近期,一个名为 ChatTTS 的文本转语音项目爆火出圈,在 GitHub 上已经斩获了 28 k 的 Star 量。 作为一款专门为对话场景设计的语音生成模型,ChatTTS 支持英文和中文两种语言。针对对话式任务进行了优化,实现了自然流畅的语音合成。
图片来源 https://chattts.com/
01 ChatTTS 亮点
-
对话式 TTS:ChatTTS 针对对话式任务进行优化,实现了自然流畅的语音合成,同时支持多说话人。
-
细粒度控制:该模型能够预测和控制细粒度的韵律特征,包括笑声、停顿和插入词等。
-
更好的韵律:ChatTTS 在韵律方面的能力超越了大部分开源语音合成模型,它能在说话时加入笑声或改变语调,让聊天更加自然。
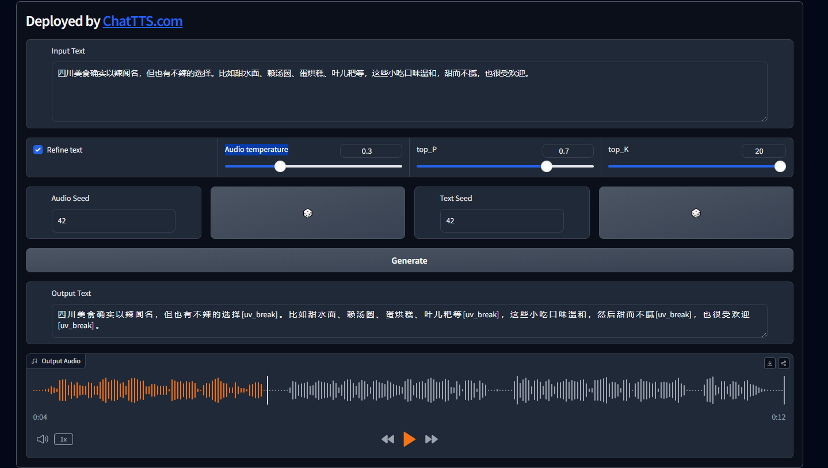
02 如何让 ChatTTS 更进一步
可以说 ChatTTS 目前的效果已经十分优秀,开发者可以在此基础上通过 SFT(Supervised Fine-Tuning, 有监督微调)来进一步实现性能的提升。
SFT 是一种在预训练大模型的基础上,使用有标签数据对模型进行进一步优化的技术。这种方法利用了预训练模型在大规模无监督数据上的学习能力,并通过有标签数据对其进行调整,使其更适应特定任务的需求。
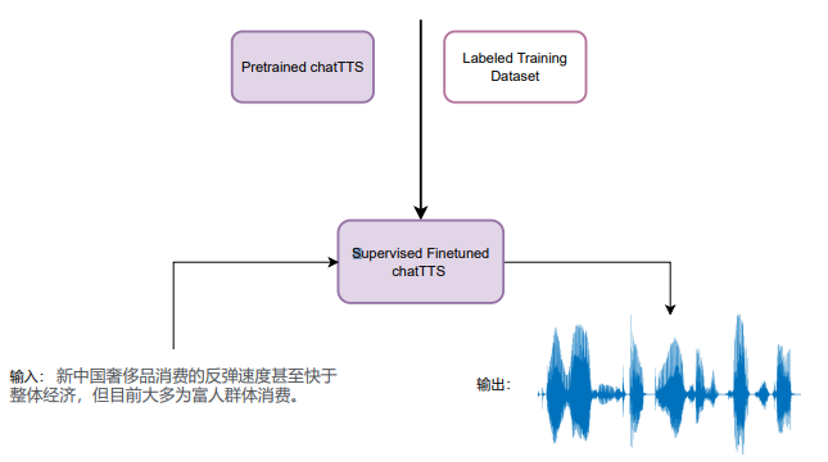
- 通过使用包含特定说话人音色的标注数据进行微调,使模型能够生成指定音色的语音。
- 可以通过优化模型结构和使用高效算法进行微调来提高推理速度,从而适用于实时场景。
- 通过使用包含丰富标点符号和特殊字符的语料进行微调,进一步提升标点和特殊字符的适配。此外,可以使用严格标注的对话数据进行微调,避免丢词或多词现象,提高模型生成内容的稳定性。
- 使用一致性较好的音频数据集进行微调,增强模型在生成不同文本时保持音色一致的能力。
通过以上这些 SFT 和高质量数据措施,将能够进一步提升 ChatTTS 的整体性能和用户体验。
03 海天瑞声千人多语种语音合成数据
在语音合成技术中,数据的质量至关重要。特别是在 SFT 过程中,精标语音合成数据是决定模型性能和质量的关键因素之一,高质量的数据才能更好的提升语音合成系统的表现。
海天瑞声拥有 超40个国家/地区的多语种高质量精标语音合成数据集,包括阿拉伯语、德语、法语、俄语、日语、韩语、葡萄牙语、西班牙语、意大利语、荷兰语、芬兰语、丹麦语、瑞典语、挪威语、捷克语、波兰语、越南语、蒙古语等。包含1300位说话人,时长1343小时,男女比例均衡。覆盖话题广泛,包括日常口语、新闻、工作、社交、音乐、家庭、健康、旅游、天气等。此外,还支持多音色、多风格、多情感,让模型能够覆盖多样化的内容表达和使用场景,更加贴近真人的自然表达。

高标准采集环境 确保顶级音质
为了提供更高质量的语音数据,海天瑞声语音采集的过程遵循严格标准,以确保录音质量。通过高标准的设备配置和录音环境,确保语音合成数据的高质量,为创建自然流畅、高保真的语音合成系统提供了坚实的基础。
采集设备:专业录音棚符合NC20 噪声标准等级,确保环境极端静谧;配备 工业级专业录音设备,如 Neumann TLM103/U87/M149、AKGC4000/C4000b/C414等卓越音质和录音性能的设备。
采集环境:
· 环境底噪BN < -60db 环境噪声极低,保证录音质量
· 信噪比SNR > 35db 确保声音清晰度和纯净度
· 混响时间RT60 < 0.2sec 具有良好声学特性的录音棚,避免不必要的回声和混响
超高准确率标注 打造高质量数据
海天瑞声语音合成数据包含高精度标注的语音数据和对应的文本数据,还详细标注了发音细节。此外,海天瑞声通过领先的DOTS平台对数据进行预处理并配合专家人工校验,进一步提高语音合成数据的准确度。
· 语音校对准确率 99%,以单个字(单词)为单位
· 发音标注准确率 99.5%,以单个音素为单位
· 韵律标注准确率 98%,以单个符号为单位
· 音素边界标注准确率 99%,边界误差不超过10 ms
通过使用高质量精标数据进行微调,语音合成模型能够生成更加自然、流畅和富有情感的语音,给用户带来更多感动与惊喜。
海天瑞声致力于推动AI技术的全球化应用,希望携手更多出海企业,满足全球不同国家用户的个性化需求,实现更广泛的用户覆盖和市场增长。
















![[玄机]流量特征分析-蚁剑流量分析](https://i-blog.csdnimg.cn/direct/0f13ff0745e04a2680c4a0f505899a93.jpeg)


