本文字数:4540;估计阅读时间:12 分钟
作者:Mathew Pregasen
本文在公众号【ClickHouseInc】首发

本周,我们欢迎来自 Lago 的一篇博客文章,介绍了他们如何使用 ClickHouse 扩展一个事件引擎,并在此过程中将查询速度最高提高了 137 倍!这篇博客文章的原始版本发布在 Github 上。
【https://github.com/getlago/lago/wiki/Using-Clickhouse-to-scale-an-events-engine】
介绍
像许多公司一样,我们在扩展核心产品 Lago (一个开源的基于使用量计费平台)时,不得不在过程中更换数据库堆栈。随着我们逐渐受到欢迎,我们每分钟开始接收数百万个事件。我们初期使用的仅 Postgres 的简单堆栈已经无法满足需求。我们遭遇了严重的加载时间问题,影响了整个应用的性能。
经过一些探索,我们决定使用一个分布式的 ClickHouse 实例专门处理我们的流事件。我们的分析服务现在可以直接查询这个 OLAP 数据库 ClickHouse。对于所有其他数据需求,我们保留了 Postgres。
这个策略非常成功。自重构后,我们从未回头。
今天,我们将探讨这个混合数据库堆栈的决策,特别是为什么我们选择 ClickHouse。
OLTP 与 OLAP 数据库
大多数开发者,包括初级开发者,都有使用 OLTP (在线事务处理)数据库(如 Postgres)的经验。顾名思义,OLTP 数据库专为处理事务而设计。事务是一个独立的工作单元,可能包括以下操作:(i) 读取,(ii) 插入,(iii) 更新,和 (iv) 删除。
OLTP 数据库通常是通用数据库。由于它们支持各种类型的数据处理,可以在一定程度上解决任何数据问题。即使在大规模使用时,OLTP 数据库对于需要以下功能的软件来说也是非常出色的:
-
原子性事务,其中一组事务要么全部发生,要么根本不发生
-
一致性,其中写入和更新之间的查询是确定的和可预测的
对于大多数问题,这些都是重要的特征。对于一些问题,它们是绝对关键的。例如,银行应用程序在账户之间转账时不能有任何差错。对于这些问题,需要 OLTP 数据库来实现精确到分的准确性。
今天,我们仍然使用 Postgres 作为我们的主数据库,通过我们的 database.yml 文件进行配置。鉴于我们使用 Ruby on Rails,我们的 Postgres 模式由 Rails 的 Active Record 自动生成,这是一个 ORM,管理着我们各种模型,如费用、信用票据、发票、邀请、费用、优惠券等等。我们编写了一些自定义查询(考虑到 ORM 的性能限制),但在大多数事务中主要依赖 Active Record。
那么 OLAP (在线分析处理)数据库(如 ClickHouse)在哪里派上用场呢?Postgres 被设计为严格的原子性和一致性,这两个属性要求在任何查询处理之前,数据必须完全摄取。这对每分钟插入数百万行数据的表(例如,可计费事件,特别是那些基础设施服务如托管服务器的事件)造成了问题。具体来说,问题不在于插入数据,而在于同时处理复杂的分析查询而不锁定队列。这些数据汇总问题正是 OLAP 数据库(如 ClickHouse)大显身手的领域。
OLAP 数据库设计用于解决两个主要问题:(i) 以近似准确性高效回答复杂的读取查询和 (ii) 批处理大量写入查询。然而,OLAP 数据库历史上不擅长变更数据(通常需要重写整个数据库)或删除数据。
不同的 OLAP 解决方案(例如 ClickHouse、QuestDB、Druid)各有其优势。在下一节中,我们将深入探讨使 ClickHouse 成为最佳解决方案的具体特性。但所有 OLAP 解决方案都有一个共同特点——数据相对于像 Postgres 这样的 OLTP 数据库是以倒置布局存储的。
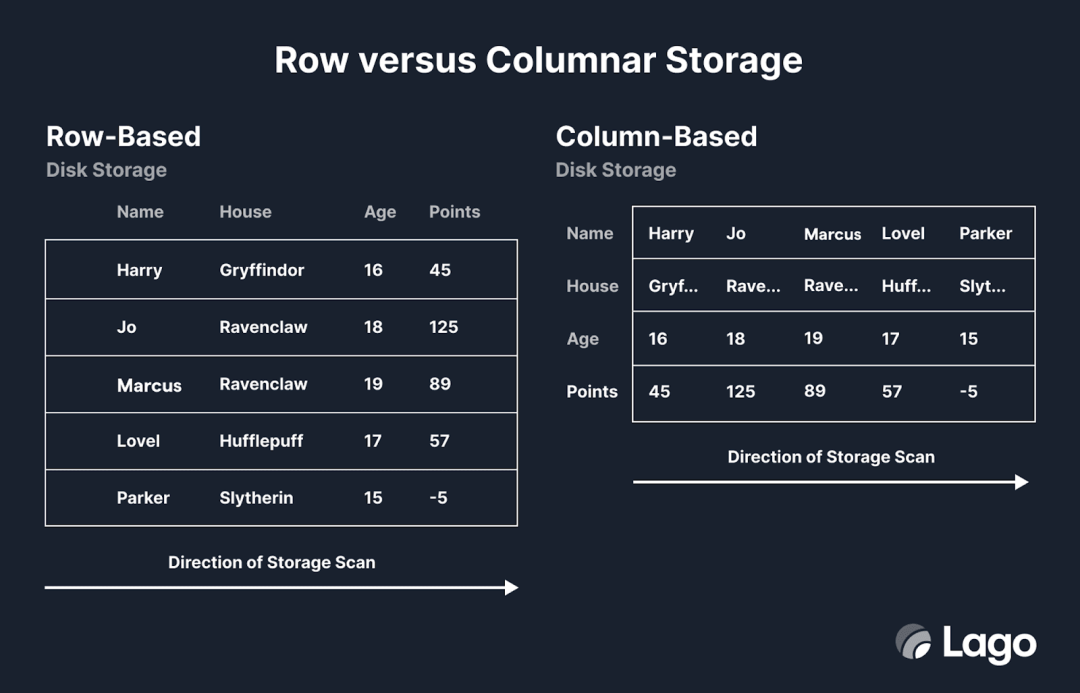
从用户的角度来看,表格的列和行仍然只是列和行。但在内存和磁盘上,数据是按列而不是按行进行扫描的。这使得聚合操作(例如将某个字段中的所有值相加)非常快,因为相关数据是顺序读取的。
介绍 ClickHouse,我们选择的 OLAP 解决方案
ClickHouse 于 2016 年开源,如今在 AWS 和 GCP 上作为无服务器云服务提供。它是采用最广泛的 OLAP 数据库之一。
ClickHouse 有三个显著特点,使其成为满足我们需求的强大分析工具:(i) 动态物化视图,(ii) 专用引擎,和 (iii) 向量化查询执行。
总结如下:
-
动态物化视图。物化视图是从基础表中的原始数据生成的可查询视图。虽然许多数据库都支持物化视图,包括 Postgres,但 ClickHouse 的物化视图是一种特殊的触发器,当数据插入时执行查询。查询结果然后被分派到目标表,在那里合并和更新。这使得工作从查询时间转移到插入时间:因为目标表通常更小,查询结果更简单。这与普通的物化视图不同,普通物化视图只是特定时间点的快照,刷新代价非常高(这些在 ClickHouse 中也得到支持,称为“可刷新的物化视图”)。
-
专用引擎。许多数据库使用单一引擎来利用硬件处理查询/事务。然而,ClickHouse 有专用引擎用于数学函数,例如求和或平均数。
-
向量化查询执行。ClickHouse 的专用引擎利用向量化查询执行,硬件通过多个单元并行处理来实现共同结果(称为 SIMD——单指令多数据)。
结合其列式存储,这些特性使 ClickHouse 能够轻松地对数据库值进行求和、平均和聚合。
需要注意的是,Postgres 并非完全不能实现类似的结果,但这只能通过大量优化来实现。例如,有一个为 Postgres 设计的第三方向量化执行器,模仿 ClickHouse 的原生特性。还有一个快速刷新模块,使用 Postgres 的日志来动态更新物化视图。结合 Postgres 触发器,开发者可以创建一个类似 ClickHouse 的环境。但所有这些技术都需要大量设置工作和额外列,才能达到与 ClickHouse 相当的效率。

来自我为 PostHog 编写的 Postgres 与 ClickHouse 指南中的相关表情包
当然,将分析过程迁移到 ClickHouse 只是战斗的一半。接下来是将 ClickHouse 实际部署到生产环境中,可以采用几种策略。
我们如何利用 ClickHouse
在讨论我们的 ClickHouse 实现时,主要涉及两个不同的主题:(i) 我们使用 ClickHouse 的用途,以及 (ii) 我们的 ClickHouse 实例如何部署和维护。
我们在 ClickHouse 中查询什么
我们的 ClickHouse 实例接收由用户派发的原始可计费事件。虽然我们不自行编写 ClickHouse 模式(因为它是由 Active Record 自动生成的),但它被写入一个文件,该文件在我们的开源库中可用。我们的 ClickHouse 实例只有两个表——raw_events 和 raw_events_queue——以及一个物化视图 events_raw_mv。仅此而已。我们不在 ClickHouse 中存储任何不需要用于分析查询的“业务关键”数据。
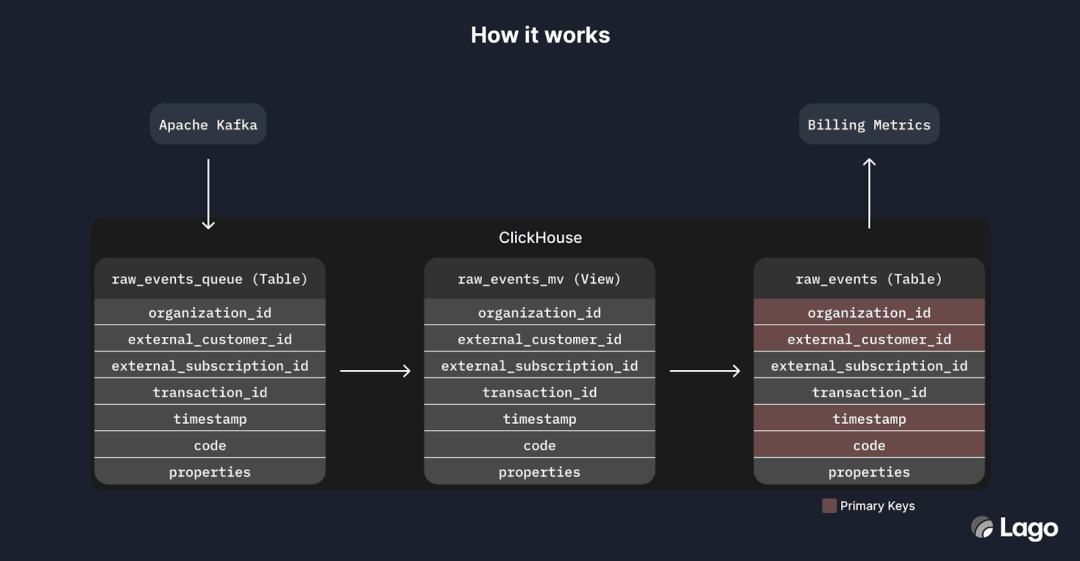
具体而言,我们的 raw_events_queue 表使用 Kafka 表引擎从 Apache Kafka(一种开源事件流软件)读取行。events_raw_mv 在 raw_events_queue 表接收插入时被触发,将事件的元数据从 JSON blob 映射到字符串数组,并将这些数据推送到 raw_events 表。这是一个为大量写入设计的 MergeTree 表。raw_events 是 Lago 的一般代码库通过我们的 ClickHouseStores 类与之交互的表,在聚合可计费指标时调用它。raw_events 使用一个由 organization_id、external_subscription_id 和 code 组成的元组——加上一个时间戳——作为主键;鉴于 ClickHouse 对主键元组的复杂支持,这使得 ClickHouse 能够非常快速地定位行数据。
我们如何部署 ClickHouse
由于 ClickHouse 是一个开源数据库,可以在任何普通的 Linux 服务器上进行自托管。然而,许多公司更信赖托管数据库解决方案,因为它们 (i) 通常可以降低总体成本,(ii) 使数据库更容易扩展,以及 (iii) 负责安全的复制和备份。
目前,我们使用 ClickHouse Cloud,这是一种由 ClickHouse Inc. 提供的托管解决方案,部署了一个无服务器的 ClickHouse 实例,具有解耦的计算和存储功能。ClickHouse Cloud 使我们更容易扩展,而无需担心扩展带来的问题。
ClickHouse 性能与 Postgres 的对比
我们对比了 Postgres 和 ClickHouse 在几个关键聚合操作上的性能:
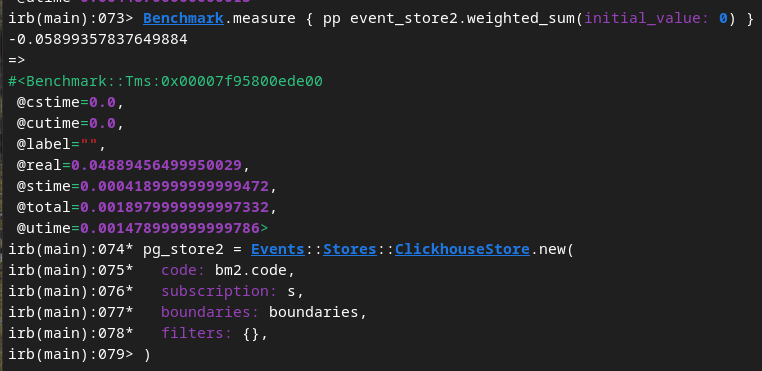
加权求和聚合
Postgres: 6.6秒
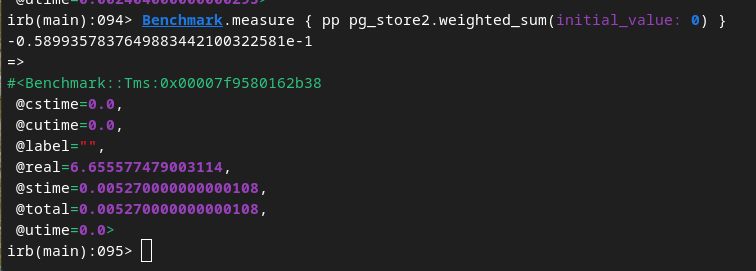
Clickhouse: 48毫秒
计数和求和操作
Postgres: 6.5秒
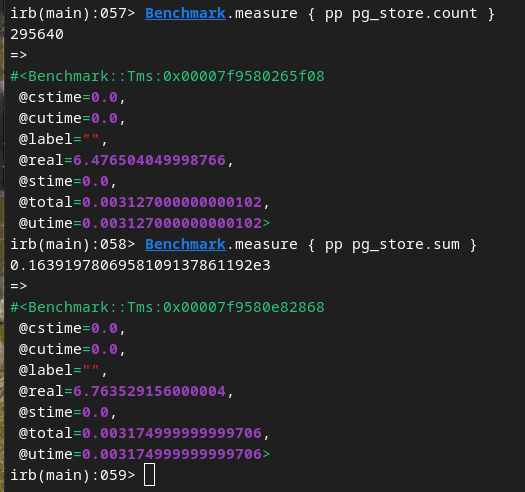
Clickhouse: 350毫秒
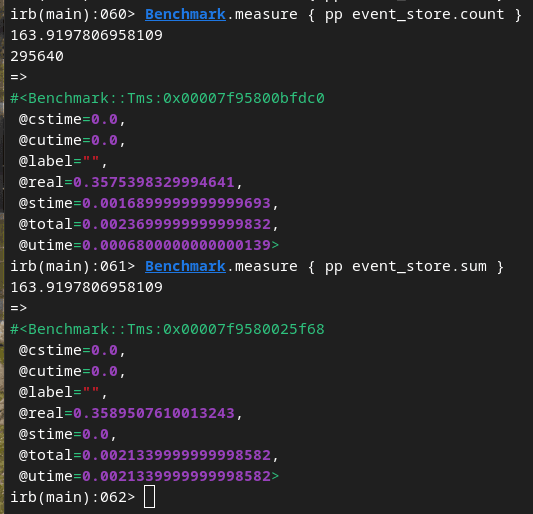
如图所示,迁移到 ClickHouse 后,我们的主要查询性能至少提高了 18 倍,最高可达 137 倍!
其他使用 ClickHouse 的著名开源项目
我们并不是唯一使用 ClickHouse 的开源项目。事实上,我们甚至不是唯一一个从 Postgres 迁移到 ClickHouse 的开源项目。另一个著名的例子是 PostHog,一个开源分析套件,由于每秒处理大量网络事件而从 Postgres 切换到 ClickHouse。
另一个典型的例子是 GitLab,它在其可观测性套件中使用 ClickHouse 存储流事件的数据。一般来说,当开源公司(和闭源项目)开始扩展时,通常会发现通用数据库如 Postgres 或 MySQL 不太适合。
即使是一些闭源解决方案,如 HTTP 数据流产品 Tinybird,也对 ClickHouse 做出了开源贡献,因为它们依赖于 ClickHouse。慢慢地,ClickHouse 在 OLAP 领域取得了与 Postgres 在 OLTP 领域相同的成功。
总结
由于倒置表布局的硬件优化,随着应用程序的扩展,没有一种数据库可以满足所有需求。在我们的旅程中,由于产品的事件密集特性,我们相当早就遇到了这个问题。然而,这并不意味着每个团队都需要从 OLTP + OLAP 堆栈开始——只需在时机到来时准备好。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求