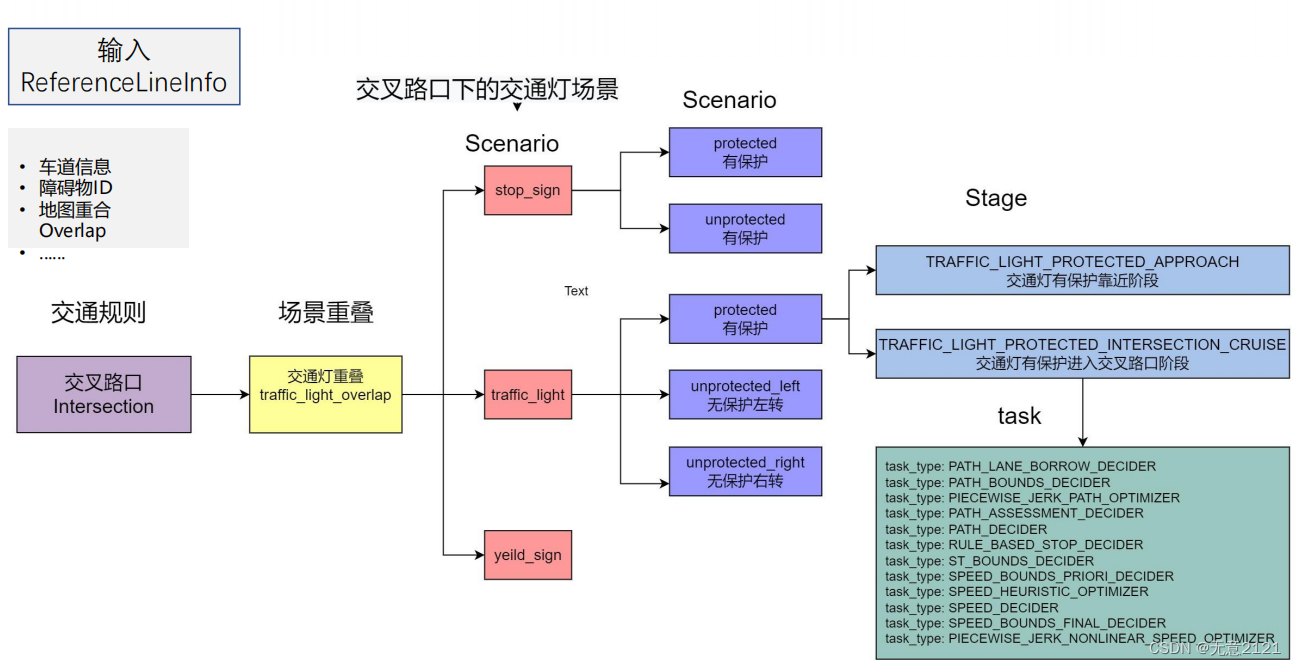
有两位极客玩家参与了一场「二叉树着色」的游戏。游戏中,给出二叉树的根节点
root,树上总共有n个节点,且n为奇数,其中每个节点上的值从1到n各不相同。最开始时:
- 「一号」玩家从
[1, n]中取一个值x(1 <= x <= n);- 「二号」玩家也从
[1, n]中取一个值y(1 <= y <= n)且y != x。「一号」玩家给值为
x的节点染上红色,而「二号」玩家给值为y的节点染上蓝色。之后两位玩家轮流进行操作,「一号」玩家先手。每一回合,玩家选择一个被他染过色的节点,将所选节点一个 未着色 的邻节点(即左右子节点、或父节点)进行染色(「一号」玩家染红色,「二号」玩家染蓝色)。
如果(且仅在此种情况下)当前玩家无法找到这样的节点来染色时,其回合就会被跳过。
若两个玩家都没有可以染色的节点时,游戏结束。着色节点最多的那位玩家获得胜利 ✌️。
现在,假设你是「二号」玩家,根据所给出的输入,假如存在一个
y值可以确保你赢得这场游戏,则返回true;若无法获胜,就请返回false。示例 1 :
输入:root = [1,2,3,4,5,6,7,8,9,10,11], n = 11, x = 3 输出:true 解释:第二个玩家可以选择值为 2 的节点。示例 2 :
输入:root = [1,2,3], n = 3, x = 1 输出:false
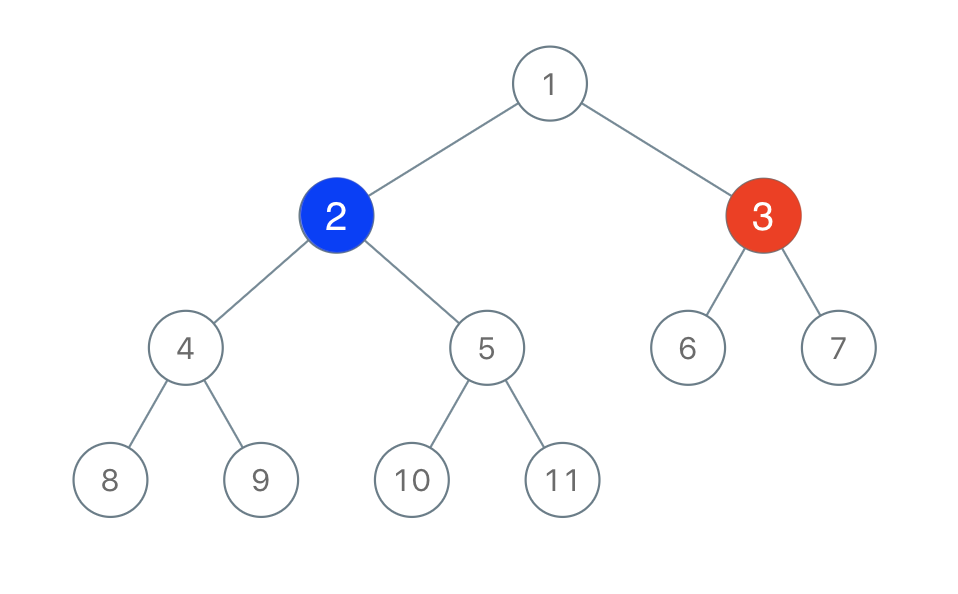
大概题意:一号玩家和二号玩家在树中选择一个结点涂色,之后从第一次选择的的结点的父节点和左右子节点继续选择并涂色,哪位玩家最后涂色结点多,哪位玩家获胜。
要让二号玩家获胜需要二号玩家最后涂的颜色多于一号,则最少要多余所有节点的一半,根据一号玩家选择的位置可以将整个树分为三块区域,一号玩家可以向三个方向延续染色,要想让二号玩家染色多于一号,则必须选择紧邻一号玩家位置的结点,这样就保证在一号玩家确定位置之后,二号玩家可以获得最多的可染色结点,从三个区域选择一个最大区域,如果三个区域中有一个区域包含的结点值大于总结点的一半。则二号玩家可以获胜。二号玩家选择的位置为该区域紧邻x结点的结点。
深搜广搜的理解 可查看这篇文章的比喻
深搜和广搜的原理及优缺点_June·D的博客-CSDN博客_深搜和广搜
以下理解可跳过
(一)深度优先搜索的特点是:
1.深度优先搜索法有递归以及非递归两种设计方法。一般的,当搜索深度较小、问题递归方式比较明显时,用递归方法设计好,它可以使得程序结构更简捷易懂。当数据量较大时,由于系统堆栈容量的限制,递归容易产生溢出,用非递归方法设计比较好。
2.深度优先搜索方法有广义和狭义两种理解。广义的理解是,只要最新产生的结点(即深度最大的结点)先进行扩展的方法,就称为深度优先搜索方法。在这种理解情况下,深度优先搜索算法有全部保留和不全部保留产生的结点的两种情况。而狭义的理解是,仅仅只保留全部产生结点的算法。本书取前一种广义的理解。不保留全部结点的算法属于一般的回溯算法范畴。保留全部结点的算法,实际上是在数据库中产生一个结点之间的搜索树,因此也属于图搜索算法的范畴。
3.不保留全部结点的深度优先搜索法,由于把扩展望的结点从数据库中弹出删除,这样,一般在数据库中存储的结点数就是深度值,因此它占用的空间较少,所以,当搜索树的结点较多,用其他方法易产生内存溢出时,深度优先搜索不失为一种有效的算法。
4.不一定会得到最优解,这个时候需要修改原算法:把原输出过程的地方改为记录过程,即记录达到当前目标的路径和相应的路程值,并与前面已记录的值进行比较,保留其中最优的,等全部搜索完成后,才把保留的最优解输出。
二、广度优先搜索法的显著特点是:
(1)在产生新的子结点时,深度越小的结点越先得到扩展,即先产生它的子结点。为使算法便于实现,存放结点的数据库一般用队列的结构。
(2)无论问题性质如何不同,利用广度优先搜索法解题的基本算法是相同的,但数据库中每一结点内容,产生式规则,根据不同的问题,有不同的内容和结构,就是同一问题也可以有不同的表示方法。
(3)当结点到跟结点的费用(有的书称为耗散值)和结点的深度成正比时,特别是当每一结点到根结点的费用等于深度时,用广度优先法得到的解是最优解,但如果不成正比,则得到的解不一定是最优解。这一类问题要求出最优解,一种方法是使用后面要介绍的其他方法求解,另外一种方法是改进前面深度(或广度)优先搜索算法:找到一个目标后,不是立即退出,而是记录下目标结点的路径和费用,如果有多个目标结点,就加以比较,留下较优的结点。把所有可能的路径都搜索完后,才输出记录的最优路径。
(4)广度优先搜索算法,一般需要存储产生的所有结点,占的存储空间要比深度优先大得多,因此程序设计中,必须考虑溢出和节省内存空间得问题。
(5)比较深度优先和广度优先两种搜索法,广度优先搜索法一般无回溯操作,即入栈和出栈的操作,所以运行速度比深度优先搜索算法法要快些。
总之,一般情况下,深度优先搜索法占内存少但速度较慢,广度优先搜索算法占内存多但速度较快,在距离和深度成正比的情况下能较快地求出最优解。因此在选择用哪种算法时,要综合考虑。决定取舍。
代码解答
class Solution {
//定义全局变量作为x的当前位置结点
TreeNode xNode;
public boolean btreeGameWinningMove(TreeNode root, int n, int x) {
findX(root,x);
//计算x结点左子节点区域的结点数目
int leftSize = getSubtreeSize(xNode.left);
//判断是否多余一半结点
if (leftSize >= (n + 1) / 2){
return true;
}
//计算x结点右子节点区域的结点数目
int rightSize = getSubtreeSize(xNode.right);
//判断是否多余一半结点
if (rightSize >= (n + 1) / 2){
return true;
}
//计算x结点父节点区域的结点数目
int fatherSize = n - 1 - leftSize - rightSize;
//判断是否多余一半结点
if (fatherSize >= (n + 1) / 2){
return true;
}
return false;
}
//寻找x结点在树中的位置
public void findX(TreeNode node, int x){
//判断是否已经找到或者当前树是否为空
if (xNode != null || node == null){
return;
}
//找到x的结点值 将node值赋给xNode
if (node.val == x){
xNode = node;
return;
}
//递归向左右子树寻找x结点
findX(node.left,x);
findX(node.right,x);
}
//计算左右结点数目
public int getSubtreeSize(TreeNode node){
if (node == null){
return 0;
}
//递归继续往下寻找
return 1 + getSubtreeSize(node.left) + getSubtreeSize(node.right);
}
}