Executor
Executor 接口定义了数据库操作的基本方法,其中 query*() 方法、update() 方法、flushStatement() 方法是执行 SQL 语句的基础方法,commit() 方法、rollback() 方法以及 getTransaction() 方法与事务的提交/回滚相关,clearLocalCache() 方法、createCacheKey() 方法与缓存有关。
MyBatis 中有多个 Executor 接口的实现类,如下图所示:
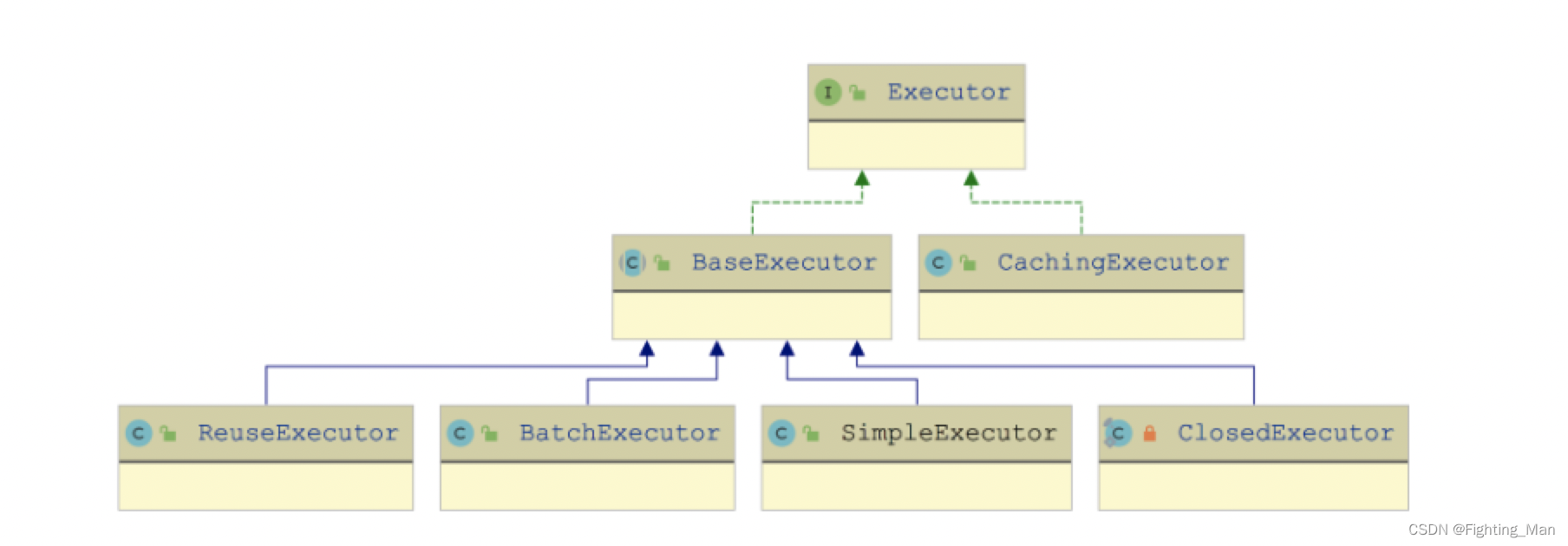
BaseExecutor
BaseExecutor 使用模板方法模式实现了 Executor 接口中的方法,其中,不变的部分是事务管理和缓存管理两部分的内容,由 BaseExecutor 实现;变化的部分则是具体的数据库操作,由 BaseExecutor 子类实现,涉及 doUpdate()、doQuery()、doQueryCursor() 和 doFlushStatement() 这四个方法。其中query方法的逻辑如下:
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 1. 获取 BoundSql 对象
BoundSql boundSql = ms.getBoundSql(parameter);
// 2. 创建查询语句对应的 CacheKey 对象
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// 3. 配置了flushCache=true,查询前清除一级缓存
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 4.从一级缓冲中获取数据
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 5. 缓冲中没查询到数据则从数据库中查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
// 7. MyBatis全局配置属性localCacheScope配置为Statement时,那么完成一次查询就会清除缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 使用配置的执行器查询逻辑
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
//6. 将数据库查出的数据放入到一级缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
SimpleExecutor
- doQuery
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 创建StatementHandler对象,实际返回的是RoutingStatementHandler对象
// 其中根据MappedStatement.statementType选择具体的StatementHandler实现
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 完成StatementHandler的创建和初始化,该方法会调用StatementHandler.prepare()方法创建
// Statement对象,然后调用StatementHandler.parameterize()方法处理占位符
stmt = prepareStatement(handler, ms.getStatementLog());
// 调用StatementHandler.query()方法,执行SQL语句,并通过ResultSetHandler完成结果集的映射
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
ReuseExecutor
ReuseExecutor 这个 BaseExecutor 实现就实现了重用 Statement 的优化,ReuseExecutor 维护了一个 statementMap 字段(HashMap<String, Statement>类型)来缓存已有的 Statement 对象,该缓存的 Key 是 SQL 模板,Value 是 SQL 模板对应的 Statement 对象。这样在执行相同 SQL 模板时,我们就可以复用 Statement 对象了。
ReuseExecutor 中的 do*() 方法实现与前面介绍的 SimpleExecutor 实现完全一样,两者唯一的区别在于其中依赖的 prepareStatement() 方法:SimpleExecutor 每次都会创建全新的 Statement 对象,ReuseExecutor 则是先尝试查询 statementMap 缓存,如果缓存命中,则会重用其中的 Statement 对象。
BatchExecutor
JDBC 在执行 SQL 语句时,会将 SQL 语句以及实参通过网络请求的方式发送到数据库,一次执行一条 SQL 语句,一方面会减小请求包的有效负载,另一个方面会增加耗费在网络通信上的时间。通过批处理的方式,我们就可以在 JDBC 客户端缓存多条 SQL 语句,然后在 flush 或缓存满的时候,将多条 SQL 语句打包发送到数据库执行,这样就可以有效地降低上述两方面的损耗,从而提高系统性能。
BatchExecutor 是用于实现批处理的 Executor 实现,其中维护了一个 List集合(statementList 字段)用来缓存一批 SQL,每个 Statement 可以写入多条 SQL。
JDBC 的批处理操作只支持 insert、update、delete 等修改操作,也就是说 BatchExecutor 对批处理的实现集中在 doUpdate() 方法中。在 doUpdate() 方法中追加一条待执行的 SQL 语句时,BatchExecutor 会先将该条 SQL 语句与最近一次追加的 SQL 语句进行比较,如果相同,则追加到最近一次使用的 Statement 对象中;如果不同,则追加到一个全新的 Statement 对象,同时会将新建的 Statement 对象放入 statementList 缓存中。
public int doUpdate(MappedStatement ms, Object parameterObject) throws SQLException {
final Configuration configuration = ms.getConfiguration();
// 创建StatementHandler对象
final StatementHandler handler = configuration.newStatementHandler(this, ms, parameterObject, RowBounds.DEFAULT, null, null);
final BoundSql boundSql = handler.getBoundSql();
// 获取此次追加的SQL模板
final String sql = boundSql.getSql();
final Statement stmt;
// 比较此次追加的SQL模板与最近一次追加的SQL模板,以及两个MappedStatement对象
if (sql.equals(currentSql) && ms.equals(currentStatement)) {
// 两者相同,则获取statementList集合中最后一个Statement对象
int last = statementList.size() - 1;
stmt = statementList.get(last);
applyTransactionTimeout(stmt);
handler.parameterize(stmt); // 设置实参
// 查找该Statement对象对应的BatchResult对象,并记录用户传入的实参
BatchResult batchResult = batchResultList.get(last);
batchResult.addParameterObject(parameterObject);
} else {
Connection connection = getConnection(ms.getStatementLog());
// 创建新的Statement对象
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);// 设置实参
// 更新currentSql和currentStatement
currentSql = sql;
currentStatement = ms;
// 将新创建的Statement对象添加到statementList集合中
statementList.add(stmt);
// 为新Statement对象添加新的BatchResult对象
batchResultList.add(new BatchResult(ms, sql, parameterObject));
}
handler.batch(stmt);
return BATCH_UPDATE_RETURN_VALUE;
}
/**这里使用到的 BatchResult 用于记录批处理的结果,一个 BatchResult 对象与一个 Statement 对象对应,BatchResult 中维护了一个 updateCounts 字段(int[] 数组类型)来记录关联 Statement 对象执行批处理的结果。
添加完待执行的 SQL 语句之后,我们再来看一下 doFlushStatements() 方法,其中会通过 Statement.executeBatch() 方法批量执行 SQL,然后 SQL 语句影响行数以及数据库生成的主键填充到相应的 BatchResult 对象中返回。下面是其核心实现:
*/
public List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException {
try {
// 用于储存批处理的结果
List<BatchResult> results = new ArrayList<>();
// 如果明确指定了要回滚事务,则直接返回空集合,忽略statementList集合中记录的SQL语句
if (isRollback) {
return Collections.emptyList();
}
for (int i = 0, n = statementList.size(); i < n; i++) { // 遍历statementList集合
Statement stmt = statementList.get(i);// 获取Statement对象
applyTransactionTimeout(stmt);
BatchResult batchResult = batchResultList.get(i); // 获取对应BatchResult对象
try {
// 调用Statement.executeBatch()方法批量执行其中记录的SQL语句,并使用返回的int数组
// 更新BatchResult.updateCounts字段,其中每一个元素都表示一条SQL语句影响的记录条数
batchResult.setUpdateCounts(stmt.executeBatch());
MappedStatement ms = batchResult.getMappedStatement();
List<Object> parameterObjects = batchResult.getParameterObjects();
// 获取配置的KeyGenerator对象
KeyGenerator keyGenerator = ms.getKeyGenerator();
if (Jdbc3KeyGenerator.class.equals(keyGenerator.getClass())) {
// 获取数据库生成的主键,并记录到实参中对应的字段
Jdbc3KeyGenerator jdbc3KeyGenerator = (Jdbc3KeyGenerator) keyGenerator;
jdbc3KeyGenerator.processBatch(ms, stmt, parameterObjects);
} else if (!NoKeyGenerator.class.equals(keyGenerator.getClass())) {
// 其他类型的KeyGenerator,会调用其processAfter()方法
for (Object parameter : parameterObjects) {
keyGenerator.processAfter(this, ms, stmt, parameter);
}
}
closeStatement(stmt);
} catch (BatchUpdateException e) {
// 异常处理逻辑
}
// 添加BatchResult到results集合
results.add(batchResult);
}
return results;
} finally {
// 释放资源
}
}
一级缓存
mybatis的以及缓存为sqlSession级别的缓存,默认开启的,不能关闭;在执行一个查询操作时,Mybatis会创建一个新的SqlSession对象,SqlSession在执行查询操作时会走BaseExecutor的执行逻辑,BaseExecutor持有一个PerpetualCache对象,如下:
this.localCache = new PerpetualCache("LocalCache");
BaseExecutor的query方法执行逻辑为(源码分析在上面):
- 获取 BoundSql 对象
- 根据BoundSql创建查询语句对应的 CacheKey 对象
- 如果配置了flushCache=true,会在查询前清除一级缓存
- 从一级缓冲中获取数据
- 如果以及缓存中有数据,则将命中的数据返回
- 如果缓冲中没有数据,则到数据库中查询数据
- 将查询的数据存入到一级缓存中
- MyBatis全局配置属性localCacheScope配置为Statement时,那么完成一次查询就会清除缓存
一级缓存的清除
- 就是获取缓存之前会先进行判断用户是否配置了flushCache=true属性,
如果配置了则会清除一级缓存。 - MyBatis全局配置属性localCacheScope配置为Statement时,那么完成一次查询就会清除缓存
- 在执行commit,rollback,update方法时会清空一级缓存
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 清除一级缓存
clearLocalCache();
return doUpdate(ms, parameter);
}
public void commit(boolean required) throws SQLException {
if (closed) {
throw new ExecutorException("Cannot commit, transaction is already closed");
}
// 清除一级缓存
clearLocalCache();
flushStatements();
if (required) {
transaction.commit();
}
}
public void rollback(boolean required) throws SQLException {
if (!closed) {
try {
// 清除一级缓存
clearLocalCache();
flushStatements(true);
} finally {
if (required) {
transaction.rollback();
}
}
}
}
一级缓存的失效
- sqlSession不同,缓存失效。
- sqlSession相同,查询条件不同,缓存失效,因为缓存中可能还没有相关数据。
- sqlSession相同,在两次查询期间,执行了增删改操作,缓存失效。
- sqlSession相同,但是手动清空了一级缓存,缓存失效
二级缓存
Mybatis默认对二级缓存是关闭的,一级缓存默认开启;如果需要开启二级缓存,需在mapper上加入配置。
<cache/>
或者
<cache-ref namespace="com.handerh.mapper.UserMapper"/>
Executor有两个实现类一个是BaseExecutor另外一个是CachingExecutor。CachingExecutor(二级缓存查询),一级缓存因为只能在同一个SqlSession中共享,所以会存在一个问题,在分布式或者多线程的环境下,不同会话之间对于相同的数据可能会产生不同的结果,因为跨会话修改了数据是不能互相感知的,所以就有可能存在脏数据的问题,正因为一级缓存存在这种不足,需要一种作用域更大的缓存,这就是二级缓存。
CachingExecutor的创建
CachingExecutor的创建是在获取SqlSession的时候,根据全局配置文件中<setting name="cacheEnabled" value="true"/>的二级缓存开关来控制的
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 创建一个Executor
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
// configuration.newExecutor(tx, execType)调用的是该方法
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
// 默认开启,使用装饰器模式创建一个CachingExecutor
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
// 插件的扩展 后面详细说明
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
CachingExecutor的执行逻辑
CachingExecutor 是一个 Executor 接口的装饰器,它为 Executor 对象增加了二级缓存的相关功能。
它封装了一个用于执行数据库操作的 Executor 对象,以及一个用于管理缓存的 TransactionalCacheManager 对象。
TransactionalCache 和 TransactionalCacheManager 是 CachingExecutor 依赖的两个组件。具体的执行逻辑如下:
- 获取BoundSql 对象并且根据BoundSql对象创建CacheKey
- 检测是否开启二级缓存,若没有开启,则通过Eexcutor执行器查询数据
- 开启了二级缓存,则判断对应sql节点是否开启了二级缓存的相关配置
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 1. 获取 BoundSql 对象
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 2. 根据BoundSql对象创建CacheKey对象
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 3. 检测是否开启了二级缓存
Cache cache = ms.getCache();
if (cache != null) {
// 4. 根据<select>节点的配置,决定是否需要清空二级缓存
flushCacheIfRequired(ms);
// 5. 检测该sql节点是否使用二级缓存
if (ms.isUseCache() && resultHandler == null) {
// 与存储过程有关 暂不清晰
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
// 6. 从二级缓存中查询数据
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 7. 如果二级缓存中没有数据,则通过Executor查询
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 8. 将查出的数据存入到二级缓存中
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
TransactionalCache
在CachingExecutor中有一个属性:
// 该对象用于管理 CachingExecutor 使用的二级缓存对象
TransactionalCacheManager tcm = new TransactionalCacheManager();
在TransactionalCacheManager中只定义了一个 transactionalCaches,它的 key 是对应的 CachingExecutor 使用的二级缓存对象,value 是相应的 TransactionalCache 对象,在该 TransactionalCache 中封装了对应的二级缓存对象。
public class TransactionalCache implements Cache {
private static final Log log = LogFactory.getLog(TransactionalCache.class);
// 底层封装的二级缓存所对应的 Cache 对象,以存储 namespace 为单位的 Cache 对象,默认为 PerpetualCache
private final Cache delegate;
// 当改字段为 true 时,则表示当前 TransactionalCache 不可查询,且提交事务时会将底层 Cache 清空
private boolean clearOnCommit;
// 暂时记录添加到 TransactionalCache 中的数据。在事务提交时,会将其中的数据添加到二级缓存中
private final Map<Object, Object> entriesToAddOnCommit;
// 记录缓存未命中的 CacheKey 对象
private final Set<Object> entriesMissedInCache;
public TransactionalCache(Cache delegate) {
this.delegate = delegate;
this.clearOnCommit = false;
this.entriesToAddOnCommit = new HashMap<>();
this.entriesMissedInCache = new HashSet<>();
}
/**
* 它首先会查询底层的二级缓存,并将为命中的 key 记录到 entriesMissedInCache,之后根据 clearOnCommit 字段的值决定具体的返回值
* @param key The key
* @return
*/
@Override
public Object getObject(Object key) {
// issue #116
// 查询底层的 Cache 是否包含了指定的 key
Object object = delegate.getObject(key);
// 如果底层缓存对象中不包含改缓存项,则将该 key 记录到 entriesMissedInCache 集合中
if (object == null) {
entriesMissedInCache.add(key);
}
// issue #146
if (clearOnCommit) {
return null;
} else {
// 返回层底层 Cache 中查询到的对象
return object;
}
}
/**
* 该方法并没有直接将结果对象记录到其封装的二级缓存中,而是暂时保存在 entriesToAddOnCommit 集合中,
* 在事务提交时才会将这些结果对象从 entriesToAddOnCommit 集合 添加到二级缓存中。
* @param key Can be any object but usually it is a {@link CacheKey}
* @param object
*/
@Override
public void putObject(Object key, Object object) {
entriesToAddOnCommit.put(key, object);
}
/**
* 会根据 clearOnCommit 字段的值决定是否清空二级缓存,然后调用 flushPendingEntries() 方法将 entriesToAddOnCommit 集合中记录的结果对象保存到二级缓存中
*/
public void commit() {
// 在事务提交前,清空二级缓存
if (clearOnCommit) {
delegate.clear();
}
// 将 entriesToAddOnCommit 集合中记录的结果对象保存到二级缓存中
flushPendingEntries();
// 重置 clearOnCommit 值,清空 entriesToAddOnCommit 和 entriesMissedInCache 集合
reset();
}
/**
* 将 entriesMissedInCache 集合中记录的缓存项从二级缓存中删除,并清空 entriesToAddOnCommit 和 entriesMissedInCache 集合
*/
public void rollback() {
// 将 entriesMissedInCache 集合中记录的缓存项从二级缓存中删除
unlockMissedEntries();
// 清空 entriesToAddOnCommit 和 entriesMissedInCache 集合
reset();
}
/**
* 重置 clearOnCommit 值,清空 entriesToAddOnCommit 和 entriesMissedInCache 集合
*/
private void reset() {
clearOnCommit = false;
entriesToAddOnCommit.clear();
entriesMissedInCache.clear();
}
/**
* 将 entriesToAddOnCommit 集合中记录的结果对象保存到二级缓存中
*/
private void flushPendingEntries() {
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
// 遍历 entriesMissedInCache 集合,缓存为命中的,且 entriesToAddOnCommit 集合中不包含的缓存项, 添加到二级缓冲中
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
/**
* 将 entriesMissedInCache 集合中记录的缓存项从二级缓存中删除
*/
private void unlockMissedEntries() {
for (Object entry : entriesMissedInCache) {
try {
delegate.removeObject(entry);
} catch (Exception e) {
log.warn("Unexpected exception while notifiying a rollback to the cache adapter."
+ "Consider upgrading your cache adapter to the latest version. Cause: " + e);
}
}
}
}
为什么事物提交的时候才将数据真正添加到二级缓冲
- 脏读的问题(假设当前数据库的隔离级别为不可重复读),假设先后开启两个事务T1,T2,T1在当前事务中更新了A数据,然后又查询了A数据,直接将A数据添加到了二级缓存中,这时T2查询A数据,这里就会有一个脏读的问题了,T1还未提交呢!!!所以二级缓存在事物真正提交的时候才将数据加入到二级缓存中;
- 不可重复读的问题,即便是在事务提交时将数据加入到二级缓存,也会存在不可重复读的问题;假设先后开启两个事务T1,T2,T1在当前事务中更新了A数据,然后又查询了A数据,这时T2查询A数据,查询到的是未更新前的,之后T1提交事务,将数据加入到二级缓存,T2再次查询,此时查到的数据就是更新后的数据了,也就是不可重复读的问题
二级缓存的清除
所有的update操作(insert,delete,uptede)都会触发缓存的刷新,从而导致二级缓存失效





![[Android开发基础3] Activity的生命周期、创建与配置](https://img-blog.csdnimg.cn/ed849be6fb564a2a9e8ddbb39200c8ca.png)