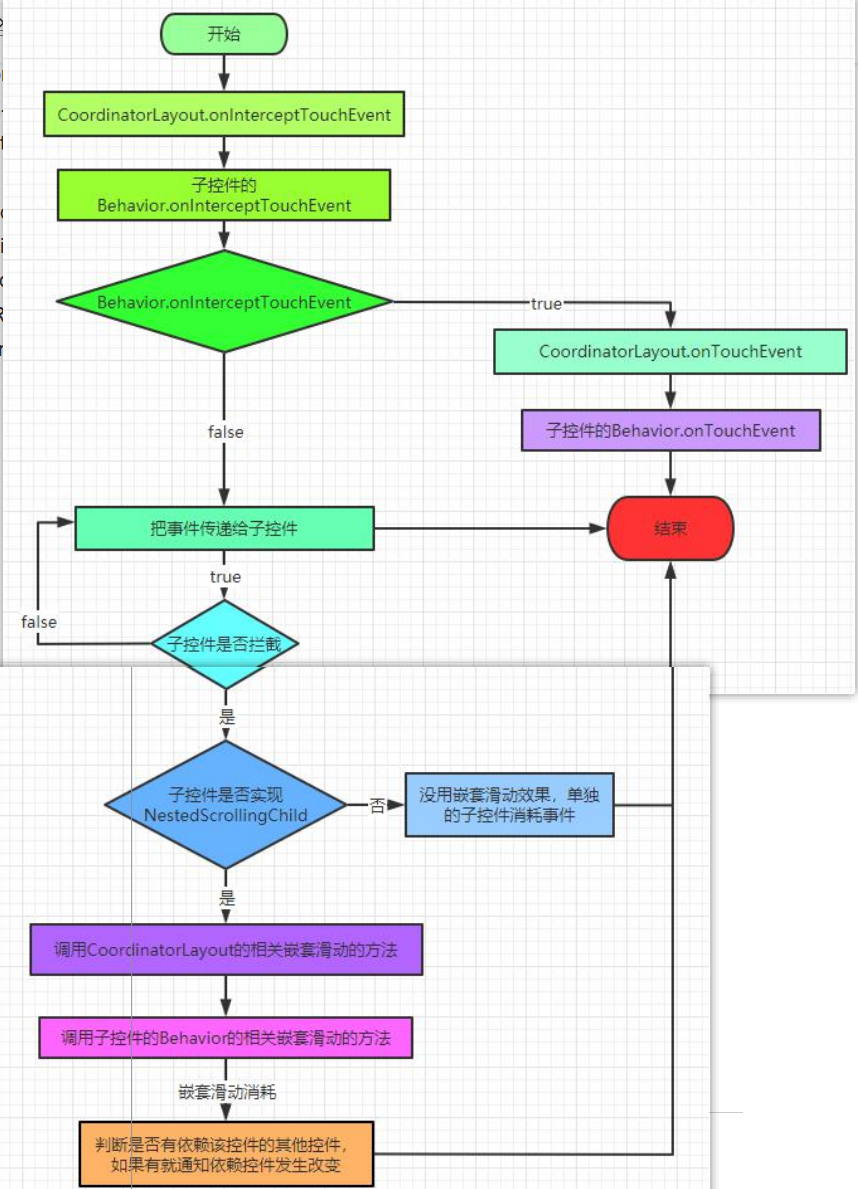
我们知道 CSV 是一种非常流行的数据格式。在 Elastic Stack 中,我们有很多的方式来摄入 CSV 格式的数据。我们可以先看看一个常用的数据摄入数据流:

如上所示,我们可以采取不同的方法来对数据进行摄入。我们可以在不同的地方对数据进行处理。如上所示:
- 我们可以使用 Beats 所提供的 processors 来进行处理。你可以参阅之前的文章 “Beats:Beats processors”。
- 我们可以采用 Logstash 所提供的丰富过滤器来进行处理。你可以参阅之前的文章 “Logstash:Logstash 入门教程 (二)”,“Logstash:使用 Logstash 导入 CSV 文件示例”。
- 我们可以使用 Elasticsearch ingest 节点所提供的 processors 来进行处理。这个也是我们今天所需要讲的内容
- 我们还可以使用各类语言进行数据写入。你可以参考文章 “Elasticsearch:使用 Jupyter Notebook 创建 Python 应用导入 CSV 文件”。
假设你有一个采用 CSV 格式的数据摄取流。 你可以选择开发一个例程,比如上面提到的 Python 应用来提取这些数据,但也许你可以通过使用 Elasticsearch 摄入节点所提供的 CSV 处理器来节省时间。
让我们配置 CSV 处理器来设置字段 “name”、“surname”、“address”、“phone”。 条目将是:“jhon bon;maclister;street wingol;552366636595”。
请注意,分隔符是 “;”,所以让我们将 “separator” 参数配置为值 “;”。
在 “target_fields” 字段中,我们将设置字段列表:“name”、“surname”、“address”、“phone”。出于教学目的,我不会使用其他参数,但如有必要,请访问文档。
我们的管道是这样的:
POST /_ingest/pipeline/_simulate?verbose=true
{
"pipeline": {
"description": "extract values from csv format",
"processors": [
{
"csv": {
"field": "csv_field",
"target_fields": [
"name", "surname", "address", "phone"
],
"separator": ";"
}
}
]
},
"docs": [
{
"_index": "index",
"_id": "id",
"_source": {
"csv_field": "jhon bon;maclister;street wingol;552366636595"
}
}
]
}上面的输出是:
{
"docs": [
{
"processor_results": [
{
"processor_type": "csv",
"status": "success",
"doc": {
"_index": "index",
"_id": "id",
"_version": "-3",
"_source": {
"name": "jhon bon",
"csv_field": "jhon bon;maclister;street wingol;552366636595",
"address": "street wingol",
"phone": "552366636595",
"surname": "maclister"
},
"_ingest": {
"pipeline": "_simulate_pipeline",
"timestamp": "2023-02-03T03:17:44.015883051Z"
}
}
}
]
}
]
}从输出中,我们可以看出来数据已经被结构化了。当然上面只是一个模拟的结果。我们需要使用如下的命令来创建一个处理 CSV 格式的 pipeline:
PUT /_ingest/pipeline/extract_csv
{
"description": "extract values from csv format",
"processors": [
{
"csv": {
"field": "csv_field",
"target_fields": [
"name",
"surname",
"address",
"phone"
],
"separator": ";"
}
}
]
}这样我们就创建了一个叫做 extract_csv 的 pipeline。我们在实际写入文档时,可以这么使用这个 pipeline:
PUT twitter/_doc/1?pipeline=extract_csv
{
"csv_field": "jhon bon;maclister;street wingol;552366636595"
}我们来查看该文档:
GET twitter/_doc/1我们可以看到如下的结果:
{
"_index": "twitter",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"name": "jhon bon",
"csv_field": "jhon bon;maclister;street wingol;552366636595",
"address": "street wingol",
"phone": "552366636595",
"surname": "maclister"
}
}很显然,文档已经被结构化了。