MySQL中的数据类型
大致分为五种:数值,日期和时间,字符串,json,空间类型
每种类型也包括也一些不同的子类型,根据需要来选择。
如数值类型包括整数类型和浮点数类型 整数类型根据占用的存储空间的不同 又包括TINYINT(1字节),SMALLINT(2字节),INT(4字节),BIGINT(8字节),DECIMAL定点型。可以存储不同范围的整数。
浮点数类型包括FLOAT(4字节)和DOUBLE(8字节),可以存储不同范围的浮点数。日期和时间类型包括DATE日期, TIME时间, DATETIME日期时间, TIMESTAMP时间戳。
字符串类型包括CHAR定长字符串, VARCHAR变长字符串, TEXT文本, BLOB二进制数据, ENUM枚举, SET集合。如VARCHAR(100)表示长度为100的变长字符串。
空间类型包括地理信息、几何图形等。
MySQL大小写
- 在SQL中,关键字和函数名是不用区分字母大小写的,比如
SELECT、WHERE、 ORDER、 GROUP BY等关键字,以及ABS、MOD、 ROUND、 MAX等函数名。 - MySQL在Linux下数据库名、表名、列名、别名大小写规则是这样的:
1、数据库名、表名、表的别名、变量名是严格区分大小写的;
2、关键字、函数名称在SQL中不区分大小写;
3、列名(或字段名)与列的别名(或字段别名)在所有的情况下均是忽略大小写的; - MySQL在Windows的环境下全部不区分大小写
- 可通过如下命令查看是否大小写敏感
SHOW VARIABLES LIKE '%lower_case_table_names%';
1.与库相关
进入mysql数据库
mysql -u root -p;
修改密码
update user set password=password(”123456″) where user=’root’; 刷新数据库
FLUSH PRIVILEGES;创建数据库
CREATE DATABASE name;如果数据库已经存在,执行 CREATE DATABASE 将导致错误。
为了避免这种情况,可以在 CREATE DATABASE 语句中添加 IF NOT EXISTS 子句
如果希望在创建数据库时指定一些选项,可以使用 CREATE DATABASE 语句的其他参数,例如,可以指定字符集和排序规则:
CREATE DATABASE [IF NOT EXISTS] database_name
[CHARACTER SET charset_name]
[COLLATE collation_name];以上代码创建一个使用 utf8mb4 字符集和 utf8mb4_general_ci 排序规则的数据库。
打开数据库
如 use game;
USE name; 显示所有数据库
SHOW DATABASES; 删除数据库
//删除数据库,如果存在的话,不提醒
DROP DATABASE IF EXISTS name;
//删除数据库前,有提示。
mysqladmin drop NAME;显示当前mysql版本和当前日期
select version(),current_date;2.与表相关
创建表
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
...
);table_name是你要创建的表的名称。column1,column2, ... 是表中的列名。datatype是每个列的数据类型。
实例1:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
birthdate DATE,
is_active BOOLEAN DEFAULT TRUE
);创建了一个users表,其中包含五列:
id: 用户 id,整数类型,AUTO_INCREMENT自增长,PRIMARY KEY作为主键。username: 用户名,变长字符串,不允许为空。email: 用户邮箱,变长字符串,不允许为空。birthdate: 用户的生日,日期类型。is_active: 用户是否已经激活,布尔类型,默认值为 true。
如果你希望在创建表时指定数据引擎,字符集和排序规则等,可以使用 CHARACTER SET 和 COLLATE 子句:
CREATE TABLE mytable (
id INT PRIMARY KEY,
name VARCHAR(50)
) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;以上代码创建一个使用 utf8mb4 字符集和 utf8mb4_general_ci 排序规则的表。
实例2:
CREATE TABLE IF NOT EXISTS runoob_tbl(
runoob_id INT UNSIGNED AUTO_INCREMENT,
runoob_title VARCHAR(100) NOT NULL,
runoob_author VARCHAR(40) NOT NULL,
submission_date DATE,
PRIMARY KEY ( runoob_id )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;-
如果你不想字段为空可以设置字段的属性为 NOT NULL,如上实例中的 runoob_title 与 runoob_author 字段, 在操作数据库时如果输入该字段的数据为空,就会报错。
- AUTO_INCREMENT 定义列为自增的属性,一般用于主键,数值会自动加 1。
- PRIMARY KEY 关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号 , 分隔。
- ENGINE 设置存储引擎,CHARSET 设置编码。
显示所有的表
先use mysql;然后
SHOW TABLES;删除整个表
//删除表,如果存在的话
DROP TABLE IF EXISTS mytable;
//直接删除表,不检查是否存在
DROP TABLE mytable;IF EXISTS是一个可选的子句,表示如果表存在才执行删除操作,避免因为表不存在而引发错误。
查看表的具体属性信息及表中各字段的描述
DESC name; 插入数据
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);table_name是你要插入数据的表的名称。column1,column2,column3, ... 是表中的列名。value1,value2,value3, ... 是要插入的具体数值。
如果数据是字符型,必须使用单引号 ' 或者双引号 ",如: 'value1', "value1"。
实例1:
INSERT INTO users (username, email, birthdate, is_active)
VALUES ('test', 'test@runoob.com', '1990-01-01', true);如果要插入所有列的数据,可以省略列名,如实例2:
INSERT INTO users
VALUES (NULL,'test', 'test@runoob.com', '1990-01-01', true);这里,NULL 是用于自增长列的占位符,表示系统将为 id 列生成一个唯一的值。
如果你要插入多行数据,可以在 VALUES 子句中指定多组数值,如实例3:
INSERT INTO users (username, email, birthdate, is_active)
VALUES
('test1', 'test1@runoob.com', '1985-07-10', true),
('test2', 'test2@runoob.com', '1988-11-25', false),
('test3', 'test3@runoob.com', '1993-05-03', true);对表结构进行修改:ALTER
//把player表中的name列数据类型改为VARCHAR(200)
alter table player modify column name VARCHAR(200);
//将player表重命名为pp
alter table player rename pp;
//把player表中的name列名字改成nick_name
alter table player rename column name to nick_name;
//在player表中加入一列last_login,其数据类型为DATETIME
alter table player add column last_login DATETIME;
//删掉player中的last_login列
alter table player drop column last_login;2.GRANT授权
创建一个可以从任何地方连接服务器的一个完全的超级用户,但是必须使用一个口令something做这个
grant all privileges on *.* to user@localhost identified by ’something’ with格式 : grant select on 数据库 .* to 用户名@登录主机 identified by ”密码"
GRANT ALL PRIVILEGES ON *.* TO monty@localhost IDENTIFIED BY ’something’ WITH GRANT OPTION;
GRANT ALL PRIVILEGES ON . TO monty@”%” IDENTIFIED BY ’something’ WITH GRANT OPTION;3.更新数据
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;table_name是你要更新数据的表的名称。column1,column2, ... 是你要更新的列的名称。value1,value2, ... 是新的值,用于替换旧的值。WHERE condition是一个可选的子句,用于指定更新的行。如果省略WHERE子句,将更新表中的所有行。
实例1,更改两列的值:
UPDATE orders
SET status = 'Shipped', ship_date = '2023-03-01'
WHERE order_id = 1001;实例2:更改所有学生的状态为"Graduated"
UPDATE students
SET status = 'Graduated';实例3: 更新使用子查询的值
UPDATE customers
SET total_purchases = (
SELECT SUM(amount)
FROM orders
WHERE orders.customer_id = customers.customer_id
)
WHERE customer_type = 'Premium';以上 SQL 语句通过子查询计算每个 'Premium' 类型客户的总购买金额,并将该值更新到 total_purchases 列中。
4.查询数据
SELECT column1, column2, ...
FROM table_name
[WHERE condition]
[ORDER BY column_name [ASC | DESC]]
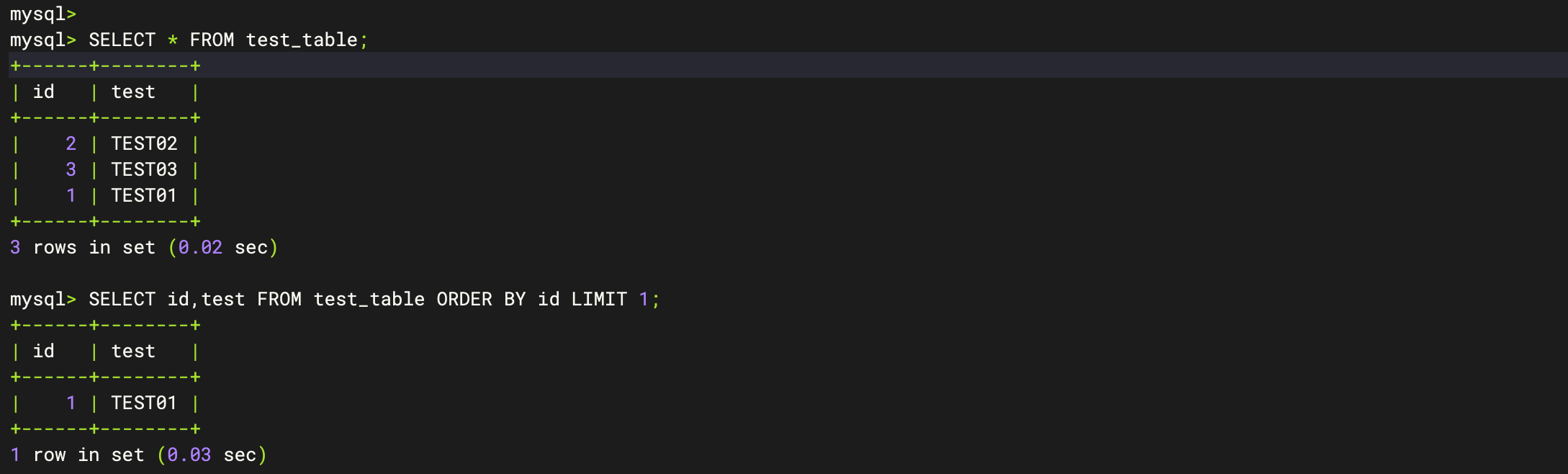
[LIMIT number];column1,column2, ... 是你想要选择的列的名称,如果使用*表示选择所有列。table_name是你要从中查询数据的表的名称。WHERE condition是一个可选的子句,用于指定过滤条件,只返回符合条件的行。ORDER BY column_name [ASC | DESC]是一个可选的子句,用于指定结果集的排序顺序,默认是升序(ASC)。LIMIT number是一个可选的子句,用于限制返回的行数。
-- 选择所有列的所有行
SELECT * FROM users;
-- 选择特定列的所有行
SELECT username, email FROM users;
-- 添加 WHERE 子句,选择满足条件的行
SELECT * FROM users WHERE is_active = TRUE;
-- 添加 ORDER BY 子句,按照某列的升序排序
SELECT * FROM users ORDER BY birthdate;
-- 添加 ORDER BY 子句,按照某列的降序排序
SELECT * FROM users ORDER BY birthdate DESC;
-- 添加 LIMIT 子句,限制返回的行数
SELECT * FROM users LIMIT 10; 在 WHERE 子句中,你可以使用各种条件运算符(如 =, <, >, <=, >=, !=),逻辑运算符(如 AND, OR, NOT),以及通配符(如 %)等。
以下是一些进阶的 SELECT 语句实例:
-- 使用 AND 运算符和通配符
SELECT * FROM users WHERE username LIKE 'j%' AND is_active = TRUE;
-- 使用 OR 运算符
SELECT * FROM users WHERE is_active = TRUE OR birthdate < '1990-01-01';
-- 使用 IN 子句
SELECT * FROM users WHERE birthdate IN ('1990-01-01', '1992-03-15', '1993-05-03');WHERE子句
WHERE 子句用于过滤查询结果,类似于程序语言中的 if 条件,只返回满足特定条件的行。
WHERE 子句也可以运用于 SQL 的 DELETE 或者 UPDATE 命令。
模糊匹配条件(LIKE):
SELECT * FROM customers WHERE first_name LIKE 'J%';LIKE子句
SELECT column1, column2, ...
FROM table_name
WHERE column_name LIKE pattern;在 MySQL 中使用 SELECT 命令来读取数据可以使用 WHERE 子句来获取指定的记录。WHERE 子句中可以使用等号 = 来设定获取数据的条件,如 "runoob_author = 'RUNOOB.COM'"。
但是有时候我们需要获取 runoob_author 字段含有 "COM" 字符的所有记录,这时我们就需要在 WHERE 子句中使用 LIKE 子句。LIKE 子句是在 MySQL 中用于在 WHERE 子句中进行模糊匹配的关键字。它通常与通配符(%或_)一起使用,用于搜索符合某种模式的字符串。
LIKE 子句中使用%字符来表示任意字符,类似于UNIX或正则表达式中的星号 *。
如果没有使用%, LIKE 子句与等号 = 的效果是一样的。
也可以在 DELETE 或 UPDATE 命令中使用 WHERE...LIKE 子句来指定条件。
实例1:% 通配符表示零个或多个字符。例如,'a%' 匹配以字母 'a' 开头的任何字符串。
SELECT * FROM customers WHERE last_name LIKE 'S%';以上 SQL 语句将选择所有姓氏以 'S' 开头的客户。
SELECT * from runoob_tbl WHERE runoob_author LIKE '%COM';以上SQL 语句将在 runoob_tbl 表中获取 runoob_author 字段中以 COM 为结尾的的所有记录
实例2:_ 通配符表示一个字符。例如,'_r%' 匹配第二个字母为 'r' 的任何字符串。
SELECT * FROM products WHERE product_name LIKE '_a%';以上 SQL 语句将选择产品名称的第二个字符为 'a' 的所有产品。
实例3:组合使用 % 和 _
SELECT * FROM users WHERE username LIKE 'a%o_';以上 SQL 语句将匹配以字母 'a' 开头,然后是零个或多个字符,接着是 'o',最后是一个任意字符的字符串,如 'aaron'、'apol'。
实例4:不区分大小写的匹配
SELECT * FROM employees WHERE last_name LIKE 'smi%' COLLATE utf8mb4_general_ci;以上 SQL 语句将选择姓氏以 'smi' 开头的所有员工,不区分大小写。
ORDER BY子句
实例1:多列排序
SELECT * FROM employees
ORDER BY department_id ASC, hire_date DESC;以上 SQL 语句将选择员工表 employees 中的所有员工,并先按部门 ID 升序 ASC 排序,然后在相同部门中按雇佣日期降序 DESC 排序。
实例2:使用数字表示列的位置
SELECT first_name, last_name, salary
FROM employees
ORDER BY 3 DESC, 1 ASC;以上 SQL 语句将选择员工表 employees 中的名字和工资列,并按第三列(salary)降序 DESC 排序,然后按第一列(first_name)升序 ASC 排序。
实例3:使用表达式排序
SELECT product_name, price * discount_rate AS discounted_price
FROM products
ORDER BY discounted_price DESC;- AS 关键字可以给表中字段 或者 表名起别名
以上 SQL 语句将选择产品表 products 中的产品名称和根据折扣率计算的折扣后价格 起别名为discounted_price,并按折扣后价格降序 DESC 排序。
5.删除数据
DELETE FROM table_name
WHERE condition;table_name是你要删除数据的表的名称。WHERE condition是一个可选的子句,用于指定删除的行。如果省略WHERE子句,将删除表中的所有行。
实例:
DELETE FROM customers
WHERE customer_id IN (
SELECT customer_id
FROM orders
WHERE order_date < '2023-01-01'
);以上 SQL 语句通过子查询删除了 orders 表中在 '2023-01-01' 之前下的订单对应的客户。
6.合并结果集:UNION
MySQL UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合,并去除重复的行。
UNION 操作符必须由两个或多个 SELECT 语句组成,每个 SELECT 语句的列数和对应位置的数据类型必须相同。
SELECT column1, column2, ...
FROM table1
WHERE condition1
UNION
SELECT column1, column2, ...
FROM table2
WHERE condition2
[ORDER BY column1, column2, ...];
column1,column2, ... 是你要选择的列的名称,如果使用*表示选择所有列。table1,table2, ... 是你要从中查询数据的表的名称。condition1,condition2, ... 是每个SELECT语句的过滤条件,是可选的。ORDER BY子句是一个可选的子句,用于指定合并后的结果集的排序顺序。
实例1:
SELECT product_name FROM products WHERE category = 'Electronics'
UNION
SELECT product_name FROM products WHERE category = 'Clothing'
ORDER BY product_name;以上 SQL 语句将选择电子产品和服装类别的产品名称,并按产品名称升序排序。
实例2:使用 UNION ALL 不去除重复行
SELECT city FROM customers
UNION ALL
SELECT city FROM suppliers
ORDER BY city;以上 SQL 语句使用 UNION ALL 将客户表和供应商表中的所有城市合并在一起,不去除重复行。
UNION 操作符在合并结果集时会去除重复行,而 UNION ALL 不会去除重复行,因此 UNION ALL 的性能可能更好,但如果你确实希望去除重复行,可以使用 UNION。
参考MySQL 教程 | 菜鸟教程 (runoob.com)
MySQL的指令大全和注意事项(强烈推荐收藏)_mysql常用命令-CSDN博客
MySQL常用命令总结_常用的mysql命令-CSDN博客