文章目录
- 一. 文件概述
- 1. 狭义和广义上的文件
- 2. 文件的分类
- 3. 文件的路径
- 二. 针对文件系统的操作
- 1. File类的属性和构造
- 2. File类的获取操作
- 3. File类的判断操作
- 4. 文件的创建和删除
- 5. 其他的常用方法
- 三. 对文件内容进行读写
- 1. IO流对象
- 2. 文件的读操作
- 3. 文件的写操作
- 4. Scanner搭配流对象进行读取
- 5. PrintStream和PrintWriter
- 6. 补充: 为什么使用后一定要关闭文件资源
- 四. 文件操作案例
- 1. 扫描指定文件并根据文件名删除指定普通文件
- 2. 普通文件的复制
- 3. 获取含有指定字符串的普通文件
一. 文件概述
1. 狭义和广义上的文件
平时我们所提到的文件, 常见的比如 .jpg,.txt, .mp3, .mp4这些, 还有放置这些格式文件的文件夹, 像这些文件都是存储在硬盘上的格式文件或者目录(文件夹), 这些就是狭义上的文件.

而在计算机中文件是一个广义的概念, 广义上的文件泛指计算机中很多的软件硬件资源, 操作系统把许多软硬件资源抽象成了文件, 按照文件的方式来进行统一管理, 比如网络设备中的网卡, 操作系统将网卡也抽象成了一种 “文件”, 以简化程序的开发, 除了网卡, 还有我们所使用的键盘和显示器等也被操作系统抽象为了文件.
而在下面的内容中, 只涉及到狭义的文件.
2. 文件的分类
常见的许多格式文件(如word, execl, 图片, 音频, 视频…), 整体可以归纳到两类中:
- 文本文件(存放的是文本, 字符串), 由字符构成, 都是指定字符集编码表里的数据.
- 二进制文件(存放的是二进制数据), 可以存放任何想存放的数据.
文本文件使用记事本打开里面显示的是正常的文本内容, 而二进制文件使用记事本打开里面大概率是会乱码的, 实际写代码的时候,这两类文件的处理方式略有差别.
3. 文件的路径
每个文件, 在硬盘上都有一个具体的 “路径”, 文件的路径包括两种, 一种是绝对路径, 以盘符(C:或者D:)开头, 另一种是相对路径, 以.或..开头的路径, 相对路径是基于当前所在目录(工作目录)来说的, 使用/(在windows上也可以使用\, 但是更建议使用的是/, 使用\在字符串中容易被解析为转义字符)来分割不同的目录级别.
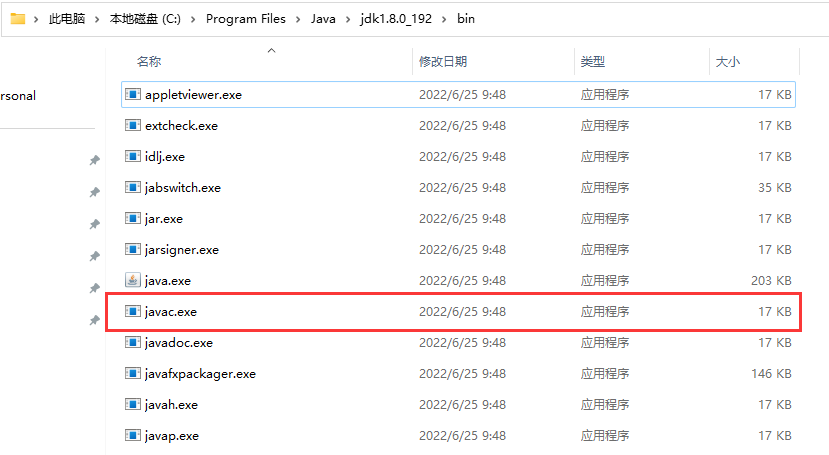
以C:/Program Files/Java/jdk1.8.0_192/bin目录为例, 以该路径为工作目录, 假设我们要在bin文件夹中找到javac.exe文件, 则使用相对路径表示为./javac.exe, 这里的.就表示当前所在目录的路径C:/Program Files/Java/jdk1.8.0_192/bin, 而使用绝对路径表示就更清晰了C:/Program Files/Java/jdk1.8.0_192/bin/javac.exe.
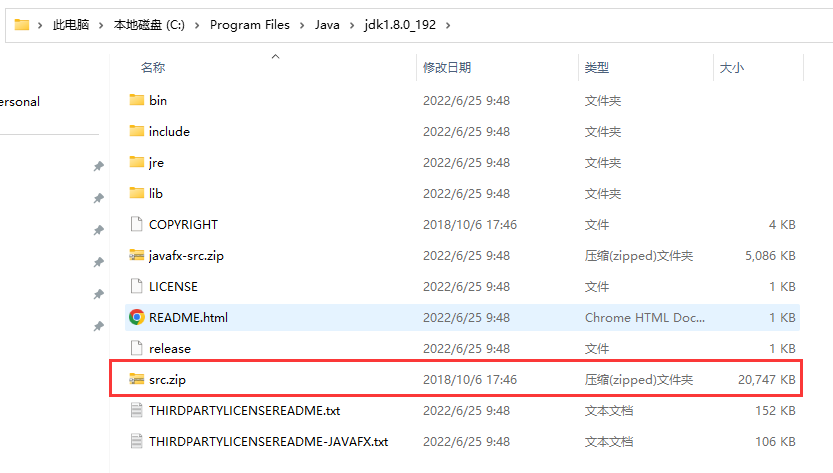
还是以C:/Program Files/Java/jdk1.8.0_192/bin目录为工作目录, 我们要表示与bin文件夹在同一目录中的src.zip文件, 我们可以使用..表示工作目录的父路径C:/Program Files/Java/jdk1.8.0_192, 该文件的相对路径为../src.zip, 绝对路径为C:/Program Files/Java/jdk1.8.0_192/src.zip.
二. 针对文件系统的操作
针对文件系统的操作, 主要是文件/目录的创建和删除, 文件的重命名等.
Java标准库中提供了一个File类, 能够完成对某一路径上的文件进行操作.
1. File类的属性和构造
File类位于import java.io包下, 该类相当于一个抽象的文件路径, 能够在指定的路径中进行文件的创建, 删除, 修改文件等, 但是不能对文件的内容进行操作.
下面先来介绍File类中的常见属性和方法.
🎯File类的属性:
| 修饰符及类型 | 属性 | 说明 |
|---|---|---|
| public static final String | pathSeparator | 依赖于系统的路径分隔符(/或者\), String类型的表示. |
| public static final char | pathSeparatorChar | 依赖于系统的路径分隔符(/或者\), char类型的表示. |
🎯File类的构造方法:
| 方法 | 说明 |
|---|---|
| File(File parent, String child) | 根据父文件对象 + 孩子文件路径, 创建文件 |
| File(String path name) | 根据一个文件路径去创建文件 |
| File(String parent, String child) | 根据父目录(路径) + 孩子路径,创建文件 |
File类实例对象就是表示一个文件路径, 上面构造方法的参数中涉及到的String表示的路径, 可以是绝对路径, 也可以是相对路径; 如果通过绝对路径创建文件的实例对象, 那么就是在所给的绝对路径目录下进行相关的文件操作, 而如果是相对路径, 在不同的环境下, 工作目录是不相同的, 比如如果是在控制台的命令行中操作, 则会以在命令行运行程序的目录作为工作目录, 如果在IDEA中操作, 那工作目录默认就是你的当前项目所在的目录.
public static void main(String[] args) throws IOException
File file = new File("D:/test.txt");
}
要注意的的是上面传入的路径是D:/test.txt, 但实际上在这里并不要求在在D:/这里真的有个test.txt文件, 后序如果需要使用这个文件但没有的话是可以通过createNewFile方法创建的.
2. File类的获取操作
| 返回值 | 方法 | 说明 |
|---|---|---|
| Sting | getParent() | 返回File对象父目录文件路径 |
| String | getName() | 返回File对象文件名 |
| String | getPath() | 返回File对象文件路径 |
| String | getAbsolutePath() | 返回File对象的绝对路径 |
| String | getCanonicalPath() | 返回File对象修饰过的绝对路径 |
代码示例:
import java.io.File;
import java.io.IOException;
public class TestDemo {
public static void main(String[] args) throws IOException {
//通过绝对路径字符串创建文件对象, 创建文件对象时不会自动创建文件
File file = new File("D:/test.txt");
//获取当前文件对象的文件名
System.out.println(file.getName());
//获取当前文件的绝对路径字符串
System.out.println(file.getAbsolutePath());
//获取当前文件省略后的绝对路径字符串
System.out.println(file.getCanonicalPath());
//获取当前文件父目录的路径字符串
System.out.println(file.getParent());
//获取当前文件对象构造时所传入的路径字符串
System.out.println(file.getPath());
System.out.println("================");
//通过相对路径字符串创建文件对象
File file2 = new File("./test.txt");
//获取当前文件对象的文件名
System.out.println(file2.getName());
//获取当前文件的绝对路径字符串
System.out.println(file2.getAbsolutePath());
//获取当前文件省略后的绝对路径字符串
System.out.println(file2.getCanonicalPath());
//获取当前文件父目录的路径字符串
System.out.println(file2.getParent());
//获取当前文件对象构造时所传入的路径字符串
System.out.println(file2.getPath());
}
}
执行结果:
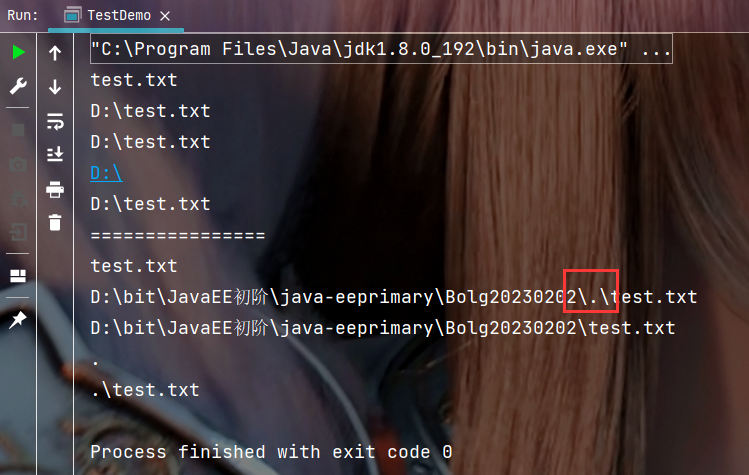
3. File类的判断操作
| 返回值 | 方法 | 说明 |
|---|---|---|
| boolean | exists() | 判断File对象代表的文件是否真实存在 |
| boolean | isDirectory() | 判断File对象代表的文件是否是一个目录 |
| boolean | isFile() | 判断File对象代表的文件是否是一个普通文件 |
| boolean | isHidden() | 判断File对象代表的文件是否是一个隐藏文件 |
| boolean | isAbsolute() | 判断File对象路径名是否是绝对路径 |
| boolean | canRead() | 判断用户是否对文件有可读权限 |
| boolean | canWrite() | 判断用户是否对文件有可写权限 |
| boolean | canExecute() | 判断用户是否对文件有可执行权限 |
代码示例:
在IDEA的在工作目录下存在一个文件test.txt, 这里使用File来判断该文件的一些相关属性.
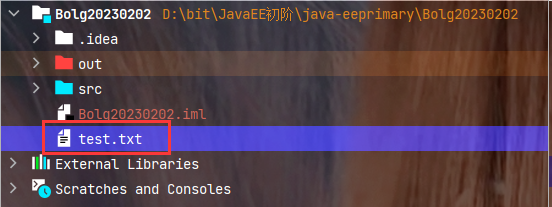
import java.io.File;
public class TestDemo1 {
public static void main(String[] args) {
File file = new File("./test.txt");
//判断文件是否存在
System.out.println(file.exists());
//判断File对象的路径是否是绝对路径
System.out.println(file.isAbsolute());
//判断文件是否是一个普通文件
System.out.println(file.isFile());
//判断文件是否是一个目录(文件夹)
System.out.println(file.isDirectory());
//判断文件是否是一个隐藏文件
System.out.println(file.isHidden());
//判断文件是否能够执行/读/写
System.out.println(file.canExecute());
System.out.println(file.canRead());
System.out.println(file.canWrite());
}
}
执行结果:
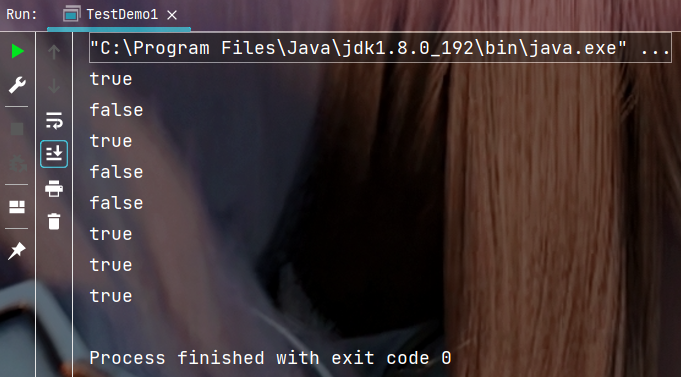
4. 文件的创建和删除
| 返回值 | 方法 | 说明 |
|---|---|---|
| boolean | createNewFile() | 自动创建一个新文件,创建成功返回true |
| boolean | mkdir() | 创建File对象表示的目录 |
| boolean | mkdir() | 创建File对象表示的多级目录 |
| boolean | delete() | 根据File对象删除该文件,删除成功返回true |
| void | deleteOnExist() | 根据File对象,标注该文件将被删除,当JVM运行结束才会执行 |
代码示例:
还是在IDEA默认的工作目录下进行演示, 当前目录中只有之前保留的test.txt文件和项目配置文件.
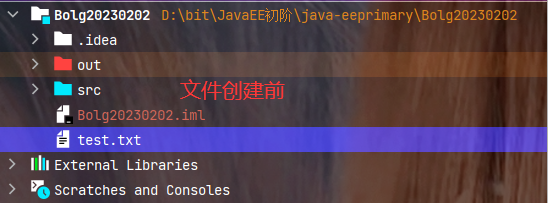
🍂创建文件演示:
import java.io.File;
import java.io.IOException;
public class TestDemo2 {
public static void main(String[] args) throws IOException {
File file = new File("./abc.txt");
//文件未创建的情况下创建新文件
if (!file.exists()) {
file.createNewFile();
System.out.println("创建文件成功!");
}
//创建一个目录(文件夹)
file = new File("./temp");
file.mkdir();
System.out.println("创建目录成功!");
//创建多个目录
file = new File("./aaa/bbb/ccc");
file.mkdirs();
System.out.println("创建多个文件夹成功!");
}
}
执行结果:
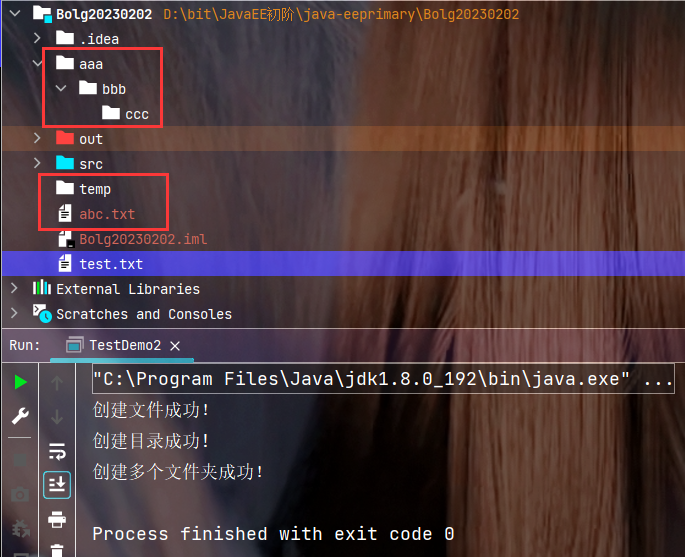
如果程序运行后工作目录中没有实时看到对应文件或者目录创建的话, 可以右键项目, 然后选择Reload from Disk刷新一下即可.
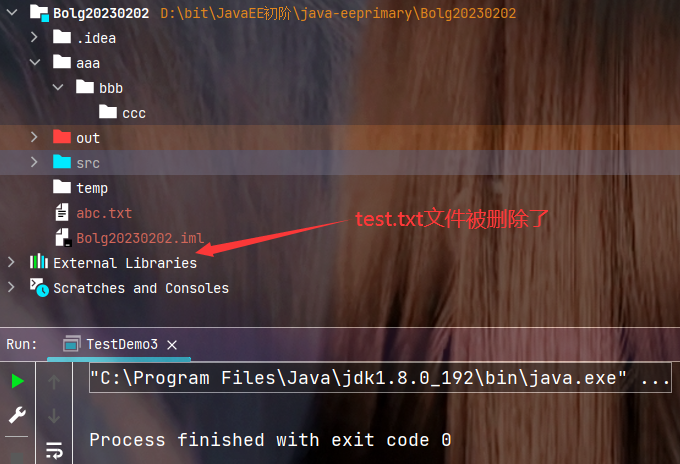
🍂删除文件演示:
import java.io.File;
public class TestDemo3 {
public static void main(String[] args) {
//删除操作
File file = new File("./test.txt");
file.delete();
}
}
执行结果:
关于删除方法中的deleteOnExist()不太好演示, 这里解释一下, 这个方法的功能是在程序退出的时候, 自动删除文件, 当我们在程序中需要用到一些 “临时文件” 的时候, 可以用到这个方法, 保证在程序退出的同时把临时文件给删除掉.
什么时候会用到临时文件的呢, 比如这里打开一个word文档, 在打开的同时就会在同级目录下生成出一个临时文件, 关闭word, 这个临时文件被删除了, 临时文件发挥的功能是实时保存我们实时编辑的内容(尤其是没有保存的内容), 防止我们编辑了很多内容但由于一些问题导致我们没有进行保存, 比如工作一半突然停电了, 东西还没来得及保存, 但由于临时文件中实时保存了我们编辑的内容, 等到再次启动word文档时, 就会提醒我们是否要恢复之前的编辑内容.
5. 其他的常用方法
| 返回值 | 方法 | 说明 |
|---|---|---|
| String[] | list() | 返回File对象目录下所有的文件名 |
| File[] | listFiles() | 返回File对象目录下的所有文件,以File对象的形式表示 |
| boolean | renameTo(File dest) | 对文件进行改名 |
代码示例:
import java.io.File;
import java.io.IOException;
import java.util.Arrays;
public class TestDemo4 {
public static void main(String[] args) throws IOException {
File file = new File("./");
File tmp1 = new File("./aaa");
File tmp2 = new File("./eee");
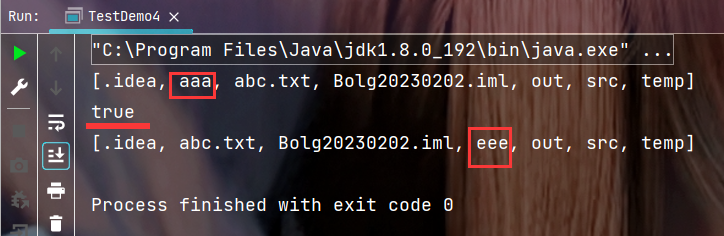
//获取当前路径目录下所有文件名
System.out.println(Arrays.toString(file.list()));
//将目录aaa更名为eee
System.out.println(tmp1.renameTo(tmp2));
//重新获取当前路径目录下所有文件名
System.out.println(Arrays.toString(file.list()));
}
}
执行结果:
三. 对文件内容进行读写
1. IO流对象
针对文件内容的读写, Java标准库中提供了两组类和接口, 分别用来针对两类文件的内容进行读写, 一组是字节流对象, 可以针对二进制文件进行读写, 另外一组是字符流对象, 可以针对文本文件进行读写.
对于二进制文件内容的读写可以使用InputStream(读)和OutputStream(写)来操作, 对于文本文件内容的读写可以使用Reader(读)和Writer(写)来操作, 这四个java提供的标准类都是抽象类, 可以认为不同的输入/输出设备都可以对应一个前面的类, 但这里只关心文件的读写, 我们在使用时使用这几个实现类来创建实例对象即可, 分别对应的是FileInputStream, FileOutputStream, FileReader和FileWriter类.
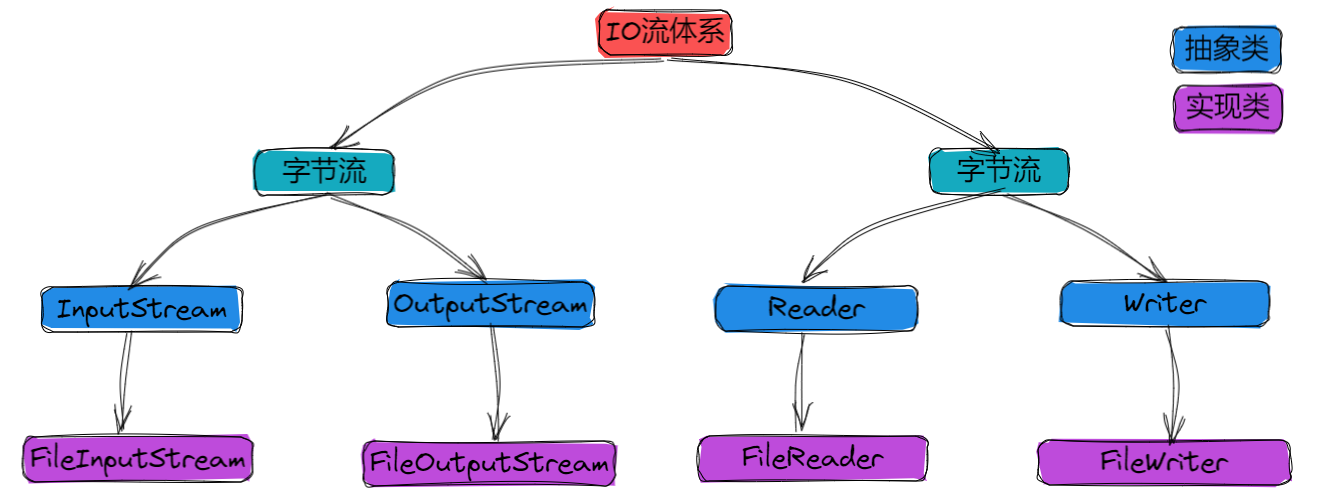
那么为什么针对文件内容操作这些类叫做 “流对象”? 其实这是一个形象的比喻, 想象一下水流的滔滔不绝, 接水时我们可以选择一次接一点水, 也可以选择一次接很多水; 而我们使用这些类对文件进行读写操作时, 可以一次读一个字节/字符, 也可以一次读多个字节/字符, 就像水流一样, 所以将这些对象叫做流对象; 想象有一个羽毛球筒, 筒里有很多羽毛球, 但羽毛球只能一个一个取, 这就不是流.
对文件进行写操作称为输出流, 对文件进行读操作称为输入流.

还有一个点这里简单说一下, 计算机中的读和写的方向, 是以CPU为中心来看待的, 内存更接近CPU, 而硬盘相较于内存离CPU更远;
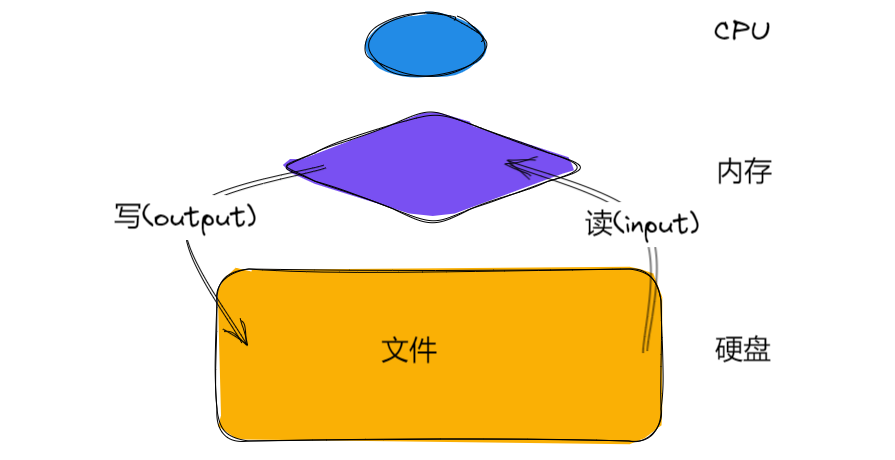
数据朝着CPU的方向流, 就是输入, 所以就把数据从硬盘到内存这个过程称为读(input); 数据向远离CPU的方向流向, 就是输出, 所以就把数据从内存到硬盘这个过程称为写(output).
那么下面就介绍具体的使用了, 虽然这里涉及到的类很多, 但在使用时规律性很强, 核心就是四个操作:
- 打开文件(构造对象).
- 读文件(
read), 针对InputStream/Reader. - 写文件(
write), 针对OutputStream/Writer. - 关闭文件(
close).
不过还是有一些需要注意的细节, 具体看下面的内容.
2. 文件的读操作
🍂首先先来看读文件的操作, 读文件涉及到的抽象类和实现类有, 字节流: InputStream, FileInputStream, 字符流: Reader, FileReader.
FileInputStream的构造方法:
| 方法 | 解释 |
|---|---|
| FileInputStream(File file) | 利用 File 构造文件输入流 |
| FileInputStream(String name) | 利用文件路径构造文件输入流 |
InputStream读文件涉及的方法:
| 返回值 | 方法 | 解释 |
|---|---|---|
| int | read() | 读取一个字节的数据, 返回值就是读取到的字节值, 返回 -1 代表已经完全读完了 |
| int | read(byte[] b) | 最多读取 b.length 字节的数据到 b 中,返回实际读到的字节数, -1 代表以及读完了, b是输出型参数 |
| int | read(byte[] b, int off, int len) | 最多读取 len - off 字节的数据到 b 中, 放在从 off 开始,返回实际读到的字节数, -1 代表已经读完了 |
| void | close() | 关闭字节流 |
对于上面无参版本的read()有一个小问题, 它的返回值是读取到的字节值, 那它的返回值按理来说设置为byte就行了, 为什么这里的返回值设置为了int呢?
其实这样设置是为了处理文件读完了情况, 我们知道使用这个方法文件读完了的情况下是返回值是一个-1, 如果使用byte类型作为返回值会出现一个问题, byte能表示的范围是-128到127, 当返回值为-1时区分不了文件是读完了还是读到的字节值就是-1, 而如果将读到一个字节的内容放在更大范围的内存当中(int), 此时读到的byte(-128到127)范围内的值就可以在int范围内表示为0到255这样的值, 此时返回-1就表示读到了文件的末尾了.
FileReader的构造方法:
| 方法 | 解释 |
|---|---|
| FileReader(File file) | 创建字符输人流与源文件对象接通 |
| FileReader(File file,Charset charset) | 创建字符输人流与源文件对象接通,指定字符集 |
| FileReader(String fileName) | 创建字符输人流与源文件路径接通 |
| FileReader(String fileName,Charset charset) | 创建字符输人流与源文件路径接通,指定字符集 |
Reader读文件涉及的方法:
| 返回值 | 方法 | 解释 |
|---|---|---|
| int | read() | 读取一个字符的数据, 返回值就是读取到的字符值, 返回-1代表已经完全读完了 |
| int | read(char[] b) | 最多读取 b.length 个字符的数据到 b 中, 返回实际读到的字符数; -1 代表以及读完了, b是输出型参数 |
| int | read(char[] b, int off, int len) | 最多读取 len - off 个字符的数据到 b 中, 放在从 off 开始,返回实际读到的字符数, -1 代表已经读完了 |
| void | close() | 关闭字节流 |
字符流无参版本的read()返值设置值为int的原因和字节流是类似的.
代码示例:
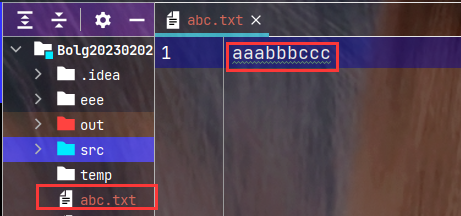
项目所在的工作目录下有一个abc.txt的文本文件, 该文件中有9个字母aaabbbccc, 使用一个缓冲数组接收数据, 使用字节流对象读取, 得到的结果就是它们的Unicode码值(Unicode码中包含ASCll码), 如果要去验证对照, 首先要知道你使用的编译器是按照什么样的方式编码, 然后再去对应码表查询对照, IDEA默认是utf8(utf8是Unicode的实现方式之一), 如果你这里的文件是其他编码, 比如gbk, 就需要去和abk码表去对照, 使用字符流对象读取, 得到的就是文件中的字符.
要注意理解下面代码中read方法的使用, 参数是一个数组, 这就需要我们提前准备好一个缓冲数组, 把这个数组传入read方法, 让read方法内部针对这个数组进行填充, read会尽可能的把参数传进来的数组给填满, 然后我们需要对数组中读到的内容进行处理, 如果文件内容没读完的话就循环进行读取再次将数据填充到数组中(会覆盖上一次读取的内容).
而这个缓冲数组存在的意义是为了提高IO操作的效率, 因为访问硬盘/IO设备都是比较耗时的, 而缓冲数组的存在降低了IO的次数.
import java.io.*;
public class TestDemo5 {
public static void main(String[] args) {
try {
//以字节为单位读取
InputStream inputStream = new FileInputStream("./abc.txt");
//以字符为单位读取
Reader reader = new FileReader("./abc.txt");
//字节流
while (true) {
byte[] bytes = new byte[1024];
int len = inputStream.read(bytes);
if (len == -1) {
break;
}
for (int i = 0; i < len; i++) {
System.out.print(bytes[i] + " ");
}
}
//关闭文件
inputStream.close();
System.out.println();
//字符流
while (true) {
char[] chars = new char[1024];
int len = reader.read(chars);
if (len == -1) break;
for (int i = 0; i < len; i++) {
System.out.print(chars[i] + " ");
}
}
//关闭文件
reader.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
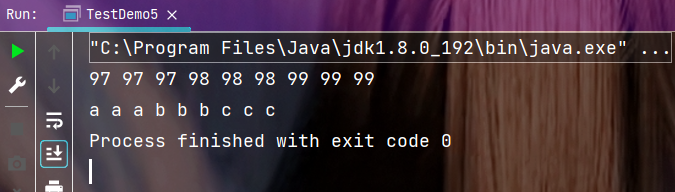
执行结果:
观察结果, 虽说字节流和字符流都可以读取文件内容, 但使用字符流读到的内容明显更直观一些.
文件读取完之后, 要记得关闭文件资源, 在上面的写法中有个问题是如果读取时发生异常就无法及时关闭文件了, 为了能够及时的关闭资源, 我们可以使用finally这个语法, 但更推荐下面的这种写法吗将读写对象定义在try中, 当try代码块执行完毕后会自动执行close关闭文件资源.
import java.io.*;
public class TestDemo6 {
public static void main(String[] args) {
//字节流
try (InputStream inputStream = new FileInputStream("./abc.txt")) {
while (true) {
byte[] bytes = new byte[1024];
int len = inputStream.read(bytes);
if (len == -1) {
break;
}
for (int i = 0; i < len; i++) {
System.out.print(bytes[i] + " ");
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println();
//字符流
try (Reader reader = new FileReader("./abc.txt");) {
while (true) {
char[] chars = new char[1024];
int len = reader.read(chars);
if (len == -1) {
break;
}
for (int i = 0; i < len; i++) {
System.out.print(chars[i] + " ");
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
但注意并不是随便拿个对象放到try中都可以自动释放资源的, 只有实现了Closeable接口的类才能放到try中去释放, Closeable接口中提供的就是close方法.
3. 文件的写操作
🍂接下来看写文件的操作, 写文件涉及到的抽象类和实现类有, 字节流: OutputStream, FileOutputStream, 字符流: Writer, FileWriter.
FileOutputStream的构造方法:
| 方法 | 解释 |
|---|---|
| FileInputStream(File file) | 利用 File 构造文件输入流 |
| FileInputStream(String name) | 利用文件路径构造文件输入流 |
| FileOutputStream(String filepath) | 创建字节输出流与源文件路径接通 |
| FileOutputStream((String filepath),boolean append) | 创建字节输出流与源文件路径接通,可追加数据 |
OutputStream写文件涉及的方法:
| 返回值 | 方法 | 解释 |
|---|---|---|
| void | write(int b) | 写入一个字节的数据 |
| void | write(byte[] b) | 将 b 这个字节数组中的数据全部写入 os 中 |
| int | write(byte[] b, int off, int len) | 将 b 这个字节数组中从 off 开始的数据写入 os 中,一共写 len 个 |
| void | close() | 关闭字节流 |
| void | flush() | 刷新缓冲区 |
FileWriter的构造方法:
| 方法 | 解释 |
|---|---|
| FileWriter(File file) | 创建字符输出流管道与源文件对象接通 |
| FileWriter(File file,boolean append) | 创建字符输出流管道与源文件接通,可追加数据 |
| FileWriter(String filepath) | 创建字符输出流管道与源文件路径接通 |
| FileWriter(String filepath,boolean append) | 创建字符输出流管道与源文件路径接通,可追加数据 |
Writer写文件涉及的方法:
| 返回值 | 方法 | 解释 |
|---|---|---|
| void | write(int b) | 写入一个字符的数据 |
| void | write(char[] b) | 将 b 这个字符数组中的数据全部写入 os 中 |
| int | write(char[] b, int off, int len) | 将 b 这个字符数组中从 off 开始的数据写入 os 中,一共写 len 个 |
| void | close() | 关闭字符流 |
| void | flush() | 刷新缓冲区 |
对于FileOutputStream和FileWriter, 默认会打开路径指向的文件, 如果没有对应路径的普通文件, 就会自动创建, 并且会清空文件里面原有内容再进行写入, 如果实现的效果是追加, 就需要设置构造方法中的append参数为true.
重要: 我们知道 I/O 的速度是很慢的, 所以, 大多的OutputStream为了减少设备操作的次数, 在写数据的时候都会将数据先暂时写入内存的一个指定区域里, 直到该区域满了或者其他指定条件时才真正将数据写入设备中, 这个区域一般称为缓冲区; 但造成一个结果, 就是我们写的数据, 很可能会遗留一部分在缓冲区中; 需要在最后或者合适的位置, 调用flush(刷新缓冲区)操作, 将数据刷到设备中, 当然close操作也会触发缓冲区的刷新.
代码示例:
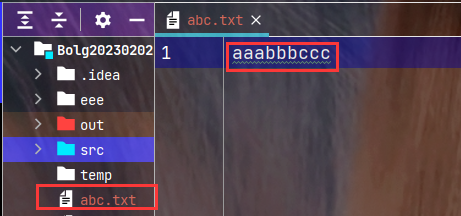
向工作目录下的abc.txt文件中使用字节流追加写入一个helloworld1, 使用字符流追加写入一个helloworld2.
import java.io.*;
public class TestDemo7 {
public static void main(String[] args) {
//字节流
try (OutputStream outputStream = new FileOutputStream("./abc.txt", true);) {
String str = " hellowold1";
//需要将字符串转化为字节数组
outputStream.write(str.getBytes());
} catch (IOException e) {
e.printStackTrace();
}
//字符流
try (Writer writer = new FileWriter("./abc.txt", true);) {
writer.write(" helloworld2");
} catch (IOException e) {
e.printStackTrace();
}
}
}
执行结果:
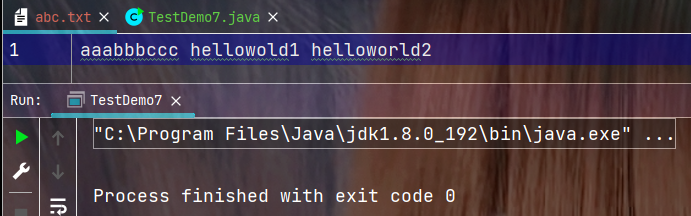
4. Scanner搭配流对象进行读取
首先看一个我们平时常见的一行代码, 这里的System.in其实就是一个输入流对象.

那么我们可以将构造参数传入为一个InputStream, 此时就可以使用Scannner从文件中进行读取了.
代码示例:
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.Scanner;
public class TestDemo8 {
public static void main(String[] args) {
try (InputStream inputStream = new FileInputStream("./abc.txt")) {
Scanner scanner = new Scanner(inputStream);
//此时就是从文件中读取内容了
while (scanner.hasNext()) {
String str = scanner.next();
System.out.println(str);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
执行结果:
5. PrintStream和PrintWriter
PrintStream字节打印流是, PrintWriter是字符打印流, 一般使用的是PrintWriter, 灵活性更强.
打印流只有输出流, 没有输入流, 主要用于写入, 会把信息写到指定的一个位置(显示器或文件等).
构造方法:
| 方法 | 解释 |
|---|---|
| PrintStream(File file) / PrintWriter(File file) | 传入一个一个File对象 |
| PrintStream(OutputStream out) / PrintWriterPrintStream | 传入一个输出流 |
| PrintStream(OutputStream out, boolean autoFlush) / PrintWriter(Writer out, boolean autoFlush) | 传入一个输出流, autoFlush 表示是否自动刷新 |
| PrintStream(String fileName, String csn) / 传入文件路径和文件编码 | 传入的是文件路径和字符编码 |
PrintWriter和PrintStream类中提供了我们熟悉的print/println/printf方法, 相当于是将OutputStream重新包装了一下, 可以更方便的输出数据.
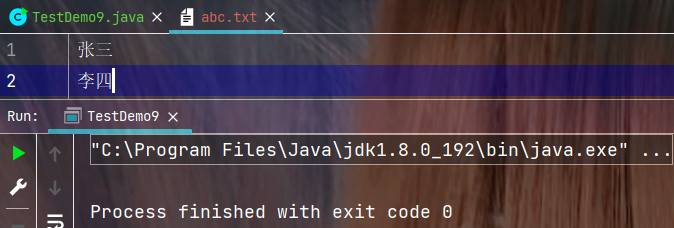
代码示例:
要注意使用使用PrintWriter必须刷新缓冲区才能将数据成功写入文件.
import java.io.*;
public class TestDemo9 {
public static void main(String[] args) throws IOException {
//字节流
try (OutputStream outputStream = new FileOutputStream("./abc.txt");) {
PrintStream printStream = new PrintStream(outputStream);
PrintWriter printWriter = new PrintWriter(outputStream);
printStream.println("张三");
printWriter.print("李四");
//使用PrintWriter必须刷新缓冲区才能将数据写入文件
printWriter.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}
执行结果:
6. 补充: 为什么使用后一定要关闭文件资源
上面提到过, 文件读写结束后一定要记得使用close方法关闭文件资源, 那么这是为什么呢?
我们知道进程在操作系统内核中是使用PCB这样的数据结构来表示的, 一个线程对应一个PCB, 一个进程可以对应一个PCB, 也可以对应多个, PCB中有一个重要的属性是文件描述符表(相当于是一个数组)记录了该进程打开了哪些文件, 进程中的这些PCB是共用一个文件描述符表的.
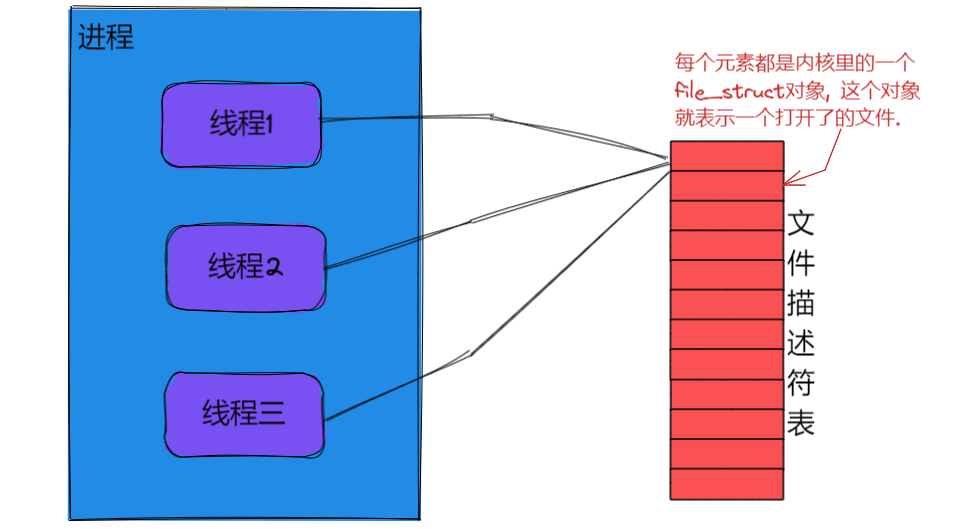
每次打开一个文件就在文件描述符表中申请一个位置把, 把代表这个文件的对象放进去, 每次关闭文件时, 就会把文件描述符表的中对应位置的内容释放掉.
要知道文件描述符表是有大小是存在上限的(最大长度在不同系统上都不太一样, 基本就是几百到几千左右), 在文件资源不在使用的时候, 如果不能及时的释放, 那么就意味着文件描述符表可能很快就被占满了, 就会导致之后再想要打开文件资源的时候就会打开失败.
那Java当中不是有GC垃圾回收机制吗? 这里为啥还需要我们手动来释放资源, 要注意, GC操作会在回收流对象的时候去完成释放资源的操作, 但GC的这个回收时间不是即时的, 释放的可能就不是那么及时, 所以使用close方法去即时使用, 即时的手动释放是最合适的做法.
四. 文件操作案例
1. 扫描指定文件并根据文件名删除指定普通文件
🍂实现要求:
用户给定一个指定目录和一个要删除的文件, 查看给定目录中是否包含要删除的文件, 找到以后让用户选择是否要删除这个文件.
🍂实现思路:
我们知道文件的组织结构是多叉树的树形结构, 我们根据给定目录要去扫描目录及子目录下是否有匹配的结果, 这里的扫描无非就是多叉树的遍历, 和二叉树的遍历是类似的, 这里是基于多叉树的前序遍历来实现的.
import java.io.File;
import java.util.Scanner;
/**
* 扫描指定目录,判断指定目录中是否包含指定文件,
* 如果包含,让用户选择是否删除文件
*/
public class TestDemo9 {
private static Scanner scanner = new Scanner(System.in);
public static void main(String[] args) {
//首先输入一个指定的搜索目录
System.out.println("请输入要搜索的路径: ");
String basePath = scanner.next();
//判断路径是否存在
File root = new File(basePath);
//判断路径是否是一个目录
if (!root.isDirectory()) {
//路径不存在,或者是一个普通文件,无法进行搜索
System.out.println("输入的路径有误!");
}
//再输入一个要删除的文件名
System.out.println("请输入一个要删除的文件名: ");
String namrToDelete = scanner.next();
//递归搜索路径和文件
// 先从根目录出发(root)
// 首先判定当前目录中是否存在要删除的文件,包含结束递归进行删除
// 如果当前目录中还包含了其他子目录,再针对子目录进行递归
scanDir(root, namrToDelete);
}
private static void scanDir(File root, String namrToDelete) {
// 1. 先列出 root 目录下的文件和目录
File[] files = root.listFiles();
if (files == null) {
// root目录是一个空目录,结束递归
return;
}
// 2. 遍历当前列出的结果
for (File file : files) {
if (file.isDirectory()) {
// 如果是目录,继续递归
scanDir(file, namrToDelete);
} else {
// 如果是普通文件,判断是否要删除的文件
if (file.getName().contains(namrToDelete)) {
//选择是否要删除
System.out.println("确认是否要删除 " + file.getAbsolutePath() + " 吗? Y(y)/N(n)");
String choice = scanner.next();
if (choice.equals("y") || choice.equals("Y")) {
file.delete();
System.out.println("删除成功!");
} else {
System.out.println("删除取消!");
}
}
}
}
}
}
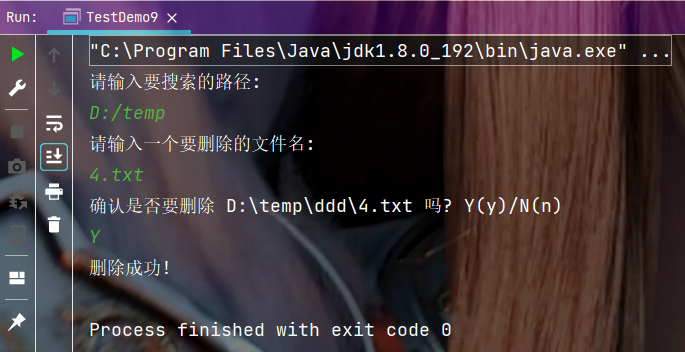
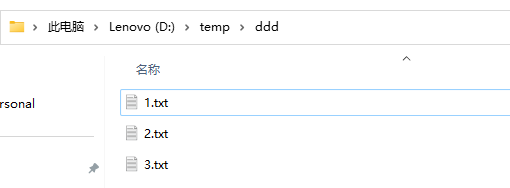
🍂程序测试:
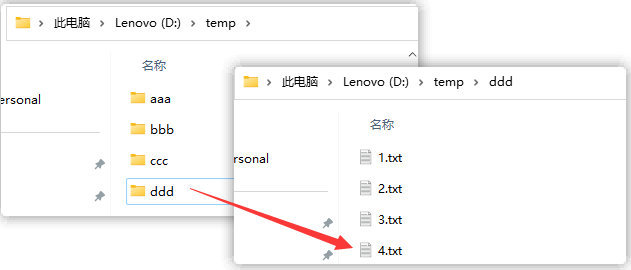
- 注意: 我们现在的方案性能较差, 所以尽量不要在太复杂的目录下或者大文件下实验.
现在测试将如下目录中的4.txt文件删除
🍂执行结果:
2. 普通文件的复制
文件的复制需要知道源路径和目标路径, 而给出源路径指向的必须是一个普通文件, 然后就读取源路径的文件, 将读到的数据写入到目标文件路径下即可.
import java.io.*;
import java.util.Scanner;
/**
* 普通文件的复制
*/
public class TestDemo10 {
public static void main(String[] args) {
// 输入两个路径
// 从哪里(源路径)拷贝到哪里(目标路径)
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要拷贝源文件的路径: ");
String srcPath = scanner.next();
System.out.println("请输入要拷贝到的目标路径: ");
String destPath = scanner.next();
File srcFile = new File(srcPath);
if (!srcFile.isFile()) {
//如果不是一个文件(或者是个目录/不存在)
System.out.println("您当前输入的源文件的路径有误!");
return;
}
File destFile = new File(destPath);
if (destFile.isFile()) {
//如果该文件已经存在,也不能进行拷贝
System.out.println("您输入的目标路径有误");
return;
}
//完成拷贝操作
try (InputStream inputStream = new FileInputStream(srcFile);
OutputStream outputStream = new FileOutputStream(destFile)) {
byte[] buffer = new byte[1024];
while (true) {
int b = inputStream.read(buffer);
if (b == -1) {
break;
}
outputStream.write(buffer);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
🍂程序测试:
有如下两个目录, 第一目录是源目录, 其中有一图片, 第二目录是目标目录, 里面是什么都没有, 这里测试将源目录中的图片拷贝到目标中.
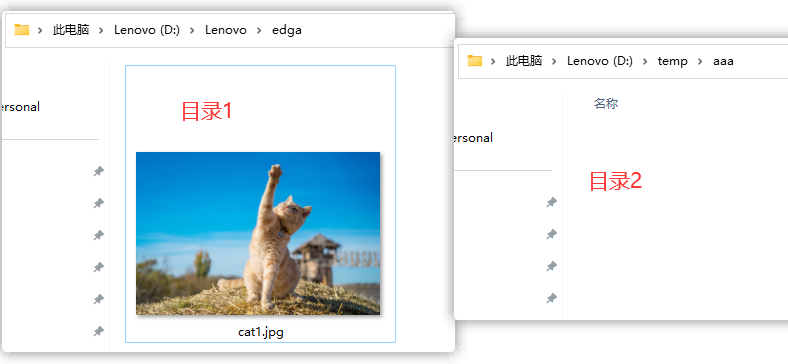
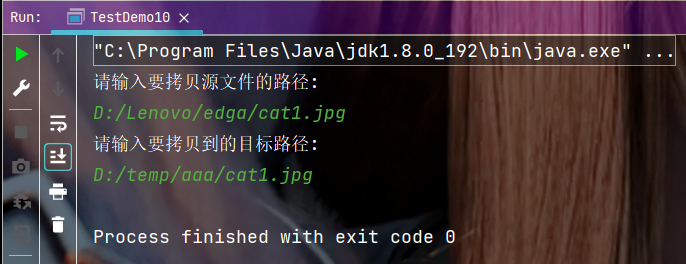
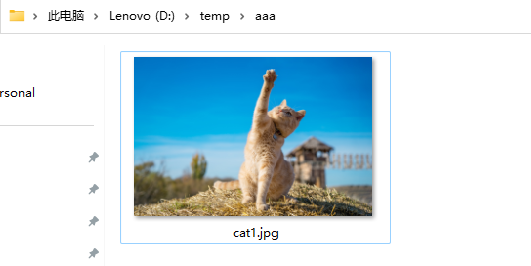
🍂执行结果:
3. 获取含有指定字符串的普通文件
🍂实现要求:
用户给定一个指定目录和字符串, 要求找到该目录下内所有文件内容含有该字符串的普通文件.
🍂实现思路:
其实这个案例相当于是上面两个案例的结合, 需要先对文件进行扫描, 找到其中的普通文件, 然后再去校验文件的内容中是否含有该字符串, 如果存在这样的文件, 则输出文件的路径.
import java.io.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
/**
* 扫描指定目录,查找文件内容中包含指定字符的所有普通文件
*/
public class TestDemo11 {
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(System.in);
//首先输入一个指定的搜索目录
System.out.println("请输入要搜索的路径: ");
String basePath = scanner.next();
//判断路径是否存在
File root = new File(basePath);
//判断路径是否是一个目录
if (!root.isDirectory()) {
//路径不存在,或者是一个普通文件,无法进行搜索
System.out.println("输入的路径有误!");
}
System.out.println("输入你所指定的要包含的字符");
String token = scanner.next();
List<File> result = new ArrayList<>();
scanDirWithContent(root, token, result);
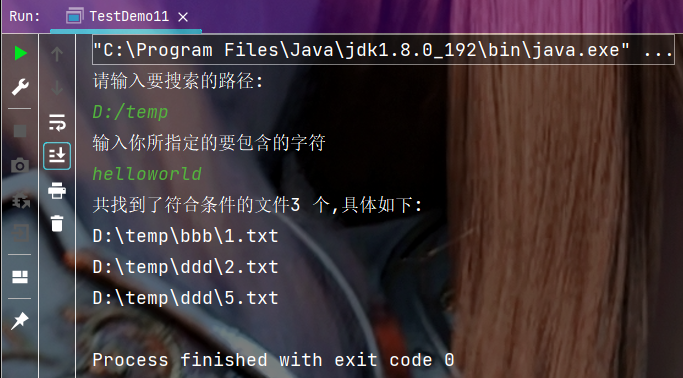
System.out.println("共找到了符合条件的文件" + result.size() + " 个,具体如下:");
for (File file : result) {
System.out.println(file.getCanonicalPath());
}
}
private static void scanDirWithContent(File root, String token, List<File> result) {
// 1. 先列出 root 目录下的文件和目录
File[] files = root.listFiles();
if (files == null) {
// root目录是一个空目录,结束递归
return;
}
// 2. 遍历当前列出的结果
for (File file : files) {
if (file.isDirectory()) {
// 如果是目录,继续递归
scanDirWithContent(file, token, result);
} else {
//判断该文件中是否包含指定字符
if(isContentContains(file, token)){
result.add(file.getAbsoluteFile());
}
}
}
}
private static boolean isContentContains(File file, String token) {
StringBuilder stringBuilder = new StringBuilder();
try (Reader reader = new FileReader(file)) {
while (true) {
char[] chars = new char[1024];
int len = reader.read(chars);
if (len == -1) {
break;
}
stringBuilder.append(chars, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
return stringBuilder.indexOf(token) != -1;
}
}
🍂程序测试:
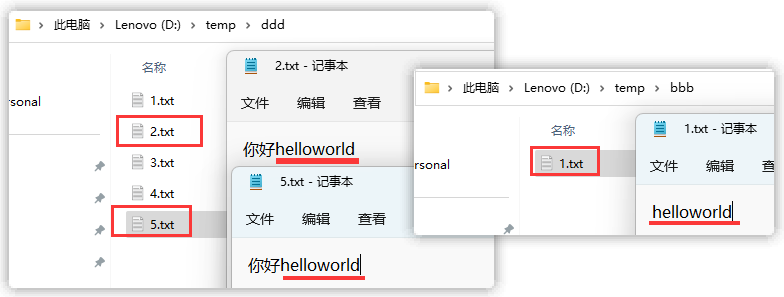
在如下目录中查找所有文件内容中包含字符串helloworld的普通文件.
🍂执行结果: