沉浸式 3D 场景下的多视点视频 增强算法研究
- 研究内容
- 图像质量增强
- 为什么进行图像质量增强
- 图像有损压缩技术
- 多视点视频中的深度图像特点
- 视点数目增强
- 虚拟视点合成技术
- 视点外推
- 为什么进行视点数目增强
- 主要贡献
- 基于自适应残差网络的多视点压缩深度图像增强算法
- 基于多约束编解码网络的多视点外推算法
- 虚拟视点合成
- 虚拟视点合成难点
- 传统的虚拟视点合成
- 基于深度学习的虚拟视点合成
- 基于自适应残差网络的多视点压缩深度图像增强算法
- 提出原因
- 实践依据
- 具体实践
- 网络结构
- 提出原因
- 实践依据
- 具体实践
- 自适应跳跃结构
- 实验结果
- 消融实验
- 深度图像主观结果
- 点云图像主观结果
- 基于多约束编解码网络的多视点外推算法
- 提出原因
- 多约束损失函数
- 像素约束
- 特征约束
- 边缘约束
- 实验结果
- 消融实验
- 扩展部分
- 基于深度学习的虚拟视点合成
- 物体虚拟视点合成
- 场景虚拟视点合成
- 展望
研究内容

文章针对三维场景中多视点视频进行图像质量增强与视点数目增强

图像质量增强
提出了一个基于自适应残差网络的多视点压缩深度图像增强算法。主要利用自适应的连接机制和更合理的训练策略来权衡多种先验信息得到增强结果
为什么进行图像质量增强
图像有损压缩技术
图像有损压缩技术节约数据传输的码率和带宽的同时,也带来模糊、结构缺失、混叠等压缩失真,影响相关应用的视觉质量和用户使用体验。
多视点视频中的深度图像特点
多视点视频中的深度图像因其缺少纹理,平滑区域很多的特点,在传输时的压缩率往往高于彩色图像,也就使得深度图像的压缩失真更严重。
视点数目增强
提出了一个基于多约束编解码网络的多视点外推算法。针对多视点外推任务,主要利用多视点相关性和边缘约束设计了深度学习方案
虚拟视点合成技术
受限于搭建复杂摄像机采集系统的人力物力成本,直接从环境中采集所有视点的多视点视频是不现实的。于是通过已采集的视点图像生成未采集的视点图像,即虚拟视点合成技术
视点外推
使用虚拟视点合成技术生成采集视点范围之外的视点,即视点外推。得到更大的视点范围供用户选择,从而进一步降低采集成本,提升用户体验。
为什么进行视点数目增强
- 多视点视频的运用可以生动地构建立体场景,为用户提供更好的浸入感与交互体验
- 受限于搭建复杂摄像机采集系统的人力物力成本,直接从环境中采集所有视点的多视点视频是不现实的。于是通过已采集的视点图像生成未采集的视点图像,即虚拟视点合成技术成为解决这一问题的方法之一
主要贡献

基于自适应残差网络的多视点压缩深度图像增强算法

基于多约束编解码网络的多视点外推算法

虚拟视点合成
虚拟视点合成难点
是对于原视点中被遮挡或不存在的部分,是难以在新视点中估计的,特别是虚拟视点在参考视点之外的视点外推任务中。
传统的虚拟视点合成
传统的虚拟视点合成多是采用基于深度的图像绘制方法,根据物体或场景的几何结构,对输入图像进行几何变换得到新视点的结果。
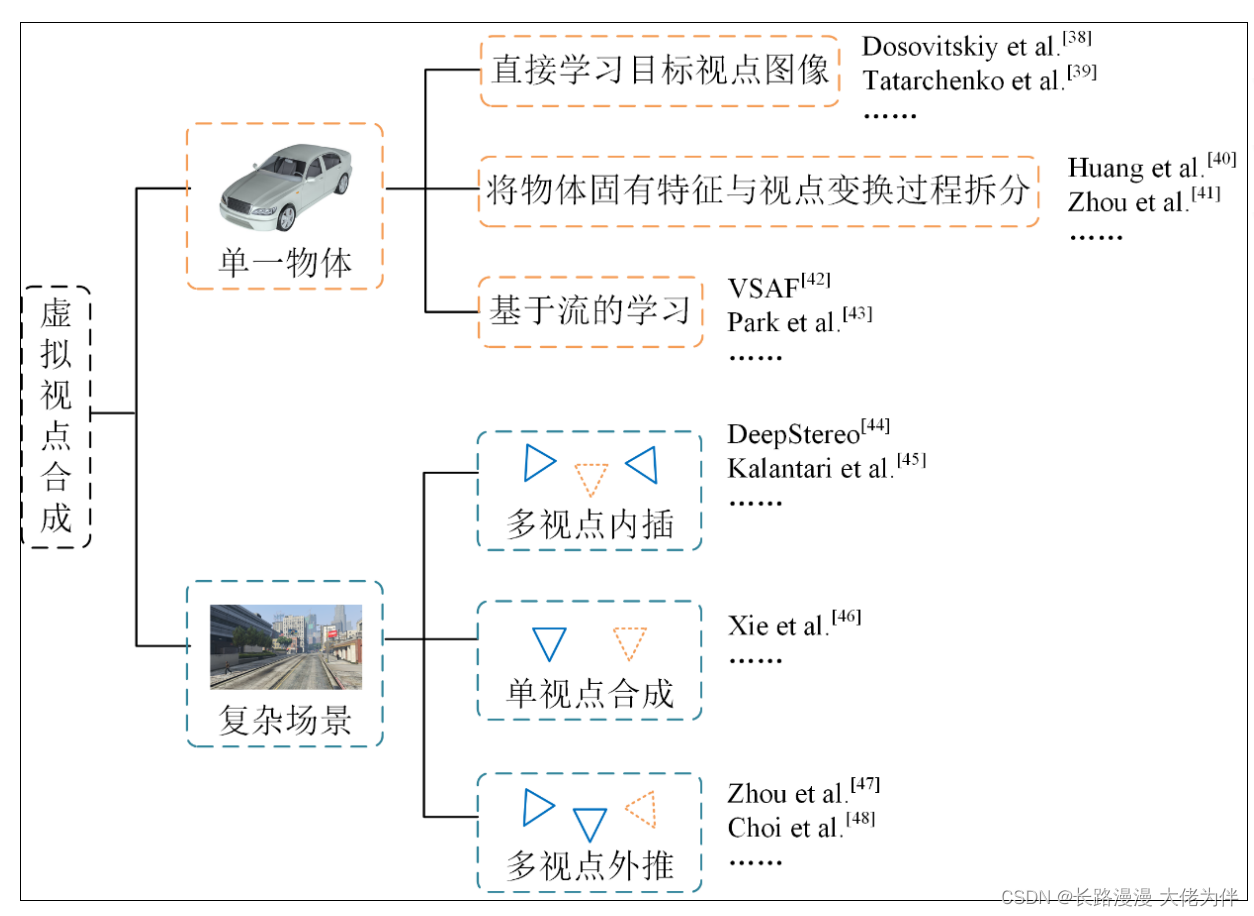
基于深度学习的虚拟视点合成
根据合成对象可分为物体与场景两类。详细见扩展部分
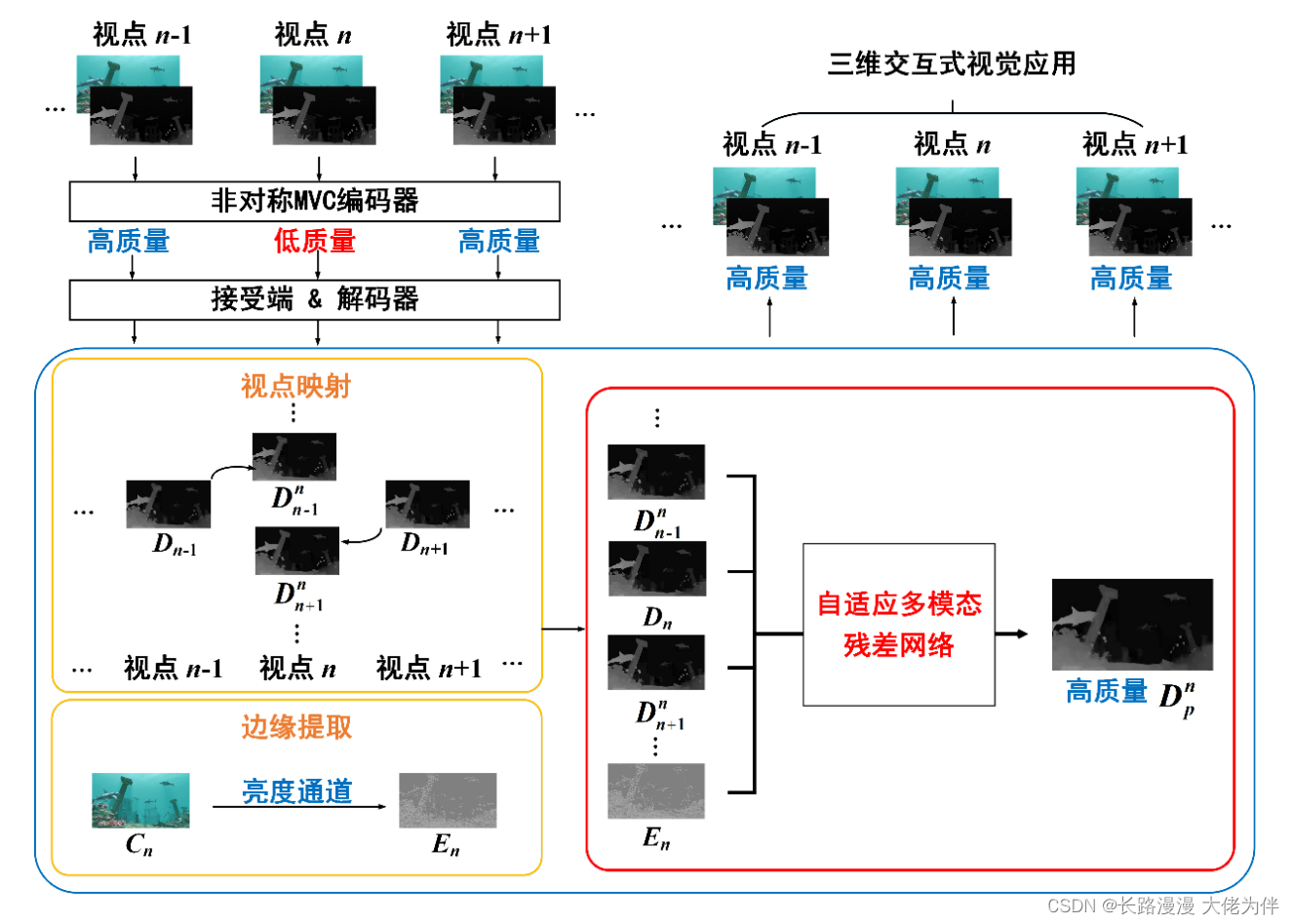
基于自适应残差网络的多视点压缩深度图像增强算法
在该框架中,来自相邻视点的深度图和目标视点的彩色图像被用作多模态先验信息,这种多模态先验信息能够很好地弥补压缩后深度图像在低码率下损失的信息,为了质量提供足够的引导信息。然后设计了自适应跳跃结构,使得这些先验对增强的贡献得以很好的权衡,充分地利用有益的先验,抑制不利的先验。
提出原因
压缩后的多视点深度图像会存在压缩失真,如何有效利用多视点之间的相关性来处理这些压缩失真是提升三维应用的用户沉浸式体验的关键问题。
实践依据
由于多视点视频是由相机从不同的视角拍摄同一时刻同一场景得到的,所以视点间存在高相关性。这种高相关性可以帮助我们从质量高的视点中获取有价值的信息,对质量低的视点的深度图像进行增强。
具体实践
将多视点的深度图像与待增强视点的彩色图像共同作为输入,设计了一个自适应多模态残差网络,以融合来自不同视点、不同图像类型的先验信息。经过我们的算法处理,较低质量的深度图像会被增强,输出较高质量的深度图像,从而提升终端应用的视觉质量
网络结构
提出原因
作为目标的深度图像是一种十分缺少纹理变化的图像,这就使得它在深层网络中更容易出现梯度消失的问题。所以我们使用残差网络这一网络结构来解决这一问题。
实践依据
残差网络结构主要由残差块构成,这种残差块的输入会经过一个跳跃结构输出到残差块的输出,使得更深层也能得到来自浅层的信息,能更好的保留浅层网络的信息,避免网络退化的问题。
具体实践
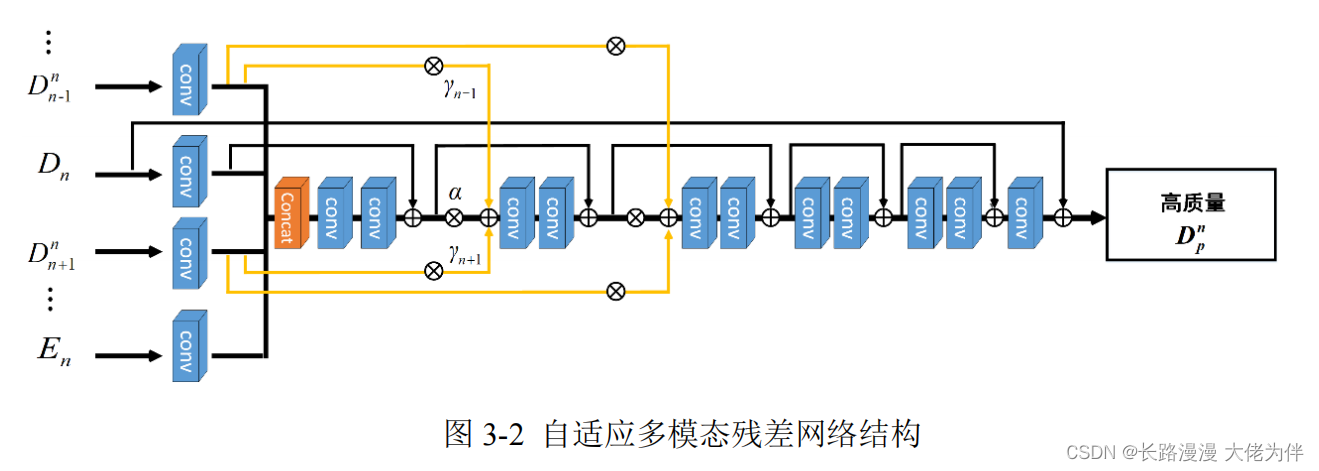
整个网络一共含有 5 个残差块,相较于原始的残差网络,残差块数量十分少。这是因为深度图像高相似性和十分平滑的特点,使得网络无法更深。
自适应跳跃结构
由于目标深度图和多模态的先验信息具有不同的特点和质量,权衡好各先验信息的贡献是十分必要的。处理它们之间的平衡,并强调具有更大贡献的先验信息。
实验结果
无论是像 VRCNN 这样的浅层网络,还是像 REDNet 这样的具有跳跃结
构的深层网络,在深度图出现严重失真的情况下,都无法从压缩深度图本身获悉细节。这说明在这一任务中,能带来更多信息的先验知识是非常重要的。
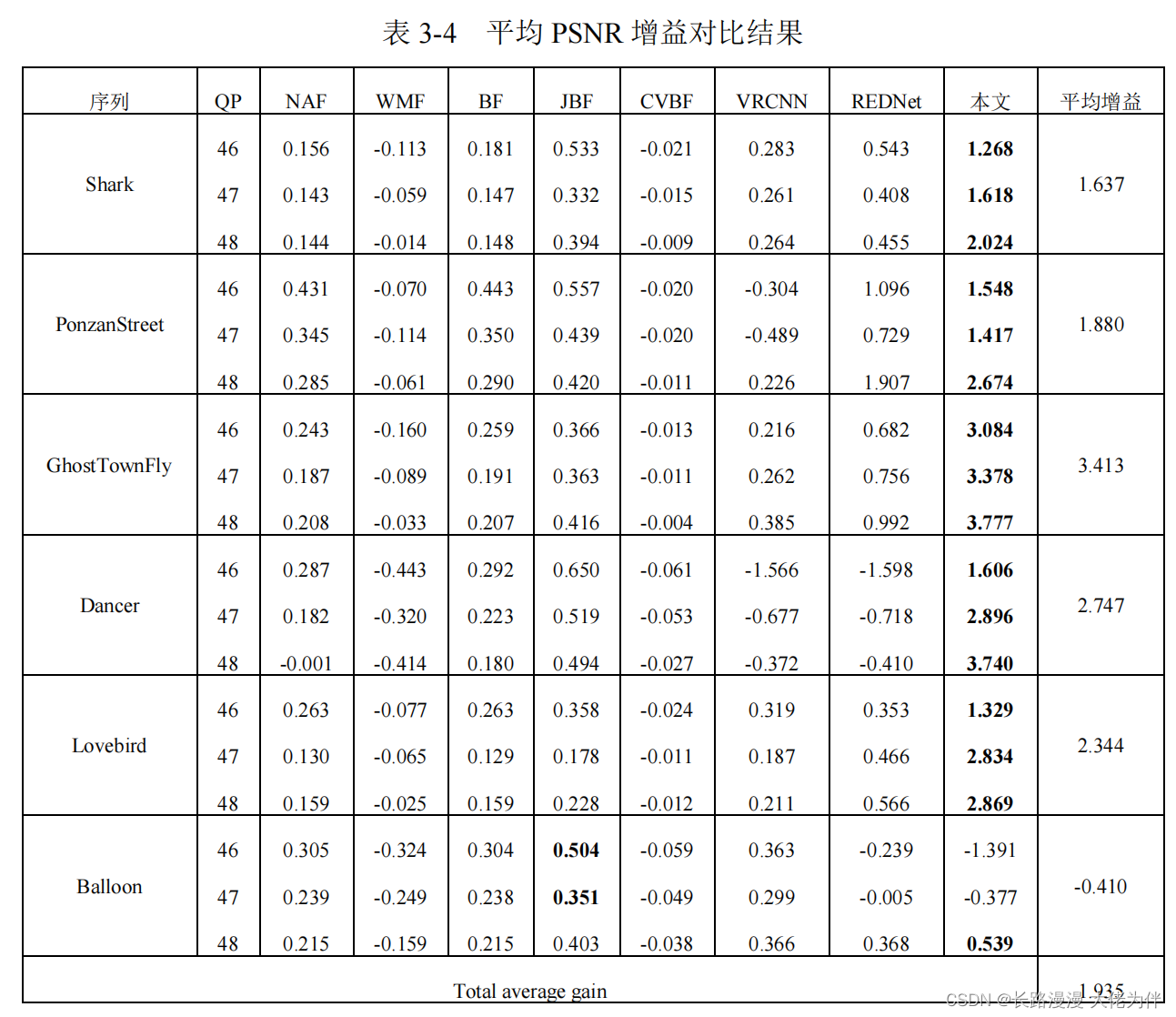
通过方法获得的质量增益比错误深度带来的影响还要大。它证明方法可以很好地处理高比特率下的压缩失真

消融实验
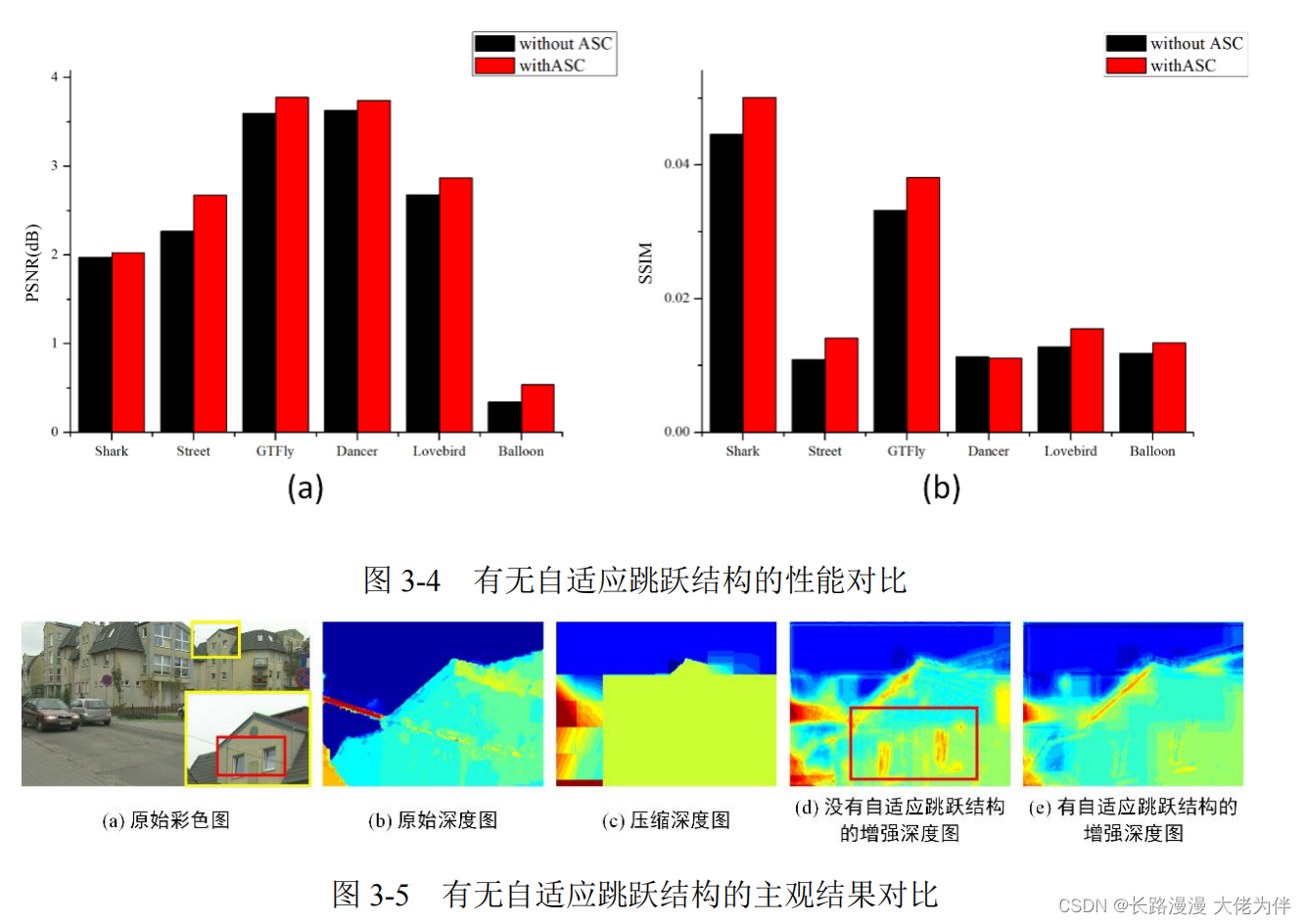
与其他深度图相比,没有自适应跳跃连接的方法增强的深度图上会出现轻微的纹理。它不属于原始深度图。相反,可以在相应的原始彩色图像中找到这种窗口纹理,彩色图像的纹理被复制到深度图上。添加自适应跳跃连接可以抑制纹理复制问题,从而获得更大的质量增益
深度图像主观结果
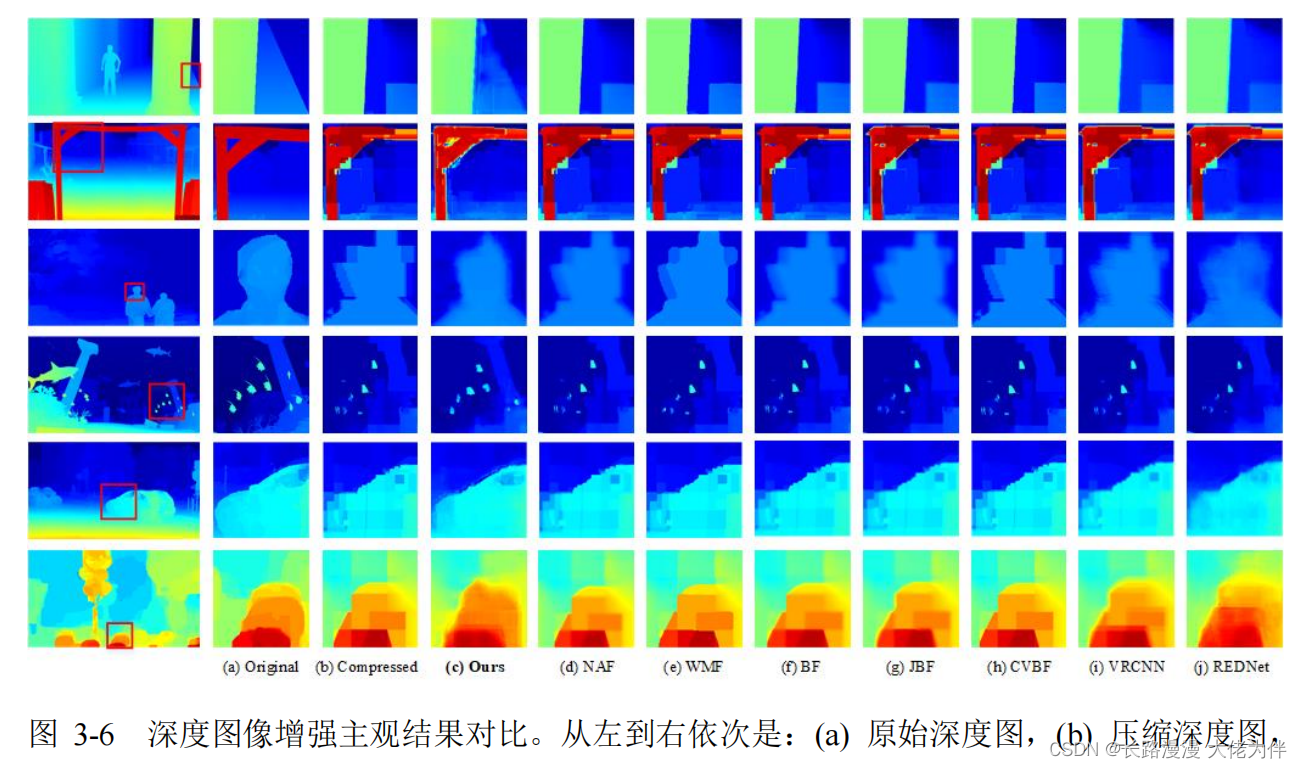
从图中可以发现,与其他方法相比,我们的方法可以有效地消除块伪像并恢复更多细节。即使在某些使用彩色图像作为先验信息的滤波方法中,由于深度图和彩色图像之间的巨大差异,彩色图像的效果也受到抑制。通过我们的方法恢复的那些鱼的图像说明选定先验对最终性能的贡献
点云图像主观结果

利用我们增强的深度图得到的点云,消失的表面和破碎的结构可以
得到适当的修复。它证明点云重构可以从我们提出的方法中受益,从而改善高质量 3D 应用程序的功能。
基于多约束编解码网络的多视点外推算法
在该框架中,网络由编码器,Gate Unit 和解码器构成,实现从多参考视点中提取特征,融合,从特征中重建图像。这种编解码网络结构可以更好地解决由于视点差和错误映射等导致的参考视点与虚拟视点间不一致的问题。
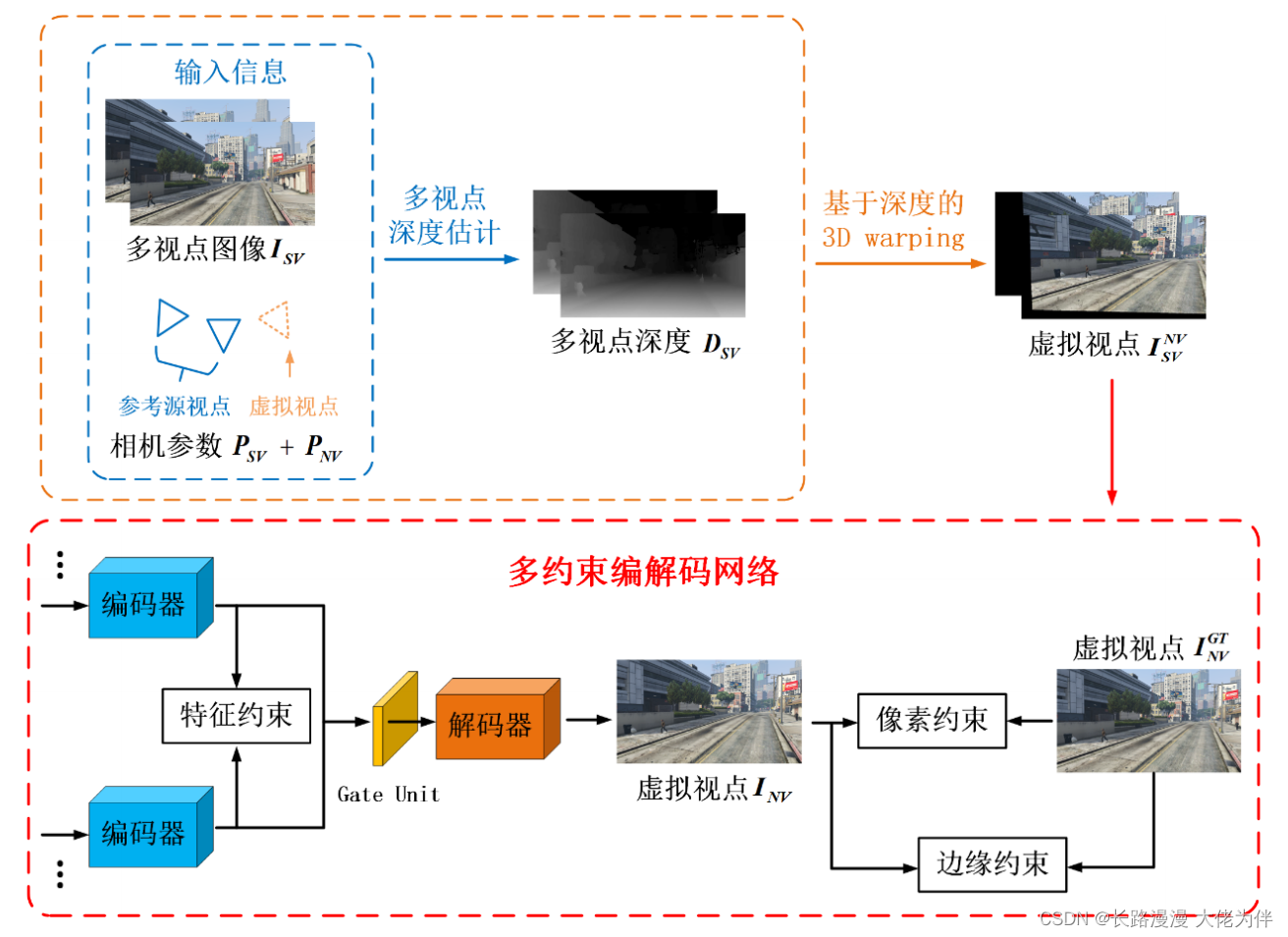
提出原因
由于虚拟视点在参考源视点范围之外,基于深度的图像绘制得到的虚拟视点图像会出现不可视的空洞区域,因此需要通过利用深度学习的学习能力,生成空洞区域的图片。在这基础上,使用多种约束来提升生成图像的结构合理性,使其拥有更好的视觉效果。
多约束损失函数
损失函数衡量的是模型的预测值和真实值不一样的程度,直接影响模型预测的结果。
像素约束
像素约束是基于深度学习的图像任务中最常用的约束,即计算模型输出图像与原始目标图像之间所有像素点数值的误差加粗样式作为损失函数
特征约束
特征约束,计算两个编码器提取的特征的误差,从而使网络倾向于提取在两个输入中更相似的特征
边缘约束
边缘约束,边缘能反应物体的轮廓,预测图像如果拥有正确的边缘说明物体没有发生较大形变,同时空洞区域生成内容的视觉效果也更合理
实验结果


消融实验
将3种约束替换为仅像素约束的损失函数
- 从结果中可以看到,算法增益更多来自网络结构本身,在仅使用像素约束的情况下,编解码网络得到的结果相比基于深度的图像绘制提升显著。说明这种编码器提取特征,解码器从特征重建结果的网络结构能很好的处理虚拟视点合成这种视点变换问题。
- 多约束相比于单约束,确实如所预想地得到更好的预测结果

扩展部分
基于深度学习的虚拟视点合成
物体虚拟视点合成
- 将深度学习与物体的虚拟视点合成相结合,通过端到端的网络同时学习目标视点图像及对应分割图像。但端到端直接学习新视点图像像素的学习方法学习新视点的物体几何的同时,却难以保留物体表面的纹理。
- 将流的学习拆分成了形状估计和图像生成两个网络,引入了深度信息的学习以更好的提供几 何结构信息。
场景虚拟视点合成
场景虚拟视点合成任务与物体虚拟视点合成任务有不小的差别,场景中往往有丰富的物体,难以将整个场景拆分成几何结构和纹理信息来学习,也难以用流的方式将所有像素一一对应
展望
- 针对压缩后的多视点深度图像算法,可以考虑增加时域方面的信息。目前仅使用不同视点的深度图像与目标视点的彩色图像进行增强,而时域信息也可以为增强提供有效的先验
- 针对多视点外推工作,可以考虑使用 GAN 网络结构,使网络具有更强的生成能力,得到更好的图像视觉效果。还可以考虑在视点遮挡的空洞区域进行更针对的处理,比如使用空洞区域蒙版来仅计算空洞区域的损失函数以增强对空洞区域的生成能力。