1. 前言
前几天写了一篇博客,告诉大家在遇到慢SQL或者复杂的并行SQL的时候怎么高效的来收集【SQL Monitor Report】,上一篇博客的链接: OceanBase 社区 ;发出去后有不少问我这份报告咋解读。今天再出一篇博客给大家介绍下如何解读报告。PS: 本文不介绍如何安装部署使用obdiag,用法参加上篇博客,本文仅做【SQL Monitor Report】报告解读。
2. 报告样式
生成的报告长这样,记得用浏览器打开。
#tree
.
├── resources
│ └── web
│ ├── bootstrap.min.css
│ ├── bootstrap.min.js
│ ├── jquery-3.2.1.min.js
│ └── popper.min.js
├── result_summary.txt
└── sql_plan_monitor_report.html
2 directories, 6 files浏览器打开表头如下:(表头展示的是基本的sql执行信息,从gv$ob_sql_audit获取的)

3. 报告【执行计划】篇
执行计划的部分如下:

执行计划有两部分组成,一个是explain extend [SQL语句] 的结果,这个我们叫做物理执行计划,并不是实际这条SQL执行的时候命中的执行计划;物理执行计划下面的是才是实际执行计划。物理执行计划可以看到统计信息、hint、outline data等信息,就不在本文展开解释了。TIPS: 这两个执行计划大部分情况下是一样的,如果不一样需要关注一下。
4. 报告【SCHEMA 信息】篇
schema这块直接参见下图就行,注意一下表行数和第三节explan extend [SQL] 是否数量级能对应上,如果数量级都对应不上,那大概率统计信息收集存在滞后,先解决统计信息收集的问题再去看SQL慢的问题。

5. 报告【SQL_AUDIT信息】篇
报告如下,点击可以展开

使用的SQL如下:
-- ob 4.x --
select /*+ sql_audit */
`SVR_IP`,`SVR_PORT`,`REQUEST_ID`,`SQL_EXEC_ID`,`TRACE_ID`,`SID`,`CLIENT_IP`,`CLIENT_PORT`,`TENANT_ID`,
`EFFECTIVE_TENANT_ID`,`TENANT_NAME`,`USER_ID`,`USER_NAME`,`USER_CLIENT_IP`,`DB_ID`,`DB_NAME`,`SQL_ID`,
`QUERY_SQL`,`PLAN_ID`,`AFFECTED_ROWS`,`RETURN_ROWS`,`PARTITION_CNT`,`RET_CODE`,`QC_ID`,`DFO_ID`,`SQC_ID`,
`WORKER_ID`,`EVENT`,`P1TEXT`,`P1`,`P2TEXT`,`P2`,`P3TEXT`,`P3`,`LEVEL`,`WAIT_CLASS_ID`,`WAIT_CLASS`,`STATE`,
`WAIT_TIME_MICRO`,`TOTAL_WAIT_TIME_MICRO`,`TOTAL_WAITS`,`RPC_COUNT`,`PLAN_TYPE`,`IS_INNER_SQL`,
`IS_EXECUTOR_RPC`,`IS_HIT_PLAN`,`REQUEST_TIME`,`ELAPSED_TIME`,`NET_TIME`,`NET_WAIT_TIME`,`QUEUE_TIME`,
`DECODE_TIME`,`GET_PLAN_TIME`,`EXECUTE_TIME`,`APPLICATION_WAIT_TIME`,`CONCURRENCY_WAIT_TIME`,
`USER_IO_WAIT_TIME`,`SCHEDULE_TIME`,`ROW_CACHE_HIT`,`BLOOM_FILTER_CACHE_HIT`,`BLOCK_CACHE_HIT`,
`DISK_READS`,`RETRY_CNT`,`TABLE_SCAN`,`CONSISTENCY_LEVEL`,`MEMSTORE_READ_ROW_COUNT`,
`SSSTORE_READ_ROW_COUNT`,`REQUEST_MEMORY_USED`,`EXPECTED_WORKER_COUNT`,`USED_WORKER_COUNT`,
`TX_ID`,`REQUEST_TYPE`,`IS_BATCHED_MULTI_STMT`,`OB_TRACE_INFO`,`PLAN_HASH`
from oceanbase.gv$ob_sql_audit where trace_id = '%s' " "AND client_ip IS NOT NULL ORDER BY QUERY_SQL ASC, REQUEST_ID
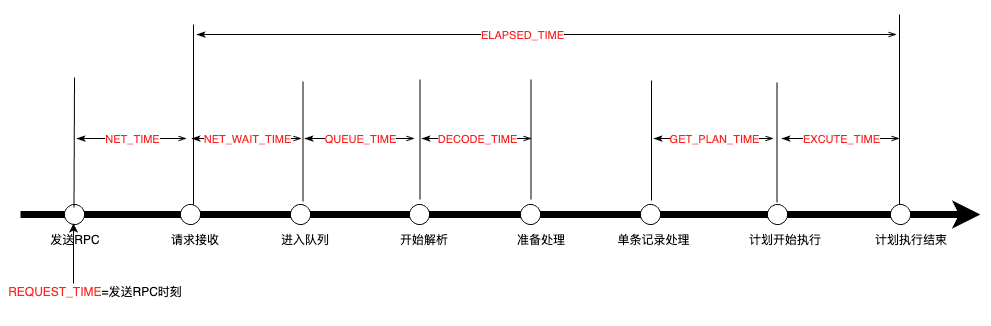
TIPS: 一些重要的时间间隔:
TIPS: sql_audit的PLAN_TYPE字段可以看到该SQL的执行计划类型,
- plan_type=1 :本地执行计划。性能最好。
- plan_type=2 : 远程执行计划。
- plan_type=3 : 分布式执行计划。包含本地执行计划和远程执行计划。
一般情况下,如果出现远程执行比较多时可能时出现切主或proxy客户端路由不准的情况。
TIPS:
- 查看retry次数是否很多(RETRY_CNT, 如果次数很多,则是否考虑是否有锁冲突或切主等情况)
- 查看queue time是不是很大(QUEUE_TIME字段)
- 查看获取执行计划时间(GET_PLAN_TIME), 如果时间很长,一般会伴随IS_HIT_PLAN = 0, 表示没有命中plan cache)
- 查看EXECUTE_TIME是否很长,如果很长,则
a. 查看是否有很长等待事件耗时
b. 查看访问的行数是否很多, 看SSSTORE_READ_ROW_COUNT, MEMSTORE_READ_ROW_COUNT两个字段, 比如大小账号场景可能导致rt抖动。
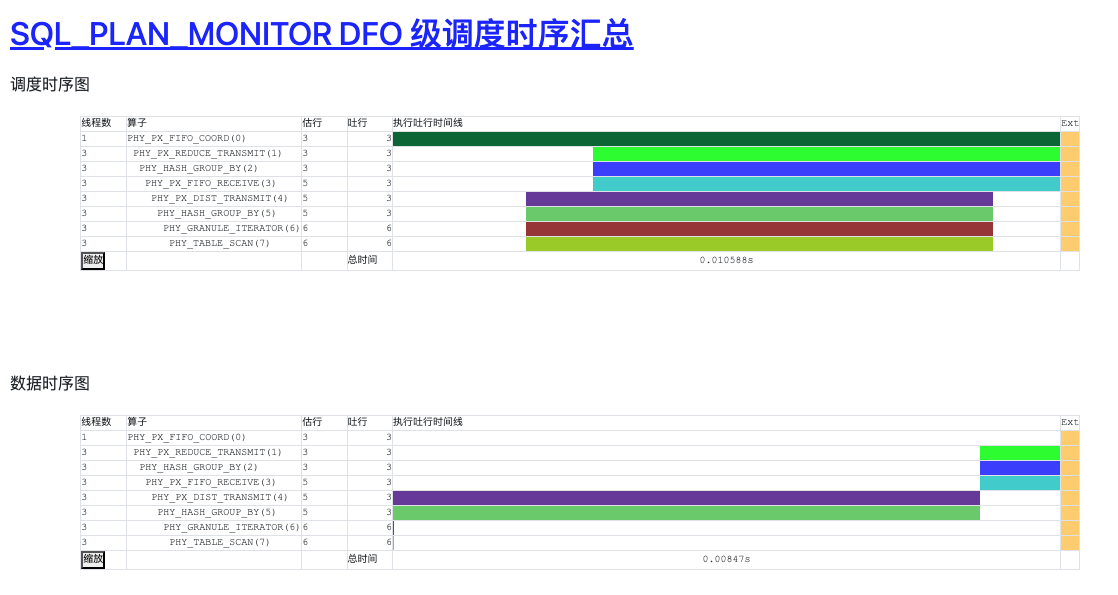
6. 报告【SQL_PLAN_MONITOR DFO级调度时序汇总】篇
概念介绍:
并行执行使用生产者-消费者模型来进行流水执行。并行调度算子解析计划,将它们切分成多个操作步骤,每个操作步骤称之为一个 DFO(Data Flow Operation)。
DFO:Data Flow Operation(DFO)即子计划,每个DFO包含若干个串行执行的算子。例如,一个DFO里包含了扫描分区,聚集,发送算子,另外一个DFO里包含了收集、聚集算子等。
obdiag 封装的SQL如下:
-- DFO 级
select
AVG(ROWS) EST_ROWS, /*0*/
plan_monitor.PLAN_DEPTH PLAN_DEPTH,
plan_monitor.PLAN_LINE_ID PLAN_LINE_ID,
PLAN_OPERATION,
COUNT(*) PARALLEL,
MIN(FIRST_REFRESH_TIME) MIN_FIRST_REFRESH_TIME,/*5*/
MAX(LAST_REFRESH_TIME) MAX_LAST_REFRESH_TIME,
MIN(FIRST_CHANGE_TIME) MIN_FIRST_CHANGE_TIME,
MAX(LAST_CHANGE_TIME) MAX_LAST_CHANGE_TIME,
UNIX_TIMESTAMP(MIN(FIRST_REFRESH_TIME)) MIN_FIRST_REFRESH_TS,
UNIX_TIMESTAMP(MAX(LAST_REFRESH_TIME)) MAX_LAST_REFRESH_TS, /*10*/
UNIX_TIMESTAMP(MIN(FIRST_CHANGE_TIME)) MIN_FIRST_CHANGE_TS,
UNIX_TIMESTAMP(MAX(LAST_CHANGE_TIME)) MAX_LAST_CHANGE_TS,
AVG(TIMESTAMPDIFF(MICROSECOND, FIRST_REFRESH_TIME, LAST_REFRESH_TIME)) AVG_REFRESH_TIME,
MAX(TIMESTAMPDIFF(MICROSECOND, FIRST_REFRESH_TIME, LAST_REFRESH_TIME)) MAX_REFRESH_TIME,
MIN(TIMESTAMPDIFF(MICROSECOND, FIRST_REFRESH_TIME, LAST_REFRESH_TIME)) MIN_REFRESH_TIME, /*15 */
AVG(TIMESTAMPDIFF(MICROSECOND, FIRST_CHANGE_TIME, LAST_CHANGE_TIME)) AVG_CHANGE_TIME,
MAX(TIMESTAMPDIFF(MICROSECOND, FIRST_CHANGE_TIME, LAST_CHANGE_TIME)) MAX_CHANGE_TIME,
MIN(TIMESTAMPDIFF(MICROSECOND, FIRST_CHANGE_TIME, LAST_CHANGE_TIME)) MIN_CHANGE_TIME,
SUM(OUTPUT_ROWS) TOTAL_OUTPUT_ROWS,
(MAX(TIMESTAMPDIFF(MICROSECOND, FIRST_CHANGE_TIME, LAST_CHANGE_TIME)) - MIN(TIMESTAMPDIFF(MICROSECOND, FIRST_CHANGE_TIME, LAST_CHANGE_TIME))) / MAX(TIMESTAMPDIFF(MICROSECOND, FIRST_CHANGE_TIME, LAST_CHANGE_TIME)+0.00000001) SKEWNESS,
SUM(STARTS) TOTAL_RESCAN_TIMES,/* 20 */
MAX(OTHERSTAT_1_ID) OTHERSTAT_1_ID,
SUM(OTHERSTAT_1_VALUE) SUM_STAT_1,
MAX(OTHERSTAT_1_VALUE) MAX_STAT_1,
MIN(OTHERSTAT_1_VALUE) MIN_STAT_1,
AVG(OTHERSTAT_1_VALUE) AVG_STAT_1, /* 25 */
MAX(OTHERSTAT_2_ID) OTHERSTAT_2_ID,
SUM(OTHERSTAT_2_VALUE) SUM_STAT_2,
MAX(OTHERSTAT_2_VALUE) MAX_STAT_2,
MIN(OTHERSTAT_2_VALUE) MIN_STAT_2,
AVG(OTHERSTAT_2_VALUE) AVG_STAT_2, /* 30 */
MAX(OTHERSTAT_3_ID) OTHERSTAT_3_ID,
SUM(OTHERSTAT_3_VALUE) SUM_STAT_3,
MAX(OTHERSTAT_3_VALUE) MAX_STAT_3,
MIN(OTHERSTAT_3_VALUE) MIN_STAT_3,
AVG(OTHERSTAT_3_VALUE) AVG_STAT_3, /* 35 */
MAX(OTHERSTAT_4_ID) OTHERSTAT_4_ID,
SUM(OTHERSTAT_4_VALUE) SUM_STAT_4,
MAX(OTHERSTAT_4_VALUE) MAX_STAT_4,
MIN(OTHERSTAT_4_VALUE) MIN_STAT_4,
AVG(OTHERSTAT_4_VALUE) AVG_STAT_4, /* 40 */
MAX(OTHERSTAT_5_ID) OTHERSTAT_5_ID,
SUM(OTHERSTAT_5_VALUE) SUM_STAT_5,
MAX(OTHERSTAT_5_VALUE) MAX_STAT_5,
MIN(OTHERSTAT_5_VALUE) MIN_STAT_5,
AVG(OTHERSTAT_5_VALUE) AVG_STAT_5, /* 45*/
MAX(OTHERSTAT_6_ID) OTHERSTAT_6_ID,
SUM(OTHERSTAT_6_VALUE) SUM_STAT_6,
MAX(OTHERSTAT_6_VALUE) MAX_STAT_6,
MIN(OTHERSTAT_6_VALUE) MIN_STAT_6,
AVG(OTHERSTAT_6_VALUE) AVG_STAT_6 /* 50 */,
TRUNCATE(AVG(DB_TIME)/1000000000.0/2.5, 4) MY_DB_TIME,
TRUNCATE(AVG(DB_TIME-USER_IO_WAIT_TIME)/1000000000.0/2.5, 4) MY_CPU_TIME,
TRUNCATE(AVG(USER_IO_WAIT_TIME)/1000000000.0/2.5, 4) MY_IO_TIME
from
(
select * FROM oceanbase.gv$sql_plan_monitor
where
trace_id = 'YF2A0BA2DA7E-00061D6A8ADDA95A-0-0'
) plan_monitor
LEFT JOIN
(
SELECT ROWS, PLAN_LINE_ID FROM oceanbase.gv$ob_plan_cache_plan_explain WHERE plan_id = xxx AND tenant_id = xxxx and svr_ip = 'xxxx' and svr_port = xxxx
) plan_explain
ON
plan_monitor.PLAN_LINE_ID = plan_explain.PLAN_LINE_ID
GROUP BY
plan_monitor.PLAN_LINE_ID, plan_monitor.PLAN_OPERATION
ORDER BY
plan_monitor.PLAN_LINE_ID ASC;
7. 报告【SQL_PLAN_MONITOR SQC级汇总】篇
概念介绍:
- QC:当用户给定的 SQL 语句需要访问的数据位于 2 台或 2 台以上 OBServer、或者单节点包含多个分区的表,就会启用并行执行,当SQL计划在连接的OBserver执行到并行查询时,主进程在决定并行度后,发送工作线程获取请求到各个机器,此时用户连接的OBServer就会作为QC角色,即查询协调者Query Coordinator(QC)。
- SQC:每个处理QC请求的线程,自动成为该查询的Sub Query Coordinator(SQC)即辅助查询协调者。SQC 负责在所在 OBServer上为各个 DFO 申请执行资源、构造执行上下文环境等,然后启动 DFO 在各个 OBServer上并行执行。

8. 报告【SQL_PLAN_MONITOR 】详情篇
这部分主要是算子展开和线程展开,你能看到哪些算子耗费时间比较长,哪些线程耗费时间多,同理你也可以看到哪些线程是不干活的,如果大部分线程都是空闲状态,那就得注意了,如果你加了并行,那大概率并行没什么用,有线程在偷懒,赶紧看看是不是并行设置的不对吧。并行这块可以参看博客:
并行执行系列的内容大家可以参考以下博客。
| 第一篇 | 并行执行概念 |
| 第二篇 | 设定并行度 |
| 第三篇 | 并发控制与排队 |
| 第四篇 | 并行执行分类 |
| 第五篇 | 并行执行控制参数 |
| 第六篇 | 并行执行诊断及调优技巧 |
| 第七篇 | 并行执行 PoC QuickStart |

9. 案例: 统计信息不准导致走错执行计划
执行SQL如下:
SELECT
`t`.`date` AS `date`,
SUM(`t`.`adcost`) AS `adcost`,
SUM(`t`.`ns`) AS `ns`,
SUM(`t`.`nc`) AS `nc`,
SUM(`t`.`realtimeordernum`) AS `realtimeordernum`,
SUM(`t`.`realtimeorderprice`) AS `realtimeorderprice`
FROM
(select * from `galileo`.`report_game_consume_conversion` where `date` BETWEEN '2024-07-21' AND '2024-07-22') AS `t`
JOIN (
SELECT
`date` AS `date1`,
`solutionid`
FROM
`galileo`.`report_game_solution`
WHERE
`date` BETWEEN '2024-07-21' AND '2024-07-22'
) AS `t1` ON `t1`.`date1`=`t`.`date`
AND `t`.`solutionid`=`t1`.`solutionid`
JOIN (
SELECT
`date` AS `date2`,
`adspaceid`
FROM
`galileo`.`report_game_adspace`
WHERE
`date` BETWEEN '2024-07-21' AND '2024-07-22'
) AS `t2` ON `t2`.`date2`=`t`.`date`
AND `t`.`adspaceid`=`t2`.`adspaceid`
LEFT JOIN (
SELECT
`date` AS `date3`,
`solutionid`,
`adspaceid`
FROM
`galileo`.`report_game_order`
WHERE
`date` BETWEEN '2024-07-21' AND '2024-07-22'
GROUP BY
`date`,
`solutionid`,
`adspaceid`
) AS `t3` ON `t3`.`date3`=`t`.`date`
AND `t`.`solutionid`=`t3`.`solutionid`
AND `t`.`adspaceid`=`t3`.`adspaceid`
GROUP BY
`t`.`date` limit 10从报告中我们看到了估行和吐行相差太大了,我们再去看报告中实际的数据行数,发现有百万级别,这也证明了算子吐行是准确的,估行相差太大了,这种估行不准非常容易误导优化器,导致优化器给出错误的执行计划。

ok, 带着怀疑我们往下看看执行计划是怎么个事。发现有三次PHY_NESTED_LOOP_JOIN动作,三张表都是百万级别的吐行,还去走PHY_NESTED_LOOP_JOIN是非常耗费时间的,不如直接hash join。
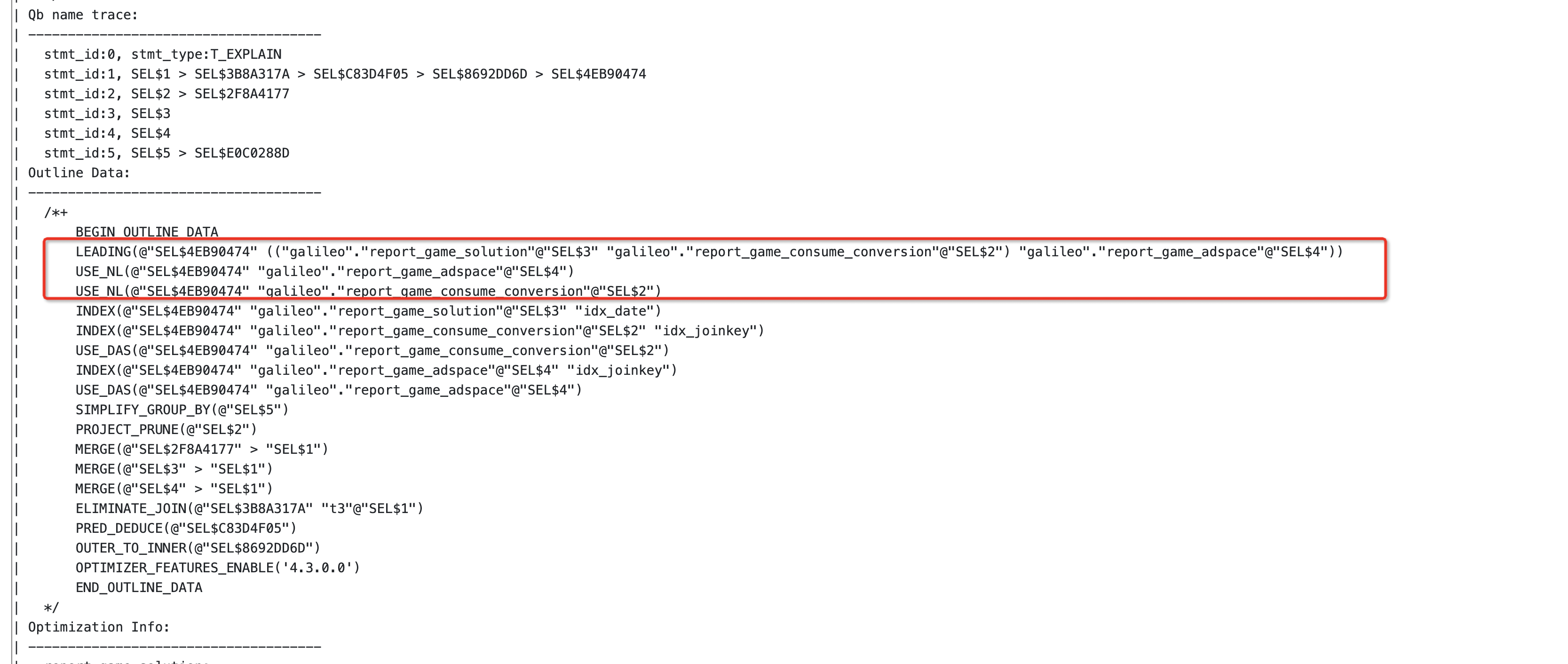
我们看了一眼SQL,发现其实SQL看起来复杂,其实一点也不复杂,多表关联而已。试试走hash join 会怎么行,说干就干,直接通过hint 来调整算子
/*+
LEADING(@"SEL$1" (("galileo"."report_game_solution"@"SEL$3" "galileo"."report_game_consume_conversion"@"SEL$2") "galileo"."report_game_adspace"@"SEL$4"))
USE_HASH(@"SEL$1" "galileo"."report_game_adspace"@"SEL$4") |
USE_HASH(@"SEL$1" "galileo"."report_game_consume_conversion"@"SEL$2")
*/说明:hint这块的内容稍微高阶一点,但是学会了很受用,大家可以看看文档: OceanBase分布式数据库-海量数据 笔笔算数
小知识点:不知道咋写hint的时候,教你一招,去看看explain extend [SQL] 的结果,照着改就行
加完hint之后执行 4s出结果,从300s --> 4s,直接提升了2个数量级。
10. 附录
- obdiag 下载地址: OceanBase分布式数据库-海量数据 笔笔算数
- obdiag 官方文档: OceanBase分布式数据库-海量数据 笔笔算数
- obdiag github地址: https://github.com/oceanbase/obdiag
- obdiag SIG 营地: [obdiag SIG] 诊断工具组 · OceanBase 技术交流


















