1、Mysql中的索引类型
(1)普通索引(2)唯一索引(3)主键索引(4)组合索引(5)全文索引
缺点
1、虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行insert、update和delete。因为更新表时,不仅要保存数据,还要保存一下索引文件。
2、建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会增长很快。索引只是提高效率的一个因素,如果有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句
2、回表
当对非主键字段建立了索引时,并且执行select * 操作就会先从B+树中拿到id,再去搜索id对应的数据,这个过程就叫做回表
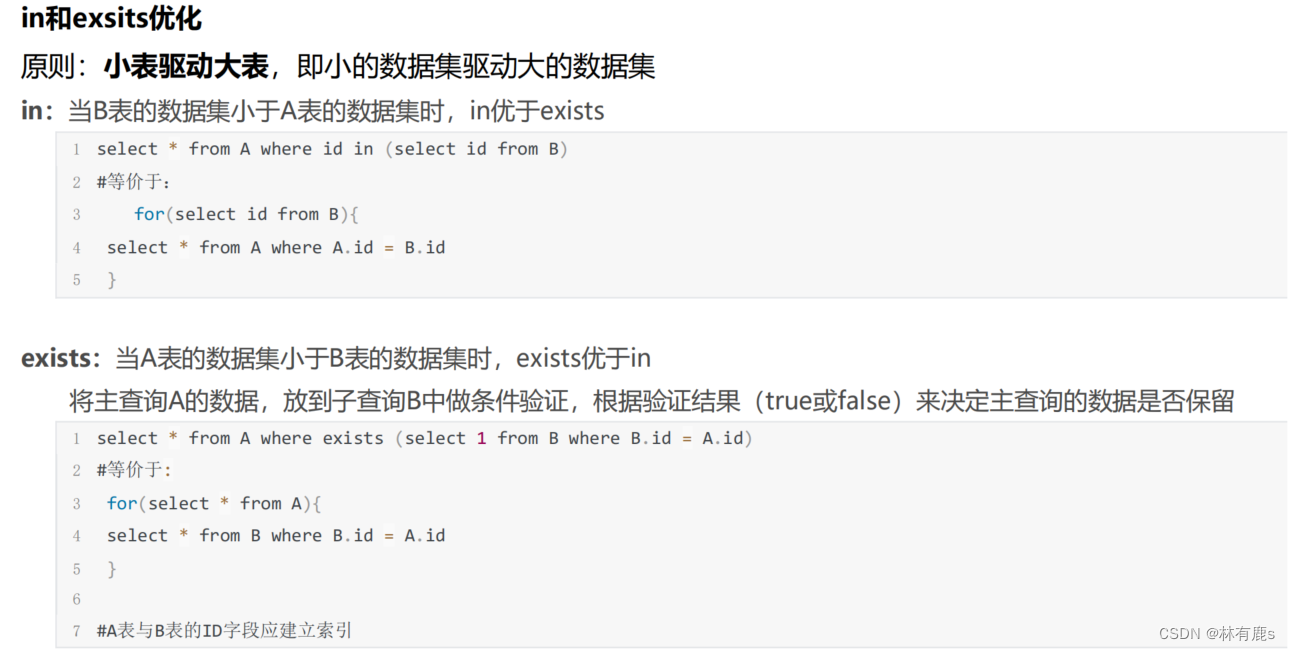
3、索引操作





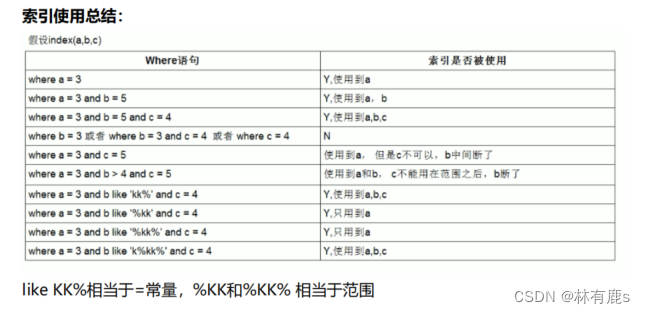
排序优化总结

分页查询优化
先让排序和分页操作走索引查出主键,然后根据主键查找对应的记录

关联查询优化





4、B树和B+树的区别
1)B树的每个结点都存储了key和data,B+树的data存储在叶子节点上。
节点不存储data,这样一个节点就可以存储更多的key。可以使得树更矮,所以IO操作次数更少。
2)树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录
由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
5、索引失效情况
七字口诀就是:
模 型 数 空 运 最 快
模:模糊查询的意思。like的模糊查询以%开头,索引失效。比如:
SELECT * FROM user WHERE name LIKE ‘%阿’;
型:代表数据类型。类型错误,如字段类型为varchar,where条件用number,索引也会失效。比如:
SELECT * FROM user WHERE height= 180;
height为varchar类型导致索引失效。
数:是函数的意思。对索引的字段使用内部函数,索引也会失效。这种情况下应该建立基于函数的索引。比如:
SELECT * FROM user WHERE DATE(create_time) = ‘2020-09-03’;
create_time字段设置索引,那就无法使用函数,否则索引失效。
空:是Null的意思。索引不存储空值,如果不限制索引列是not null,数据库会认为索引列有可能存在空值,所以不会按照索引进行计算。比如:
SELECT * FROM user WHERE address IS NULL不走索引。
SELECT * FROM user WHERE address IS NOT NULL;走索引。
建议大家这设计字段的时候,如果没有必要的要求必须为NULL,那么最好给个默认值空字符串,这可以解决很多后续的麻烦。
运:是运算的意思。对索引列进行(+,-,*,/,!, !=, <>)等运算,会导致索引失效。比如:
SELECT * FROM user WHERE age - 1 = 20;
最:是最左原则。在复合索引中索引列的顺序至关重要。如果不是按照索引的最左列开始查找,则无法使用索引。
快:全表扫描更快的意思。如果数据库预计使用全表扫描要比使用索引快,则不使用索引。
6、InnoDB和MYISAM的区别
(1)InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
(2)InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;
(3)InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的一个索引结构),必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。
MyISAM是非聚集索引,也是使用B+Tree作为索引结构,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
也就是说:InnoDB的B+树主键索引的叶子节点就是数据文件,辅助索引的叶子节点是主键的值;而MyISAM的B+树主键索引和辅助索引的叶子节点都是数据文件的地址指针。
(4) InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快
(5) InnoDB支持表、行(默认)级锁,而MyISAM支持表级锁
聚集索引和非聚集索引的区别
在 InnoDB 中,聚集索引 B+ 树的叶子节点中除了存放主键信息,还存放了主键对应的行数据,因此我们可以直接在聚集索引中查找到想要的数据
在 InnoDB 中,非聚集索引 B+ 树的叶子节点中存放了主键信息,当我们要查找数据时,需要先在非聚集索引中查找到对应的主键,然后再根据主键去聚集索引中查找到想要的数据
7、事务的ACID特性和隔离级别
ACID特性
原子性(Atomicity) :事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
一致性(Consistent) :在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性。
隔离性(Isolation) :数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
持久性(Durable) :事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
并发事务带来的问题
更新数据丢失或脏写:最后的更新覆盖了由其他事务所做的更新
脏读:事务A读取到了事务B已经修改但未提交的数据
不可重复读:事务A内部的相同查询语句在不同时刻读出来的结果不一致,不符合隔离性性
幻读:事务A读取到了事务B提交的新增数据,不符合隔离性
隔离级别
读未提交、读已提交、可重复读、串行化
可重复读的隔离级别下使用了MVCC(multi-version concurrency control)机制,select操作不会更新版本号,是快照读(历史版本);insert、update和delete会更新版本号,是当前读(当前版本)。
8、MySQL中的锁机制
从性能上分为乐观锁(用版本对比来实现)和悲观锁
从对数据库操作的类型分,分为读锁和写锁(都属于悲观锁)
读锁(共享锁,S锁(Shared)):针对同一份数据,多个读操作可以同时进行而不会互相影响
写锁(排它锁,X锁(eXclusive)):当前写操作没有完成前,它会阻断其他写锁和读锁
从对数据操作的粒度分,分为表锁和行锁
间隙锁,锁的就是两个值之间的空隙。范围更新会将行以及所在的间隙加锁,间隙锁是在可重复读隔离级别下才会生效。
锁主要是加在索引上,如果对非索引字段更新,行锁可能会变表锁。InnoDB的行锁是针对索引加的锁,不是针对记录加的锁。并且该索引不能失效,否则都会从行锁升级为表锁。
9、MVCC多版本并发控制机制
Mysql在读已提交和可重复读隔离级别下都实现了MVCC机制。
undo日志版本链与read view机制详解
undo日志版本链是指一行数据被多个事务依次修改过后,在每个事务修改完后,Mysql会保留修改前的数据undo回滚日志
在可重复读隔离级别,当事务开启,执行任何查询sql时会生成当前事务的一致性视图read-view,该视图在事务结束之前都不会变化(如果是读已提交隔离级别在每次执行查询sql时都会重新生成),该视图保存了所有未提交的事务id数组,判断某一行undo的事务id是否在视图数组中,若在则修改不可见。
10、binlog和redolog
对于一次写操作首先将数据加载到Buffer Pool缓存池,然后将数据写入undo日志文件,更新内存数据后写redolog,redolog记录的是数据变化,然后写binlog记录的是sql语句,最后将数据写入磁盘。
11、主从复制
Mysql主从优点
1、高性能方面,实现读写分离,不会因为写操作过长导致读服务不能进行的问题
2、可靠性方面:解决了单点故障问题,提高了系统的可靠性和稳定性
写性能瓶颈
可是使用分库分表,有垂直分表和水平分表
数据一致性问题
对于强一致性要求,采用同步复制策略,实现最终一致性采用异步复制策略