生产出克隆对象,再由工厂模式交给使用者。
下面使用代码演示在原型类上进行修改产生的问题:
例如:我要从数据库中查询一条数据封装到一个pojo对象中,为了减少系统压力,只查询一次数据库,这个对象会被多个地方访问,修改。
public class Application {
public static void main(String[] args) throws CloneNotSupportedException {
MyMyBatis myMyBatis = new MyMyBatis();
User u1 = myMyBatis.getByDB("张三");
u1.setAge(0);
User u2 = myMyBatis.getByDB("张三");
System.out.println(u1 == u2);
System.out.println(u2);
}
}
class MyMyBatis {
HashMap<String,User>userHashMap=new HashMap<String, User>();
User getByDB(String name) {
// 模拟这里查询库,为了减少数据库的开销,同一个name只创建一个对象,然后放在map中,向外提供方法供到处使用
User user = userHashMap.get(name);
if(user==null){
User u1 = new User().setUsername(name).setAge(100);
user=u1;
userHashMap.put(name,user);
}
return user;
}
}
@Data
@ToString
@Accessors(chain = true)
class User {
private String username;
private int age;
}
结果:

有一个地方修改了此对象,另一个地方获取的还是此对象,一个对象到处共用,这就使得修改对象使得在另一个地方是可见的。
思考:为什么两次调用方法从userHashMap中获取的对象是同一个?
userHashMap中存放的是对象的地址,是在第一次new开启堆空间后将name作为key,值为对象地址存放在hashMap中,每次获取对象都是同一个对象即同一个堆地址。在一个地方对该地址的数据进行修改,这就使得其他地方通过该地址获取的数据是被更改后的。
使用单例模式对上面进行改装:
public class Application {
public static void main(String[] args) throws CloneNotSupportedException {
MyMyBatis myMyBatis = new MyMyBatis();
User u1 = myMyBatis.getByDB("张三");
u1.setAge(0);
User u2 = myMyBatis.getByDB("张三");
System.out.println(u1 == u2);
System.out.println(u2);
}
}
class MyMyBatis {
private HashMap<String,User> hashMap=new HashMap<>();
User getByDB(String name) throws CloneNotSupportedException {
User user=hashMap.get(name);
User user1=null;
if(user==null){
user = new User().setUsername(name).setAge(100);
hashMap.put(name,user);
hashMap.put(name,user);
}
user1= (User) user.clone();
return user1;
}
}
@Data
@ToString
@Accessors(chain = true)
class User implements Cloneable{
private String username;
private int age;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
结果:

将原型保护起来,克隆出多个对象向外提供, 一个克隆对象的修改不会影响到其他其他对象和原型。
思考:为什么克隆对象间不会相互影响?
因为每一个克隆对象与原型在堆内存中都是一个个独立的空间。