🌈欢迎来到Linux专栏~~ 深入理解文件系统
- (꒪ꇴ꒪(꒪ꇴ꒪ )🐣,我是Scort
- 目前状态:大三非科班啃C++中
- 🌍博客主页:张小姐的猫~江湖背景
- 快上车🚘,握好方向盘跟我有一起打天下嘞!
- 送给自己的一句鸡汤🤔:
- 🔥真正的大师永远怀着一颗学徒的心
- 作者水平很有限,如果发现错误,可在评论区指正,感谢🙏
- 🎉🎉欢迎持续关注!


深入理解文件系统
- 🌈欢迎来到Linux专栏~~ 深入理解文件系统
- 一. 答疑解惑
- 🌈close关闭fd之后文件内部没有数据
- 🌈stdout 和 stderr 区别
- 二 . 理解文件系统
- 🎨科普背景知识
- 🎨了解磁盘结构
- 🔵物理结构
- 🟡磁盘的存储结构
- 🟢磁盘的虚拟结构
- 🎨文件系统与inode
- 三 . 软硬链接
- 🌏软链接
- 🌏硬链接
- 📢写在最后

一. 答疑解惑
🌈close关闭fd之后文件内部没有数据
代码展示:
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<string.h>
int main()
{
close(1);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if(fd < 0)
{
perror("open");
return 0;
}
printf("hello world: %d\n", fd);//stdout -> 1
close(fd);
return 0;
}

发现运行和打印都没有打印出结果,而当我们fflush的时候才在文件中打印出来

看了上两篇博客的都应该游刃有余了
因为close(1),而printf()只向1中打印,此时的fd = 1。此时数据会暂存在stdout的缓冲区中,此时普通文件是全缓冲,遇到\n不会及时刷新。对应 的fd先关闭, 数据无法及时刷新了,而加了fflush会把数据直接刷新
🌈stdout 和 stderr 区别
#include<iostream>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
int main()
{
//stdout -> 1
printf("hello printf 1\n");
fprintf(stdout, "hello fprintf 1\n");
// stderr -> 2
perror("hello perror 2"); //stderr
const char *s1 = "hello write 1\n";
write(1, s1, strlen(s1));
const char *s2 = "hello write 2\n";
write(1, s2, strlen(s1));
//cout -> 1
std::cout << "hello cout 1" << std::endl;
//cout -> 2
std::cerr << "hello cerr 2" << std::endl;
return 0;
}
结果如下~
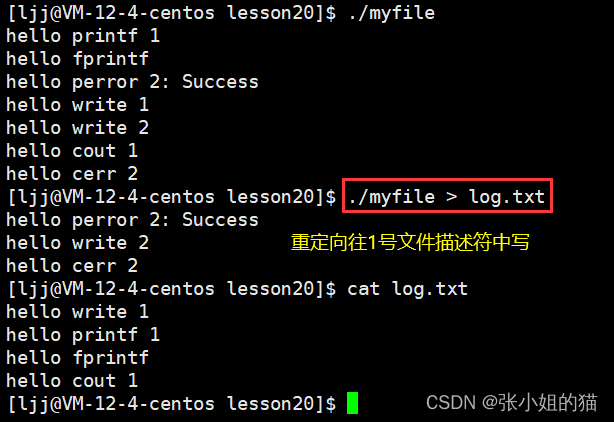
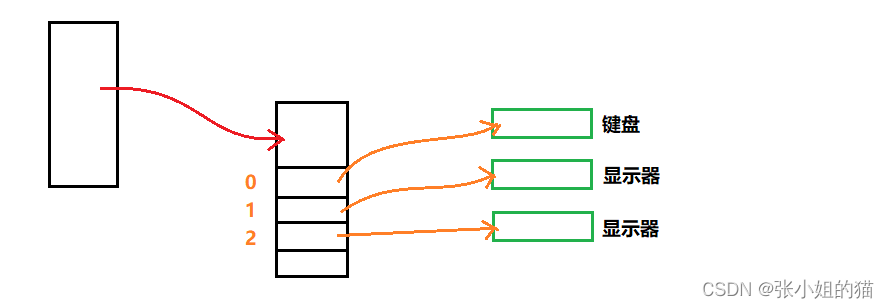
- 我们发现,重定向只对1号文件描述符有用;也就是正确信息被重定向
- 文件描述符 1 和 2 对应的都是显示器文件,但是题目两个是不同的,如同认为同一个显示器文件,被打开了两次
一般而言,如果程序运行有可能有问题的话,建议使用
stderr,或者cerr来打印
如果是常规的文本内容,我们建议进行cout 或 stdout 进行打印
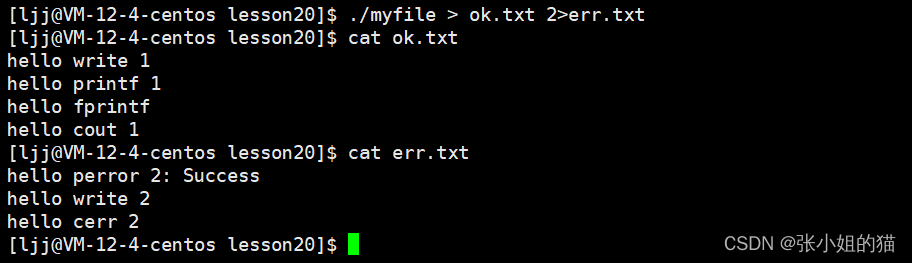
💦举例:常规信息和报错信息分开打印
正确的打印到ok.txt ,错误的打印到err.txt 也称错误重定向
./myfile 1 > log.txt 2 > err.txt
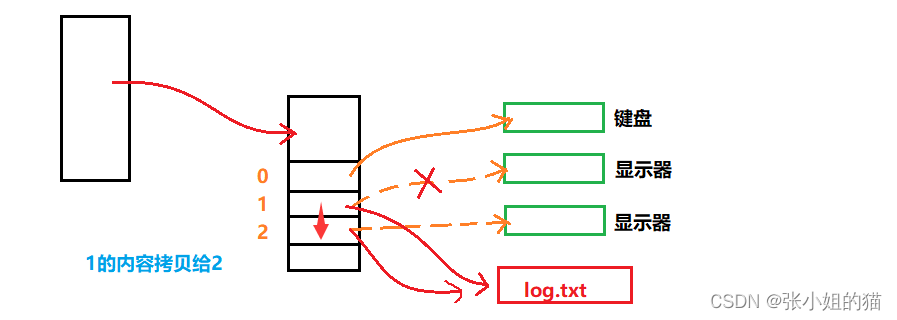
💦但如果我们像都打印在一个文件中呢?
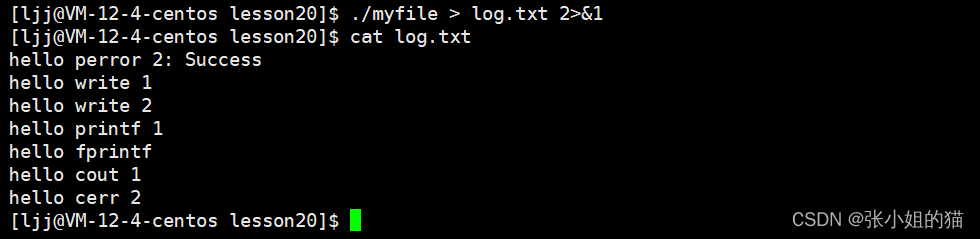
./myfile > log.txt 2>&1
💢先重定向,指向log.txt;把1的内容给2拷贝一份,最后1和2指向同一个文件
 结果还真的是
结果还真的是
还有一个骚操作也可以实现
cat < log.txt > back.txt//相当于拷贝
我们一个都见过这个errno(错误码)的吧
#include <errno.h>
RETURN VALUE
open() and creat() return the new file descriptor, or -1 if an error occurred (in which
case, errno is set appropriately).
如果打开成功,返回文件描述符,打开失败,errno被设置,所以perror会根据全局的错误码输出对应的错误原因
如果我们自己想设计一个perror
void myperror(const char *msg)
{
fprintf(stderr, "%s: %s\n", msg, strerror(errno));
}
此前已经删除了log.txt

二 . 理解文件系统
🎨科普背景知识
🥑有没有没有被打开的文件呢? 在哪里呢?
- 当然存在,在磁盘上
🥑我们学习磁盘级别的文件,我们的侧重点在哪?
- 单个文件角度 —— 这个文件在哪里?这个文件多大?这个文件的其他属性是什么?
- 站在系统角度 ——一共有多少个文件?各自属性在哪里?如何快速找到?还可以存储多少个文件
接下来我们来正式了解一下磁盘吧
- 内存 - 掉电易失存储介质
- 磁盘 - 永久性存储介质 还有: SSD(固态 贵!) 、U盘、flash卡、光盘、磁带
🎨了解磁盘结构
🔵物理结构
磁盘是一个外设 且是我们计算机中唯一的一个机械设备(相对而言很慢)
这个磁盘的盘片就像光盘一样,数据就在盘片上放着,只不过光盘是只读的,磁盘是可读可写的
光说有点抽象的,直接上图

盘面上要存储数据!(二进制) -> 但计算机只认识二进制 -> 二进制是两态 —> 我们想到磁铁也是两态的
- 向磁盘写入本质就是改变磁盘的正负性(磁头)
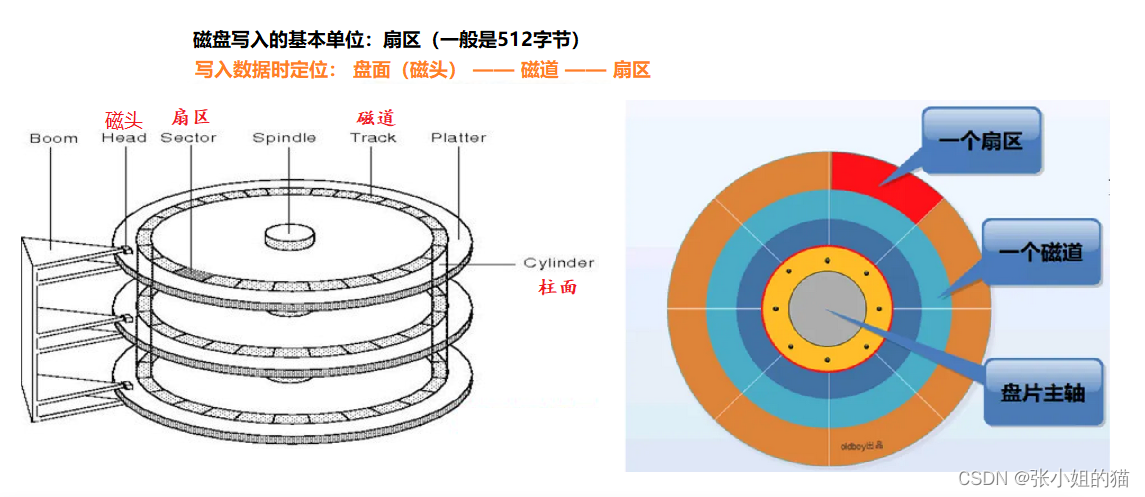
🟡磁盘的存储结构
机械硬盘的寻址的工作方式:盘片不断旋转,磁头不断摆动,定位到特定的扇区(面 — 磁道 — 扇区)
通过柱面Cylinder —— 磁头Head —— 扇区Sector 的寻址方法为CHS寻址
扇区的大小:512字节是硬件上的要求(外磁道和内磁道都是一样大小,密度不一样)
🟢磁盘的虚拟结构
类比磁带,我们可以把磁盘盘片想象成线性结构。
站在OS角度,我们就认为磁盘是线性结构,要访问某一扇区,就要定位数组下标LBA(logic block address);要写到物理磁盘上,就要把LBA地址转化成磁盘的三维地址(磁头,磁道,扇区)。这种关系类似于我们之前的虚拟地址空间和物理内存

所以:找到特定扇区的位置 ——> 找到数组特定的位置;对磁盘的管理——> 对数组的管理
🎨文件系统与inode
文件在磁盘上是如何被保存的?文件是在磁盘中的,而磁盘现在被我们想象成一个线性结构。
💜 磁盘空间很大,管理成本高。我们采用分治思维,类比管理我们的国家,我们分成好几个省份,再分成好几个市,最后轮到区。因此我们就对大磁盘 ——
1️⃣ 分区:大磁盘 → 小空间,化整为零
2️⃣ 格式化:给每个分区写入文件系统
所以理论上,我能把这100G的小空间管理好,其他空间就复刻我就好啦,因为硬件都是标品,当然了不同分区也可以写入不同的文件系统
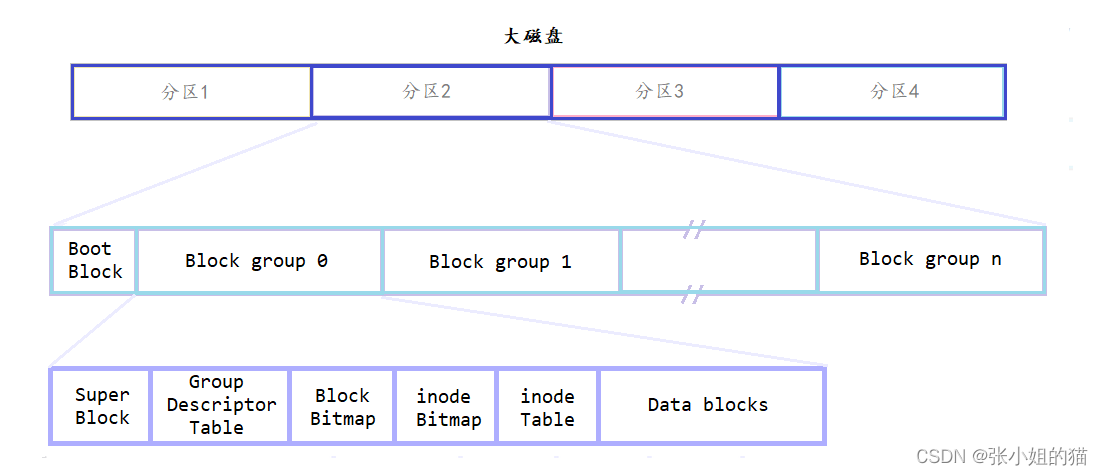
- boot block 存在于每个分区的开头,备份文件,是与启动相关的,供启动时查找分区
- 我们再把剩下的空间继续拆解分组,Block group 0 ,Block group 1 … 那么问题就又变成了如果我能管理好Block Group 0,就能管好1~n这些,因此研究文件系统又缩小范围了,就变成研究这一个Block Group 0
话不多说开始吧
虽然磁盘的基本单位是扇区(512字节),但是操作系统(文件系统)和磁盘进行IO的基本单位是4KB(8*512字节),4KB是block大小,所以磁盘被称为块设备
哪怕我们只想在磁盘上读取1字节,OS也必须直接读取4KB的数据
原因有两个:
- 512字节太小了,有可能导致多次IO,进而导致效率的降低
- 解耦合:如果操作系统使用和磁盘一样的大小,万一磁盘基本大小改变了,OS的源代码也要不要跟着改呢?硬件(磁盘)和软件(OS)进行解耦
逐个解释:
-
Super Block:文件系统的属性信息,整个分区属性的属性集(每个块组都有 防止磁盘被刮伤而找不到 文件属性) -
Data blocks:多个4KB(扇区*8)大小的集合,保存的都是特定文件的内容 -
inode Table:inode是一个大小为128字节的空间,保存的是对应文件的属性,该块组内,所有文件的inode空间的集合,需要标识唯一性,每一个inode块都要有一个inode编号!(一般而言,一个文件,一个inode,一个inode编号) -
BlockBitmap(位图):统计block的使用情况。假设有10000+个blocks,就有一一对应的比特位。其中比特位为1,代表该block被占用,否则表示可用 -
inode Bitmap:统计inode的使用情况,假设有10000+个inode,就有一一对应的比特位。其中比特位为1,代表该inode被占用,否则表示可用 -
GDT:块组描述符,已经使用了多少,有多少个inode,已经被占用了多少个,还剩下多少个,使用了多少
💥众所周知,文件 = 文件内容 + 文件属性,其中文件内容放在Data blocks中,属性放在inode Table中
inode内部保存了一个数组,保存了对应块的编号,二者关系就联系起来了
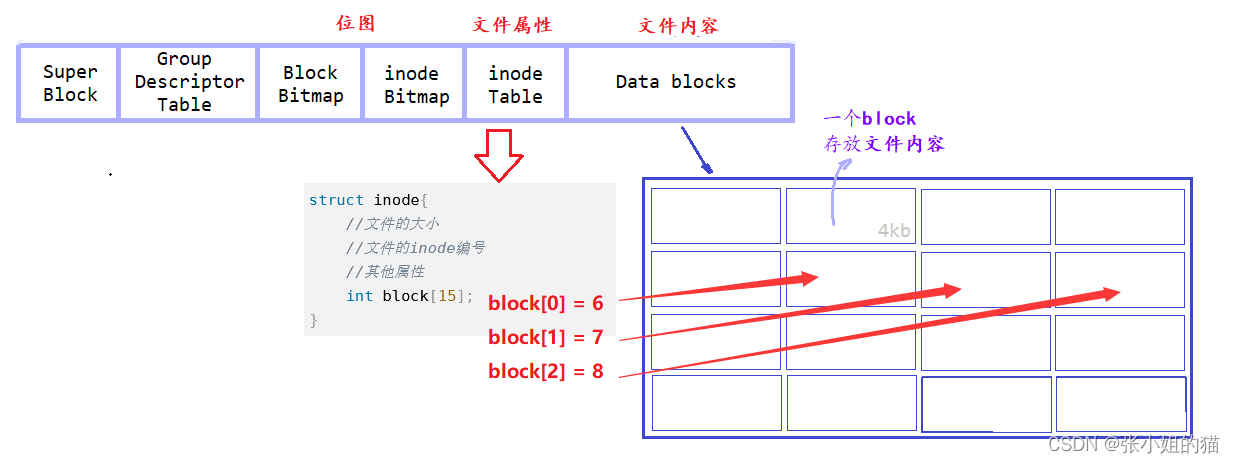 Linux中真正标识一个文件,是通过文件的
Linux中真正标识一个文件,是通过文件的inode编号,一个文件,一个inode(属性集合);一个inode也都有自己的编号。
那么要创建文件就要在inode Table中申请一个未被使用的inode,填入属性;文件中还有内容,inode还用数组存储了相关联的blocks块编号,我们可以简单地理解成 ——
struct inode{
//文件的大小
//文件的inode编号
//其他属性
int block[15];
}
⚡万一这个文件特别大呢? 怎么办?
不是所有的
data block只能存文件数据,也可以存其他块的块号
如果文件特别大,最后的block存的是其他block的块号,所以最后指向的是更多的block来存储
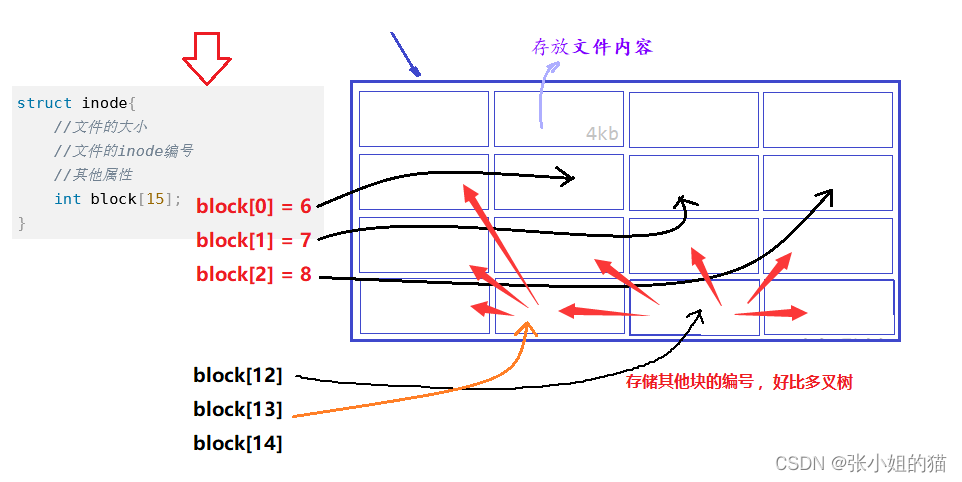
我们知道要找到文件:inode编号 —— 分区特定的block group —— inode —— 属性 —— 文件
🎨可是我们怎么知道inode呢?(Linux中,inode属性里面,没有文件名这样的说法)
预备知识:
- 一个目录下,是不是可以保存很多文件,但这些文件没有重复的文件名!
- 目录也算是文件,有自己的
inode(存的是目录的大小、权限、(链接数)、拥有者、所属组等)、有自己的data block(存的是文件名和inode的映射关系),因为文件名不存在于文件的inode里面
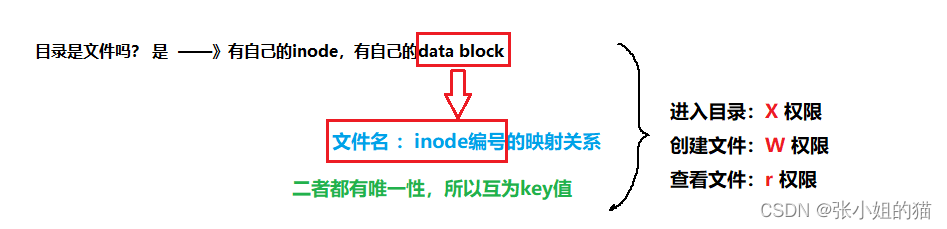
回答上面的问题:我们是依托目录文件来找到inode编号,因为目录的data block中保存了inode编号和文件名的映射关系,所以能找到文件名进而找到inode编号
💢灵魂多问:
- 目录下创建文件:遍历
inode Bitmap,位图中找0,申请一个未被使用的inode,随后便置1;向inode table中填入属性信息(权限、ACM时间)。并把这个映射关系(文件名是用户输入,inode是我们从文件系统申请得到的)写到当前目录的Data blocks中。

- 查看文件,根据目录inode找到与其映射的文件名 以及属性 全部打印
- 向文件写入:遍历block Map找到若干未被使用的块儿,将该文件的inode与这些blocks建立映射关系,再向blocks中写入内容。

- 查看文件内容:
cat hello.c→ 查看当前目录的data Blocks数据块儿 → 找到映射关系:文件名儿对应的inode编号 → 在inode Table中找到inode → 找到对应的blocks[] → 文件内容加在进内存中,在刷新到显示屏。 - 删除文件 :在目录的data block,用户提供的文件名,以文件名作为key值索引对应的
inode,在inode Bitmap中把对应的比特位置中由1置0;再根据属性把使用的数据块儿们也在Bitmap中把它由1置0。最后在目录的data block中,删除inode和文件名的映射关系。 - 所以拷贝一个文件需要一会儿,但是删除很快(因为不需要改文件的属性inode Table和数据data Blocks,标志文件无效即可,并不用覆盖)
( 如果你在Linux系统中,不小心rm -rf误删了文件,还能恢复!(前提是inode未被使用,inode和data block没有被占用)最好的做法就是什么也不做!找到你在windows下删除文件到回收站,其实只不过是转移了目录,在回收站中删掉才是相当于1置0了)
还有一个问题:位图一开始是不是要被操作系统全清0,那个区域要被分成inode table和super在什么位置 ?GDT是谁写的?inode table的128kb是谁划分的?
- 以上所有的信息都是:格式化 也就是写入文件系统(写入属性)
【面试题】:
🥗系统里还有空间,为什么创建文件老是失败:
- 因为inode是固定的,data block也是固定的。可能存在 inode还有,data block不够了;inode没有,data block还有的情况(特别少)
说了一大圈,最终为了引出我们的大boss
三 . 软硬链接
🌏软链接
🍤建立软链接
ln -s testLink.txt soft.link
💛 删除链接,可以rm,但是更建议
unlink soft.link
🔷什么时候会使用到软连接呢?
对于一些执行路径非常深的程序,我们不用每次都输入长长的路径,我们可以通过软链接快速找到它
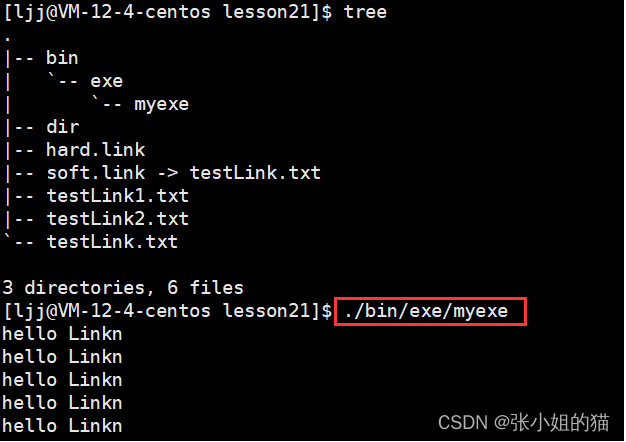
现在我不断回退,退到所谓工作目录上来,这时如果我还想运行test.sh就比较麻烦,那么我们就可以通过建立软链接的方式 ——
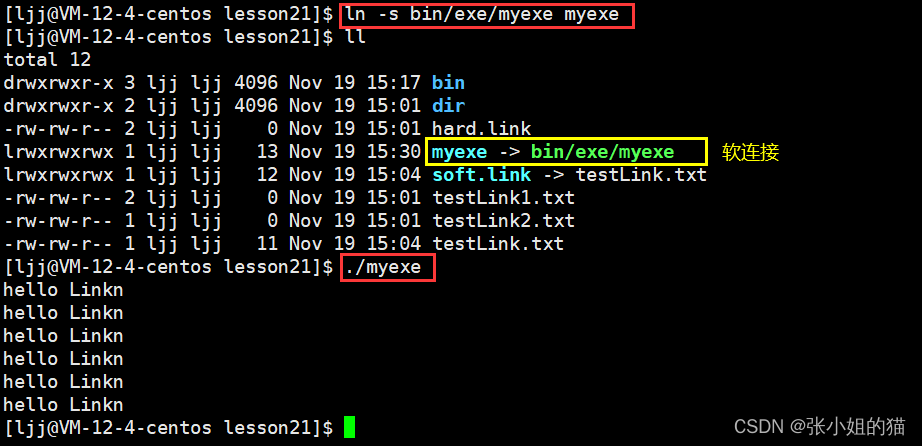
这相当于windows下创建的快捷方式
在系统路径下,也看见了大量了软链接的存在
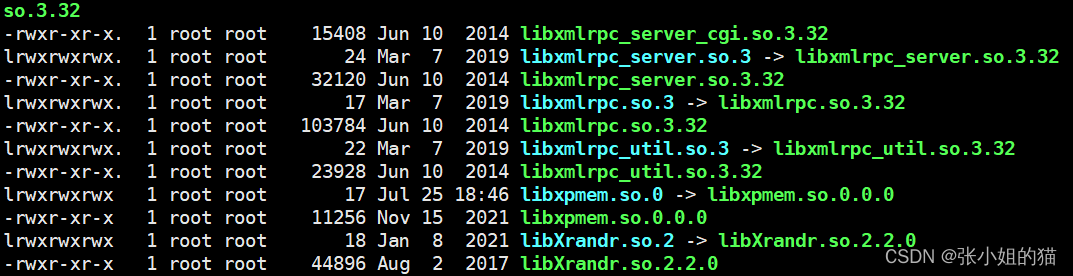
🌏硬链接
不带s就是硬链接
ln testLink1.txt hard.link
我们观察发现,软链接是有自己独立inode的,即软链接是一个独立文件!有自己的inode属性集也有自己的数据块儿 (保存的是它所指向文件的路径 + 文件名)
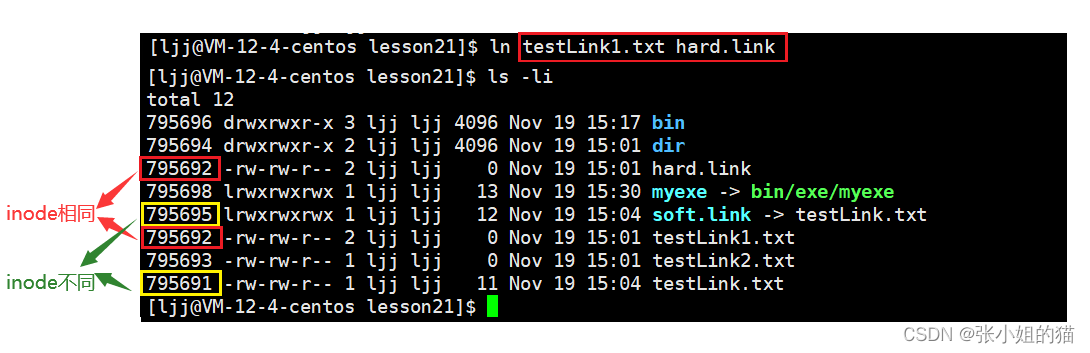 而硬链接自己没有独立的inode,用的是别人的inode;根本就不是一个独立的文件,说白了就起别名,其本质:在特定目录下,添加一个文件名和inode编号的映射关系,仅此而已
而硬链接自己没有独立的inode,用的是别人的inode;根本就不是一个独立的文件,说白了就起别名,其本质:在特定目录下,添加一个文件名和inode编号的映射关系,仅此而已
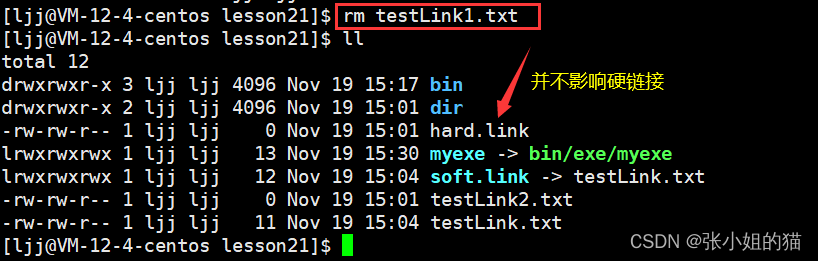
我们还发现在属性中有一个数字,1-> 2 ->1,这个数字就叫做硬链接数
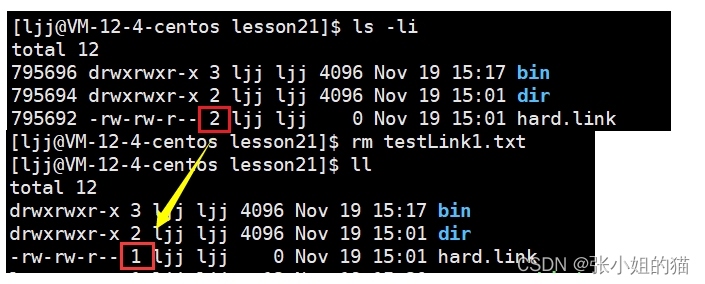
当我们删除一个文件的时候,并不是把这个文件inode删除,而是把inode引用计数--,当引用计数为0(没有文件名与之关联)的时候,这个文件才真正删除

🍤那么硬链接的使用场景呢?
为什么创建一个文件的时候,硬链接数是1?
- 因为自己的文件名就和inode就是一组映射关系
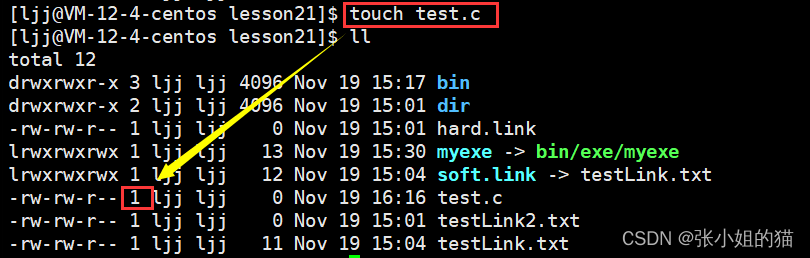
那为什么dir目录的硬链接数是2呢?
- 首先目录和自身的inode就是一组映射,第二个是目录内部的
.和inode 也是一组映射

在dir下又创建了d1目录,此处为什么dir的硬链接数变成3了?

因为d1的有..文件指向上级目录dir,所以硬链接数+1
总结:软硬连接的本质:有无独立的inode
📢写在最后
最近作业有点多,更新可能会慢一点