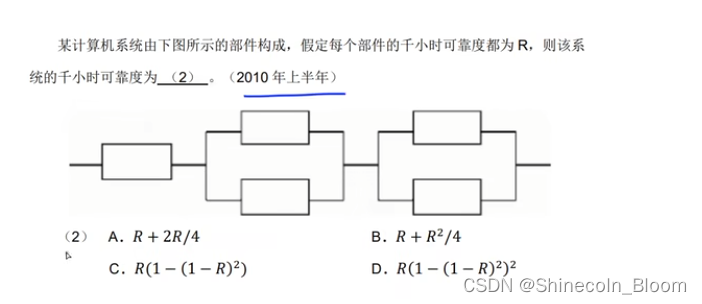
创建可用环境
# 创建环境
conda create -n demo python=3.10 -y
# 激活环境
conda activate demo
# 安装 torch
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
# 安装其他依赖
pip install transformers==4.38
pip install sentencepiece==0.1.99
pip install einops==0.8.0
pip install protobuf==5.27.2
pip install accelerate==0.33.0
pip install streamlit==1.37.0
如果没有( InternLM2-Chat-1.8B模型)下载 InternLM2-Chat-1.8B模型
创建download_hf.py文件用于下载模型
import os
# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下载模型
os.system('huggingface-cli download --resume-download InternLM2-Chat-1.8B --local-dir /root/model/InternLM2-Chat-1.8B')
激活对应的环境并运行下载模型脚本
conda activate demo
python download_hf.py
运行InternLM2-Chat-1.8B模型
创建一个文件touch cli_demo.py写入如下代码
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
#此处填写自己的模型下载在什么地方就写什么地方
model_name_or_path = "/root/model/internlm2-chat-1_8b"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True, device_map='cuda:0')
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='cuda:0')
model = model.eval()
system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""
messages = [(system_prompt, '')]
print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")
while True:
input_text = input("\nUser >>> ")
input_text = input_text.replace(' ', '')
if input_text == "exit":
break
length = 0
for response, _ in model.stream_chat(tokenizer, input_text, messages):
if response is not None:
print(response[length:], flush=True, end="")
length = len(response)
运行cli_demo.py
在上面创建的环境中运行
conda activate demo
python cli_demo.py
直接用脚本执行的效果如图

用浏览器来进行对话之Streamlit Web Demo 部署 InternLM2-Chat-1.8B 模型
创建streamlit_demo.py来运行InternLM2-Chat-1.8B 模型
# isort: skip_file
import copy
import warnings
from dataclasses import asdict, dataclass
from typing import Callable, List, Optional
import streamlit as st
import torch
from torch import nn
from transformers.generation.utils import (LogitsProcessorList,
StoppingCriteriaList)
from transformers.utils import logging
from transformers import AutoTokenizer, AutoModelForCausalLM # isort: skip
logger = logging.get_logger(__name__)
@dataclass
class GenerationConfig:
# this config is used for chat to provide more diversity
max_length: int = 32768
top_p: float = 0.8
temperature: float = 0.8
do_sample: bool = True
repetition_penalty: float = 1.005
@torch.inference_mode()
def generate_interactive(
model,
tokenizer,
prompt,
generation_config: Optional[GenerationConfig] = None,
logits_processor: Optional[LogitsProcessorList] = None,
stopping_criteria: Optional[StoppingCriteriaList] = None,
prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor],
List[int]]] = None,
additional_eos_token_id: Optional[int] = None,
**kwargs,
):
inputs = tokenizer([prompt], padding=True, return_tensors='pt')
input_length = len(inputs['input_ids'][0])
for k, v in inputs.items():
inputs[k] = v.cuda()
input_ids = inputs['input_ids']
_, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]
if generation_config is None:
generation_config = model.generation_config
generation_config = copy.deepcopy(generation_config)
model_kwargs = generation_config.update(**kwargs)
bos_token_id, eos_token_id = ( # noqa: F841 # pylint: disable=W0612
generation_config.bos_token_id,
generation_config.eos_token_id,
)
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
if additional_eos_token_id is not None:
eos_token_id.append(additional_eos_token_id)
has_default_max_length = kwargs.get(
'max_length') is None and generation_config.max_length is not None
if has_default_max_length and generation_config.max_new_tokens is None:
warnings.warn(
f"Using 'max_length''s default \
({repr(generation_config.max_length)}) \
to control the generation length. "
'This behaviour is deprecated and will be removed from the \
config in v5 of Transformers -- we'
' recommend using `max_new_tokens` to control the maximum \
length of the generation.',
UserWarning,
)
elif generation_config.max_new_tokens is not None:
generation_config.max_length = generation_config.max_new_tokens + \
input_ids_seq_length
if not has_default_max_length:
logger.warn( # pylint: disable=W4902
f"Both 'max_new_tokens' (={generation_config.max_new_tokens}) "
f"and 'max_length'(={generation_config.max_length}) seem to "
"have been set. 'max_new_tokens' will take precedence. "
'Please refer to the documentation for more information. '
'(https://huggingface.co/docs/transformers/main/'
'en/main_classes/text_generation)',
UserWarning,
)
if input_ids_seq_length >= generation_config.max_length:
input_ids_string = 'input_ids'
logger.warning(
f'Input length of {input_ids_string} is {input_ids_seq_length}, '
f"but 'max_length' is set to {generation_config.max_length}. "
'This can lead to unexpected behavior. You should consider'
" increasing 'max_new_tokens'.")
# 2. Set generation parameters if not already defined
logits_processor = logits_processor if logits_processor is not None \
else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None \
else StoppingCriteriaList()
logits_processor = model._get_logits_processor(
generation_config=generation_config,
input_ids_seq_length=input_ids_seq_length,
encoder_input_ids=input_ids,
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
logits_processor=logits_processor,
)
stopping_criteria = model._get_stopping_criteria(
generation_config=generation_config,
stopping_criteria=stopping_criteria)
logits_warper = model._get_logits_warper(generation_config)
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
scores = None
while True:
model_inputs = model.prepare_inputs_for_generation(
input_ids, **model_kwargs)
# forward pass to get next token
outputs = model(
**model_inputs,
return_dict=True,
output_attentions=False,
output_hidden_states=False,
)
next_token_logits = outputs.logits[:, -1, :]
# pre-process distribution
next_token_scores = logits_processor(input_ids, next_token_logits)
next_token_scores = logits_warper(input_ids, next_token_scores)
# sample
probs = nn.functional.softmax(next_token_scores, dim=-1)
if generation_config.do_sample:
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
else:
next_tokens = torch.argmax(probs, dim=-1)
# update generated ids, model inputs, and length for next step
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
model_kwargs = model._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=False)
unfinished_sequences = unfinished_sequences.mul(
(min(next_tokens != i for i in eos_token_id)).long())
output_token_ids = input_ids[0].cpu().tolist()
output_token_ids = output_token_ids[input_length:]
for each_eos_token_id in eos_token_id:
if output_token_ids[-1] == each_eos_token_id:
output_token_ids = output_token_ids[:-1]
response = tokenizer.decode(output_token_ids)
yield response
# stop when each sentence is finished
# or if we exceed the maximum length
if unfinished_sequences.max() == 0 or stopping_criteria(
input_ids, scores):
break
def on_btn_click():
del st.session_state.messages
@st.cache_resource
def load_model():
model = (AutoModelForCausalLM.from_pretrained(
'/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b',
trust_remote_code=True).to(torch.bfloat16).cuda())
tokenizer = AutoTokenizer.from_pretrained(
#下载的模型在哪里就填写哪里
'/internlm2-chat-1_8b',
trust_remote_code=True)
return model, tokenizer
def prepare_generation_config():
with st.sidebar:
max_length = st.slider('Max Length',
min_value=8,
max_value=32768,
value=32768)
top_p = st.slider('Top P', 0.0, 1.0, 0.8, step=0.01)
temperature = st.slider('Temperature', 0.0, 1.0, 0.7, step=0.01)
st.button('Clear Chat History', on_click=on_btn_click)
generation_config = GenerationConfig(max_length=max_length,
top_p=top_p,
temperature=temperature)
return generation_config
user_prompt = '<|im_start|>user\n{user}<|im_end|>\n'
robot_prompt = '<|im_start|>assistant\n{robot}<|im_end|>\n'
cur_query_prompt = '<|im_start|>user\n{user}<|im_end|>\n\
<|im_start|>assistant\n'
def combine_history(prompt):
messages = st.session_state.messages
meta_instruction = ('You are InternLM (书生·浦语), a helpful, honest, '
'and harmless AI assistant developed by Shanghai '
'AI Laboratory (上海人工智能实验室).')
total_prompt = f'<s><|im_start|>system\n{meta_instruction}<|im_end|>\n'
for message in messages:
cur_content = message['content']
if message['role'] == 'user':
cur_prompt = user_prompt.format(user=cur_content)
elif message['role'] == 'robot':
cur_prompt = robot_prompt.format(robot=cur_content)
else:
raise RuntimeError
total_prompt += cur_prompt
total_prompt = total_prompt + cur_query_prompt.format(user=prompt)
return total_prompt
def main():
# torch.cuda.empty_cache()
print('load model begin.')
model, tokenizer = load_model()
print('load model end.')
st.title('InternLM2-Chat-1.8B')
generation_config = prepare_generation_config()
# Initialize chat history
if 'messages' not in st.session_state:
st.session_state.messages = []
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message['role'], avatar=message.get('avatar')):
st.markdown(message['content'])
# Accept user input
if prompt := st.chat_input('What is up?'):
# Display user message in chat message container
with st.chat_message('user'):
st.markdown(prompt)
real_prompt = combine_history(prompt)
# Add user message to chat history
st.session_state.messages.append({
'role': 'user',
'content': prompt,
})
with st.chat_message('robot'):
message_placeholder = st.empty()
for cur_response in generate_interactive(
model=model,
tokenizer=tokenizer,
prompt=real_prompt,
additional_eos_token_id=92542,
**asdict(generation_config),
):
# Display robot response in chat message container
message_placeholder.markdown(cur_response + '▌')
message_placeholder.markdown(cur_response)
# Add robot response to chat history
st.session_state.messages.append({
'role': 'robot',
'content': cur_response, # pylint: disable=undefined-loop-variable
})
torch.cuda.empty_cache()
if __name__ == '__main__':
main()
运行streamlit来部署,在对应的虚拟环境中
streamlit run streamlit_demo.py --server.address 127.0.0.1 --server.port 6006
浏览器运行效果