spark 内存管理
文章目录
- spark 内存管理
- spark 1.6 内存管理机制
- spark 2.0 内存管理机制
- spark 3.3.1 官方文档
- spark 内存相关参数调优
spark 1.6 内存管理机制
https://0x0fff.com/spark-memory-management
统一内存管理
Spark 1.6 之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域
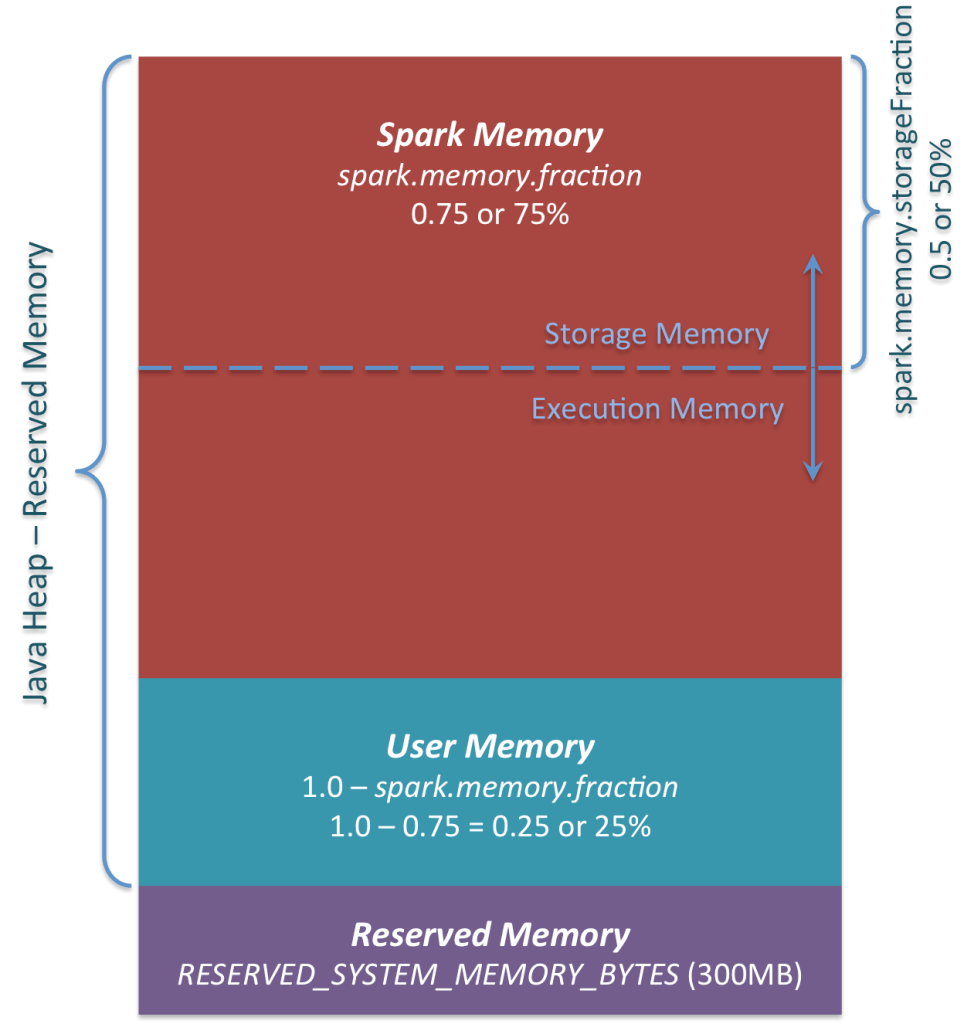
初始storage memory区域大小计算为“ Spark Memory”* spark.memory.storageFraction =(“ Java Heap ”-“ Reserved Memory ”)* spark.memory.fraction * spark.memory.storageFraction。对于默认值,这等于(“ Java 堆”– 300MB)* 0.75 * 0.5 =(“ Java 堆”– 300MB)* 0.375。对于 4GB 堆,这将在初始存储内存区域中产生 1423.5MB RAM
【注:spark 2.0+,默认spark.memory.fraction=0.6而不是0.75】
spark 2.0 内存管理机制
参考博客(好文!推荐)
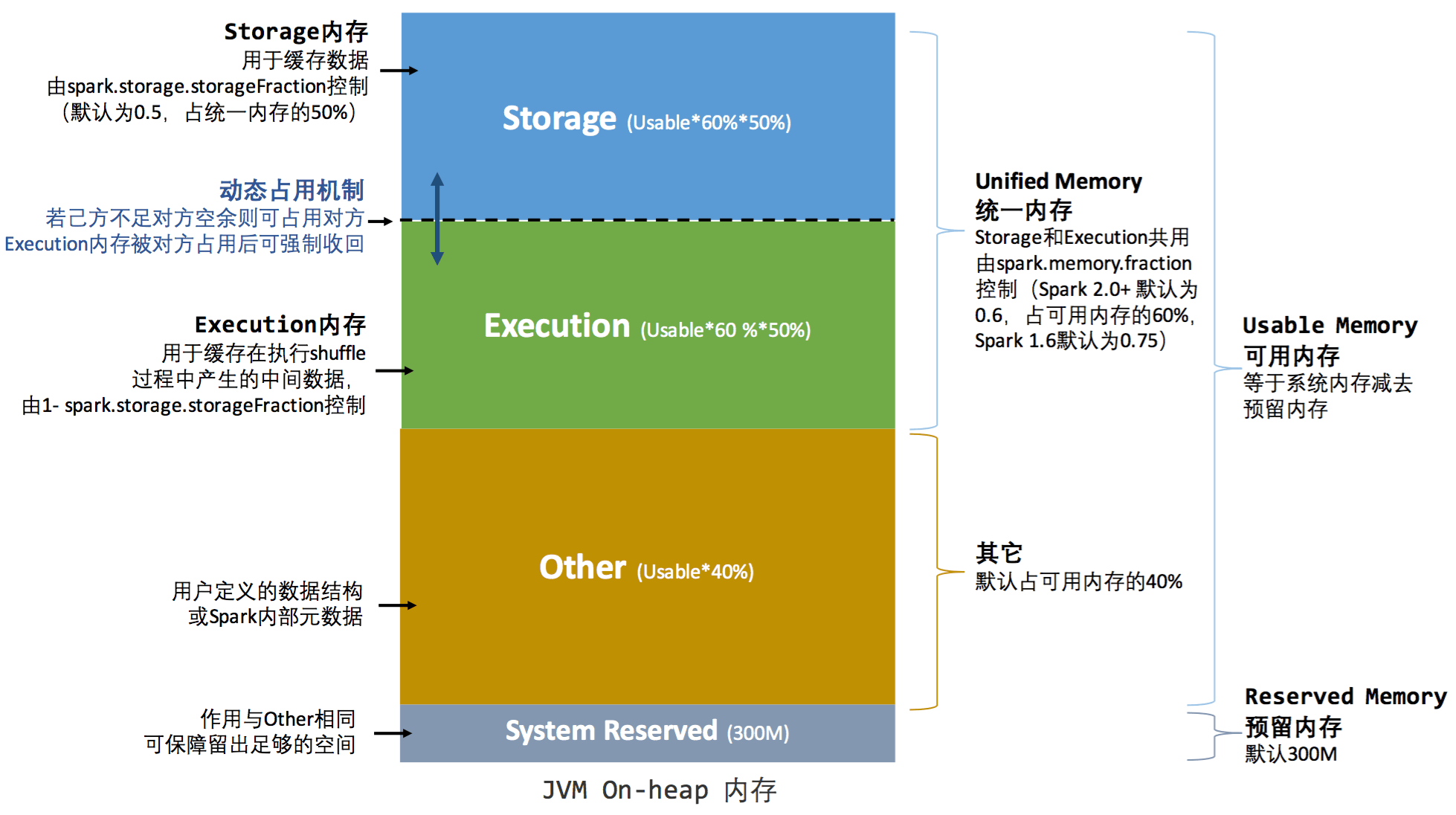
统一内存管理图示(堆内):
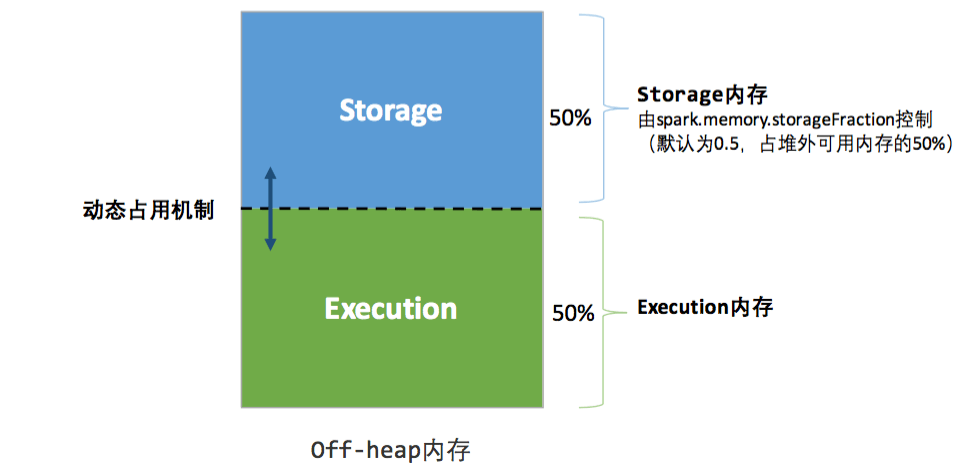
统一内存管理图示(堆外):
spark 3.3.1 官方文档
https://spark.apache.org/docs/latest/tuning.html#memory-management-overview
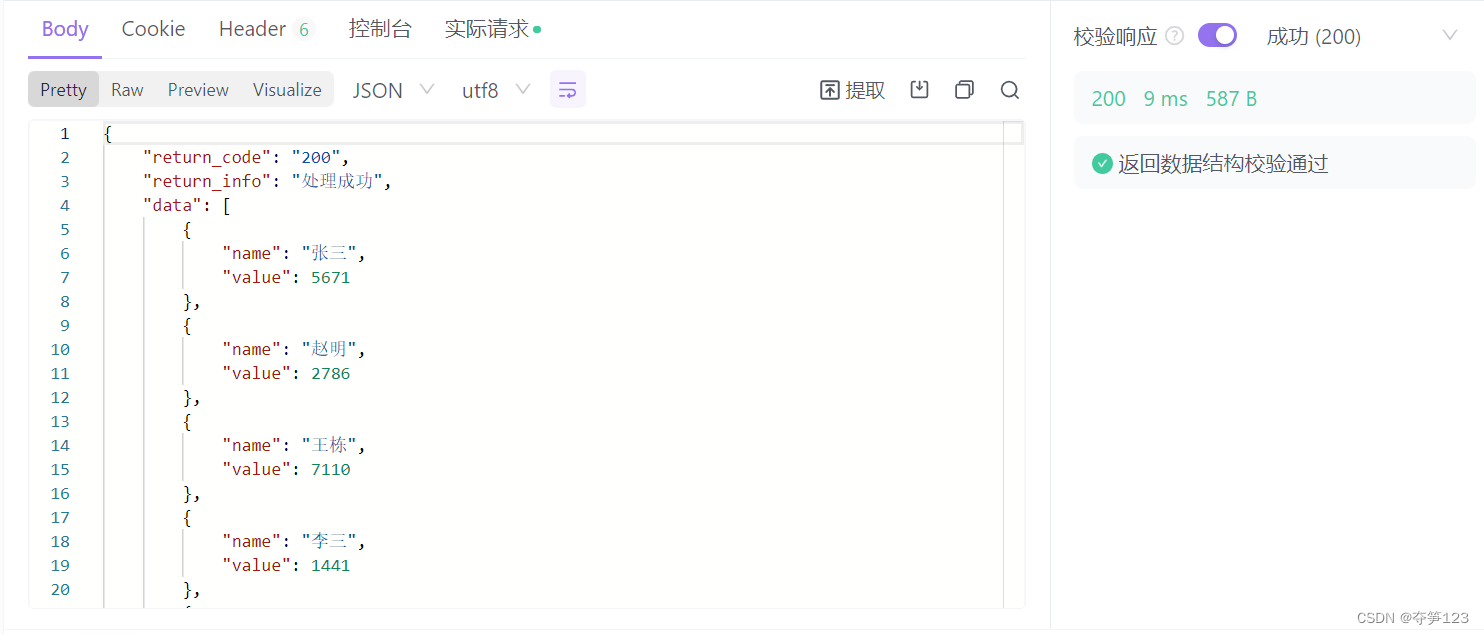
Spark 中的内存使用主要属于两类之一:执行和存储。执行内存是指用于洗牌(shuffle)、连接、排序和聚合中的计算,而存储内存是指用于在集群中缓存和传播内部数据的内存。在 Spark 中,执行和存储共享一个统一的区域(M)。当没有使用执行内存时,存储可以获得所有可用内存,反之亦然。如有必要,执行可能会逐出存储,但只有在总存储内存使用量低于某个阈值 ® 时才会执行。换句话说,R描述了M缓存块永远不会被驱逐的子区域。由于实现的复杂性,存储可能不会驱逐执行。
spark.memory.fraction将大小表示M为 (JVM 堆空间 - 300MiB) 的一小部分(默认 0.6)。其余空间 (40%) 保留用于用户数据结构、Spark 中的内部元数据,以及在稀疏和异常大的记录情况下防止 OOM 错误。spark.memory.storageFraction将大小表示R为分数M(默认为 0.5)。R是M缓存块免于被执行逐出的存储空间。
spark 内存相关参数调优
https://www.cnblogs.com/piaolingzxh/p/5428541.html
spark.storage.memoryFraction:很明显,是指spark缓存的大小,默认比例0.6
spark.shuffle.memoryFraction:管理executor中RDD和运行任务时的用于对象创建内存比例,默认0.2
关于这两个参数的设置,常见的一个场景就是操作关系数据库
spark 可以通过jdbc操作关系数据库,但是若是没有分散数据的依据,则将所有数据都读到driver节点上时,这时,强烈建议先看一下表的数据量和集群中对spark的内存设置参数
假设 executor memory 大小设置为2G,也就是说,spark.shuffle.memoryFraction可用内存为2G*0.2=400M,假设5W条数据大小为1M,也就是说可以读取400*50W=2000W条
当你在单节点上读取数据超过2000W而不能及时处理时,就有极大的可能oom
内存设置:
-
spark.shuffle.memoryFraction=0.4 #适当调高
-
spark.storage.memoryFraction=0.4 #适当调低