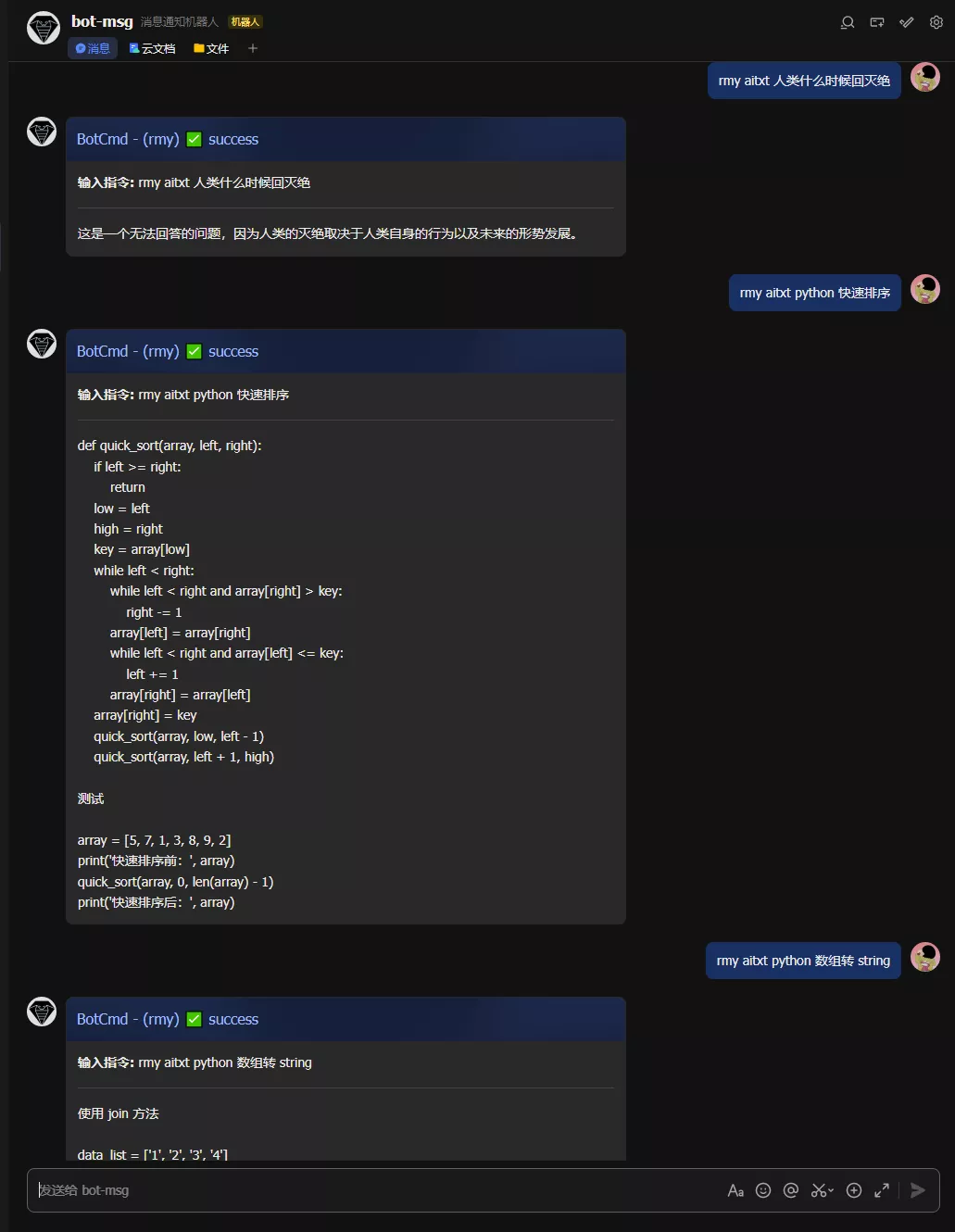
OpenMMLab AI实战课笔记 -- 第2节课
- 1. 第二节课(图像分类)
- 1.1 深度学习模型
- 1.2 网络进化过程
- 1.3 ResNet (残差网络)
- 1.4 卷积的参数量
- 1.5 卷积的计算量(乘加次数)
- 1.6 降低模型参数量和计算量的方法
- 1.7 可分离卷积
- 1.8 注意力机制 Attention Mechanism
1. 第二节课(图像分类)
- 图像分类目标:识别图像中有哪些物体
- 视觉任务的难点:图像中的物体是通过图像中的所有像素整体呈现出的效果,与单个像素没有直接关联,难以设计规则算法来处理,所以传统的基于特征的算法(如:HOG、LBP、SIFT等)无法很好地处理这些问题。为更好地解决此问题,既然无法设计规则,就超越规则,让机器自己从数据中学习映射方法。深度学习方法解决了传统特征提取方法的瓶颈。
- 特征的特性:特征对物体的抽象层次越高(即越抽象),其数据的分布就越“规整”,即更易于实现分类。
- 先进的特征提取方法(卷积):
- 特征和图像一样具有二维空间结构,保持了二维空间特征
- 可分层提取可学习的特征(如CNN)
- 可实现一步特征提取(如多头注意力:Transformer)
1.1 深度学习模型
- 模型设计:设计适合图像的
F
θ
(
X
)
F_{\theta}(X)
Fθ(X),模型可分为以下几类:
- 卷积神经网络
- 轻量化卷积神经网络
- 神经结构搜索 (NAS:Neural Architecture Search):
- 基本思路是借助强化学习等方法搜索表现最佳的网络
- 代表作有:NASNet (2017)、MnasNet (2018)、EfficientNet (2019) 、RegNet (2020) 等
- Transformer:
- 使用 Transformer 替代卷积网络实现图像分类,使用更大的数据集训练,达到超越卷积网络的精度
- 其代表作有:Vision Transformer (2020),Swin-Transformer (2021 ICCV 最佳论文) - 模型训练:学习一组好的参数
Θ
\Theta
Θ
- 监督学习:基于标注数据学习 (关键步骤:损失函数、随机梯度下降算法、视觉模型常用训练技巧)
- 自监督学习:基于无标注的数据学习
1.2 网络进化过程

1.3 ResNet (残差网络)
-
残差网络特征
- 让新增加的层拟合浅层网络与深层网络之间的差异
- 更易学习梯度可以直接回传到浅层网络监督浅层网络的学习
- 没有引入额外参数,让参数更有效地贡献到最终的模型中
- 每级输出分辨率减半,通道倍增
- 全局平均池化压缩空间维度
- 单层全连接层产生类别概率
-
ResNet中的两种残差模块
- 1×1 卷积用于压缩通道,降低计算开销

- 1×1 卷积用于压缩通道,降低计算开销
-
残差链接让损失曲面(Loss Surface) 更平滑,更容易收敛到局部/全局最优解

-
图像分类 & 视觉基础模型的发展史

- ConvNeXt (2022):将 Swin Transformer 的模型元素迁移到卷积网络中,性能反超 Transformer
1.4 卷积的参数量

1.5 卷积的计算量(乘加次数)
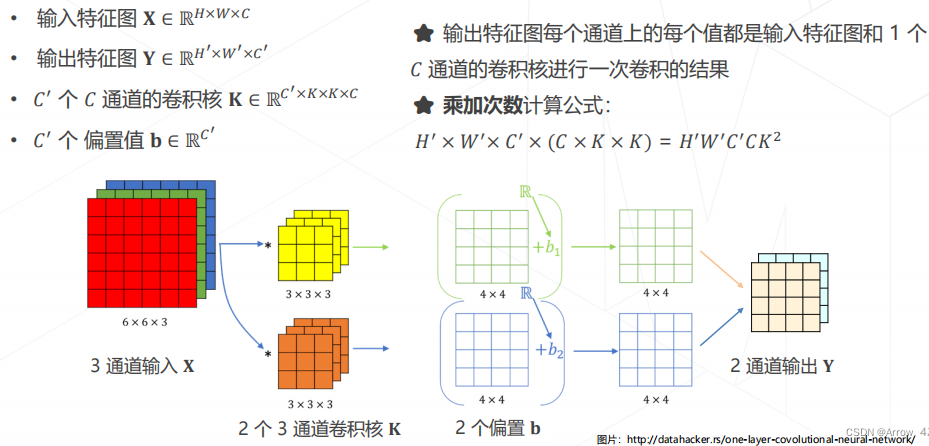
1.6 降低模型参数量和计算量的方法

1.7 可分离卷积
- 将常规卷积分解为逐层卷积和逐点卷积,降低参数量和计算量

- MobileNet V1 使用可分离卷积,只有 4.2M 参数
- MobileNet V2/V3 在 V1 的基础上加入了残差模块和 SE 模块
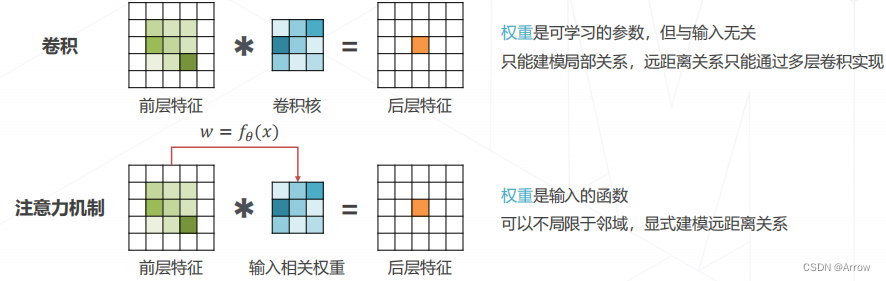
1.8 注意力机制 Attention Mechanism
- 实现层次化特征:
- 后层特征是空间邻域内的前层特征的加权求和
- 权重越大,对应位置的特征就越重要