【Apache Doris】3.0存算分离|标准部署篇(一)
- 一、前提概要
- 二、环境信息
- 三、前置准备
- 四、FoundationDB安装
- 五、OpenJDK 17安装
- 六、 Meta Service安装
- 七、集群安装
- 八、快速体验
接上 数据架构新篇章:存算一体与存算分离的协同演进。
本文主要分享Apache Doris 3.0存算分离架构的标准部署实践。
一、前提概要
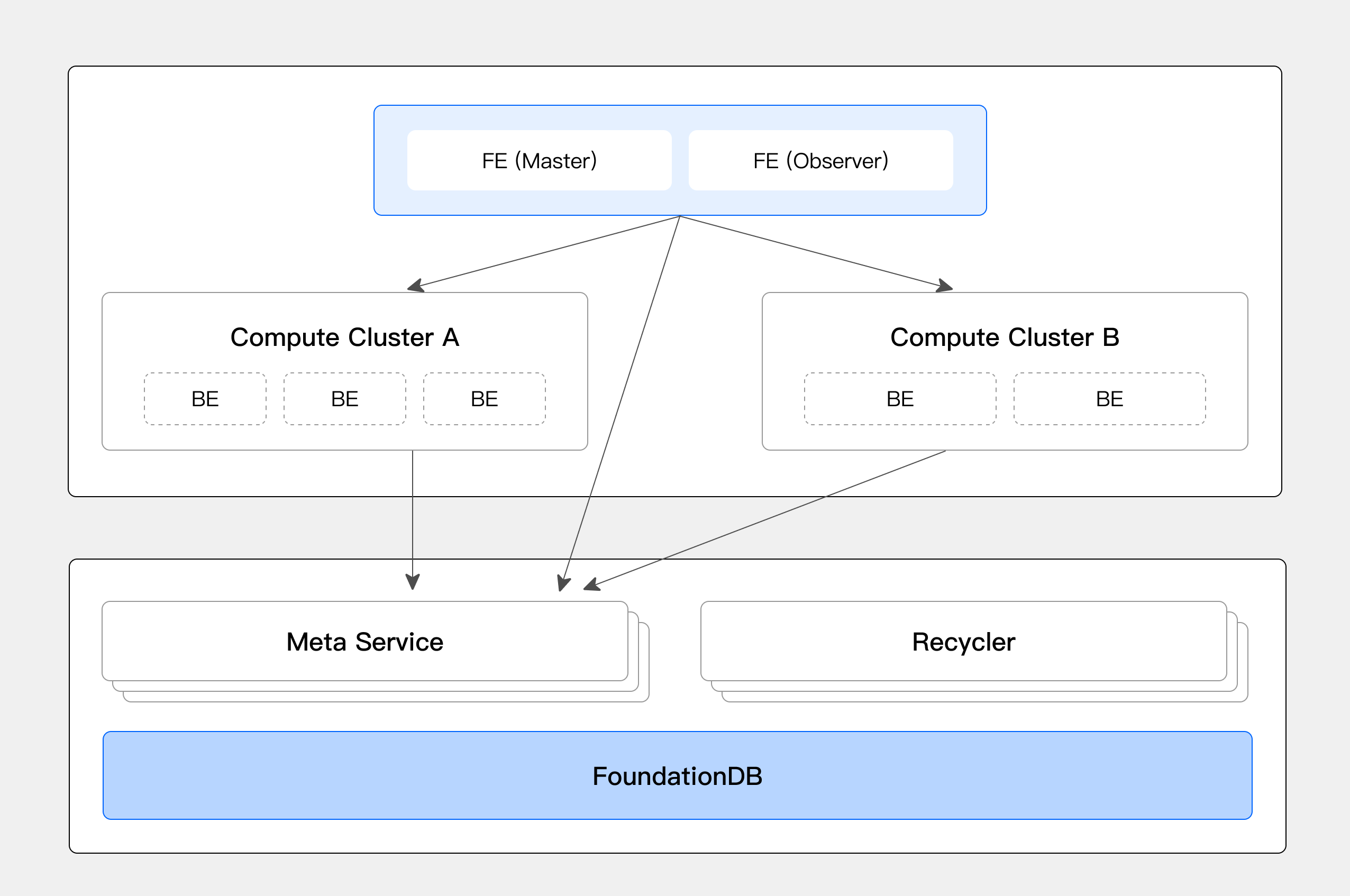
Doris 存算分离架构部署方式示意图如下,共需要 3 个模块参与工作:
- FE:负责接收用户请求,负责存储库表的元数据,目前是有状态的,未来会和 BE 类似,演化为无状态。
- BE:无状态化的 Doris BE 节点,负责具体的计算任务。BE 上会缓存一部分 Tablet 元数据和数据以提高查询性能。
- MS:存算分离模式新增模块,程序名为 doris_cloud,可通过启动不同参数来指定为以下两种角色之一
- Meta Service:元数据管理,提供元数据操作的服务,例如创建 Tablet,新增 Rowset,Tablet 查询以及 Rowset 元数据查询等功能。
- Recycler:数据回收。通过定期对记录已标记删除的数据的元数据进行扫描,实现对数据的定期异步正向回收(文件实际存储在 S3 或 HDFS 上),而无须列举数据对象进行元数据对比。

Meta Service 是一种无状态化的服务,依赖了一个高性能分布式事务 KV(即 FoundationDB)来存储元数据,大幅简化了元数据管理流程,同时提供强大的横向的扩展能力。
Doris 存算分离架构依赖于两个外部开源项目,为确保部署顺利,请在开始前预先安装以下依赖:
- FoundationDB (FDB)
- OpenJDK17: 需要安装到所有部署 Meta Service 的节点上。
二、环境信息
2.1 硬件信息
- CPU架构:X86_64
2.2 软件信息
- Doris版本:3.0.0
- JDK版本:OpenJDK17
- FoundationDB:7.1.38
- 系统:Linux VM-10-6-centos
三、前置准备
动手先,先梳理下安装步骤。
Doris 存算分离模式部署按照模块与分工"自下而上"部署:
- 官方手册文档浏览:https://doris.apache.org/zh-CN/docs/dev/compute-storage-decoupled/before-deployment
- 存算分离模式机器规划。
- 部署 FoundationDB 以及运行环境(JDK17)等基础的依赖,这一步骤不需要 Doris 的编译产出即可完成。
- 部署 Meta Service以及 Recycler
- 部署 FE 以及 BE
注意:一套 FoundationDB + Meta Service + Recycler 基础环境可以支撑多个存算分离模式的 Doris 实例(即多套 FE + BE )。
四、FoundationDB安装
通常情况下,需要至少 3 台机器组成一个双副本、允许单机故障的 FoundationDB 集群。如果仅出于开发/测试需要,使用一台机器即可。
本文先以一台测试为例。
4.1 安装包下载
每台机器都需先安装 FoundationDB 服务。可通过以下地址选择一个版本下载 FoundationDB 安装包,目前通常推荐使用 7.1.38 版本。
对于 CentOS (Red Hat) 和 Ubuntu 用户,以下是下载链接:
- clients-x86_64.rpm
- server-x86_64.rpm
- clients-amd64.deb
- server-amd64.deb
如果需要更高速的下载,也可使用如下镜像链接:
- clients-x86_64.rpm
- server-x86_64.rpm
- clients-amd64.deb
- server-amd64.deb
-- client
wget https://selectdb-doris-1308700295.cos.ap-beijing.myqcloud.com/toolkit/fdb/foundationdb-clients-7.1.38-1.el7.x86_64.rpm
-- server
wget https://selectdb-doris-1308700295.cos.ap-beijing.myqcloud.com/toolkit/fdb/foundationdb-server-7.1.38-1.el7.x86_64.rpm
4.2 安装部署
可以使用如下命令安装 FoundationDB 程序:
sudo rpm -Uvh foundationdb-clients-7.1.38-1.el7.x86_64.rpm foundationdb-server-7.1.38-1.el7.x86_64.rpm

安装完毕后,在命令行输入 fdbcli 查看是否安装成功。若返回结果显示如下 available 字样,则表示安装成功:
[zhangbinhua@VM-10-6-centos package]$ fdbcli
Using cluster file `/etc/foundationdb/fdb.cluster'.
The database is available.
Welcome to the fdbcli. For help, type `help'.

安装成功后:
- 默认将启动一个 FoundationDB 服务。
- 默认集群信息文件 fdb.cluster将存放在/etc/foundationdb/fdb.cluster,默认集群配置文件 foundationdb.conf 将存放在/etc/foundationdb/foundationdb.conf。
- 默认将数据和日志分别保存在/var/lib/foundationdb/data/和/var/log/foundationdb。
- 默认将新建一个 FoundationDB 的 user 和 group,数据和日志的路径默认已具备 FoundationDB 的访问权限。
五、OpenJDK 17安装
OpenJDK 17 需安装到所有的节点上,可通过以下链接获取安装OpenJDK 17:
https://download.java.net/java/GA/jdk17.0.1/2a2082e5a09d4267845be086888add4f/12/GPL/openjdk-17.0.1_linux-x64_bin.tar.gz
wget https://download.java.net/java/GA/jdk17.0.1/2a2082e5a09d4267845be086888add4f/12/GPL/openjdk-17.0.1_linux-x64_bin.tar.gz
然后,将下载好的 OpenJDK 安装包直接解压到安装路径即可:
tar xf openjdk-17.0.1_linux-x64_bin.tar.gz
启动 Meta Service 或者 Recycler 之前
export JAVA_HOME=/opt/jdk-17.0.1
六、 Meta Service安装
相比 3.0.0 之前的版本,编译完成的二进制包中(产出)多了 ms 目录。

ms目录将同时用于 Meta Service 和 Recycler 两种进程。 需要注意的是,尽管 Meta Service 和 Recycler 在本质上属于同一程序,但目前需要分别为它们准备独立的二进制文件,以及工作目录。 Meta Service 和 Recycler 两个工作目录除了配置完全一致,使用不同启动参数启动。
要准备两份二进制文件/工作目录,只需使用以下命令从ms目录中拷贝二进制文件至一个新的 Recycler 工作目录re,然后在ms和re的conf子目录下,对端口号等参数按需进行必要修改即可。详细的配置启动会在本文后续章节介绍。
cp -r ms re

6.1 Meta Service配置
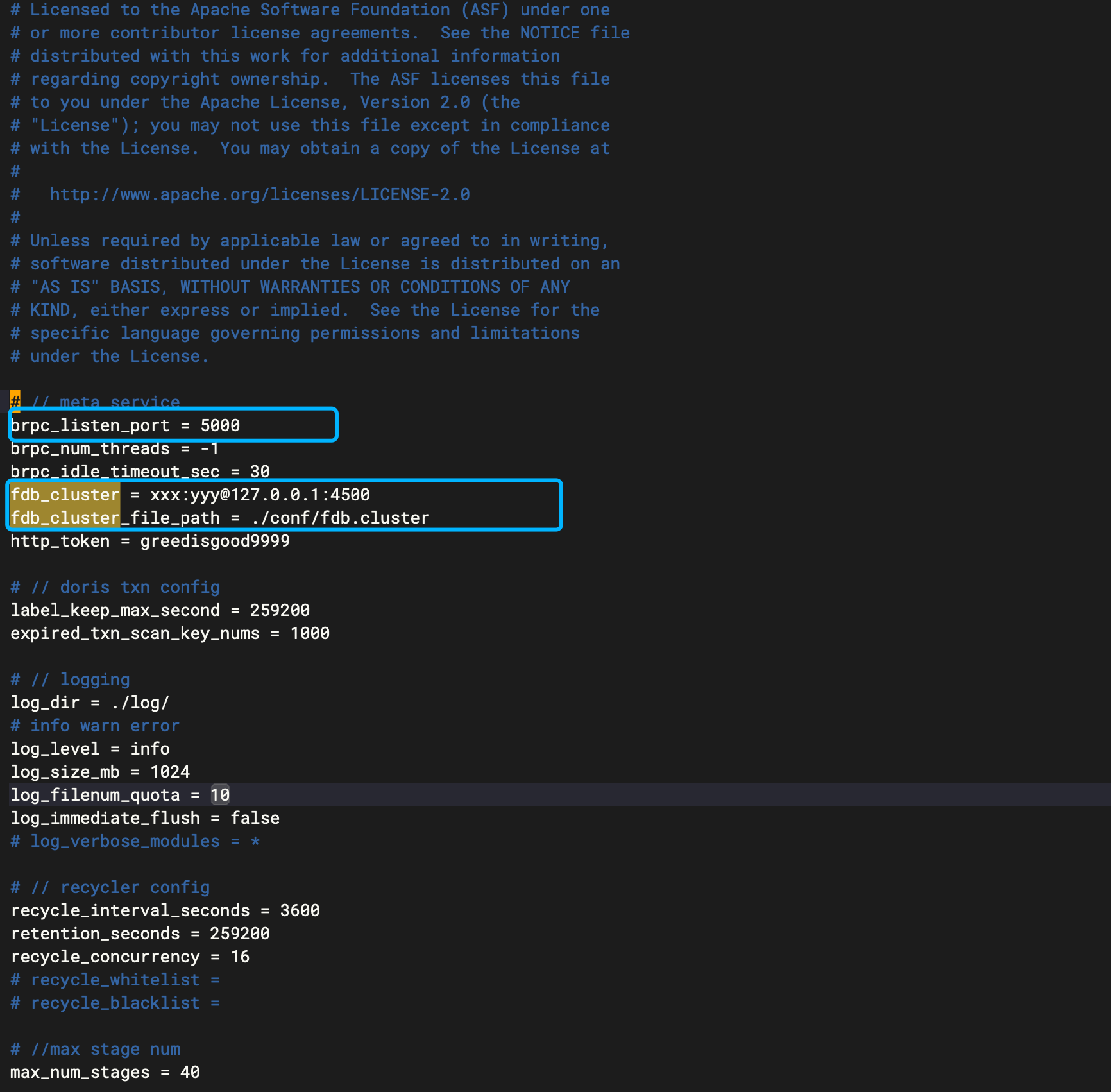
# 通常情况下,只需在
./apache-doris-3.0.0-bin-x64/ms/conf
目录下的默认配置文件
doris_cloud.conf中修改 brpc_listen_port
和 fdb_cluster 两个参数。
(Meta Service 配置只需一个配置文件。)
brpc_listen_port = 5000
fdb_cluster = xxx:yyy@127.0.0.1:4500
上述 brpc_listen_port = 5000 是 Meta Service 的默认端口。其中,fdb_cluster 是 FoundationDB 集群的连接信息,通常可从 FoundationDB 所部署机器上的 /etc/foundationdb/fdb.cluster 文件中获得。
6.2 Recycler配置
除了端口外,Recycler 的其他默认配置均与 Meta Service 相同。Recycler 的 bRPC 端口一般采用 5100。
# 通常情况下,只需在
./apache-doris-3.0.0-bin-x64/re/conf
目录下的默认配置文件
doris_cloud.conf中修改 brpc_listen_port
和 fdb_cluster 两个参数。
(Recycler 配置只需一个配置文件。)
brpc_listen_port = 5100
fdb_cluster = xxx:yyy@127.0.0.1:4500
上述 brpc_listen_port = 5100 是 Recycler 的默认端口。其中,fdb_cluster 是 FoundationDB 集群的连接信息,通常可从 FoundationDB 所部署机器上的 /etc/foundationdb/fdb.cluster 文件中获得。
6.3 MS服务启动
Meta Service 和 Recycler 依赖 JAVA 运行环境,并使用 OpenJDK 17。在启动前这两个服务前,请确保已正确设置 export JAVA_HOME 环境变量。
doris_cloud 部署的 bin 目录下提供了启停脚本,调用对应的启停脚本即可完成启停。
6.3.1 启停 Meta Service
# 确保为jdk17的环境
export JAVA_HOME=${path_to_jdk_17}
# 进入meta-service目录
cd ./apache-doris-3.0.0-bin-x64/ms/bin
# 后台启动meta-service
bin/start.sh --meta-service --daemon
# 停止meta-service
bin/stop.sh
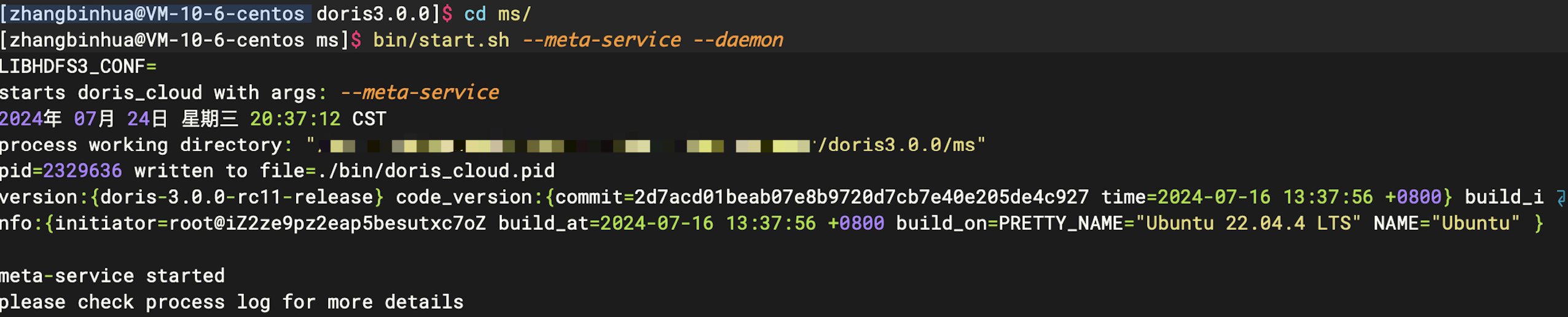
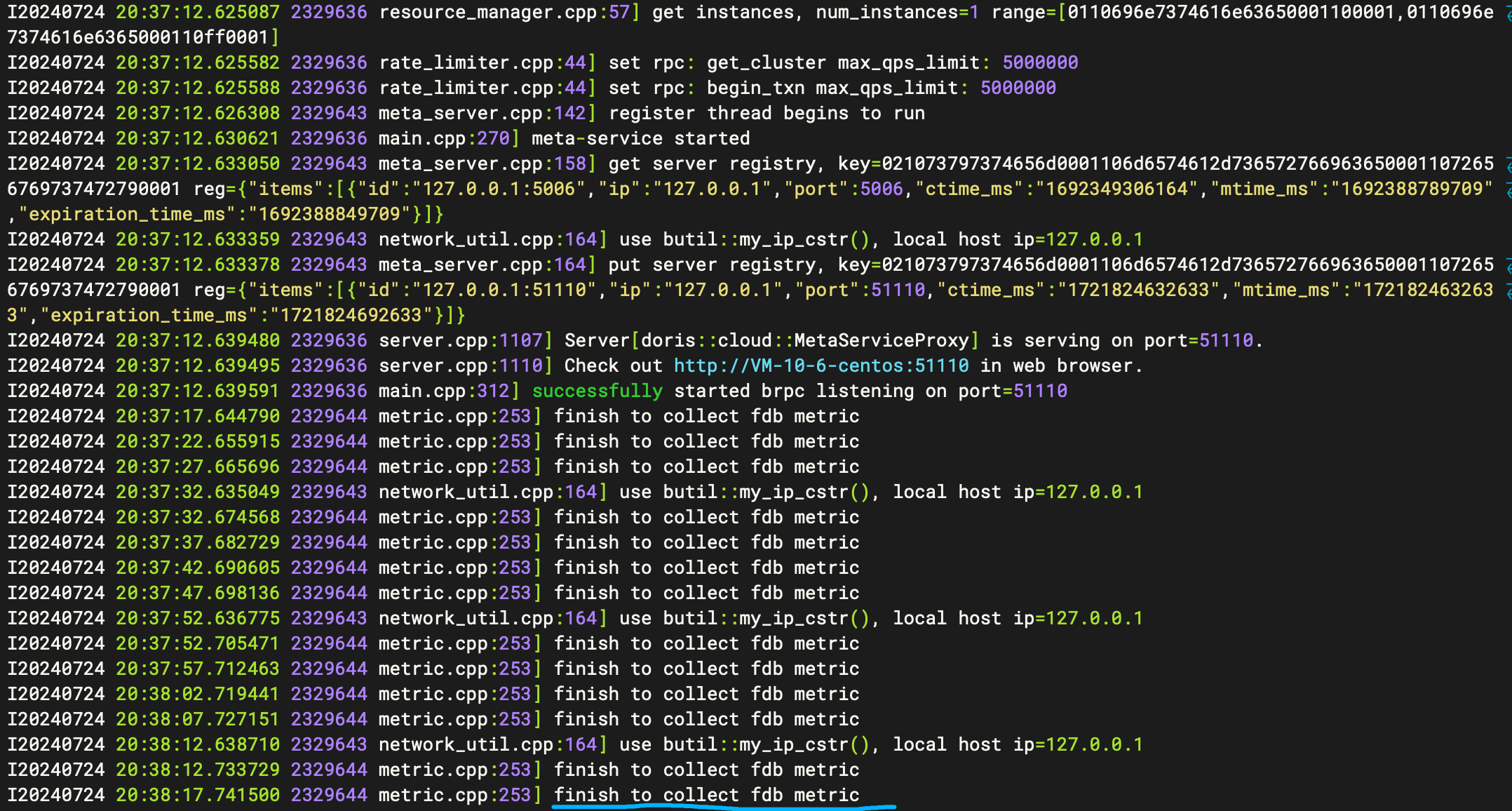
此时再查看下ms/log确认
# 滚动打印 finish to collect fdb metric 表示ms启动成功!
tail -100f meta_service.INFO
6.3.2 启停 Recycler
# 进入recycler目录
cd ./apache-doris-3.0.0-bin-x64/re/bin
# 后台启动recycler
bin/start.sh --recycler --daemon
# 停止recycler
bin/stop.sh

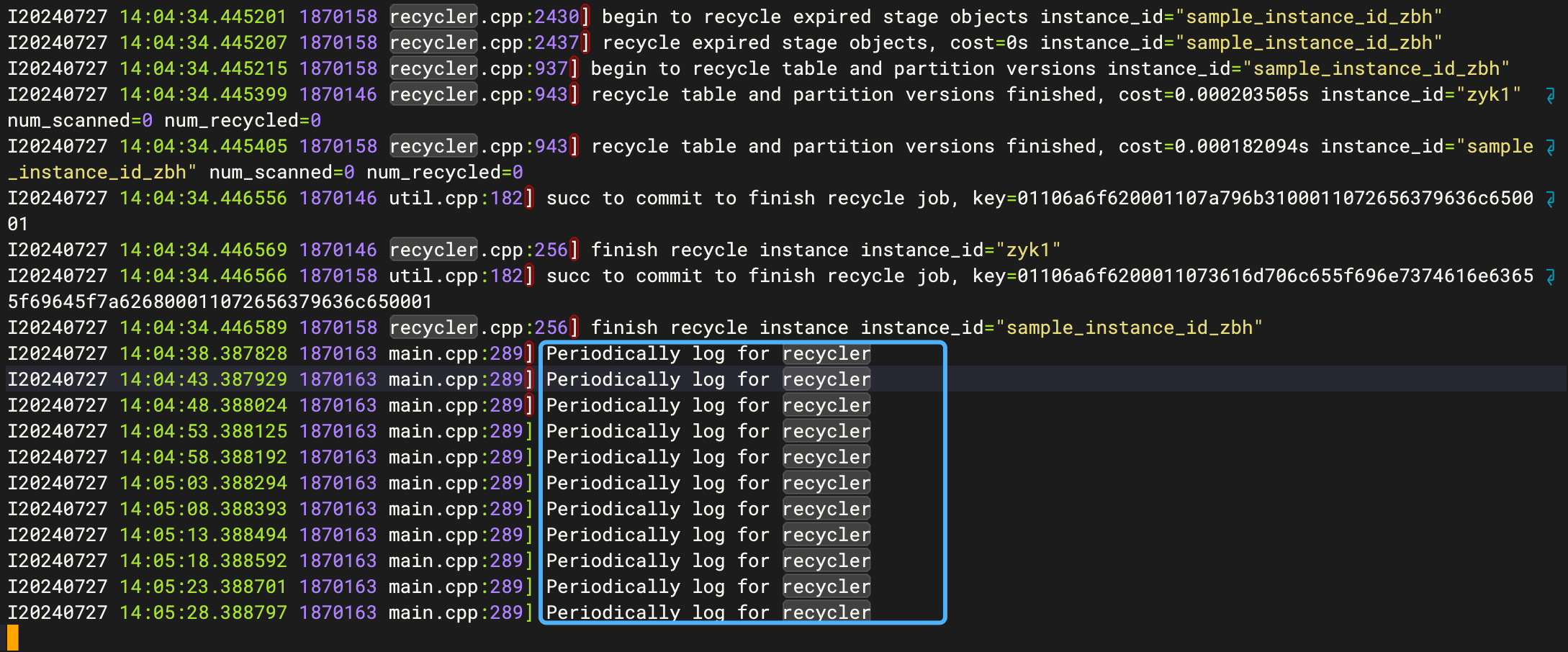
此时再查看下re/log确认
# 滚动打印 Periodically log for recycler 表示ms启动成功!
tail -100f recycler.INFO
在成功部署并启动 Meta Service 和 Recycler 之后,Doris 存算分离模式的底座便已完成搭建。
七、集群安装
前文部署的一套 FoundationDB + Meta Service + Recycler 基础环境可以支撑多个存算分离集群,一个存算分离集群又称为一个数仓实例(Instance)。
在存算分离架构下,数仓实例的节点构成信息由 Meta Service 维护(注册 + 变更)。FE、BE 和 Meta Service 交互以实现服务发现和身份验证。创建存算分离集群主要涉及与 Meta Service 的交互,Meta Service 提供了标准的 HTTP 接口进行资源管理操作。
Doris 存算分离模式采用服务发现的机制进行工作,创建存算分离集群可以归纳为以下步骤:
- 注册FE/BE:注册声明数仓实例中的 FE 和 BE 节点组成,分别包含哪些机器,以及如何组成集群。
- 安装FE/BE:配置并启动所有的 FE 和 BE 节点。
- 注册存储后端:注册声明数仓实例以及它的存储后端。
7.1 注册FE/BE
7.1.1 添加FE
存算分离模式下,FE 以及 BE 的节点管理使用的接口相同,仅参数配置不同, 可通过 Meta Service add_cluster 接口先进行 FE 以及 BE 的初始节点添加。
add_cluster 接口的参数列表如下:
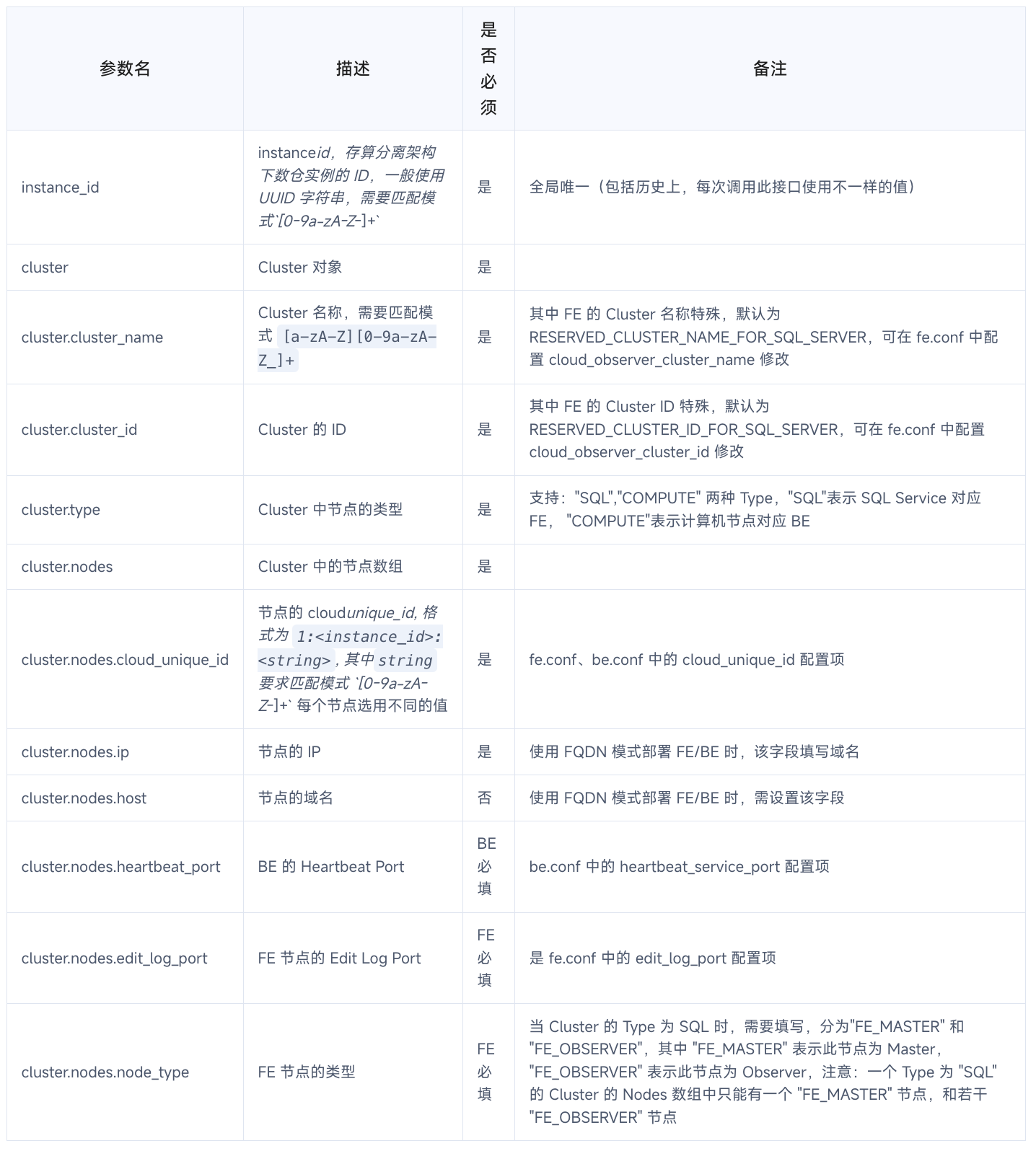
以下为添加一个 FE 的示例,cloud_unique_id自定义为
1:sample_instance_id:zbh_cloud_unique_id_sql_server00
# 示例
# 添加 FE
curl '127.0.0.1:5000/MetaService/http/add_cluster?token=greedisgood9999' -d '{
"instance_id":"sample_instance_id",
"cluster":{
"type":"SQL",
"cluster_name":"RESERVED_CLUSTER_NAME_FOR_SQL_SERVER",
"cluster_id":"RESERVED_CLUSTER_ID_FOR_SQL_SERVER",
"nodes":[
{
"cloud_unique_id":"1:sample_instance_id:zbh_cloud_unique_id_sql_server00",
"ip":"172.21.16.21",
"edit_log_port":12103,
"node_type":"FE_MASTER"
}
]
}
}'
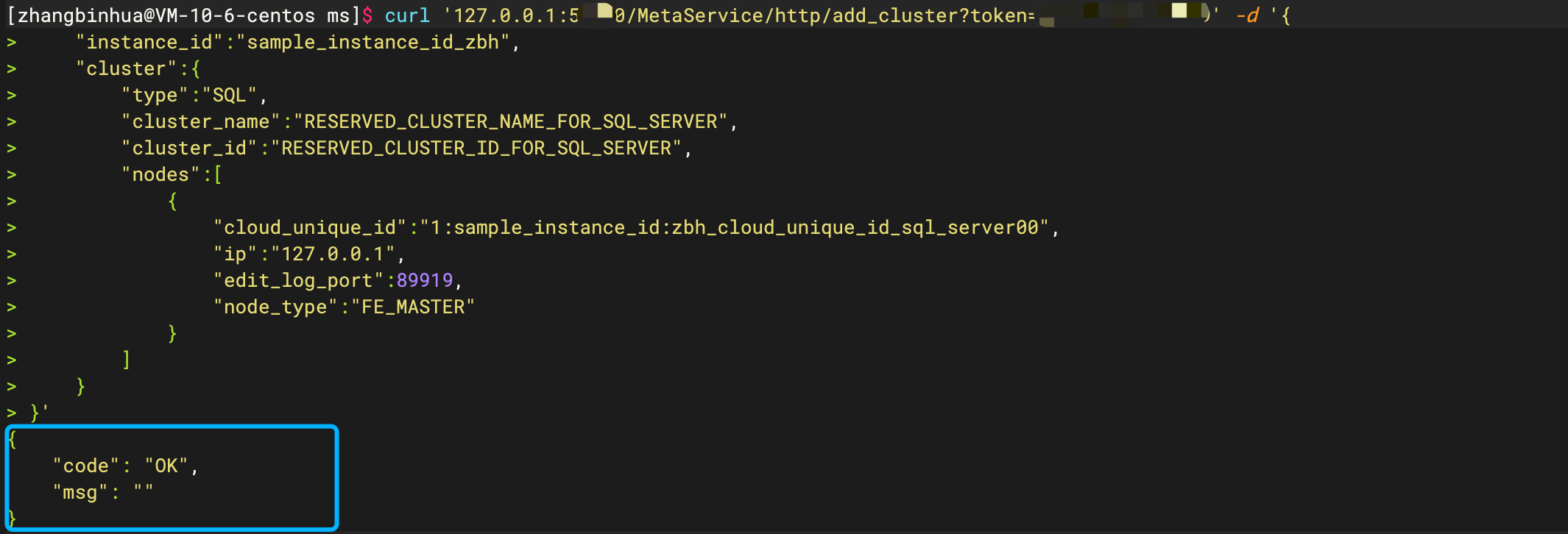
# 示例
# 创建成功后,可以通过 get_cluster 返回值 进行确认
curl '127.0.0.1:5000/MetaService/http/get_cluster?token=greedisgood9999' -d '{
"instance_id":"sample_instance_id",
"cloud_unique_id":"1:sample_instance_id:cloud_unique_id_sql_server00",
"cluster_name":"RESERVED_CLUSTER_NAME_FOR_SQL_SERVER",
"cluster_id":"RESERVED_CLUSTER_ID_FOR_SQL_SERVER"
}'
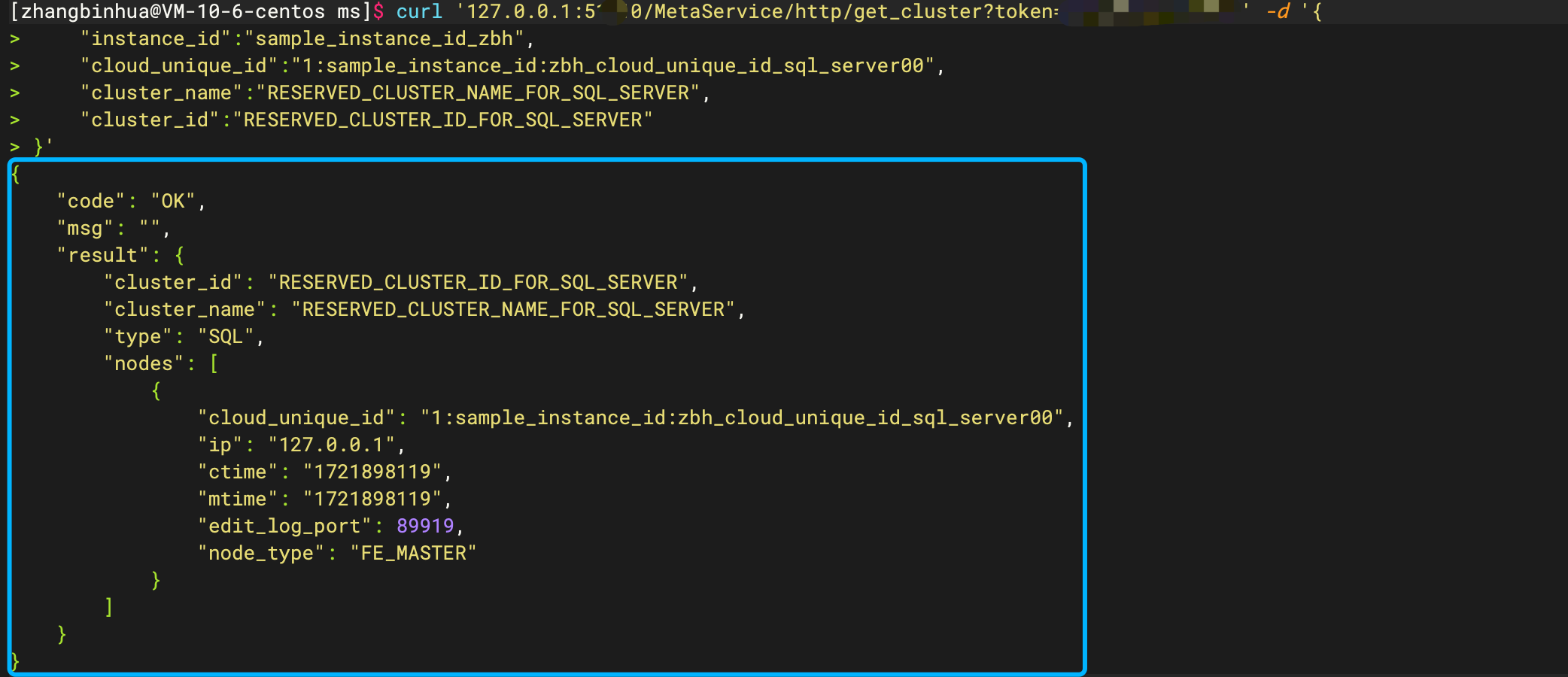
7.1.2 添加BE
用户可创建一个或多个计算集群,一个计算集群由任意多个 BE 节点组成。 创建计算集群操作也可通过 Meta Service add_cluter 接口进行。
接口描述详见前文 “添加 FE” 章节。
用户可根据实际需求调整计算集群的数量及其所包含的节点数量,不同的计算集群需要使用不同的 cluster_name 和 cluster_id。
如下是创建包含 1 个 BE 的 计算集群:
# 示例
# 添加 BE
curl '127.0.0.1:5000/MetaService/http/add_cluster?token=greedisgood9999' -d '{
"instance_id":"sample_instance_id",
"cluster":{
"type":"COMPUTE",
"cluster_name":"cluster_name0",
"cluster_id":"cluster_id0",
"nodes":[
{
"cloud_unique_id":"1:sample_instance_id:cloud_unique_id_compute_node0",
"ip":"172.21.16.21",
"heartbeat_port":9455
}
]
}
}'
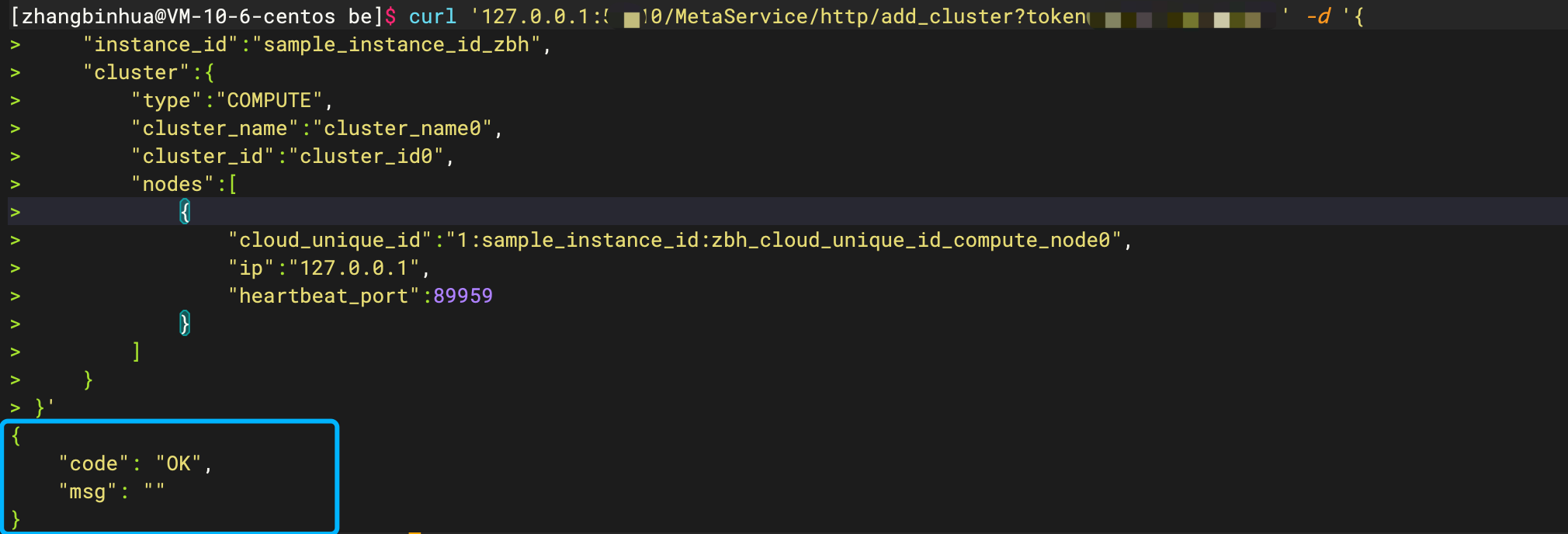
# 示例
# 创建成功后,通过 get_cluster 进行确认
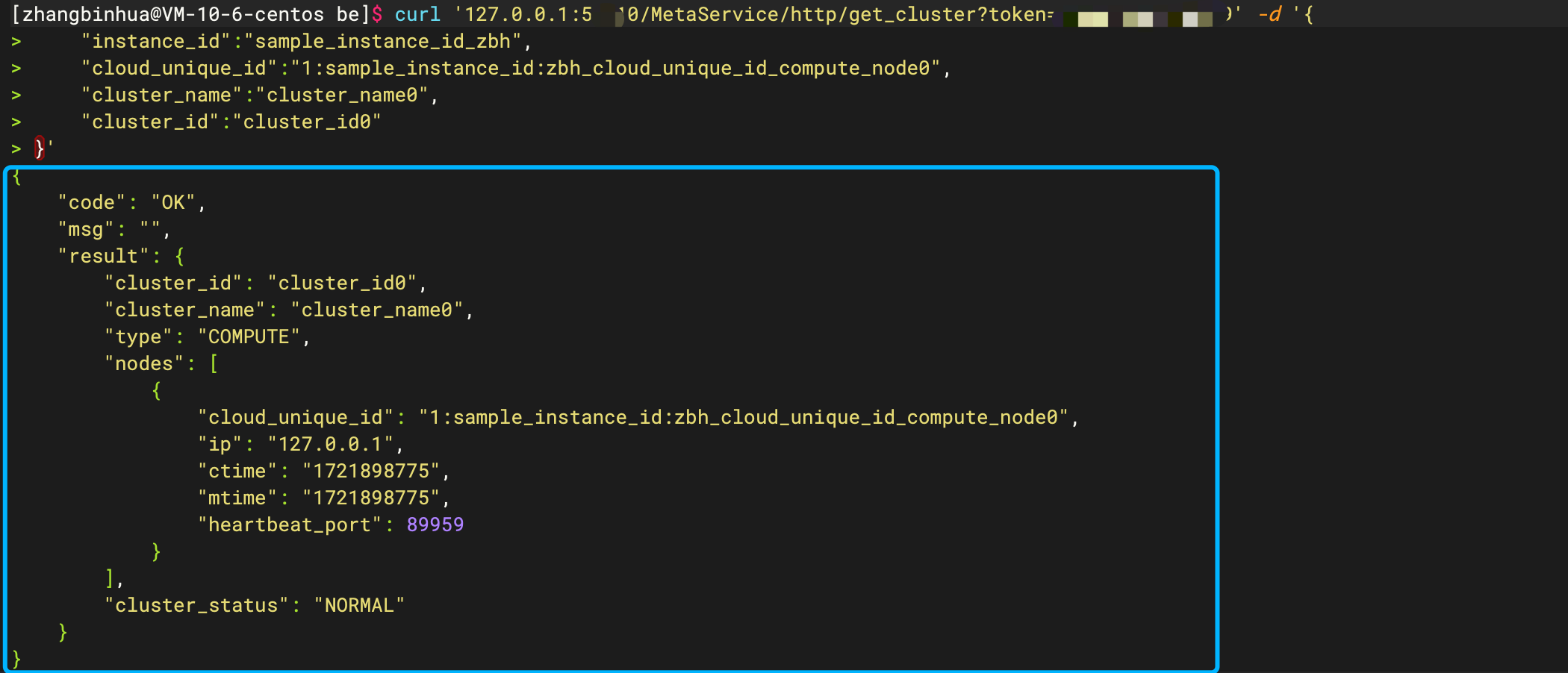
curl '127.0.0.1:5000/MetaService/http/get_cluster?token=greedisgood9999' -d '{
"instance_id":"sample_instance_id",
"cloud_unique_id":"1:sample_instance_id:cloud_unique_id_compute_node0",
"cluster_name":"cluster_name0",
"cluster_id":"cluster_id0"
}'
7.3 安装FE/BE
7.3.1 FE/BE 配置
相较于存算一体模式,存算分离模式下的 FE 和 BE 增加了部分配置,其中:
- meta_service_endpoint:Meta Service 的地址,需在 FE 和 BE 中填写。
- cloud_unique_id:根据创建存算分离集群发往 Meta Service add_cluster 请求中的实际值填写即可;Doris 通过该配置的值确定是否在存算分离模式下工作。可自定义!
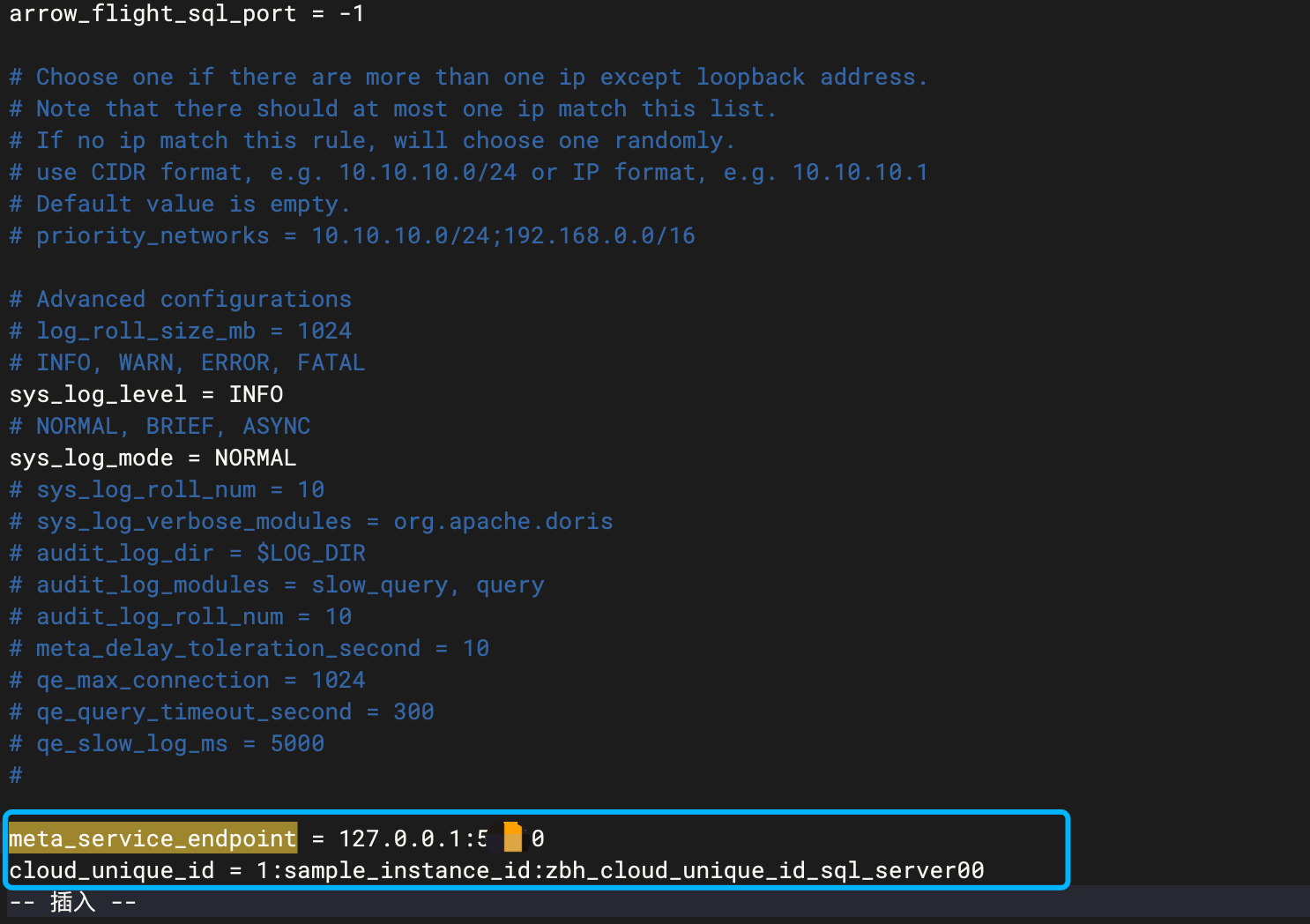
fe.conf
# 示例
meta_service_endpoint = 127.0.0.1:5000
cloud_unique_id = 1:sample_instance_id:cloud_unique_id_sql_server00
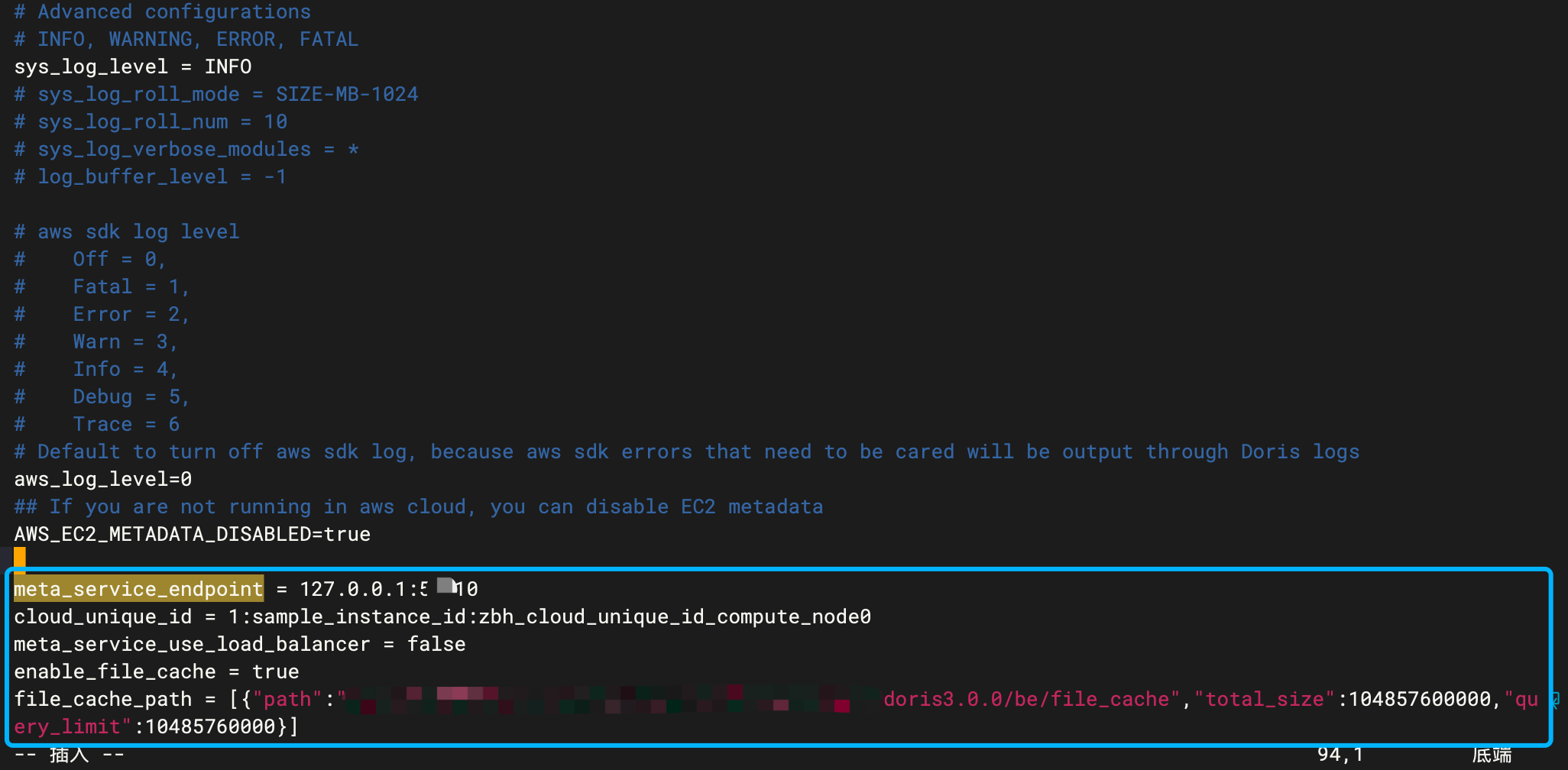
be.conf
下述示例中, meta_service_use_load_balancer 和 enable_file_cache 均可复制,其他配置项需根据实际情况填写。
file_cache_path 是一个 JSON 数组(根据实际缓存盘的个数配置),其各个字段含义如下:
- path:缓存数据存放路径,类似于存算一体模式下的 storage_root_path
- total_size:期望使用的缓存空间上限
- query_limit:单个查询在缓存未命中时最多可淘汰的缓存数据量(为了防止大查询将缓存全部淘汰);因缓存需要存放数据,所以最好使用 SSD 等高性能磁盘作为缓存存储介质。
# 示例
meta_service_endpoint = 127.0.0.1:5000
cloud_unique_id = 1:sample_instance_id:cloud_unique_id_compute_node0
meta_service_use_load_balancer = false
enable_file_cache = true
file_cache_path = [{"path":"/mnt/disk1/doris_cloud/file_cache","total_size":104857600000,"query_limit":10485760000}, {"path":"/mnt/disk2/doris_cloud/file_cache","total_size":104857600000,"query_limit":10485760000}]
7.3.2 FE/BE 启停
Doris 存算分离模式下,FE/BE 启停方式和存算一体模式下的启停方式一致。 存算分离模式属于服务发现的模式,不需通过 alter system add/drop frontend/backend 等命令操作节点。
# 示例
bin/start_be.sh --daemon
bin/stop_be.sh
启动成功后jps可以查看对应新增be进程,并查看./log/be.INFO日志,正常启动日志如下:
bin/start_fe.sh --daemon
bin/stop_fe.sh
启动成功后jps可以查看对应新增fe进程,并查看./log/fe.log日志,正常启动日志如下:
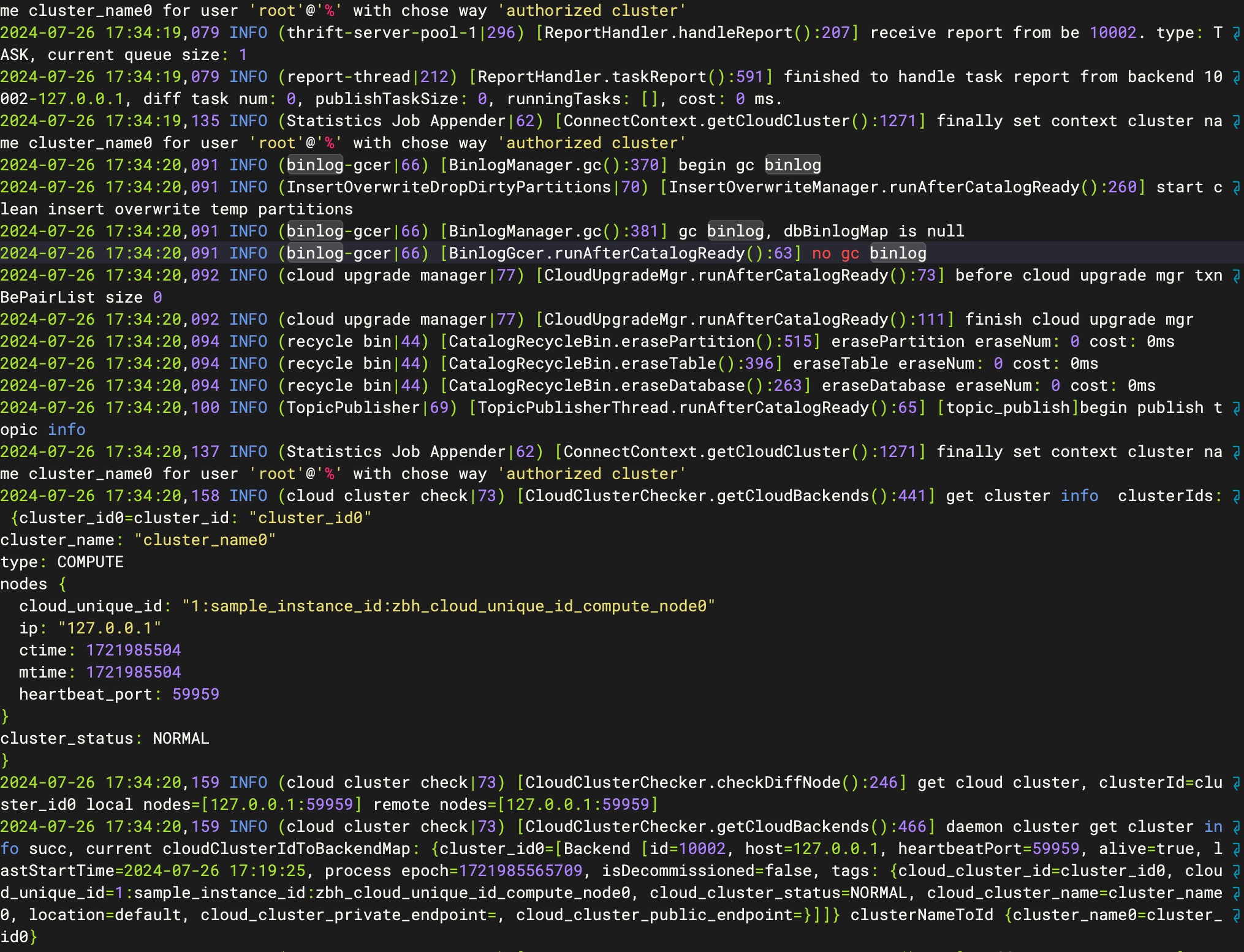
启动后观察日志,如果上述配置均正确,则说明已进入正常工作模式,可通过 MySQL 客户端连接 FE 进行访问。
mysql -uroot -h 10.16.10.6 -P 9030 -p
7.4 注册存储后端
本文以基于 S3 的存算分离模式 Doris 集群为例。
存储后端是 Doris 在存算分离模式中所使用的远程共享存储,可配置一个或多个存储后端,可将不同表存储在不同存储后端上。
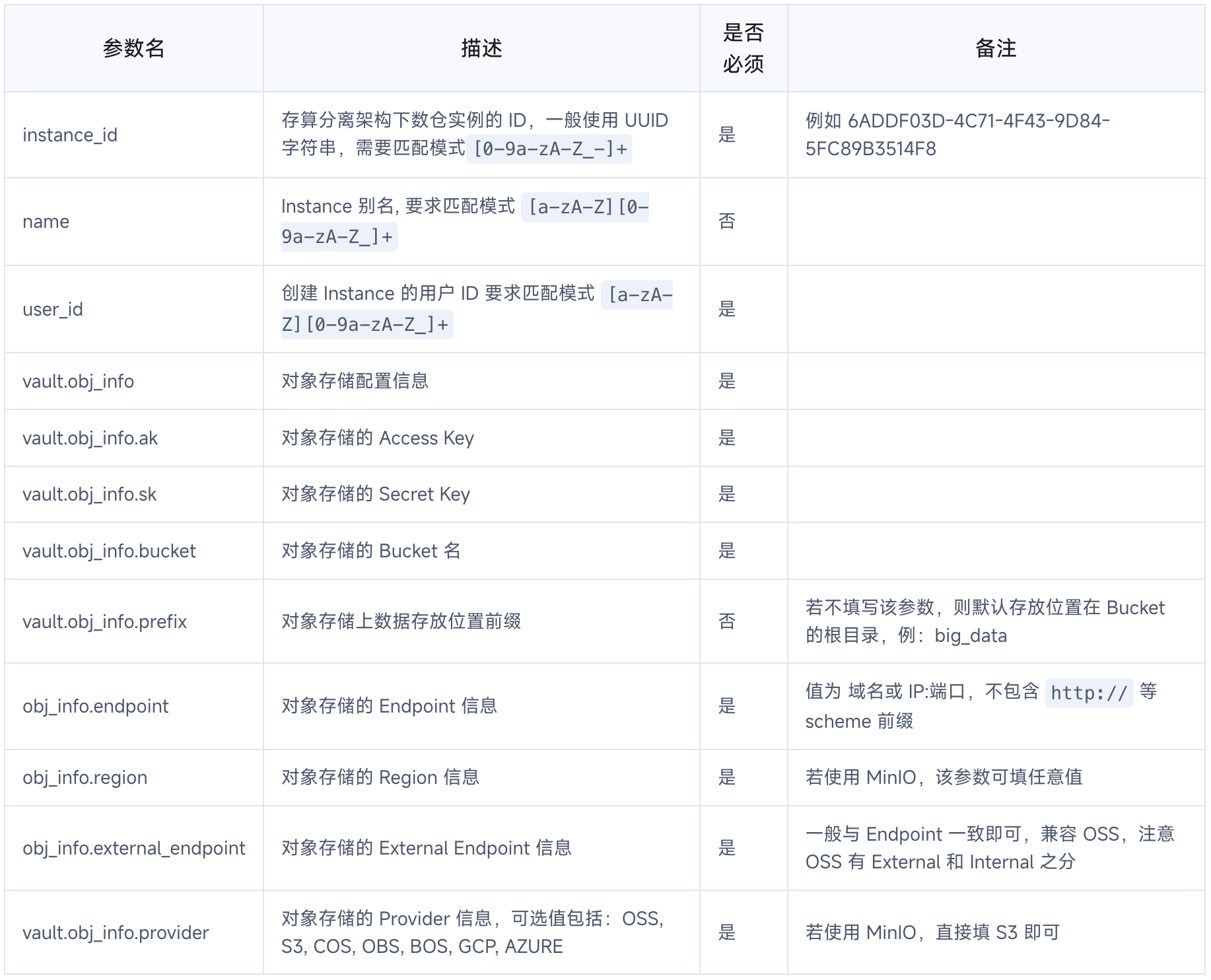
基于对象存储的所有属性均为必填项,其中:
- 使用 MinIO 等支持 S3 协议的对象存储时,需要自行测试连通性以及 AK / SK 的正确性。具体做法可参考使用 AWS CLI 验证 MinIO 是否工作。
- Bucket 字段的值为 Bucket 名称,不包含 s3:// 等 schema。
- external_endpoint 保持与 endpoint 值相同即可。
- 如果使用非云厂商对象存储,region 和 provider 可填写任意值。
# 示例
curl -s "127.0.0.1:5000/MetaService/http/create_instance?token=greedisgood9999" -d \
'{
"instance_id": "sample_instance_id",
"name": "sample_instance_name",
"user_id": "sample_user_id",
"vault": {
"obj_info": {
"ak": "ak_xxxxxxxxxxx",
"sk": "sk_xxxxxxxxxxx",
"bucket": "sample_bucket_name",
"prefix": "sample_prefix",
"endpoint": "cos.ap-beijing.myqcloud.com",
"external_endpoint": "cos.ap-beijing.myqcloud.com",
"region": "ap-beijing",
"provider": "COS"
}
}
}'
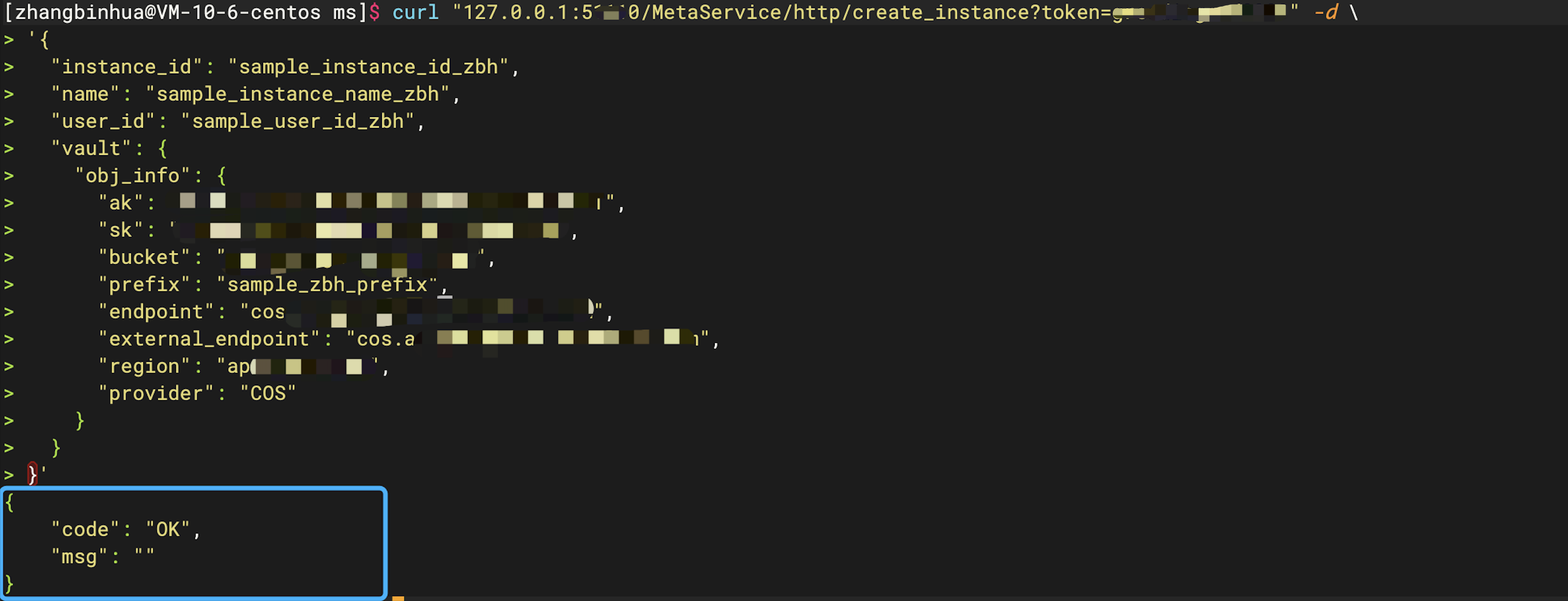
创建完成后通过如下语句,在MySQL 客户端连接 FE 进行查看存储后端验证
# MySQL 客户端连接 FE
mysql -uroot -h 10.16.10.6 -P 9030 -p
# 查看存储后端
SHOW STORAGE VAULT\G
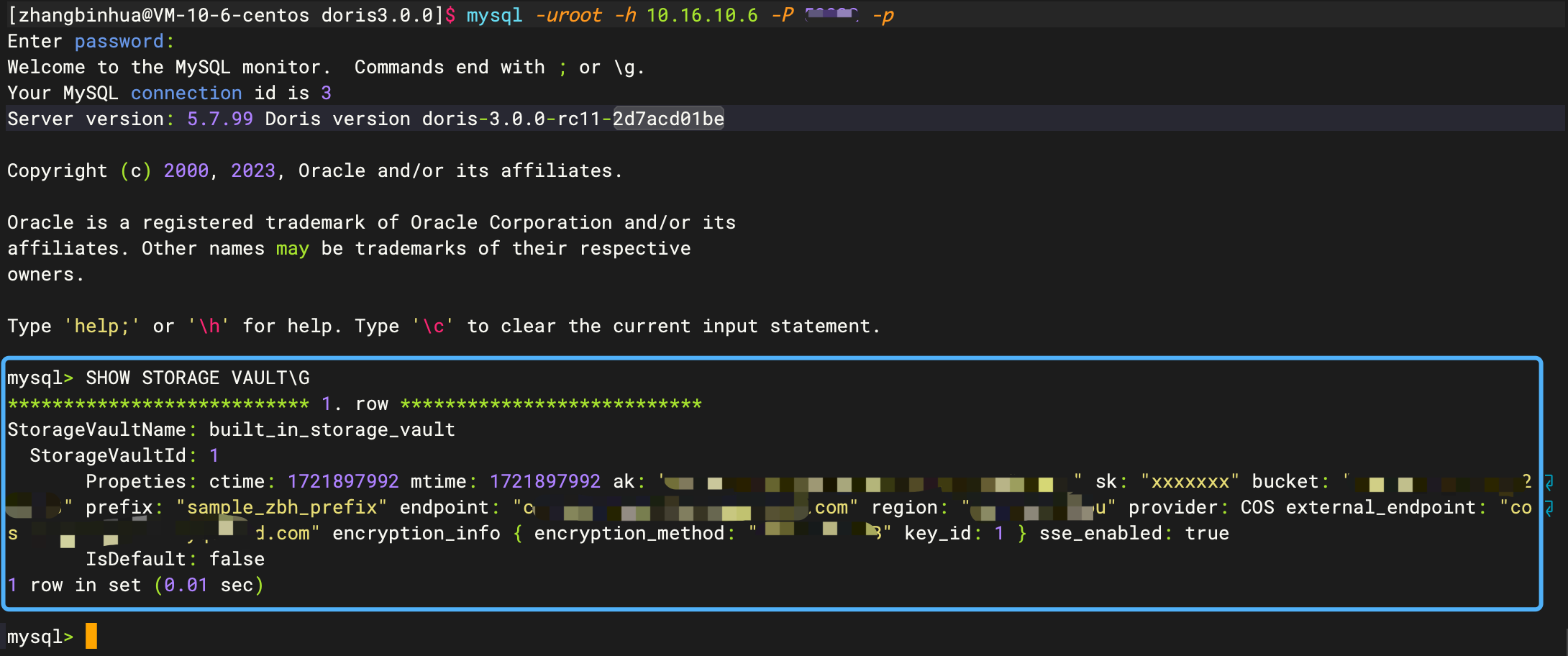
在成功注册FE/BE、安装FE/BE和注册存储后端之后,单节点的Doris存算分离集群构建完成,需要构建多节点Doris存算分离集群的小伙伴可以结合官方文档进行部署。
八、快速体验
MySQL 客户端连接 FE 测验。
8.1 查看计算集群
-- 通过 show clusters 查看当前仓库拥有的所有计算集群。
show clusters;

8.2 创建表
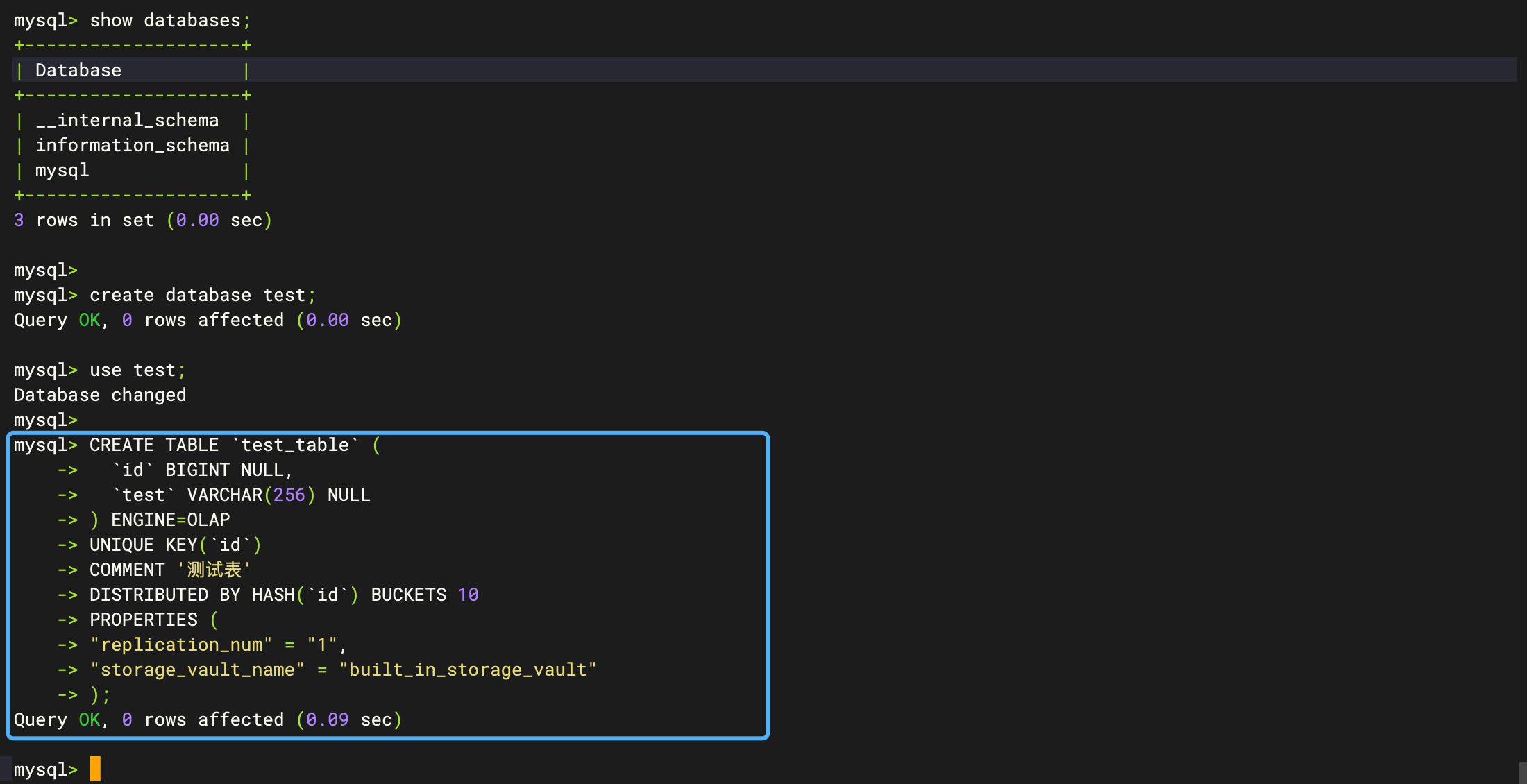
存算分离模式下,建表时在 PROPERTIES 中需要指定 storage_vault_name,则数据会存储在指定 vault name 所对应的存储后端上。建表成功后,该表不允许再修改 storage_vault,即不支持更换存储后端。
storage_vault_name 可以通过 SHOW STORAGE VAULT 查看存储后端的结果进行选择。

-- 创建测试库
create database test;
-- 选择测试库
use test;
-- 创建测试表
CREATE TABLE `test_table` (
`id` BIGINT NULL,
`test` VARCHAR(256) NULL
) ENGINE=OLAP
UNIQUE KEY(`id`)
COMMENT '测试表'
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES (
"replication_num" = "1",
"storage_vault_name" = "built_in_storage_vault"
);
8.3 数据写入
-- 生产不建议 INSERT INTO VALUES,仅测试用
INSERT INTO test_table VALUES (1,'TEST01'),(2,'TEST02'),(3,'TEST03');

8.4 查询测试
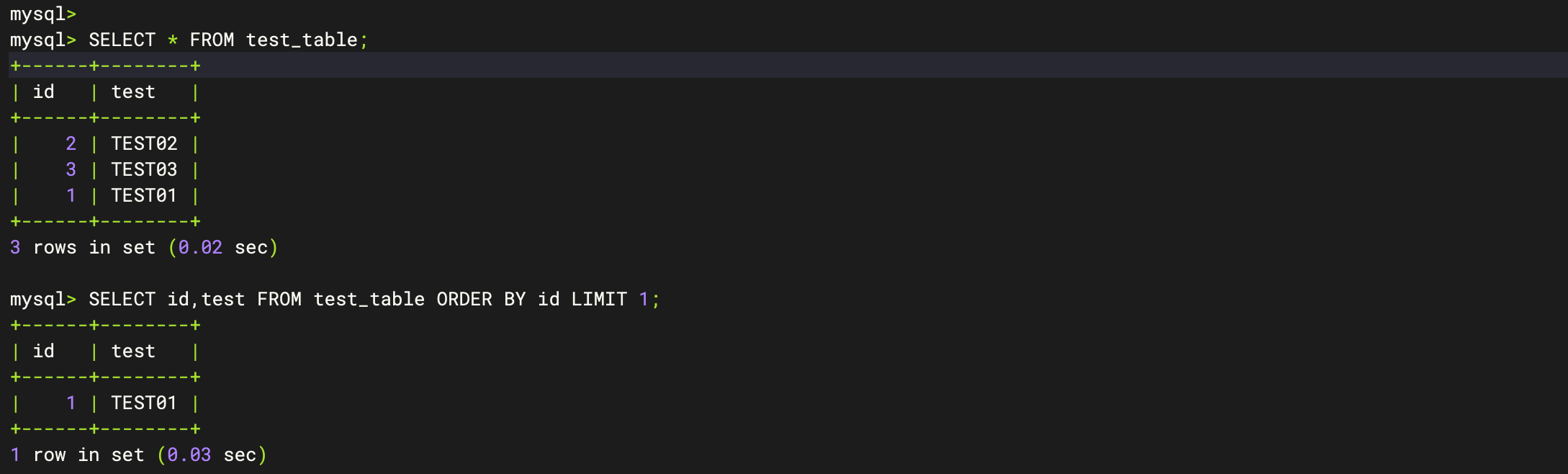
-- 查验数据完整性
SELECT * FROM test_table;
-- 查询数据准确性
SELECT id,test FROM test_table ORDER BY id LIMIT 1;
至此,Doris 3.0 存算分离|单节点标准部署实践Over。