【数据库原理与SQL Server应用】Part05——表和表数据操作
- 一、表概念
- 1.1 表结构
- 1.2 表类型
- 1.3 数据类型
- 二、创建表
- 2.1 管理工具界面方式创建表
- 2.2 命令行方式创建表
- 三、修改表
- 3.1 管理工具界面方式修改表
- 3.2 命令行方式修改表
- 四、删除表
- 五、表数据操作
- 5.1 管理工具界面方式操作表数据
- 5.2 命令行方式操作表数据
一、表概念
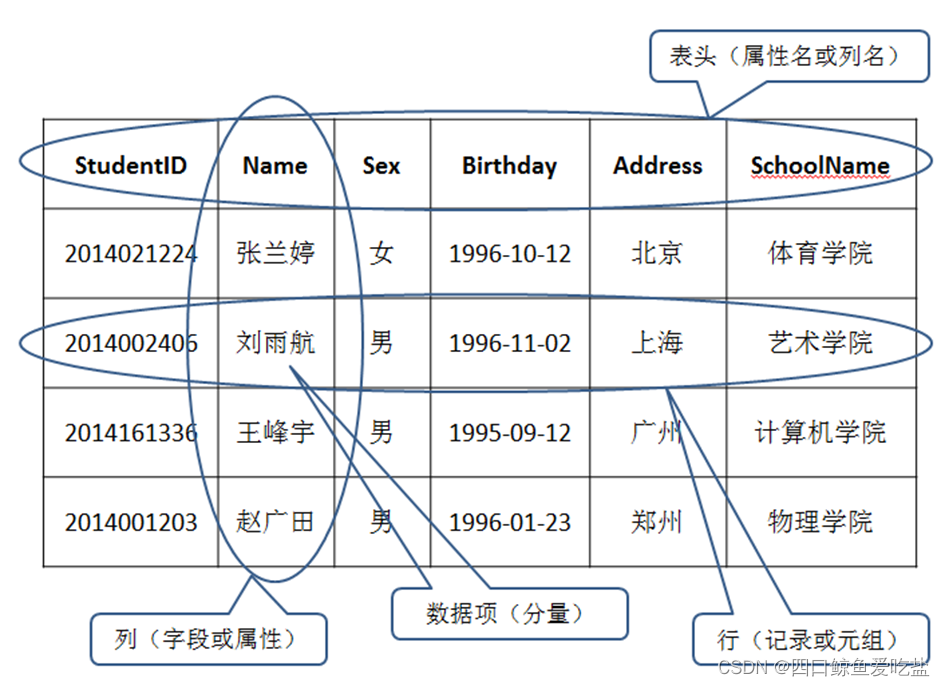
表是数据库存放数据的对象,表必须建在某一数据库中,不能单独存在,也不以操作系统文件形式存在。表中数据的组织形式如同Excel电子表格,由行、列和表头组成。每行表示一条记录(或元组),每列表示一个字段(或属性)。其中第一行是表的属性列部分,又称为表头。行和列的交叉称为数据项(或分量),其逻辑结构如图所示:
1.1 表结构
SQL Server的表,都必须有一个名字,以标识该表,称为表名。表名在某一个数据库实例中必须惟一。数据库中的表数仅受数据库中允许的对象数的限制。
行的顺序可以是任意的,每一行代表一条记录,是对某个实体的一个完整的描述,一般是按照插入的先后顺序存储的。表的行数仅受服务器的存储容量的限制。
列的顺序也可以是任意的。对每一个标准的表,用户最多可以定义1024列,任何列也都必须有一个名字,称为列名(或属性名)。在一个表中,列名必须惟一,而且必须指明数据类型。
1.2 表类型
在SQL Server中,除了由用户定义的基本表的标准角色以外,还提供了已分区表、临时表、系统表、宽表,这些表在数据库中起着特殊的作用。
1. 基本表
基本表就是由用户在数据库里创建的,用以存放数据的表,也称为用户定义的永久表。
如果不特殊说明,本书介绍的表都是用户定义的基本表。
本文着重说明基本表。
2. 已分区表
已分区表是将数据水平划分为多个单元的表,这些单元可以分布到数据库中的多个文件组中。在维护整个集合的完整性时,使用分区可以快速而有效地访问或管理数据子集,从而使大型表或索引更易于管理。
3. 临时表
临时表存储在tempdb系统数据库中。临时表有两种类型:本地表和全局表。它们在名称、可见性以及可用性上有区别。本地临时表的名称以单个数字符号(#)打头;它们仅对当前的用户连接是可见的;当用户从SQL Server实例断开连接时被删除。全局临时表的名称以两个数字符号(##)打头,创建后对任何用户都是可见的,当所有引用该表的用户从SQL Server实例断开连接时将被删除。
4. 系统表
SQL Server将定义服务器配置及其所有表的数据存储在一组特殊的表中,这组表称为系统表。用户不能直接查询或更新系统表。可以通过系统视图查看系统表中的信息。
任何用户都不应直接更改系统表。例如,不要尝试使用DELETE、UPDATE、INSERT语句或用户定义的触发器修改系统表。允许在系统表中引用所记录的列。然而,系统表中的许多列都未被记录。
5. 宽表
宽表使用稀疏咧,从而将表可以包含的总列数增大为30000列。稀疏列是对Null值采用优化的存储方式的普通列。稀疏列减少了Null值的空间需求,但代价是检索非Null值的开销增加。宽表已定义了一个列集,列集是一种非类型化的XML表示形式,它将表的所有稀疏列合并为一种结构化的输出。
1.3 数据类型
在SQL Server中,每个列、局部变量、表达式和参数都具有一个相关的数据类型。数据类型是一种属性,用于指定对象可保存的数据的类型。
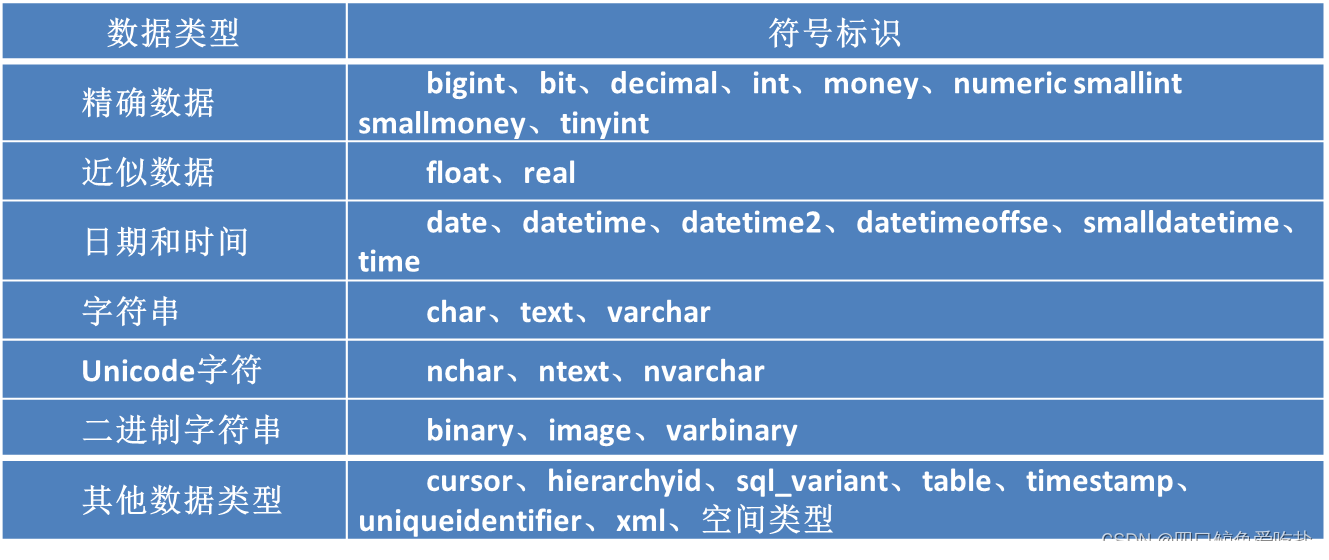
SQL Server提供了的数据类型分为系统数据类型和用户定义数据类型。本节只介绍系统数据类型。SQL Server提供了大量的系统数据类型。见如下表:
在介绍数据类型时,涉及到3个概念:精度、小数位数和存储长度。
精度是指数值数据中所存储的十进制数据的总范围。
小数位数是指数值数据中小数点右边可以有的数字位数的最大值。
长度是指存储数据所用的字节数。
1. 精确数据类型
精确数据类型用于存储精确的数据,又分为整数类型、定点数据类型、货币数据类型和位数据类型。
整数类型只表示精确的整数。见如下表:

定点类型也称为带固定精度和小数位数的数值数据类型,由整数部分和小数部分组成。包括decimal[ (p[ , s] )]类型和numeric[ (p[ , s] )]类型。使用最大精度时,有效值从-10^38+1到10^38-1。numeric在功能上等价于decimal。
p(精度)最多可以存储的十进制数字的总位数,包括小数点左边和右边的位数。该精度必须是从1到最大精度38之间的值。默认精度为18。s(小数位数)小数点右边可以存储的十进制数字的最大位数。小数位数必须是从0到p之间的值。仅在指定精度后才可以指定小数位数。默认的小数位数为0。因此,0<=s<=p。最大存储大小基于精度而变化。
货币数据类型是代表货币或货币值的数据类型,包括money和smallmoney数据类型,它们精确到所代表的货币单位的万分之一。见如下表:
位数据类型就是bit型,可以取值为1、0或NULL(空值)。SQL Server可优化bit列的存储。如果表中的列为8bit或更少,则这些列作为1个字节存储。如果列为9到16bit,则这些列作为2个字节存储,以此类推。字符串值TRUE和FALSE可以转换为bit值1和0。
2. 近似数据类型
近似数据类型也称为浮点数值数据类型,采用科学计数法存储十进制小数,用于表示浮点数值数据的大致数值数据类型。浮点数据为近似值。见如下表:

float [ ( n ) ]其中n为用于存储float数值尾数的位数(以科学记数法表示),因此可以确定精度和存储大小。如果指定了n,则它必须是介于1和53之间的某个值。n的默认值为53。1到24精度为7位,存储长度为4字节。25到53精度为15位,存储长度为8字节。
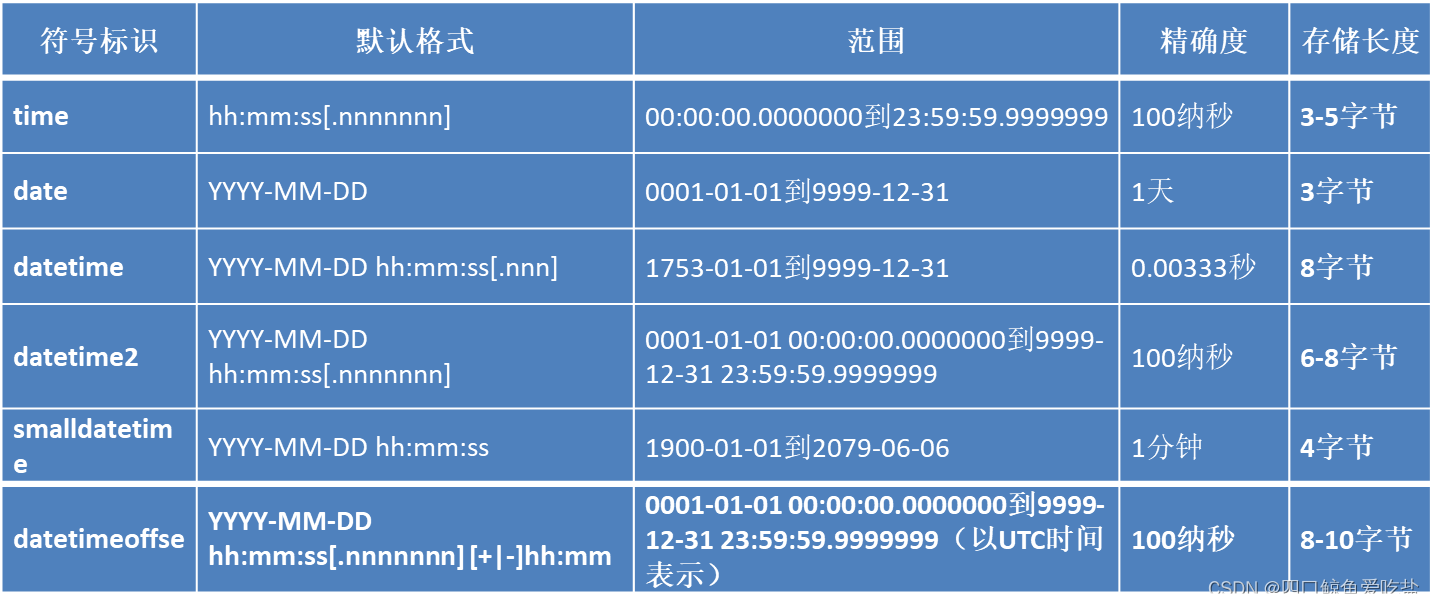
3. 日期和时间类型
日期和时间类型用于存储日期、时间或日期和时间的结合体数据。见如下表:
4. 字符串类型
字符串类型和Unicode字符串类型可以统称为字符类型。字符串类型用来存储各种非Unicode的字母、数字和符号组成的字符串。
char[ ( n ) ]类型固定长度,长度为n个字节。n的取值范围为1至8000,存储大小是n个字节。
varchar[ ( n | max ) ]类型可变长度,n的取值范围为1至8000,max指示最大存储大小是2^31-1个字节。存储大小是输入数据的实际长度加2个字节。所输入数据的长度可以为0个字符。
text类型存储服务器代码页中长度可变的非Unicode数据,最大长度为2^31-1(2,147,483,647)个字符。当服务器代码页使用双字节字符时,存储仍是2,147,483,647字节。根据字符串,存储大小可能小于2,147,483,647字节。
5. Unicode字符类型
Unicode字符类型用来存储各种Unicode的字母、数字和符号组成的字符。nchar[ ( n ) ]存储n个字符的固定长度的Unicode字符数据。n值必须在1到4,000之间(含)。存储大小为两倍n字节。nvarchar[ ( n | max ) ]存储可变长度Unicode字符数据。n值在1到4,000之间(含)。max指示最大存储大小为2^31-1字节。存储大小是所输入字符个数的两倍+2个字节。所输入数据的长度可以为0个字符。ntext类型存储长度可变的Unicode数据,最大长度为2^30-1(1,073,741,823)个字符。存储大小是所输入字符个数的两倍(以字节为单位)。
6. 二进制字符串类型
二进制数据类型表示的是位数据流,如较长的备注、日志信息等。包括固定长度或可变长度的binary数据类型,以及image类型。binary[ ( n ) ]是长度为n字节的固定长度二进制数据,其中n是从1到8,000的值。存储大小为n字节。varbinary[ ( n | max) ]是可变长度二进制数据。n可以是从1到8,000之间的值。max指示最大存储大小为2^31-1字节。存储大小为所输入数据的实际长度+2个字节。所输入数据的长度可以是0字节。image数据类型是长度可变的二进制数据,从0到2^31-1(2,147,483,647)个字节。image数据类型不只用来保存图像,也可以用户保存文档等。
7. 其他数据类型类型
其他数据类型使用频率不高。例如cursor是变量或存储过程的OUTPUT参数的一种数据类型,这些参数包含对游标的引用。sql_variant用于存储除text、ntext、timage、timestamp和sql_variant外的其他任何合法的数据。
8. xml数据类型
XML(可扩展标记语言),是标准通用标记语言的子集,是一种用于标记电子文件使其具有结构性的标记语言。它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。它非常适合Internet传输,提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。
二、创建表
创建表的实质就是定义表结构。在SQL Server中提供了两种创建表的方式,一种是管理工具界面方式创建,另一种是命令行方式创建。
本章将以COLLEGE数据库和PUBLISH数据库中表的操作为例,介绍表的基本操作,包括创建、修改、删除表,以及对表数据操作等。
首先创建两个数据库,COLLEGE数据库和PUBLISH数据库。
2.1 管理工具界面方式创建表
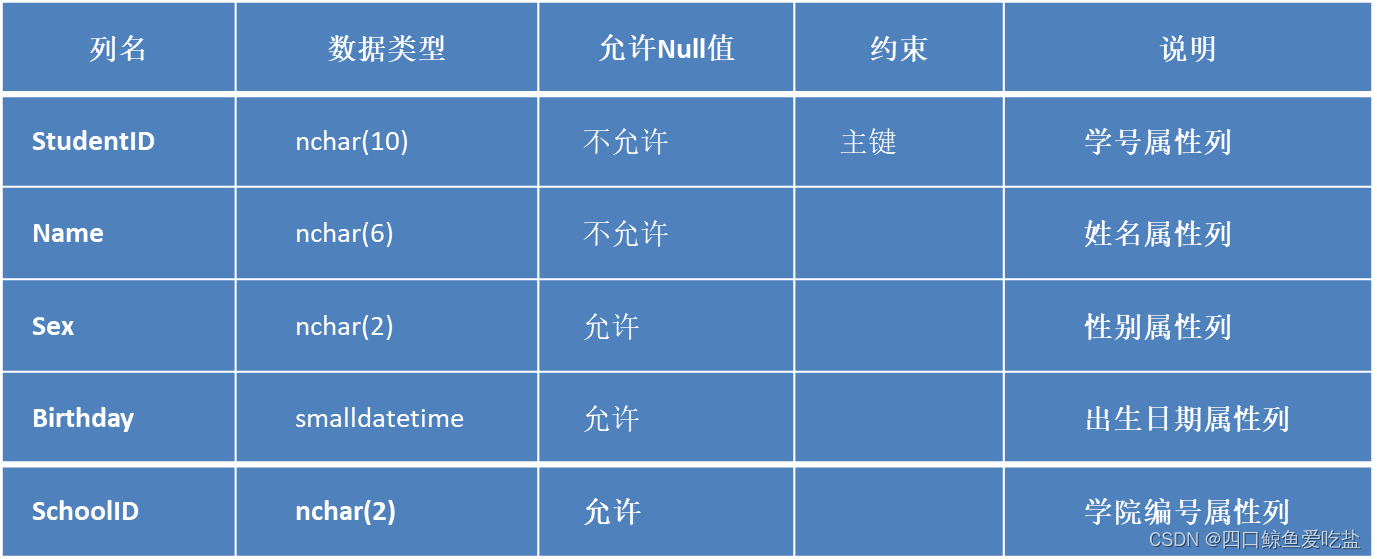
COLLEGE数据库有4个表,分别是Student表、School表、Course表、Mark表。
Student表结构基本说明见下(其余表结构省略):
Student表:
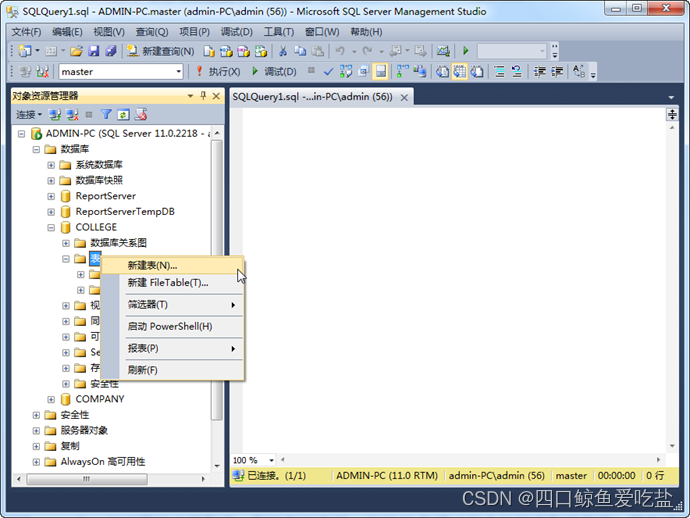
在对象资源管理器中,展开数据库COLLEGE,进一步展开表对象,新建的数据库表对象中,初始时已经有系统表和FileTables两个对象。与SQL Server以前版本不同的是,系统表中是空的,没有一系列系统表存在。选择表对象,选择右键菜单新建表选项,如图所示:
之后,进入表结构设计器窗口,如图所示:
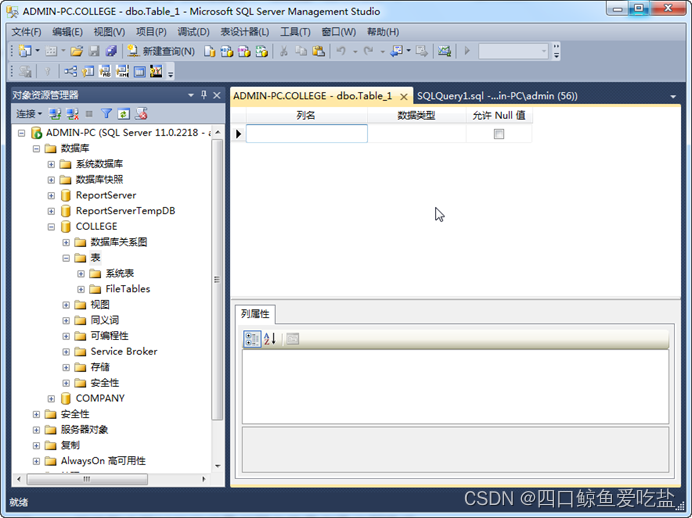
表设计器主体分为上下两部分:列常规和列属性子窗口。初始时都为空。在列常规子窗口中,用户可以设置 列名、列的数据类型、允许Null值(是否允许该列取空值) 等常规属性。列属性子窗口可以设置列的其他更为复杂的操作。
首先新建Student表。按照前文中表的提示,在列常规子窗口中输入列名,设置列的数据类型,允许Null值等常规属性 ,如下图所示:
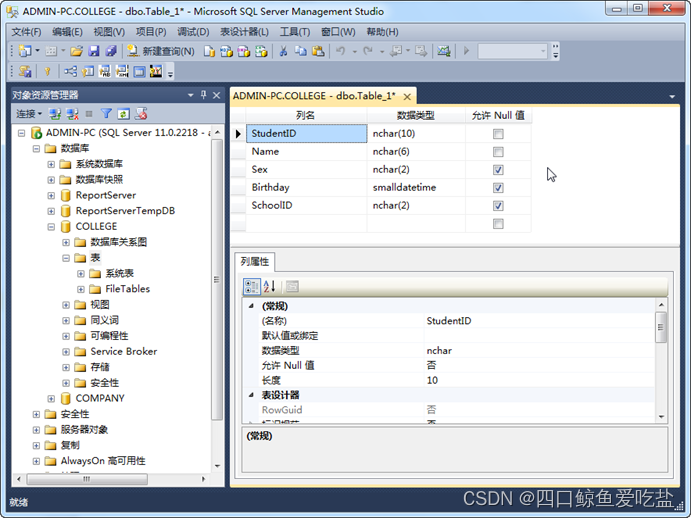
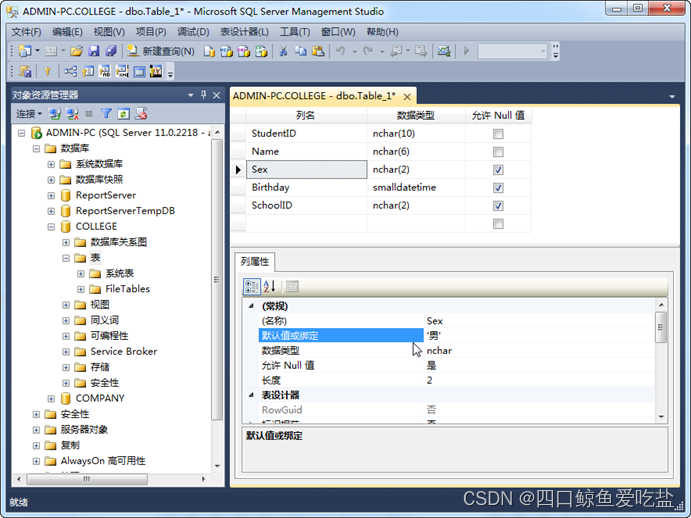
通常,每个表都必须设置主键。选择要设置为主键的StudentID列,选择右键菜单设置主键选项。如图所示:
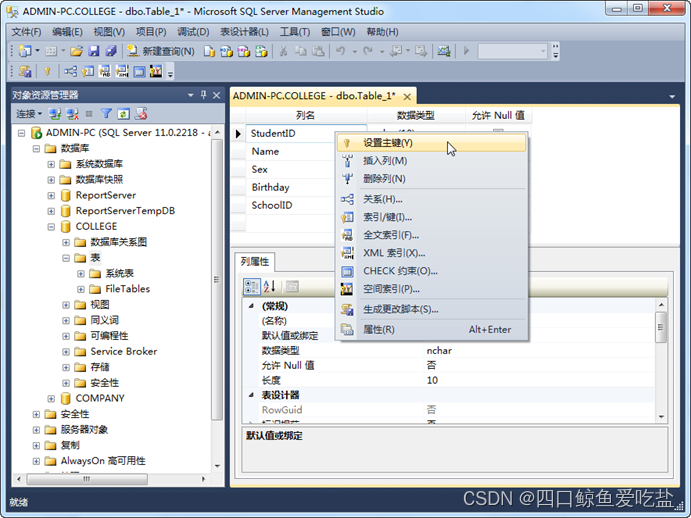
设置成功,该列左边出现标识一个钥匙图标,表示该列为主键。如图所示:
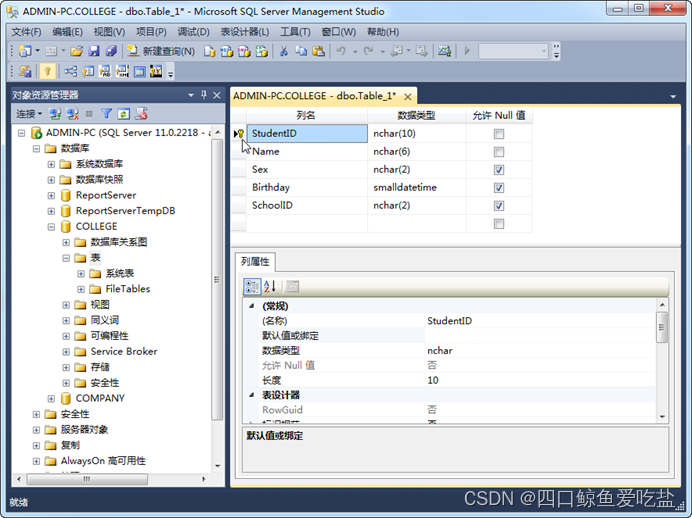
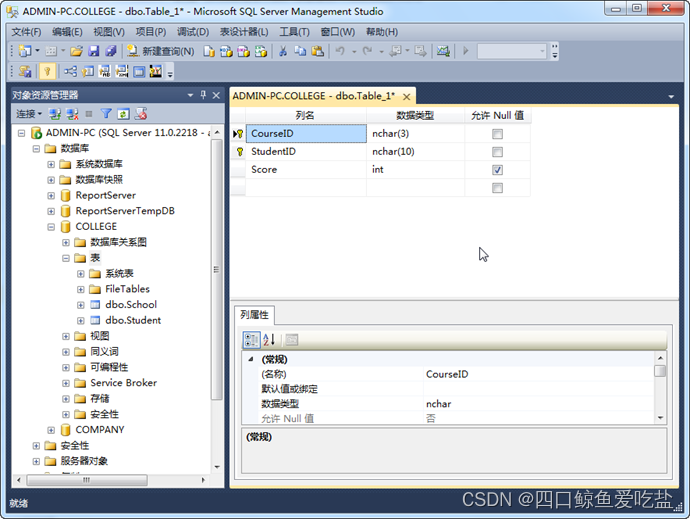
虽然一个表只能有一个主键,但主键可以是多个列的组合。这时需要键盘的Ctrl键和Shift键与鼠标组合使用。Ctrl键与鼠标组合使用是断续选择,Shift键与鼠标组合使用是连续选择。例如Mark表的主键就是CourseID与StudentID的组合。就需要Ctrl键或Shift键与鼠标组合使用设置。如图所示:
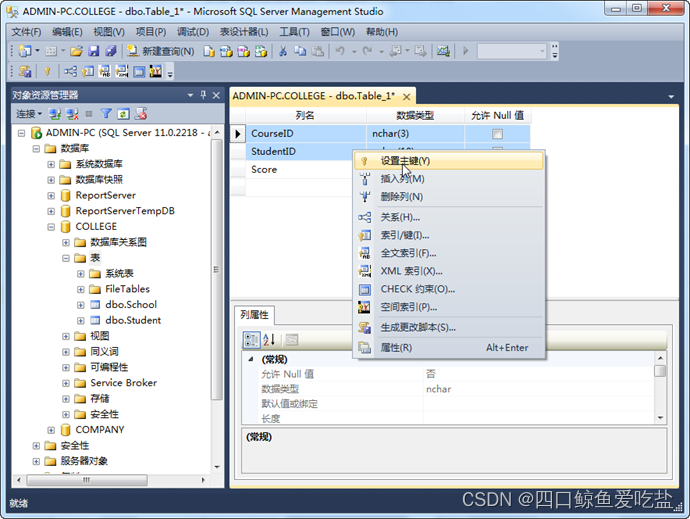
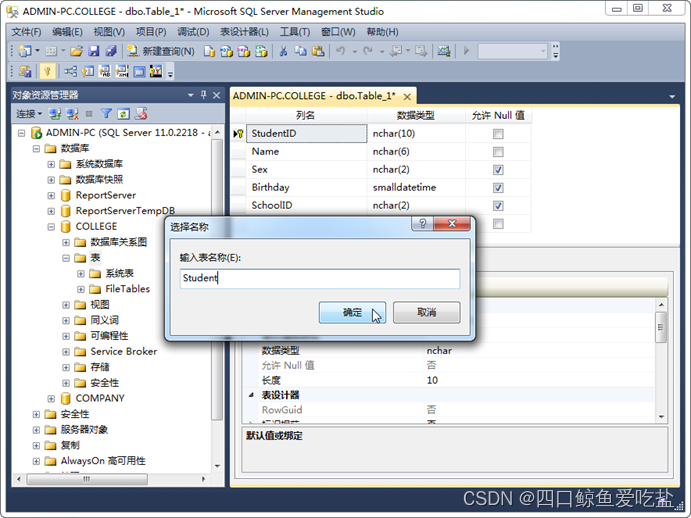
一切设置完毕,选择表设计器右上角的关闭按钮,或选择系统菜单文件的保存选项,或单击工具栏上的保存按钮,出现一个选择名称对话框,输入表名Student,选择确定按钮即可保存新建的表。如图所示:
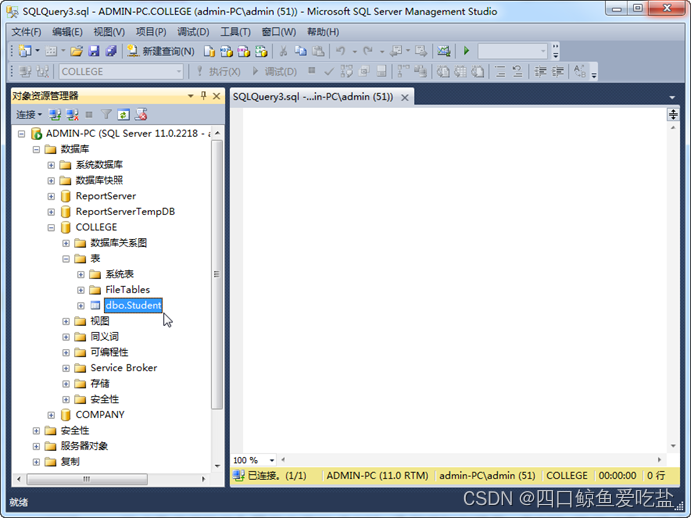
刷新表对象,可以看到新建一个名为dbo.Student的表,dbo是表的所有者,即当前数据库所有者,用户操作时可以省略。如图所示:
2.2 命令行方式创建表
在SQL Server中,还可以利用命令行方式创建表。在SQL Server Management Studio的查询编辑器窗口中使用T-SQL语句编程创建表。T-SQL提供了表创建语句CREATE TABLE。其语法格式如下:
CREATE TABLE [ database_name . [ schema_name ] . | schema_name . ] table_name
( { <column_definition> | <computed_column_definition>
| <column_set_definition> }
[ <table_constraint> ] [ ,...n ] )
[ ON { partition_scheme_name ( partition_column_name ) | filegroup
| "default" } ]
[ { TEXTIMAGE_ON { filegroup | "default" } ]
[ FILESTREAM_ON { partition_scheme_name | filegroup
| "default" } ]
[ WITH ( <table_option> [ ,...n ] ) ]
[ ; ]
CREATE TABLE语句语法说明:
table_name是所创建的表名。表名在一个数据库中必须惟一,并且符合标识符的规则。表名可以是一个部分限定名,也可以是一个完全限定名。<column_definition>对列属性定义,包括列名、列数据类型、默认值、标识规范、允许空等。<column_definition>格式为:
column_name <data_type>
[ FILESTREAM ]
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
[
[ CONSTRAINT constraint_name ] DEFAULT constant_expression ]
| [ IDENTITY [ ( seed ,increment ) ] [ NOT FOR REPLICATION ]
]
[ ROWGUIDCOL ] [ <column_constraint> [ ...n ] ]
[ SPARSE ]
NULL表示允许为空,NOT NULL表示不允许为空,DEFAULT表示默认值。
其中<column_constraint>(约束)格式为:
<column_constraint> ::=
[ CONSTRAINT constraint_name ]
{ { PRIMARY KEY | UNIQUE }
[ CLUSTERED | NONCLUSTERED ]
[
WITH FILLFACTOR = fillfactor
| WITH ( < index_option > [ , ...n ] )
]
[ ON { partition_scheme_name ( partition_column_name )
| filegroup | "default" } ]
| [ FOREIGN KEY ]
REFERENCES [ schema_name . ] referenced_table_name [ ( ref_column ) ]
[ ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT } ]
[ ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT } ]
[ NOT FOR REPLICATION ]
| CHECK [ NOT FOR REPLICATION ] ( logical_expression )
}
PRIMARY KEY表示主关键字约束。UNIQUE表示惟一性约束。CLUSTERED表示聚集索引。NONCLUSTERED表示非聚集索引。CHECK表示检查约束。DEFAULT表示默认值约束。FOREIGN KEY表示外部键约束。
例:使用CREATE TABLE语句创建Author表。
在对象资源管理器中,选择数据库PUBLISH,选择右键菜单新建查询选项,新建一个查询编辑器窗口。输入以下T-SQL语句:
USE PUBLISH
GO
CREATE TABLE Author
(
/* 作者号属性列,不允许为空,设置为主键 */
AuthorID NCHAR(5) NOT NULL PRIMARY KEY,
Name NCHAR(6) NOT NULL, /* 姓名属性列,不允许为空*/
Sex NCHAR(2) NULL DEFAULT '男', /* 性别属性列,默认值“男”*/
Birthday SMALLDATETIME NULL, /* 出生日期属性列,允许为空*/
Provinces NCHAR(10) NULL /* 所属省属性列,允许为空*/
)
GO
选择执行按钮,表创建成功。如图所示:
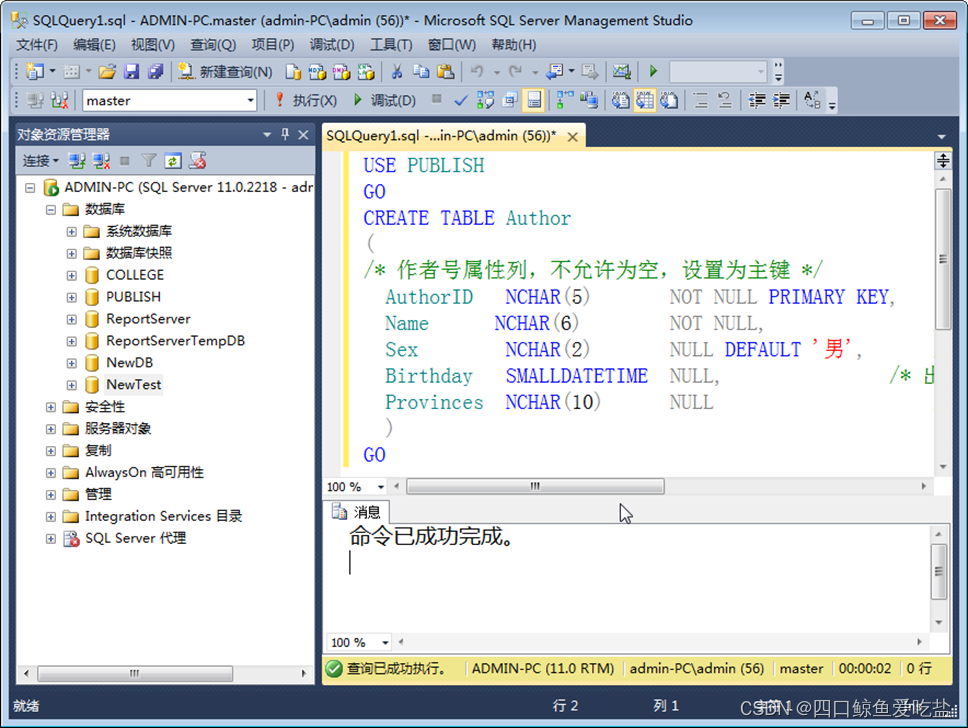
刷新
表对象后,可以看到新添一个名为dbo.Author的表。dbo是系统自动加上的,标识表的所有者。
注意,在哪个数据库中操作表(包括创建、修改、删除、查询等),原则上就应该在哪个数据库下新建
查询编辑器窗口,用以指明可用数据库,即当前数据库。否则有可能对其它数据库中的表操作。为避免出现误操作,建议在操作表语句前添加以下语句:
USE database_name
USE语句的功能是将数据库上下文更改为指定数据库(或数据库快照)。
也可以在SQL Server Management Studio中指定数据库。选择工具栏上的可用数据库下拉列表框,选择当前数据库。如图所示:
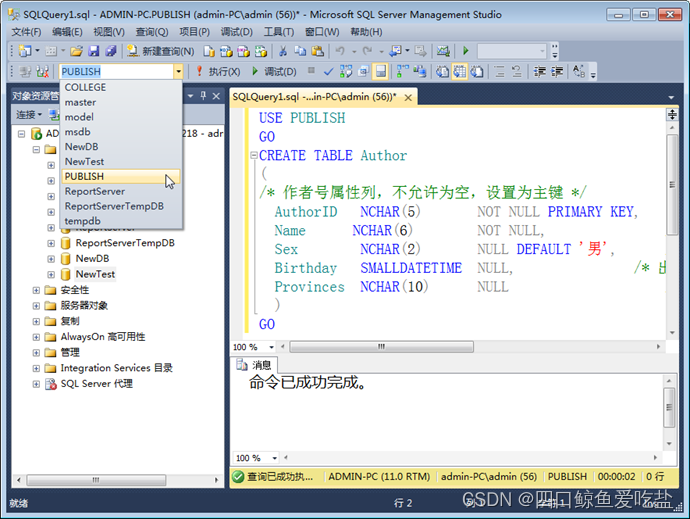
例:使用CREATE TABLE语句创建Book表。
USE PUBLISH
GO
CREATE TABLE Book
(
BookID NCHAR(5) NOT NULL PRIMARY KEY,
BookName NCHAR(20) NOT NULL,
AuthorID NCHAR(5) NULL,
Price INT,
TypeID NCHAR(3) NULL
)
GO
执行结果,创建Book表。
例:使用CREATE TABLE语句创建Type表。
USE PUBLISH
GO
CREATE TABLE Type
(
TypeID NCHAR (3) NOT NULL PRIMARY KEY,
TypeName NCHAR (10) NULL
)
GO
执行结果,创建Type表。
创建架构(所有者):
CREATE SCHEMA schema_name_clauseUse PUBLISH go CREATE SCHEMA wang
三、修改表
修改表包括修改表结构,修改表属性,重命名表名等操作。通常,修改表只是修改表结构。在SQL Server中提供了两种修改表的方式,一种是管理工具界面方式修改,另一种是命令行方式修改。
3.1 管理工具界面方式修改表
在对象资源管理器中,右键单击要修改的表名,选择设计选项,进入表结构设计器窗口,如同创建新表一样,修改表结构,修改后保存退出即可。或者选择重命名选项,重新命名表名。或者选择属性选项,修改权限等。如图所示:
3.2 命令行方式修改表
在SQL Server中,还可以利用命令行方式修改表。T-SQL提供了表修改语句ALTER TABLE。其语法格式如下:
ALTER TABLE [ database_name . [ schema_name ] . | schema_name . ]table_name
{
ALTER COLUMN column_name
{
[ type_schema_name. ] type_name [ ( { precision [ , scale ]
| max | xml_schema_collection } ) ]
[ COLLATE collation_name ]
[ NULL | NOT NULL ] [ SPARSE ]
| {ADD | DROP }
{ ROWGUIDCOL | PERSISTED | NOT FOR REPLICATION | SPARSE }
}
| [ WITH { CHECK | NOCHECK } ]
| ADD
{
<column_definition>
| <computed_column_definition>
| <table_constraint>
| <column_set_definition>
} [ ,...n ]
| DROP
{ [ CONSTRAINT ] constraint_name
[ WITH ( <drop_clustered_constraint_option> [ ,...n ] ) ]
| COLUMN column_name
} [ ,...n ]
}
ALTER DATABASE语句语法说明:
table_name是所修改的表名。ALTER COLUMN子句是修改列。ADD子句是新增列。DROP子句是删除列。
例:使用ALTER TABLE语句修改COLLEGE数据库的Course表,新增名为CourseRemarks,数据类型为NTEXT(备注型)的新列。
USE COLLEGE
GO
ALTER TABLE Course
ADD CourseRemarks NTEXT
GO
执行结果,新增一列。
例:使用ALTER TABLE语句修改PUBLISH数据库的Book表,将Price列的数据类型改为decimal。
USE PUBLISH
GO
ALTER TABLE Book
ALTER COLUMN Price DECIMAL(8,1)
GO
执行结果,列的属性修改成功。
四、删除表
如果表不需要了,可以删除。删除表,将删除表结构和表中所有数据,而且不能恢复。如果没有备份,数据将丢失。所以删除表一定要小心。
在SQL Server中提供了两种删除表的方式,一种是管理工具界面方式修改,另一种是命令行方式修改。
在对象资源管理器中,右键单击要删除的表名,选择删除选项,进入“删除对象”对话框,确定删除即可。或者选择系统菜单编辑的删除选项删除表。如图所示:
进入删除对象对话框,删除表,如图所示:
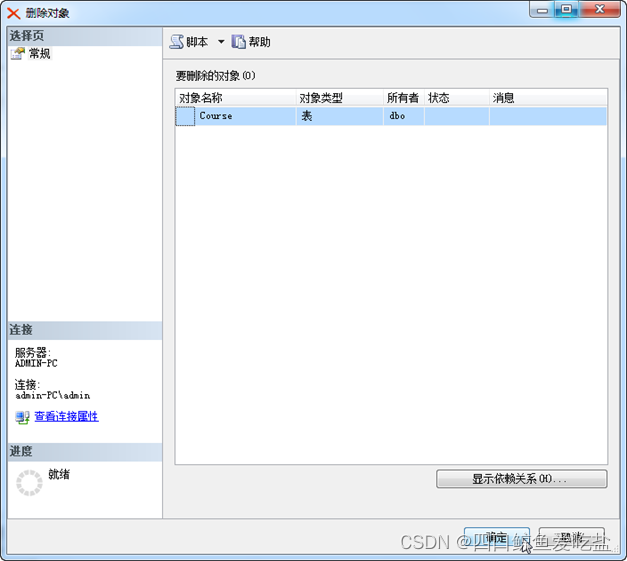
T-SQL提供了表删除语句DROP TABLE。其语法格式如下:
DROP TABLE [ database_name . [ schema_name ] . | schema_name . ]
table_name [ ,...n ] [ ; ]
例:使用DROP TABLE语句删除PUBLISH数据库的Book表。
USE PUBLISH
GO
DROP TABLE Book
GO
执行结果,删除指定表。
五、表数据操作
表创建、修改完毕,它只是一个空表,即只有表结构,没有表数据。用户创建表的目的是让表存储所需数据,因此随后的工作就是向表中新增、修改或删除数据。
在SQL Server中提供了两种表数据的操作方式,一种是管理工具界面方式操作,另一种是命令行方式操作。
5.1 管理工具界面方式操作表数据
右键单击要操作的表名,选择编辑前200行选项,如图所示:
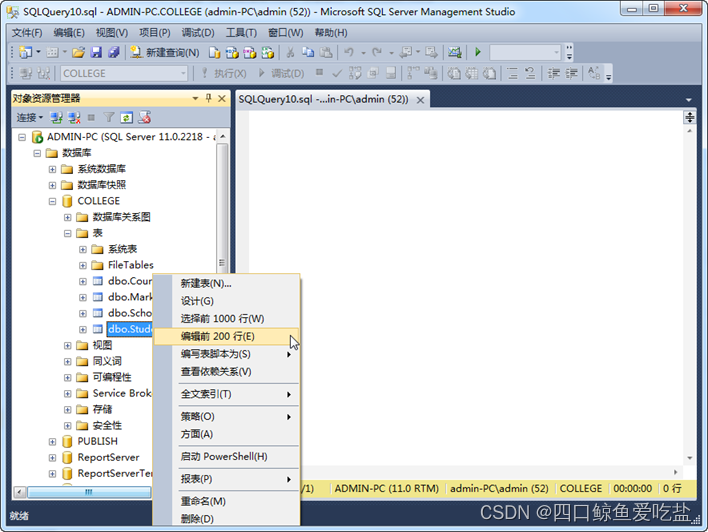
打开表数据编辑窗口,默认表数据为空。如图所示:
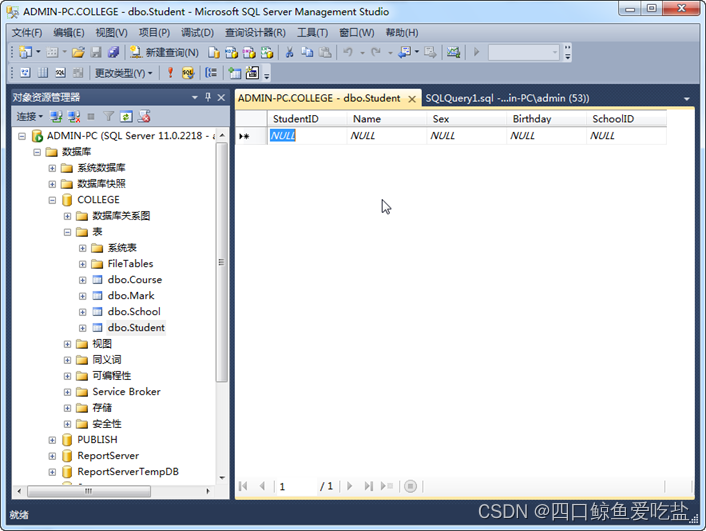
用户可以直接在显示NULL处输入数据,新增数据。同时也可以将光标移到需要修改的数据上进行修改。如图所示:
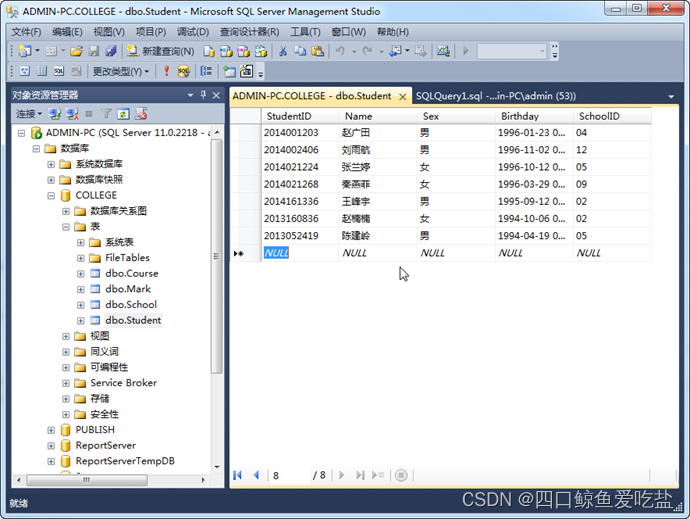
或者选择系统菜单编辑的剪切、复制、粘贴、删除选项来操作表数据。如图所示:
如果选中的是一个数据项,那么修改、删除等操作只针对这个数据项操作。如果选中的是一行(记录),那么操作的是一整行数据。系统菜单选项和右键快捷菜单选项都可以操作。如图所示:
如果选择的是编辑前1000行选项,出现一个查询窗口,显示了相应操作的T-SQL语句,以及该语句的查询结果,而用户无法直接添加、修改和删除表数据,如图所示:
5.2 命令行方式操作表数据
在查询编辑器窗口主窗体输入T-SQL语句,也可以对表数据操作。
T-SQL提供了INSERT语句、UPDATE语句、DELETE语句对表数据进行插入、修改和删除操作。
1. INSERT语句
INSERT语句语法格式如下:
INSERT [INTO] table_name [(column_list)] VALUES (data_values,…n)
说明:
- 使用
INSERT语句可以向表中插入新记录,但一次只能插入一条记录。 table_name后面的属性列列表可以省略。如果省略,则VALUES后面的data_values数量要和表的列的数量一致,并且每个data_values要和表的列顺序一致,数据类型也要匹配。table_name后面的属性列如果标明,可以标明部分或全部列。这时data_values要和table_name后面的属性列数量一致,并且每个data_values要和列顺序一致,数据类型也要匹配。
例:使用INSERT语句给COLLEGE数据库的Student表插入一行记录。
USE COLLEGE
GO
INSERT Student(StudentID,Name,Sex,Birthday,SchoolID)
VALUES('2014110205','张雄伟','男','1995-1-10','2')
GO
INSERT Student(StudentID,Sex,Name)
VALUES('2013010110','女','刘新丽')
GO
执行结果,新增两行记录。这里需要说明的是,在插入数据时,INSERT语句一次只能插入一条记录。表名后可以标明全部列名,列名顺序无所谓,但VALUES后面赋值顺序必须与列名顺序一致,否则将会引起数据赋值的混乱。如果类型不匹配或出现其它情况,系统甚至提示错误。在不违反表结构设置(例如列是否允许为空)的前提下,表名后也可以只标明部分列名,那么VALUES只能给部分列赋值。
例:使用INSERT语句给COLLEGE数据库的Course表插入一行记录。
USE COLLEGE
GO
INSERT Course
VALUES('115','数据库原理',3,'必修课')
GO
执行结果,新增一行记录。在插入数据时,表名后省略了列名,所以VALUES后面赋值时,数值个数必须与表的列个数一致,并且顺序也得一致。
2. UPDATE语句
T-SQL提供了表记录修改语句UPDATE语句。其语法格式如下:
UPDATE table_name
SET column_name={expression | DEFAULT | NULL } [,…n]
[WHERE <search_condition>]
说明:
- 使用
UPDATE语句可以修改表数据。具体修改哪个列数据由SET子句设定。 WHERE子句设定修改哪一行或哪些行。
例:使用UPDATE语句修改Student表的记录。
USE COLLEGE
GO
UPDATE Student
SET SchoolID='3'
WHERE Name='张雄伟'
GO
执行结果,修改指定记录。修改后将姓名为张雄伟的学院编号改为3,其他数据不变。
例:使用UPDATE语句修改Course表的记录。
USE COLLEGE
GO
UPDATE Course
SET Credit= Credit +1
WHERE CourseName='数据库原理'
GO
执行结果,修改指定记录。修改后,将选修了课程名为“数据库原理”的学分数加1分。如果没有WHERE子句,所有记录(不论是哪门课程)的学分都加1分。
3. DELETE语句
如果只删除表数据,T-SQL提供了表数据删除语句DELETE语句。其语法格式如下:
DELETE FROM table_name
[WHERE <search_condition>]
说明:
WHERE子句设定修改哪一行或哪些行。- 如果没有使用
WHERE子句,将删除所有数据。
例:使用DELETE语句删除Course表的一行记录。
USE COLLEGE
GO
DELETE Course
WHERE CourseName='软件工程'
GO
执行结果,删除Course表中CourseName名为软件工程的记录。
例:使用DELETE语句删除School的所有记录。
USE COLLEGE
GO
DELETE School
GO
执行结果,删除School表中所有记录行,即清空该表,此操作慎用。
用户也可以在表数据编辑窗口中使用T-SQL语句。选择表中数据,选择右键菜单窗格选项的SQL子选项。如图所示:
在表数据编辑窗口上方打开一个查询窗口,用户可以在查询窗口中使用T-SQL语句操作表数据,同时也可以直接在表数据中操作。如图所示: