〔探索AI的无限可能,微信关注“AIGCmagic”公众号,让AIGC科技点亮生活〕
本文作者:AIGCmagic社区 猫先生
一、简 介
DiffIR2VR-Zero:一种创新的零样本视频恢复技术,该技术利用预训练的图像恢复模型,解决了传统方法在不同场景下泛化能力不足的问题。
通过关键帧与局部帧的分层合并策略和混合对应机制,该方法在无需重新训练的情况下,实现了卓越的视频恢复效果,甚至在极端退化条件下超越了训练模型。这项研究不仅提升了视频恢复的效率和适用性,也为高质量视频输出需求的领域带来了技术革新。
项目主页:https://jimmycv07.github.io/DiffIR2VR_web/
官方演示:https://huggingface.co/spaces/Koi953215/DiffIR2VR

二、视频超分辨率

(a) 传统的基于回归的方法(例如 FMA-Net)仅限于训练数据域,并且在遇到域外输入时往往会产生模糊的结果。
(b) 虽然将基于图像的扩散模型(例如 DiffBIR)应用于各个帧可以生成真实的细节,但这些细节通常缺乏帧间的一致性。
(c) DiffIR2VR-Zero方法利用图像扩散模型来恢复视频,无需任何额外的训练即可实现真实且一致的结果。
三、方法概述
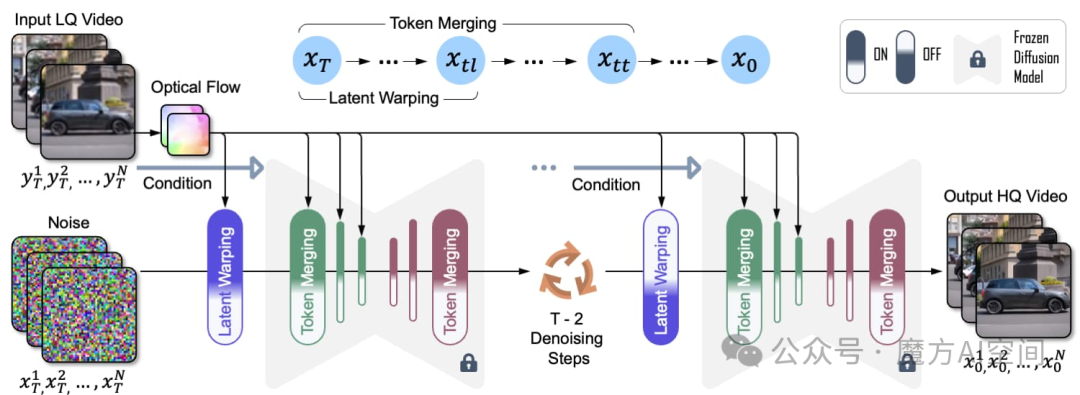
使用扩散模型批量处理低质量 (LQ) 视频,并在每批中随机采样关键帧。(a) 在扩散去噪过程开始时,分层潜在扭曲通过关键帧之间的潜在扭曲在全局提供粗略的形状指导,并通过在批次内传播这些潜在扭曲在局部提供粗略的形状指导。(b) 在大部分去噪过程中,标记在自注意力层之前合并。对于下采样块,使用光流来查找标记之间的对应关系,对于上采样块,利用余弦相似度。这种混合流引导、空间感知的Token合并通过利用流和空间信息准确地识别Token之间的对应关系,从而增强Token级别的整体一致性。
分层潜在变形
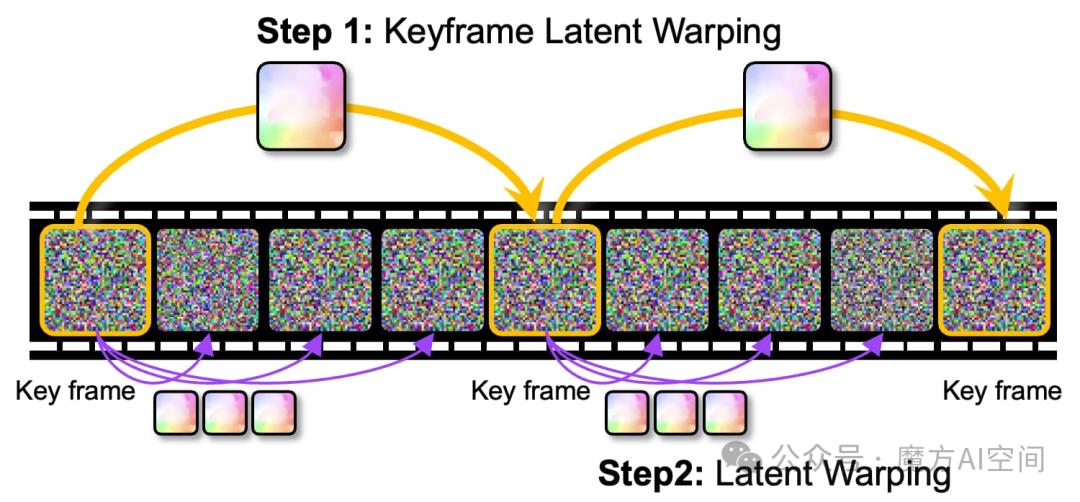
无需任何训练,分层潜在变形即可提供全局和局部形状指导,并可以通过增强潜在空间中的时间稳定性来实现跨帧的一致性。
混合空间感知Token合并
在自注意力层之前,利用光流和余弦相似性匹配相似的Token,提高时间一致性。
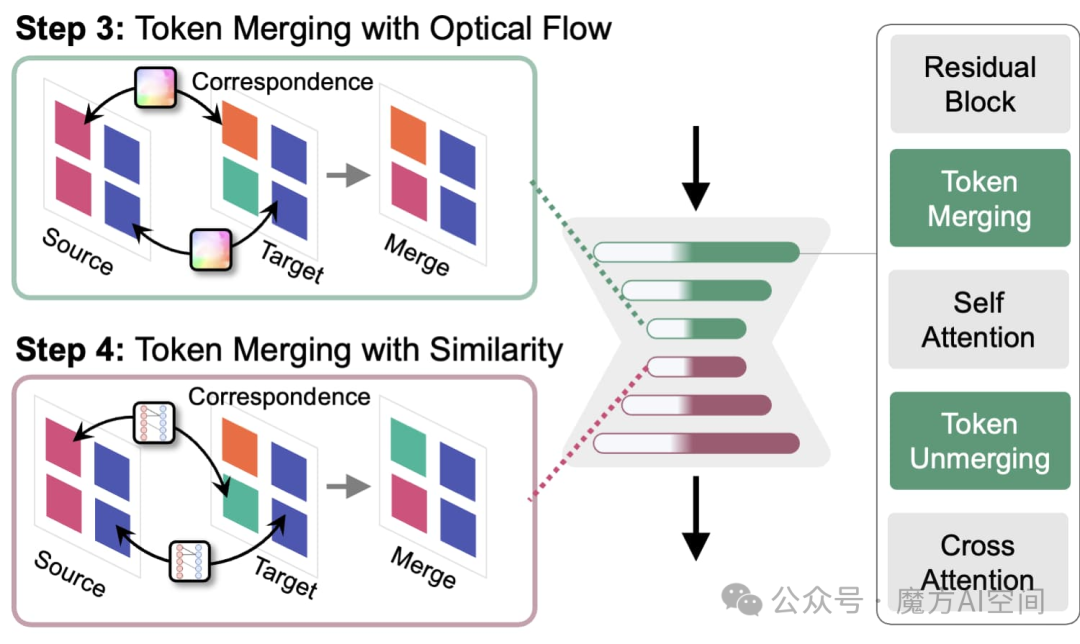
自注意力层之前的混合空间感知令牌合并通过使用 UNet 的下行块中的光流和上行块中的**余弦相似性**来匹配相似的令牌,从而提高了时间一致性。
令牌对应关系
通过光流和余弦相似性找到不同的对应关系,采用混合方法提高效果。

通过余弦相似度和光流找到对应关系。在去噪过程开始时,UNet下块中的潜在噪声太大,余弦相似性无法有效,而从 LQ 帧估计的光流仍然可靠。流和余弦相似度通常会识别不同的对应关系,因此混合方法更有效。
四、实操部署
为了方便访问huggingface不方便的朋友,关于DiffIR2VR-Zero的代码和模型文件,已打包好了,关注【魔方AI空间】,回复“111”即可领取!!
安装依赖
# clone this repo
git clone https://github.com/jimmycv07/DiffIR2VR-Zero.git
cd DiffIR2VR-Zero
# create environment
conda create -n diffir2vr python=3.10
conda activate diffir2vr
pip install -r requirements.txt
下载模型文件
请按照以下文件夹结构放置预训练权重。
weights
└─── gmflow_sintel-0c07dcb3.pth
└─── v2.pth
└─── v2-1_512-ema-pruned.ckpt
推理命令
视频去噪
python -u inference.py \
--version v2 \
--task dn \
--upscale 1 \
--cfg_scale 4.0 \
--batch_size 10 \
--input inputs/noise_50/flamingo \
--output results/Denoise/flamingo \
--config configs/inference/my_cldm.yaml \
--final_size "(480, 854)" \
--merge_ratio "(0.6, 0)" \
--better_start
视频超分
python -u inference.py \
--version v2 \
--task sr \
--upscale 4 \
--cfg_scale 4.0 \
--batch_size 10 \
--input inputs/BDx4/rhino \
--output results/SR/rhino \
--config configs/inference/my_cldm.yaml \
--final_size "(480, 854)" \
--merge_ratio "(0.6, 0)"
推荐阅读:
《AIGCmagic星球》,五大AIGC方向正式上线!让我们在AIGC时代携手同行!限量活动
《三年面试五年模拟》版本更新白皮书,迎接AIGC时代
AIGC |「多模态模型」系列之OneChart:端到端图表理解信息提取模型
AI多模态模型架构之模态编码器:图像编码、音频编码、视频编码
AI多模态模型架构之输入投影器:LP、MLP和Cross-Attention
AI多模态模型架构之LLM主干(1):ChatGLM系列
AI多模态模型架构之LLM主干(2):Qwen系列
AI多模态模型架构之LLM主干(3):Llama系列
AI多模态模型架构之输出映射器:Output Projector
AI多模态教程:从0到1搭建VisualGLM图文大模型案例
AI多模态教程:Mini-InternVL1.5多模态大模型实践指南
AI多模态教程:Qwen-VL多模态大模型实践指南
AI多模态实战教程:面壁智能MiniCPM-V多模态大模型问答交互、llama.cpp模型量化和推理
智谱推出创新AI模型GLM-4-9B:国家队开源生态的新里程碑
技术交流:
加入「AIGCmagic社区」群聊,一起交流讨论,涉及 「AI视频、AI绘画、Sora技术拆解、数字人、多模态、大模型、传统深度学习、自动驾驶」等多个不同方向,可私信或添加微信号:【lzz9527288】,备注不同方向邀请入群!!