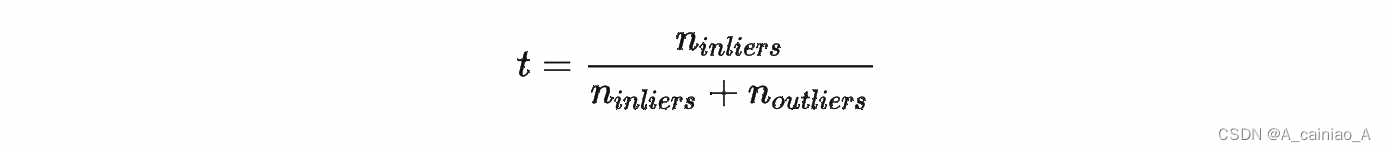1、失效的情况
1.前导模糊查询不能利用索引(like ‘%XX’或者like ‘%XX%’)
假如有这样一列code的值为’AAA’,‘AAB’,‘BAA’,‘BAB’ ,如果where code like '%AB’条件,由于前面是
模糊的,所以不能利用索引的顺序,必须一个个去找,看是否满足条件。这样会导致全索引扫描或者全表扫
描。如果是这样的条件where code like 'A % ',就可以查找CODE中A开头的CODE的位置,当碰到B开头的
数据时,就可以停止查找了,因为后面的数据一定不满足要求。这样就可以利用索引了。
2.如果是组合索引的话,如果不按照索引的顺序进行查找,比如直接使用第三个位置上的索引而忽略第一二个位置上的索引时,则会进行全表查询
索引为c1,c2,c3,c4
直接使用c3是全表查询,无法使用该索引的,所以c3字段使用索引的前提是c1,c2两字段均使用了索引。
3.条件中有or
应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
查询条件中使用or会使索引失效,要想是索引生效,需要将or中的每个列都加上索引
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10 union all select id from t where num=20
4.索引无法存储null值,所以where的判断条件如果对字段进行了null值判断,将导致数据库放弃索引而进行全表查询,如
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
a.单列索引无法储null值,复合索引无法储全为null的值。
b.查询时,采用is null条件时,不能利用到索引,只能全表扫描。
为什么索引列无法存储Null值?
a.索引是有序的。NULL值进入索引时,无法确定其应该放在哪里。(将索引列值进行建树,其中必然涉及到诸多的比较操作,null 值是不确定值无法比较,无法确定null出现在索引树的叶子节点位置。
5.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
6.in 和 not in 也要慎用,否则会导致全表扫描,如:select id from t where num in(1,2,3)对于连续的数值,能用 between 就不要用 in 了
select id from t where num between 1 and 3
- 应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:–name以abc开头的id select id from t where substring(name,1,3)=‘abc’
8.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
9、连表查询的时候查看两个表字符集是否相同
实测失效的常用sql
mysql版本:5.7.40
"%四%":全匹配会失效
explain select address from student where name like "%四%"
not in:会失效
explain select * from t_work WHERE status not in(8,9)
in:两个值不会失效,三个值则会失效
explain select * from t_work WHERE status in(6,9,10)
or:需要or中的每个列都加上索引 status 有索引 person_id无索引 则会索引失效 全表扫描
explain select * from t_work WHERE status =8 or person_id=9
where条件函数:条件使用函数会导致索引失效
explain select address from student where substring(name,1,3)="名字"
orderby asc 、desc :都会导致索引失效
explain select * from t_work order by status asc
is not null:会导致索引失效 is null则不会
explain select * from t_work where status is not null
not like:会导致索引失效
explain select address from student where name not like "四%"
!= :不等于会导致索引失效
explain select * from t_work WHERE status !=9
<、<=、>、>=:会导致索引失效
explain select * from t_work WHERE status <9
当查询条件涉及到order by、limit等条件时,是否走索引情况比较复杂,而且与Mysql版本有关,通常普通索引,如果未使用limit,则不会走索引。order by多个索引字段时,可能不会走索引。其他情况,建议在使用时进行expain验证
说明!!! 当where条件值为多个索引列即使有一个无效, 实测当有一个有效也会走索引
2、命名规范
(1)单张表中索引数量不超过5个。
(2)单个索引中的字段数不超过5个。
(3)索引名必须全部使用小写。
(4)非唯一索引按照“idx_字段名称[_字段名称]”进用行命名。例如idx_age_name。
(5)唯一索引按照“uniq_字段名称[_字段名称]”进用行命名。例如uniq_age_name。
(6)组合索引建议包含所有字段名,过长的字段名可以采用缩写形式。例如idx_age_name_add。
(7)表必须有主键,推荐使用UNSIGNED自增列作为主键。
(8)唯一键由3个以下字段组成,并且字段都是(整)(形)(时),可使用唯一键作为主键。其他情况下,建议使用自增列或发号器作主键。
(9)禁止冗余索引。
(10)禁止重复索引。
(11)禁止使用外键。
(12)联表查询时,JOIN列的数据类型必须相同,并且要建立索引。
(13)不在低基数列上建立索引,例如“性别”。
(14)选择区分度大的列建立索引。组合索引中,区分度大的字段放在最前。
(15)对字符串使用前缀索引,前缀索引长度不超过8个字符。
(16)不对过长的VARCHAR字段建立索引。建议优先考虑前缀索引,或添加CRC32或MD5伪列并建立索引。
(17)合理创建联合索引,(a,b,c) 相当于 (a) 、(a,b) 、(a,b,c)。
(18)合理使用覆盖索引减少IO,避免排序。
3、索引计划分析
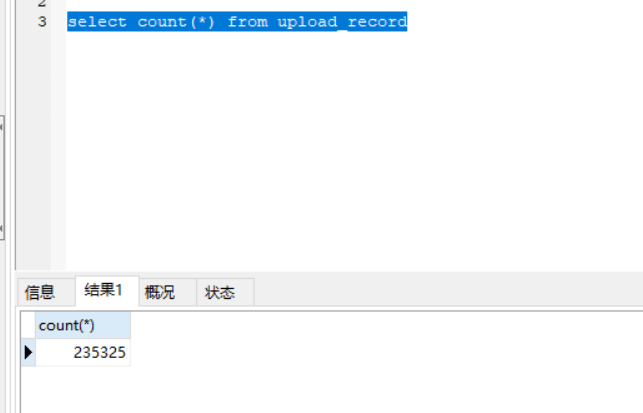
使用 explain 关键字查看sql执行情况 explain select name, address from student where address like “北京市%”;
解释Explain得到的结果
1、 type 反应查询语句的性能我们主需要注意一个最重要的的 type 的信息很明显地体现出是否用到了索引:
type 结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到 range 级别,最好能达到 ref 级别,否则就可能出现性能问题。

2、 possible_keys: SQL查询时用到的索引。
可以看到,没加索引时,possible_keys 的值为 NULL,加了索引后的值为 address,即用到了索引address(索引默认为(column_list)中的第一个列的名字).
3、 key 显示SQL实际决定查询结果使用的键(索引)。如果没有使用索引,值为NULL
可以看到,没加索引时,key 的值为 NULL,加了索引后的值为 address,即决定查询结果用到了索引address
4、 rows 显示MySQL认为它执行查询时必须检查的行数
可以看到,没加索引时,rows 的值为17,即数据表student中所有数据,说明没加索引时的SQL查询是全表扫描;
加了索引后,rows 的值为6,数据库表中address以“北京市”开头的一共也就6条,SQL在执行查询操作时,一共也检查了6行,不必进行全表扫描查询,可以很容易得出结论:加索引的SQL查询性能远高于不加索引的情况。
5、问题
1、为什么possible_keys有值,却没有走索引?
为什么possible_keys有值,但 key 列为 NULL,type 列为 all呢?因为MySQL通过估算发现,走索引的代价比走全表扫描的代价更高,那么什么情况下会出现这种情况?
如果查找的值占了全表的1/3或者更多,此时还需要回表查询的话,MySQL可能就会选择走全表扫描了。


- 总结
通过在SQL查询语句前面添加关键字 explain 就可以分析SQL查询语句的性能了.