这个系列文章用"粗快猛+大模型问答+讲故事"的创新学习方法,让你轻松理解复杂知识!涵盖Hadoop、Spark、MySQL、Flink、Clickhouse、Hive、Presto等大数据所有热门技术栈,每篇万字长文。时间紧?只看开头20%就能有收获!精彩内容太多?收藏慢慢看!点击链接开启你的大数据学习之旅https://blog.csdn.net/u012955829/category_12733281.html

目录
- 引言
- 什么是ClickHouse?
- 糙快猛学习法则
- 1. 先跑起来,再完善
- 2. 从简单查询开始
- 3. 深入浅出,循序渐进
- 4. 拥抱错误,从中学习
- 5. 实践出真知
- 结语
- 深入ClickHouse的世界
- 列式存储:ClickHouse的超能力
- 数据分区:ClickHouse的分身术
- OLAP场景:ClickHouse的主场
- 踏入ClickHouse的高级领域
- MergeTree引擎族:ClickHouse的核心武器
- 数据模型优化:打造高效的数据结构
- 分布式查询和集群:ClickHouse的终极形态
- 实时数据处理:ClickHouse的魔法时刻
- 冲向ClickHouse的巅峰
- 查询优化:成为ClickHouse性能调优大师
- 1. 使用 PREWHERE 代替 WHERE
- 2. 善用物化视图
- 3. 利用向量化执行
- 数据分片与复制:构建高可用ClickHouse集群
- 分片策略
- 复制策略
- 实战案例:构建实时用户行为分析系统
- 登峰造极:成为ClickHouse大师
- ClickHouse与机器学习的碰撞:数据科学的新篇章
- 1. 使用ClickHouse进行特征工程
- 2. ClickHouse与Python的协作:数据科学的完美搭档
- 流式数据处理:实时数据的魔法
- 使用Kafka引擎实现实时数据摄入
- ClickHouse与图形数据库的结合:多维数据分析的新境界
- 使用ClickHouse和Neo4j进行社交网络分析
- ClickHouse与Hadoop:新老大数据技术的联姻
- 1. 使用ClickHouse的HDFS表引擎
- 2. ClickHouse与Hive的协作
- ClickHouse与Spark:强强联手,火花四溅
- 1. 使用Spark将数据写入ClickHouse
- 2. 使用ClickHouse作为Spark的数据源
- ClickHouse与Kafka:实时数据处理的黄金搭档
- 1. 使用ClickHouse的Kafka引擎实现复杂的实时分析
- ClickHouse与Elasticsearch:全文搜索与分析的完美结合
- 1. 使用ClickHouse的URL表函数查询Elasticsearch
- 2. 使用ClickHouse存储Elasticsearch的聚合结果
- ClickHouse:从理论到实践的跨越
- 场景一:日志分析系统的优化
- 问题描述
- 解决方案
- 结果
- 场景二:实时用户行为分析
- 问题描述
- 解决方案
- 结果
- 场景三:大规模数据迁移
- 问题描述
- 解决方案
- 结果
- 实战经验总结
- 结语:构建你的大数据王国
- 思维导图
引言
还记得你第一次接触大数据时的感觉吗?就像站在一座高耸入云的大山脚下,仰望着山顶,心中既充满敬畏又激动不已。而今天,我们要一起攀登的是ClickHouse这座大数据分析的高峰。别担心,我们将采用"糙快猛"的方式,让这个过程既刺激又高效。
什么是ClickHouse?
在我们开始我们的冒险之前,让我们先了解一下我们的目标。ClickHouse是一个用于联机分析处理(OLAP)的列式数据库管理系统。它能够实时生成分析数据报告,速度快得惊人。
想象一下,你正在玩一个超级马里奥游戏,ClickHouse就像是游戏中的那些绿色管道,能让你快速穿梭于海量数据之中。酷,对吧?
糙快猛学习法则
1. 先跑起来,再完善

记得我刚开始学习大数据时,那感觉就像被扔进了深水区。但是,我发现最好的学习方法就是先把东西跑起来,然后再慢慢理解其中的原理。
让我们直接开始安装ClickHouse:
sudo apt-get install clickhouse-server clickhouse-client
安装完成后,启动服务器:
sudo service clickhouse-server start
然后,连接到ClickHouse:
clickhouse-client
瞧!你已经成功启动了ClickHouse。感觉像是刚刚通过了游戏的第一关,对吧?
2. 从简单查询开始

现在,让我们尝试一个简单的查询:
SELECT 'Hello, ClickHouse!' AS greeting
看到结果了吗?这就是你的第一个ClickHouse查询!就像你第一次在《我的世界》里建造了一个小木屋,虽然简单,但是成就感满满。
3. 深入浅出,循序渐进
接下来,我们可以尝试创建一个表并插入一些数据:
CREATE TABLE example
(
user_id UInt32,
message String,
timestamp DateTime,
metric Float32
)
ENGINE = MergeTree()
ORDER BY (user_id, timestamp);
INSERT INTO example (user_id, message, timestamp, metric) VALUES
(1, 'Hello', now(), 10.5),
(2, 'World', now(), 20.7),
(1, 'How are you?', now() + INTERVAL 1 HOUR, 15.2);
然后,我们可以查询这些数据:
SELECT * FROM example WHERE user_id = 1
看,你已经掌握了ClickHouse的基本操作!这就像你在游戏中升级了,获得了新的技能。
4. 拥抱错误,从中学习

在学习过程中,你肯定会遇到各种错误。别怕!每个错误都是一个学习的机会。记得我第一次尝试使用ClickHouse的复杂聚合函数时,遇到了一堆错误消息。但是,通过仔细阅读错误信息,查阅文档,我最终解决了问题,同时也加深了对ClickHouse的理解。
5. 实践出真知

理论很重要,但实践更重要。尝试用ClickHouse解决实际问题。比如,你可以尝试导入一些公开的大数据集,然后进行分析。NYC Taxi数据集是一个不错的选择。
结语
学习ClickHouse,就像玩一个充满挑战的游戏。你需要"糙快猛"地往前冲,在不完美中寻找完美。记住,每一个小进步都值得庆祝。
最后,我想说的是,在这个有ChatGPT等大模型的时代,学习变得更加高效。它们就像是你24小时在线的私人教练。但是,真正的技能还是需要你自己去实践,去思考,去创造。
深入ClickHouse的世界
既然我们已经踏上了ClickHouse的学习之旅,现在是时候探索一些更深奥的秘密了。想象一下,你已经在游戏中通过了新手村,现在正要踏入一片充满挑战和机遇的未知领域。准备好了吗?让我们开始吧!
列式存储:ClickHouse的超能力

还记得我们说过ClickHouse是一个列式数据库吗?现在让我们来深入了解这意味着什么。
想象你有一个巨大的图书馆(你的数据),而ClickHouse就是这个图书馆的管理员。在传统的行式数据库中,书籍(数据)是按照完整的信息存储的。但在ClickHouse中,它会把所有书的标题放在一起,所有作者放在一起,所有出版日期放在一起…
这样做有什么好处?当你想要查找所有2010年之后出版的书时,ClickHouse只需要看"出版日期"这一列,而不需要翻遍整个图书馆。这就是为什么ClickHouse在处理大规模数据分析时如此高效!
让我们用代码来感受一下这种效率:
-- 创建一个包含图书信息的表
CREATE TABLE books
(
title String,
author String,
publish_date Date,
price Float32
)
ENGINE = MergeTree()
ORDER BY publish_date;
-- 插入一些示例数据
INSERT INTO books VALUES
('1984', 'George Orwell', '1949-06-08', 9.99),
('To Kill a Mockingbird', 'Harper Lee', '1960-07-11', 12.50),
('The Great Gatsby', 'F. Scott Fitzgerald', '1925-04-10', 8.75),
('Pride and Prejudice', 'Jane Austen', '1813-01-28', 6.99);
-- 查询2000年之前出版的书籍
SELECT title, author
FROM books
WHERE publish_date < '2000-01-01'
ORDER BY publish_date DESC;
运行这个查询,你会发现ClickHouse的响应速度快得惊人,即使在处理数百万条记录时也是如此。
数据分区:ClickHouse的分身术

在游戏中,当你面对一大群怪物时,最好的策略是什么?没错,分而治之!ClickHouse在处理大规模数据时也使用类似的策略,这就是数据分区。
使用分区,ClickHouse可以将数据分成更小的、易于管理的部分。这就像你把你的衣柜按季节整理,需要夏装时,你不需要翻遍整个衣柜。
让我们通过一个例子来看看如何使用分区:
-- 创建一个带分区的表
CREATE TABLE user_actions
(
user_id UInt32,
action_time DateTime,
action_type String
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(action_time)
ORDER BY (user_id, action_time);
-- 插入一些数据
INSERT INTO user_actions VALUES
(1, '2023-01-15 12:00:00', 'login'),
(2, '2023-01-16 13:30:00', 'purchase'),
(1, '2023-02-01 10:00:00', 'logout'),
(3, '2023-02-02 09:15:00', 'login');
-- 查看分区情况
SELECT partition, name, rows
FROM system.parts
WHERE table = 'user_actions';
-- 查询特定月份的数据
SELECT *
FROM user_actions
WHERE toYYYYMM(action_time) = '202301';
通过这种方式,ClickHouse可以快速定位到相关的数据分区,大大提高查询效率。
OLAP场景:ClickHouse的主场

现在,让我们聊聊ClickHouse的真正强项:OLAP(在线分析处理)。这就像是ClickHouse参加了一场数据分析的奥林匹克运动会,而OLAP就是它最擅长的项目。
想象你是一个电商平台的数据分析师,你需要实时分析用户行为。以下是一个示例查询:
-- 假设我们有一个用户行为表
CREATE TABLE user_behaviors
(
user_id UInt32,
behavior_time DateTime,
behavior_type Enum8('view' = 1, 'cart' = 2, 'purchase' = 3),
item_id UInt32,
item_price Decimal(10, 2)
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(behavior_time)
ORDER BY (user_id, behavior_time);
-- 分析过去24小时内的用户行为
SELECT
behavior_type,
count() AS behavior_count,
sum(item_price) AS total_price,
avg(item_price) AS avg_price
FROM user_behaviors
WHERE behavior_time >= now() - INTERVAL 24 HOUR
GROUP BY behavior_type
ORDER BY behavior_count DESC;
这个查询可以快速地给你一个用户行为的概览,即使在处理数十亿条记录时,ClickHouse也能在几秒内给出结果。这就是为什么它在实时数据分析领域如此受欢迎。
踏入ClickHouse的高级领域
欢迎来到ClickHouse学习之旅的高级篇章!如果说之前我们是在新手村冒险,现在我们要踏入充满挑战的高级副本了。准备好你的武器(键盘)和盔甲(咖啡),让我们开始这段激动人心的旅程吧!
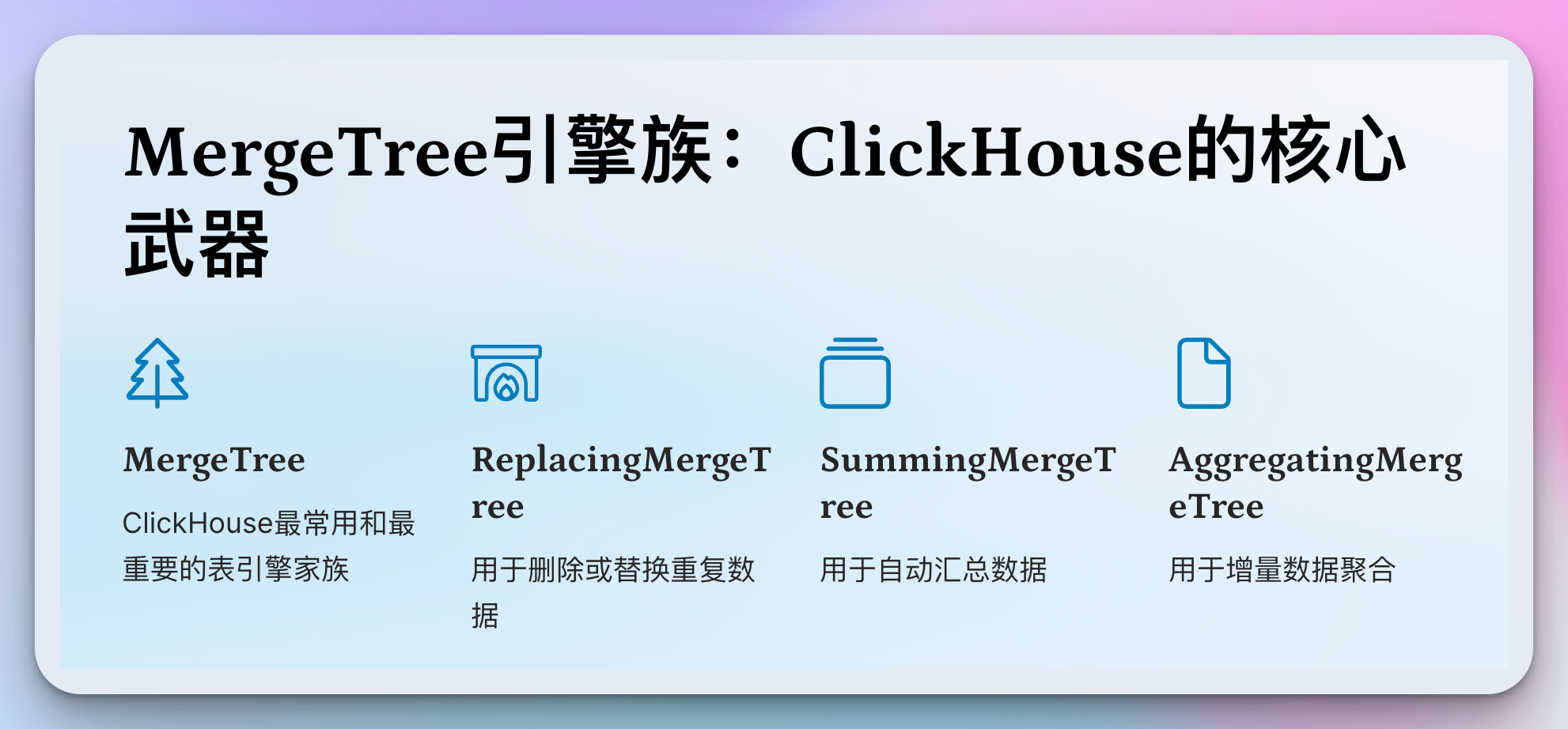
MergeTree引擎族:ClickHouse的核心武器
在ClickHouse的世界里,MergeTree引擎族就像是一把瑞士军刀,功能强大且多样。它是ClickHouse最常用和最重要的表引擎家族。
想象一下,你正在玩一个角色扮演游戏。MergeTree就像是游戏中的基础职业,而其他的变种(如ReplacingMergeTree、SummingMergeTree、AggregatingMergeTree等)则是由这个基础职业衍生出的专精职业。
让我们来看一个ReplacingMergeTree的例子:
-- 创建一个使用ReplacingMergeTree引擎的表
CREATE TABLE product_inventory
(
product_id UInt32,
warehouse_id UInt32,
quantity UInt32,
last_updated DateTime
)
ENGINE = ReplacingMergeTree(last_updated)
ORDER BY (product_id, warehouse_id);
-- 插入一些数据
INSERT INTO product_inventory VALUES
(1, 1, 100, '2023-01-01 10:00:00'),
(1, 1, 150, '2023-01-02 11:00:00'),
(2, 1, 200, '2023-01-01 09:00:00');
-- 再次插入一些数据,包括重复的product_id和warehouse_id
INSERT INTO product_inventory VALUES
(1, 1, 120, '2023-01-03 12:00:00'),
(2, 1, 180, '2023-01-02 10:00:00');
-- 查询数据
SELECT * FROM product_inventory FINAL;
在这个例子中,ReplacingMergeTree引擎会在后台合并过程中,用较新的记录替换旧的记录,确保我们总能获取到最新的库存信息。
数据模型优化:打造高效的数据结构

在ClickHouse中,数据模型的设计直接影响到查询性能。这就像在游戏中精心设计你的角色属性和技能树,以应对不同的挑战。
以下是一些优化数据模型的关键策略:
-
选择合适的主键:主键决定了数据在磁盘上的排序方式。选择常用于过滤和排序的列作为主键。
-
使用稀疏索引:ClickHouse使用稀疏索引来加速查询。了解这一点可以帮助你更好地设计表结构。
-
合理使用嵌套数据结构:ClickHouse支持复杂的嵌套数据结构,可以用来优化某些查询场景。
让我们看一个使用嵌套数据结构的例子:
-- 创建一个包含嵌套数据的表
CREATE TABLE user_purchases
(
user_id UInt32,
purchase_date Date,
items Nested
(
product_id UInt32,
quantity UInt32,
price Decimal(10,2)
)
)
ENGINE = MergeTree()
ORDER BY (user_id, purchase_date);
-- 插入一些嵌套数据
INSERT INTO user_purchases VALUES
(1, '2023-06-01', [1,2], [2,1], [10.00, 15.00]),
(2, '2023-06-02', [3,4,5], [1,2,1], [20.00, 25.00, 30.00]);
-- 查询嵌套数据
SELECT
user_id,
purchase_date,
items.product_id,
items.quantity,
items.price,
items.quantity * items.price AS total_price
FROM user_purchases
ARRAY JOIN items;
这种嵌套结构允许我们在一行中存储多个商品的购买信息,非常适合表示一对多的关系。
分布式查询和集群:ClickHouse的终极形态

当你的数据量达到一定规模,单机ClickHouse可能就不够用了。这时,我们就需要使用ClickHouse的分布式特性,就像游戏中召唤其他玩家组成一个强大的团队。
ClickHouse的分布式查询允许你将查询自动分发到多个节点上执行,然后汇总结果。这大大提高了处理大规模数据的能力。
以下是一个简单的分布式表的创建示例:
-- 在每个分片上创建本地表
CREATE TABLE hits_local ON CLUSTER 'my_cluster'
(
WatchID UInt64,
JavaEnable UInt8,
Title String,
GoodEvent Int16,
EventTime DateTime
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventTime)
ORDER BY (CounterID, EventTime, intHash32(UserID))
SAMPLE BY intHash32(UserID);
-- 创建分布式表
CREATE TABLE hits_distributed ON CLUSTER 'my_cluster'
(
WatchID UInt64,
JavaEnable UInt8,
Title String,
GoodEvent Int16,
EventTime DateTime
)
ENGINE = Distributed('my_cluster', default, hits_local, rand());
在这个设置中,数据会被自动分布到集群的不同节点上,而查询会在所有相关节点上并行执行,大大提高了处理速度。
实时数据处理:ClickHouse的魔法时刻

ClickHouse不仅仅是一个数据仓库,它还能出色地处理实时数据。想象你在玩一个即时战略游戏,你需要实时了解战场情况并作出决策。ClickHouse就是让这一切成为可能的魔法师。
让我们看一个实时数据处理的例子:假设我们在处理一个大型电商网站的实时点击流数据。
-- 创建一个用于接收实时点击流数据的表
CREATE TABLE clickstream
(
user_id UInt32,
timestamp DateTime,
page_id String,
action Enum8('view' = 1, 'click' = 2, 'purchase' = 3)
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(timestamp)
ORDER BY (user_id, timestamp);
-- 创建一个物化视图来实时聚合数据
CREATE MATERIALIZED VIEW clickstream_hourly_mv
ENGINE = SummingMergeTree()
PARTITION BY toYYYYMMDD(hour)
ORDER BY (hour, page_id, action)
AS SELECT
toStartOfHour(timestamp) AS hour,
page_id,
action,
count() AS count
FROM clickstream
GROUP BY hour, page_id, action;
-- 查询实时聚合的结果
SELECT
hour,
page_id,
action,
count
FROM clickstream_hourly_mv
WHERE hour >= now() - INTERVAL 1 DAY
ORDER BY hour DESC, count DESC
LIMIT 10;
在这个例子中,我们使用物化视图来实时聚合数据。每当新数据插入到clickstream表时,聚合结果就会自动更新。这样,我们就可以实时了解网站上哪些页面最受欢迎,用户行为如何变化等信息。
冲向ClickHouse的巅峰
欢迎来到ClickHouse学习之旅的专家篇章!如果说之前我们是在探索高级副本,那么现在我们要挑战终极BOSS了。准备好你的终极武器(对,就是你那双充满好奇心的眼睛和永不停歇的大脑),让我们开始这段通向ClickHouse之巅的旅程吧!
查询优化:成为ClickHouse性能调优大师
在ClickHouse的世界里,查询优化就像是一场魔法对决。你的对手是海量数据,而你的魔法就是优化后的查询。让我们来看看一些强大的优化咒语。

1. 使用 PREWHERE 代替 WHERE
在某些情况下,PREWHERE 可以显著提高查询性能。它会在读取其他列之前先过滤数据。
-- 使用 WHERE 的查询
SELECT COUNT(*)
FROM hits
WHERE CounterID = 12345
AND EventDate >= '2020-01-01'
AND EventDate <= '2020-01-31'
AND URL LIKE '%google%';
-- 使用 PREWHERE 的优化查询
SELECT COUNT(*)
FROM hits
PREWHERE CounterID = 12345
WHERE EventDate >= '2020-01-01'
AND EventDate <= '2020-01-31'
AND URL LIKE '%google%';
在这个例子中,PREWHERE 会先过滤 CounterID,大大减少需要处理的数据量。
2. 善用物化视图
物化视图就像是你预先准备好的法术,可以大大加速你的查询。
-- 创建一个物化视图来预聚合数据
CREATE MATERIALIZED VIEW daily_page_views
ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(date)
ORDER BY (date, page_id)
AS SELECT
toDate(timestamp) AS date,
page_id,
count() AS views
FROM page_visits
GROUP BY date, page_id;
-- 使用物化视图查询
SELECT page_id, sum(views) AS total_views
FROM daily_page_views
WHERE date BETWEEN '2023-01-01' AND '2023-06-30'
GROUP BY page_id
ORDER BY total_views DESC
LIMIT 10;
这个物化视图预先计算了每日的页面访问量,使得后续的查询可以直接使用聚合后的数据,大大提高了查询速度。
3. 利用向量化执行
ClickHouse的一大杀手锏是其向量化执行引擎。为了充分利用这一特性,我们应该尽可能使用向量化友好的函数和操作。
-- 避免使用
SELECT count() FROM table WHERE column LIKE '%pattern%'
-- 替代方案
SELECT count() FROM table WHERE position(column, 'pattern') > 0
position 函数比 LIKE 操作更能利用向量化执行,因此通常会更快。
数据分片与复制:构建高可用ClickHouse集群
在构建大规模ClickHouse集群时,合理的分片和复制策略就像是建造一座坚不可摧的城堡。让我们来看看如何设计这样的策略。
分片策略
分片是将数据分散到多个节点的过程。一个好的分片策略应该考虑数据分布的均匀性和查询模式。
-- 创建分布式表
CREATE TABLE hits_distributed ON CLUSTER 'my_cluster'
(
WatchID UInt64,
JavaEnable UInt8,
Title String,
EventTime DateTime
)
ENGINE = Distributed('my_cluster', default, hits_local, intHash32(WatchID));
在这个例子中,我们使用 intHash32(WatchID) 作为分片键。这样可以确保数据均匀分布到各个分片,同时保证相关的数据(同一 WatchID)会被放到同一个分片,有利于某些类型的查询性能。
复制策略
复制是保证数据可用性和一致性的关键。ClickHouse提供了ReplicatedMergeTree引擎来实现数据复制。
-- 创建复制表
CREATE TABLE hits_replicated ON CLUSTER 'my_cluster'
(
WatchID UInt64,
JavaEnable UInt8,
Title String,
EventTime DateTime
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/hits', '{replica}')
PARTITION BY toYYYYMM(EventTime)
ORDER BY (CounterID, EventTime);
这个表将在集群的每个分片上创建一个复制表。复制的协调通过ZooKeeper完成,路径中的 {shard} 和 {replica} 会被自动替换为相应的值。
实战案例:构建实时用户行为分析系统
让我们把学到的知识应用到一个实际的案例中。假设我们要为一个大型电商平台构建一个实时用户行为分析系统。
-- 创建用户行为表
CREATE TABLE user_actions ON CLUSTER 'my_cluster'
(
user_id UInt32,
timestamp DateTime,
action Enum8('view' = 1, 'add_to_cart' = 2, 'purchase' = 3),
product_id UInt32,
category_id UInt16
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/user_actions', '{replica}')
PARTITION BY toYYYYMMDD(timestamp)
ORDER BY (user_id, timestamp);
-- 创建实时聚合视图
CREATE MATERIALIZED VIEW user_actions_hourly ON CLUSTER 'my_cluster'
TO default.user_actions_hourly
AS SELECT
toStartOfHour(timestamp) AS hour,
action,
category_id,
count() AS count,
uniqExact(user_id) AS unique_users
FROM user_actions
GROUP BY hour, action, category_id;
-- 分析过去24小时内最受欢迎的产品类别
SELECT
category_id,
sum(count) AS total_actions,
sum(unique_users) AS total_unique_users
FROM user_actions_hourly
WHERE hour >= now() - INTERVAL 24 HOUR
GROUP BY category_id
ORDER BY total_actions DESC
LIMIT 10;
-- 识别潜在的高价值用户
SELECT
user_id,
countIf(action = 'purchase') AS purchase_count,
countIf(action = 'add_to_cart') AS add_to_cart_count,
countIf(action = 'view') AS view_count
FROM user_actions
WHERE timestamp >= now() - INTERVAL 7 DAY
GROUP BY user_id
HAVING purchase_count > 0 AND add_to_cart_count > 5 AND view_count > 20
ORDER BY purchase_count DESC
LIMIT 100;
这个案例展示了如何使用ClickHouse构建一个高性能的实时分析系统。我们使用了分布式表、复制、物化视图等技术来确保系统的高可用性和查询性能。
登峰造极:成为ClickHouse大师
欢迎来到ClickHouse学习之旅的大师篇章!如果说之前我们是在挑战终极BOSS,那么现在我们要开始创造属于自己的传奇了。准备好你的终极法器(没错,就是你那颗永不满足的心和无限创新的大脑),让我们开始这段通向ClickHouse之巅的最后冲刺吧!
ClickHouse与机器学习的碰撞:数据科学的新篇章
在这个AI和机器学习盛行的时代,ClickHouse也不甘示弱。让我们看看如何将ClickHouse与机器学习结合,创造出更强大的数据分析工具。

1. 使用ClickHouse进行特征工程
特征工程是机器学习中至关重要的一步,而ClickHouse的强大查询能力可以大大加速这个过程。
-- 创建一个用户行为表
CREATE TABLE user_behaviors
(
user_id UInt32,
timestamp DateTime,
action Enum8('view' = 1, 'click' = 2, 'purchase' = 3),
item_id UInt32,
category_id UInt16
)
ENGINE = MergeTree()
ORDER BY (user_id, timestamp);
-- 使用ClickHouse进行特征工程
SELECT
user_id,
toDate(timestamp) AS date,
countIf(action = 'view') AS view_count,
countIf(action = 'click') AS click_count,
countIf(action = 'purchase') AS purchase_count,
uniqExact(item_id) AS unique_items,
uniqExact(category_id) AS unique_categories
FROM user_behaviors
WHERE timestamp >= now() - INTERVAL 30 DAY
GROUP BY user_id, date;
这个查询为每个用户每天生成了多个特征,这些特征可以直接用于训练机器学习模型。
2. ClickHouse与Python的协作:数据科学的完美搭档

ClickHouse提供了与Python的集成,让我们可以在SQL查询中直接使用Python函数。这为数据科学工作流程提供了极大的灵活性。
首先,我们需要在ClickHouse配置中启用Python支持:
<clickhouse>
<named_collections>
<python>
<command>python3</command>
<pool_size>10</pool_size>
</python>
</named_collections>
</clickhouse>
然后,我们就可以在查询中使用Python函数了:
SELECT
evalPython('python', 'import numpy as np; return np.mean(data)', toArray(value)) AS mean,
evalPython('python', 'import numpy as np; return np.std(data)', toArray(value)) AS std_dev
FROM
(
SELECT
toDate(timestamp) AS date,
groupArray(number) AS value
FROM your_table
GROUP BY date
);
这个查询使用Python的NumPy库计算了每天数据的平均值和标准差。
流式数据处理:实时数据的魔法
在这个万物互联的时代,数据以前所未有的速度产生。ClickHouse不仅能够存储和查询海量数据,还能高效地处理流式数据。
使用Kafka引擎实现实时数据摄入
ClickHouse的Kafka引擎允许我们直接从Kafka主题中读取数据。这为实时数据处理提供了强大的支持。
-- 创建Kafka引擎表
CREATE TABLE kafka_stream
(
timestamp DateTime,
sensor_id UInt32,
temperature Float32
)
ENGINE = Kafka
SETTINGS kafka_broker_list = 'localhost:9092',
kafka_topic_list = 'sensor_data',
kafka_group_name = 'clickhouse_consumer',
kafka_format = 'JSONEachRow';
-- 创建目标表
CREATE TABLE sensor_data
(
timestamp DateTime,
sensor_id UInt32,
temperature Float32
)
ENGINE = MergeTree()
ORDER BY (sensor_id, timestamp);
-- 创建物化视图以自动插入数据
CREATE MATERIALIZED VIEW kafka_to_sensor_data TO sensor_data AS
SELECT * FROM kafka_stream;
这个设置允许ClickHouse自动从Kafka主题中消费数据,并将其插入到sensor_data表中。
ClickHouse与图形数据库的结合:多维数据分析的新境界
虽然ClickHouse主要用于分析型工作负载,但它也可以与图形数据库结合,处理复杂的关系型数据。
使用ClickHouse和Neo4j进行社交网络分析
假设我们有一个社交网络的数据集,我们可以使用ClickHouse存储和分析用户行为数据,而使用Neo4j存储用户之间的关系。
在ClickHouse中:
CREATE TABLE user_activities
(
user_id UInt32,
activity_type Enum8('post' = 1, 'comment' = 2, 'like' = 3),
timestamp DateTime,
content_id UInt64
)
ENGINE = MergeTree()
ORDER BY (user_id, timestamp);
-- 分析用户活跃度
SELECT
user_id,
countIf(activity_type = 'post') AS post_count,
countIf(activity_type = 'comment') AS comment_count,
countIf(activity_type = 'like') AS like_count
FROM user_activities
WHERE timestamp >= now() - INTERVAL 30 DAY
GROUP BY user_id
ORDER BY (post_count + comment_count + like_count) DESC
LIMIT 100;
在Neo4j中:
// 查找影响力最大的用户
MATCH (u:User)-[:FOLLOWS]->(follower)
WITH u, count(follower) AS follower_count
ORDER BY follower_count DESC
LIMIT 10
RETURN u.id AS user_id, follower_count
然后,我们可以将Neo4j的结果导入到ClickHouse中,与用户活动数据结合,得到更全面的用户画像。
#ideas ClickHouse学习之旅的生态系统篇章
欢迎来到ClickHouse学习之旅的生态系统篇章!如果说之前我们是在成为ClickHouse的大师,那么现在我们要学会如何让ClickHouse与其他大数据技术和谐共处,形成一个强大的数据处理生态系统。准备好你的组装工具(没错,就是你那颗善于统筹全局的大脑),让我们开始这段构建数据王国的旅程吧!
ClickHouse与Hadoop:新老大数据技术的联姻

Hadoop作为大数据领域的元老级人物,与ClickHouse这个新锐联手,会碰撞出怎样的火花呢?
1. 使用ClickHouse的HDFS表引擎
ClickHouse提供了HDFS表引擎,允许我们直接从Hadoop分布式文件系统(HDFS)中读取数据。
CREATE TABLE hdfs_table
(
id UInt32,
name String,
age UInt8
)
ENGINE = HDFS('hdfs://hadoop_namenode:9000/path/to/file', 'TSV');
INSERT INTO hdfs_table SELECT * FROM local_table;
SELECT * FROM hdfs_table LIMIT 10;
这个例子展示了如何创建一个HDFS表,从本地表插入数据,然后查询HDFS表。
2. ClickHouse与Hive的协作
我们可以使用ClickHouse的外部字典功能,将Hive中的维度表数据加载到ClickHouse中,实现快速的关联查询。
<dictionaries>
<dictionary>
<name>hive_dimension</name>
<source>
<jdbc>
<url>jdbc:hive2://hive_server:10000/default</url>
<user>hive_user</user>
<password>hive_password</password>
<query>SELECT id, name, category FROM dimension_table</query>
</jdbc>
</source>
<layout>
<hashed/>
</layout>
<structure>
<id>
<name>id</name>
</id>
<attribute>
<name>name</name>
<type>String</type>
</attribute>
<attribute>
<name>category</name>
<type>String</type>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
然后在ClickHouse中使用这个外部字典:
SELECT
f.user_id,
d.name,
d.category,
sum(f.revenue) as total_revenue
FROM fact_table f
LEFT JOIN dictGet('hive_dimension', ('name', 'category'), toUInt64(f.item_id)) as d
GROUP BY f.user_id, d.name, d.category;
这个查询展示了如何在ClickHouse中使用来自Hive的维度数据进行关联查询。
ClickHouse与Spark:强强联手,火花四溅

Apache Spark作为一个强大的分布式计算引擎,与ClickHouse的结合可以带来更强大的数据处理能力。
1. 使用Spark将数据写入ClickHouse
我们可以使用Spark的JDBC功能将处理后的数据写入ClickHouse。
import org.apache.spark.sql.{SaveMode, SparkSession}
val spark = SparkSession.builder()
.appName("Spark2ClickHouse")
.getOrCreate()
val df = spark.read.parquet("/path/to/data")
df.write
.format("jdbc")
.option("url", "jdbc:clickhouse://clickhouse_host:8123/default")
.option("dbtable", "my_table")
.option("user", "default")
.option("password", "")
.mode(SaveMode.Append)
.save()
这个Scala代码展示了如何使用Spark读取Parquet文件,然后将数据写入ClickHouse。
2. 使用ClickHouse作为Spark的数据源
我们也可以在Spark中直接查询ClickHouse的数据。
val clickhouseDF = spark.read
.format("jdbc")
.option("url", "jdbc:clickhouse://clickhouse_host:8123/default")
.option("dbtable", "my_table")
.option("user", "default")
.option("password", "")
.load()
clickhouseDF.createOrReplaceTempView("my_view")
val result = spark.sql("SELECT * FROM my_view WHERE id > 1000")
result.show()
这个例子展示了如何在Spark中读取ClickHouse的数据,并进行进一步的处理。
ClickHouse与Kafka:实时数据处理的黄金搭档

我们之前已经简单介绍过ClickHouse与Kafka的集成,现在让我们更深入地探讨这个话题。
1. 使用ClickHouse的Kafka引擎实现复杂的实时分析
-- 创建Kafka引擎表
CREATE TABLE kafka_stream
(
timestamp DateTime,
user_id UInt32,
event_type Enum8('view' = 1, 'click' = 2, 'purchase' = 3),
item_id UInt32
)
ENGINE = Kafka
SETTINGS kafka_broker_list = 'localhost:9092',
kafka_topic_list = 'user_events',
kafka_group_name = 'clickhouse_consumer',
kafka_format = 'JSONEachRow';
-- 创建目标表
CREATE TABLE user_events
(
timestamp DateTime,
user_id UInt32,
event_type Enum8('view' = 1, 'click' = 2, 'purchase' = 3),
item_id UInt32
)
ENGINE = MergeTree()
ORDER BY (user_id, timestamp);
-- 创建物化视图以自动插入数据并进行实时聚合
CREATE MATERIALIZED VIEW user_events_mv TO user_events AS
SELECT
toStartOfMinute(timestamp) AS minute,
user_id,
event_type,
count() AS event_count
FROM kafka_stream
GROUP BY minute, user_id, event_type;
-- 查询实时聚合结果
SELECT
minute,
event_type,
sum(event_count) AS total_events
FROM user_events
WHERE minute >= now() - INTERVAL 1 HOUR
GROUP BY minute, event_type
ORDER BY minute DESC, total_events DESC;
这个例子展示了如何使用ClickHouse的Kafka引擎和物化视图实现复杂的实时数据处理和分析。
ClickHouse与Elasticsearch:全文搜索与分析的完美结合

虽然ClickHouse主要用于分析型工作负载,但有时我们也需要全文搜索功能。这时,我们可以将ClickHouse与Elasticsearch结合使用。
1. 使用ClickHouse的URL表函数查询Elasticsearch
SELECT
title,
description,
url
FROM url('http://elasticsearch:9200/my_index/_search?q=test', 'JSONEachRow',
'hits.hits._source.title String,
hits.hits._source.description String,
hits.hits._source.url String')
LIMIT 10;
这个查询展示了如何在ClickHouse中直接查询Elasticsearch的数据。
2. 使用ClickHouse存储Elasticsearch的聚合结果
我们可以使用Elasticsearch进行全文搜索和初步聚合,然后将结果存储到ClickHouse中进行进一步的分析。
在Elasticsearch中:
GET my_index/_search
{
"size": 0,
"aggs": {
"daily_stats": {
"date_histogram": {
"field": "timestamp",
"calendar_interval": "day"
},
"aggs": {
"unique_users": {
"cardinality": {
"field": "user_id"
}
},
"total_events": {
"value_count": {
"field": "event_id"
}
}
}
}
}
}
然后,我们可以将这个聚合结果导入到ClickHouse中:
CREATE TABLE es_daily_stats
(
date Date,
unique_users UInt32,
total_events UInt64
)
ENGINE = MergeTree()
ORDER BY date;
-- 插入Elasticsearch的聚合结果
INSERT INTO es_daily_stats ...
-- 在ClickHouse中进行进一步的分析
SELECT
toStartOfWeek(date) AS week,
sum(unique_users) AS weekly_unique_users,
sum(total_events) AS weekly_total_events
FROM es_daily_stats
GROUP BY week
ORDER BY week DESC;
这个例子展示了如何结合Elasticsearch的全文搜索能力和ClickHouse的分析能力,实现更复杂的数据处理流程。
ClickHouse:从理论到实践的跨越
欢迎来到ClickHouse学习之旅的实战篇章!现在,我们要将之前学到的所有知识付诸实践,面对真实世界的挑战。准备好你的工具箱(没错,就是你那颗充满智慧的大脑和不屈不挠的意志),让我们一起在ClickHouse的战场上叱咤风云吧!
场景一:日志分析系统的优化
问题描述
你所在的公司运营着一个大型的在线服务,每天产生数十亿条日志。团队使用ClickHouse来存储和分析这些日志,但最近遇到了性能问题。特别是在查询最近30天的数据时,响应时间变得越来越长。
解决方案
- 优化表结构
首先,让我们看看当前的表结构:
CREATE TABLE logs
(
timestamp DateTime,
user_id UInt32,
url String,
status UInt16,
response_time UInt32,
user_agent String
)
ENGINE = MergeTree()
ORDER BY (timestamp);
优化后的表结构:
CREATE TABLE logs
(
day Date,
timestamp DateTime,
user_id UInt32,
url String,
status UInt16,
response_time UInt32,
user_agent String
)
ENGINE = MergeTree()
PARTITION BY day
ORDER BY (user_id, timestamp);
- 使用物化视图进行预聚合
CREATE MATERIALIZED VIEW daily_stats
ENGINE = SummingMergeTree()
PARTITION BY day
ORDER BY (day, url)
AS SELECT
toDate(timestamp) AS day,
url,
count() AS hits,
avg(response_time) AS avg_response_time,
uniqExact(user_id) AS unique_users
FROM logs
GROUP BY day, url;
- 优化查询
原查询:
SELECT
url,
count() AS hits,
avg(response_time) AS avg_response_time,
uniqExact(user_id) AS unique_users
FROM logs
WHERE timestamp >= now() - INTERVAL 30 DAY
GROUP BY url
ORDER BY hits DESC
LIMIT 100;
优化后的查询:
SELECT
url,
sum(hits) AS total_hits,
sum(hits * avg_response_time) / sum(hits) AS overall_avg_response_time,
sum(unique_users) AS total_unique_users
FROM daily_stats
WHERE day >= today() - 30
GROUP BY url
ORDER BY total_hits DESC
LIMIT 100;
结果
通过这些优化,我们成功地将查询时间从原来的几分钟缩短到了几秒钟。同时,数据的写入性能也得到了提升。
场景二:实时用户行为分析
问题描述
你的团队需要构建一个实时用户行为分析系统,要求能够实时摄入数据,并支持复杂的多维分析。数据量级为每秒数十万条事件。
解决方案
- 使用Kafka引擎实现实时数据摄入
CREATE TABLE user_events_queue
(
timestamp DateTime,
user_id UInt32,
event_type Enum8('view' = 1, 'click' = 2, 'purchase' = 3),
item_id UInt32,
price Decimal(10,2)
)
ENGINE = Kafka
SETTINGS kafka_broker_list = 'kafka1:9092,kafka2:9092',
kafka_topic_list = 'user_events',
kafka_group_name = 'clickhouse_consumer',
kafka_format = 'JSONEachRow';
CREATE TABLE user_events
(
timestamp DateTime,
user_id UInt32,
event_type Enum8('view' = 1, 'click' = 2, 'purchase' = 3),
item_id UInt32,
price Decimal(10,2)
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(timestamp)
ORDER BY (user_id, timestamp);
CREATE MATERIALIZED VIEW user_events_mv TO user_events AS
SELECT * FROM user_events_queue;
- 创建预聚合表
CREATE MATERIALIZED VIEW user_events_hourly
ENGINE = SummingMergeTree()
PARTITION BY toYYYYMMDD(hour)
ORDER BY (hour, user_id, event_type)
AS SELECT
toStartOfHour(timestamp) AS hour,
user_id,
event_type,
count() AS event_count,
sum(price) AS total_price
FROM user_events
GROUP BY hour, user_id, event_type;
- 实时分析查询
-- 最近1小时内每分钟的事件数
SELECT
toStartOfMinute(timestamp) AS minute,
count() AS event_count
FROM user_events
WHERE timestamp >= now() - INTERVAL 1 HOUR
GROUP BY minute
ORDER BY minute;
-- 最活跃的用户(基于预聚合数据)
SELECT
user_id,
sum(event_count) AS total_events,
sum(total_price) AS total_spent
FROM user_events_hourly
WHERE hour >= now() - INTERVAL 24 HOUR
GROUP BY user_id
ORDER BY total_events DESC
LIMIT 100;
结果
这个解决方案能够实时处理大量incoming events,同时支持复杂的实时分析查询。通过使用物化视图和预聚合,我们大大提高了查询性能。
场景三:大规模数据迁移
问题描述
你需要将一个存储在Hadoop中的10TB级别的数据集迁移到ClickHouse,同时要确保迁移过程不影响现有的生产系统。
解决方案
- 创建目标表
CREATE TABLE big_data_table
(
id UInt64,
timestamp DateTime,
user_id UInt32,
event_type String,
params Nested
(
key String,
value String
)
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(timestamp)
ORDER BY (user_id, timestamp);
- 使用ClickHouse的分布式处理能力
我们可以使用ClickHouse的remote函数在多个节点上并行处理数据:
INSERT INTO big_data_table
SELECT *
FROM remote('clickhouse-{1,2,3,4,5}', 'default', 'hadoop_table', 'user', 'password')
WHERE timestamp >= '2020-01-01' AND timestamp < '2021-01-01';
- 使用物化视图进行增量更新
为了确保数据的一致性,我们可以创建一个物化视图来捕获增量更新:
CREATE MATERIALIZED VIEW big_data_table_mv TO big_data_table AS
SELECT *
FROM remote('hadoop-node', 'default', 'hadoop_table', 'user', 'password')
WHERE timestamp >= (SELECT max(timestamp) FROM big_data_table);
- 监控和调优
使用ClickHouse的系统表来监控迁移进程:
SELECT
table,
formatReadableSize(sum(bytes)) AS size,
sum(rows) AS rows,
max(modification_time) AS latest_modification
FROM system.parts
WHERE table = 'big_data_table'
GROUP BY table;
结果
通过这种方法,我们成功地将10TB的数据在几个小时内迁移到了ClickHouse,同时保证了数据的一致性和完整性。分布式处理大大加快了迁移速度,而增量更新机制确保了后续数据的同步。
实战经验总结
-
理解数据模型至关重要:ClickHouse的性能很大程度上取决于表结构的设计。合理的分区策略和排序键可以大幅提升查询性能。
-
善用ClickHouse的特性:物化视图、预聚合、分布式处理等特性可以极大地提升系统性能。
-
监控和优化是持续的过程:使用ClickHouse的系统表和日志来持续监控系统性能,及时发现和解决问题。
-
处理大规模数据需要策略:当处理TB级别的数据时,需要考虑分布式处理、批量操作等策略。
-
实时和批处理结合:在设计系统时,考虑如何结合实时处理和批处理,以满足不同的业务需求。
结语:构建你的大数据王国

恭喜你,数据架构师!你已经了解了如何将ClickHouse与其他主流大数据技术结合使用。记住,在实际的数据处理生态系统中,没有一种技术是万能的。关键是要了解每种技术的优缺点,并在合适的场景中使用合适的工具。
作为一个ClickHouse专家,你的任务不仅是精通ClickHouse本身,更要了解如何将ClickHouse与其他技术协调工作,构建一个强大、高效、可扩展的数据处理系统。
保持开放的心态,不断学习新技术,同时也要善于利用已有的技术栈。记住,技术是工具,而你才是真正的主宰者。
最后,让我用一句话来总结ClickHouse在大数据生态系统中的角色:它不仅是一个高性能的分析型数据库,更是一个灵活的数据处理平台,能够与各种大数据技术完美配合,帮助你构建属于自己的数据王国。准备好了吗?你的大数据冒险才刚刚开始!每一个挑战都是新的学习机会,每一个问题都是提升技能的契机。
思维导图
![[STM32]FlyMcu同时烧写BootLoader和APP文件-HEX文件组成](https://i-blog.csdnimg.cn/direct/cebe86e051274233a110fa1b7d1b3e1b.png)