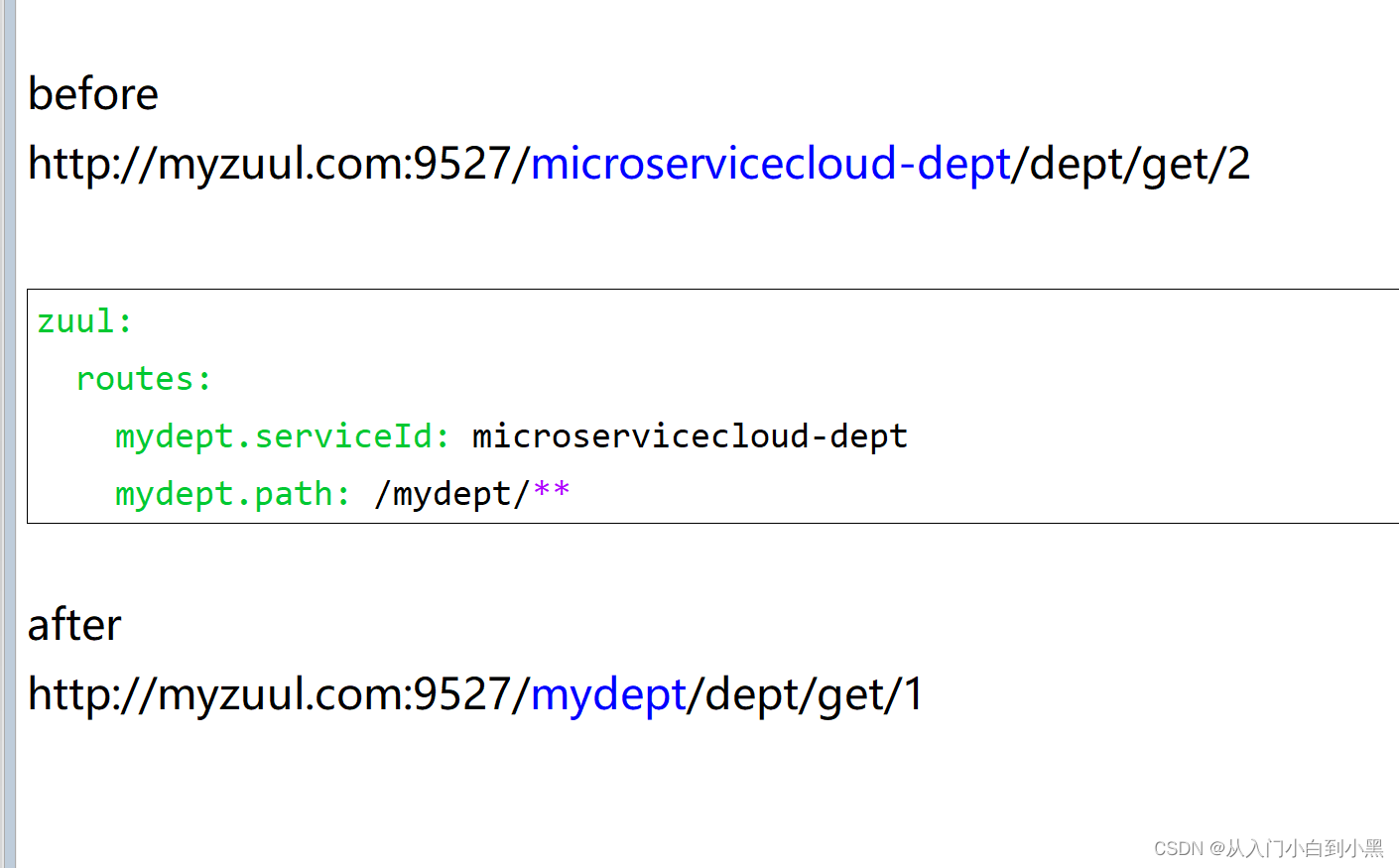
一、LongAdder简介
1.下图是JDK-API文档的的截图信息
我们可以得知这两个类都是1.8开始提供的,并且都具有顶级的并发性。这两类的区别点主要在于LongAdder初始值为0,只能做累加操作,而LongAccumulator可以完成一些复杂的计算,本文主要以LongAdder作为核心来讲解。


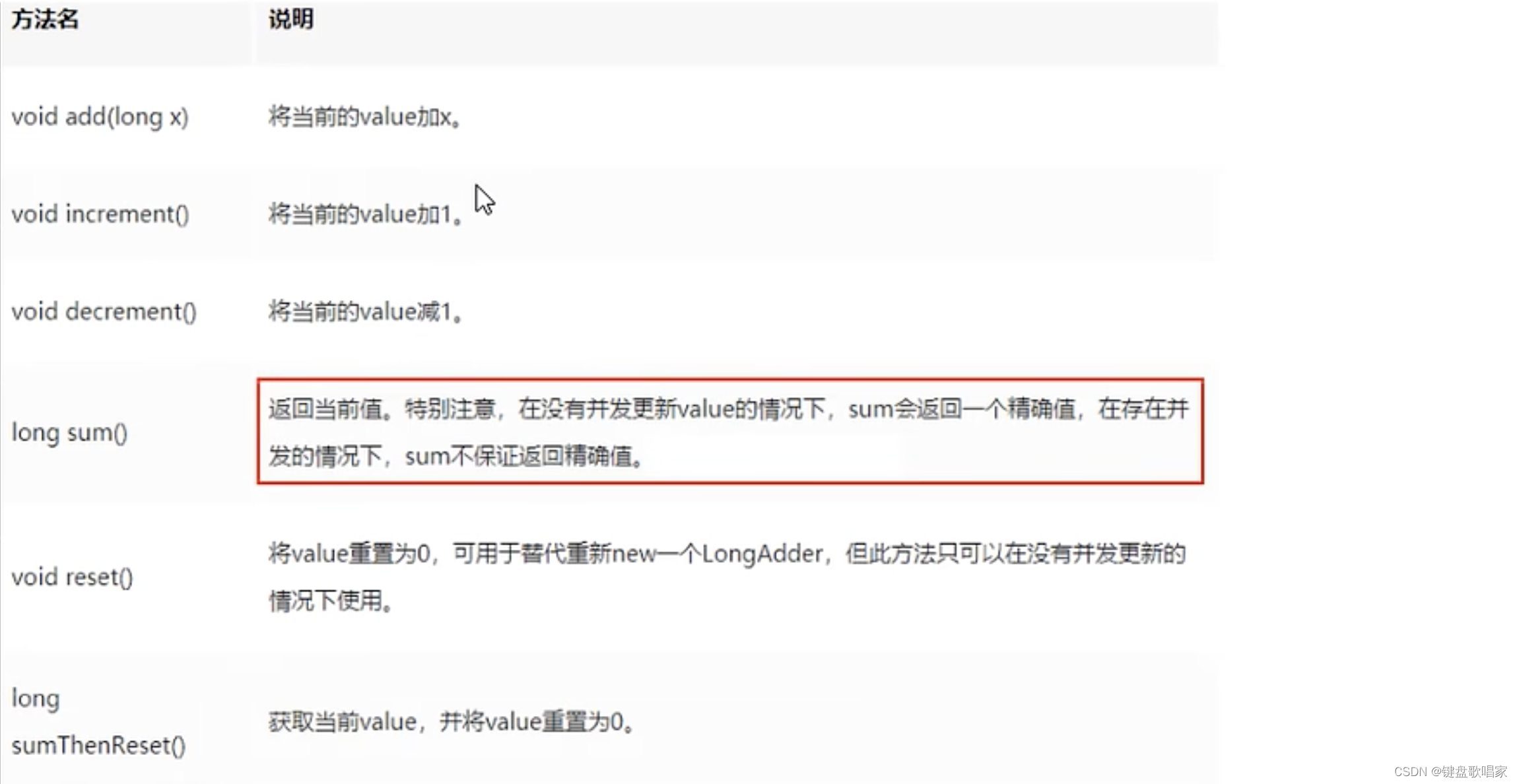
2.LongAdder常用的api如下:
3.性能优势demo
class ClickNumber{
int number = 0;
public synchronized void clickBySynchronized(){
number++;
}
AtomicLong atomicLong = new AtomicLong(0);
public void clickByAtomicLong(){
atomicLong.getAndIncrement();
}
LongAdder longAdder = new LongAdder();
public void clickByLongAdder(){
longAdder.increment();
}
LongAccumulator longAccumulator = new LongAccumulator((x,y)->x+y,0);
public void clickByLongAccumulator(){
longAccumulator.accumulate(1);
}
}
public class Test {
public static final int _1W = 10000;
public static final int threadNumber = 50;
public static void main(String[] args) throws InterruptedException {
ClickNumber clickNumber = new ClickNumber();
long startTime;
long endTime;
CountDownLatch countDownLatch1 = new CountDownLatch(threadNumber);
startTime = System.currentTimeMillis();
for (int i = 0; i < threadNumber; i++) {
new Thread(() ->{
try{
for (int i1 = 0; i1 < 100 * _1W; i1++) {
clickNumber.clickBySynchronized();
}
}finally {
countDownLatch1.countDown();
}
}).start();
}
countDownLatch1.await();
endTime = System.currentTimeMillis();
System.out.println("synchronize花费:"+(endTime - startTime) + "毫秒");
}
}
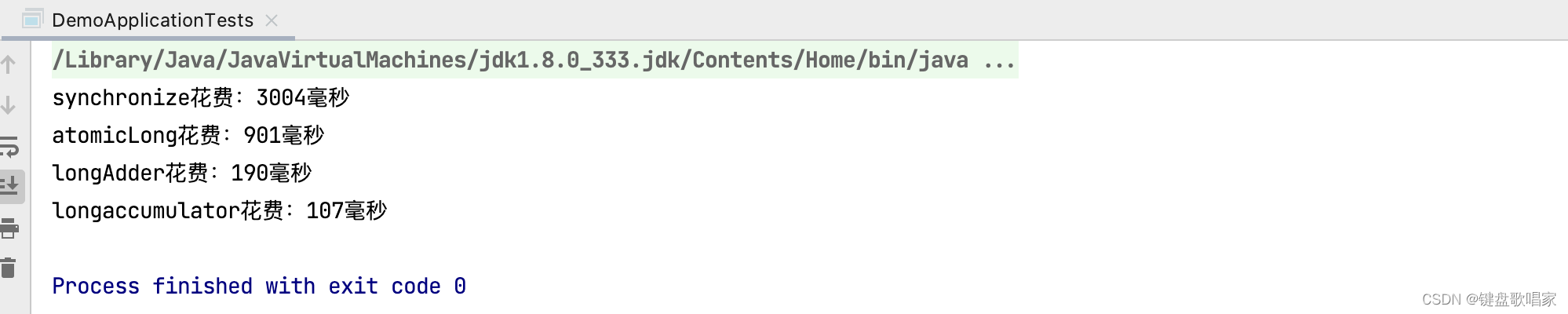
其结果展示了在高并发的状态下,LongAdder和LongAccumulator完爆上面两种高并发累加,AutomicLong性能与之差了9-10倍。(因为其底层减少了乐观锁的重试次数)
二、原因分析
1.类继承分析
LongAdder是striped64的子类,该64类是性能暴虐其他原子类的灵魂
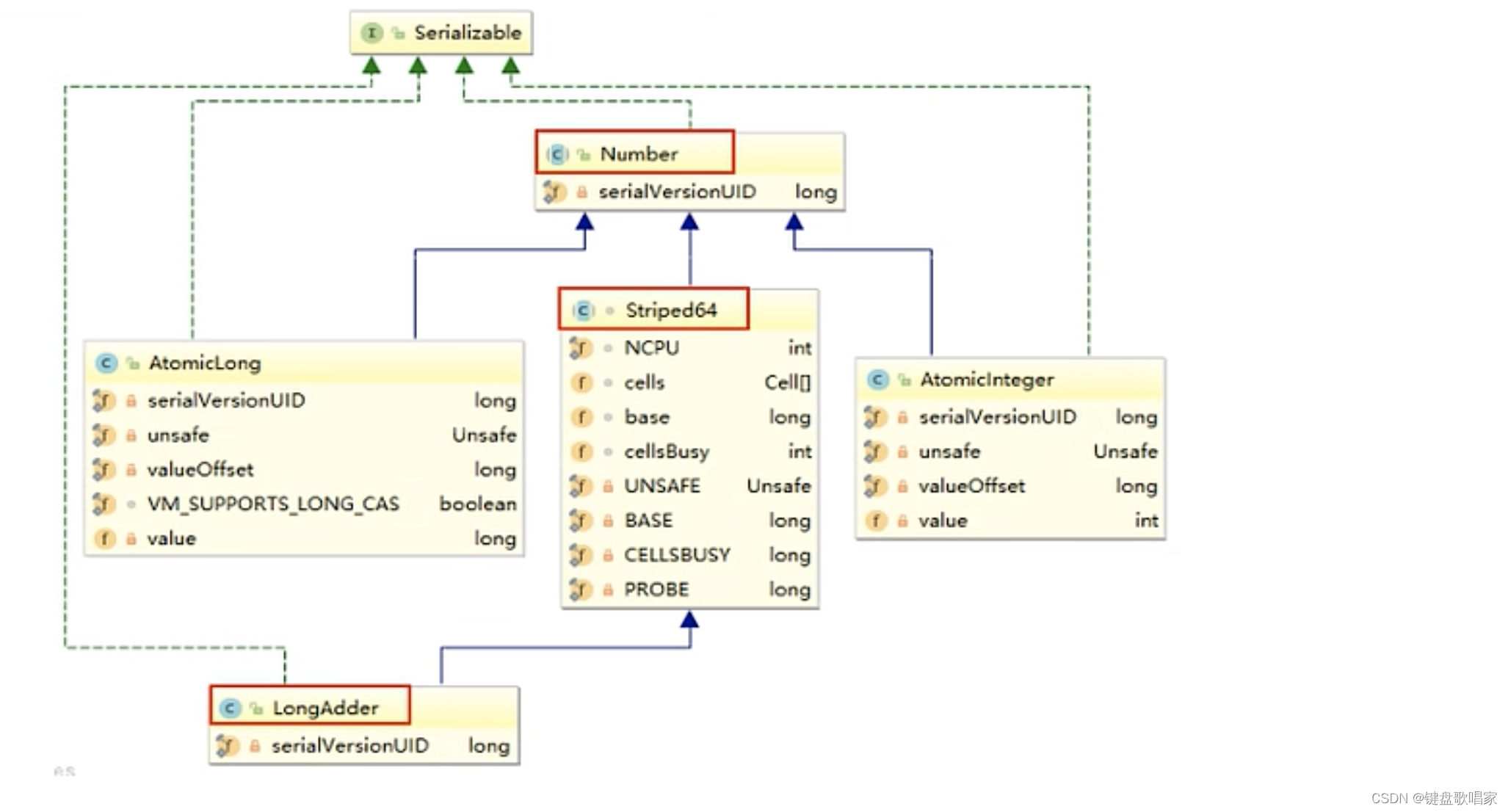
1.下图是Striped64的重要成员变量和方法解析


3.先说结论:

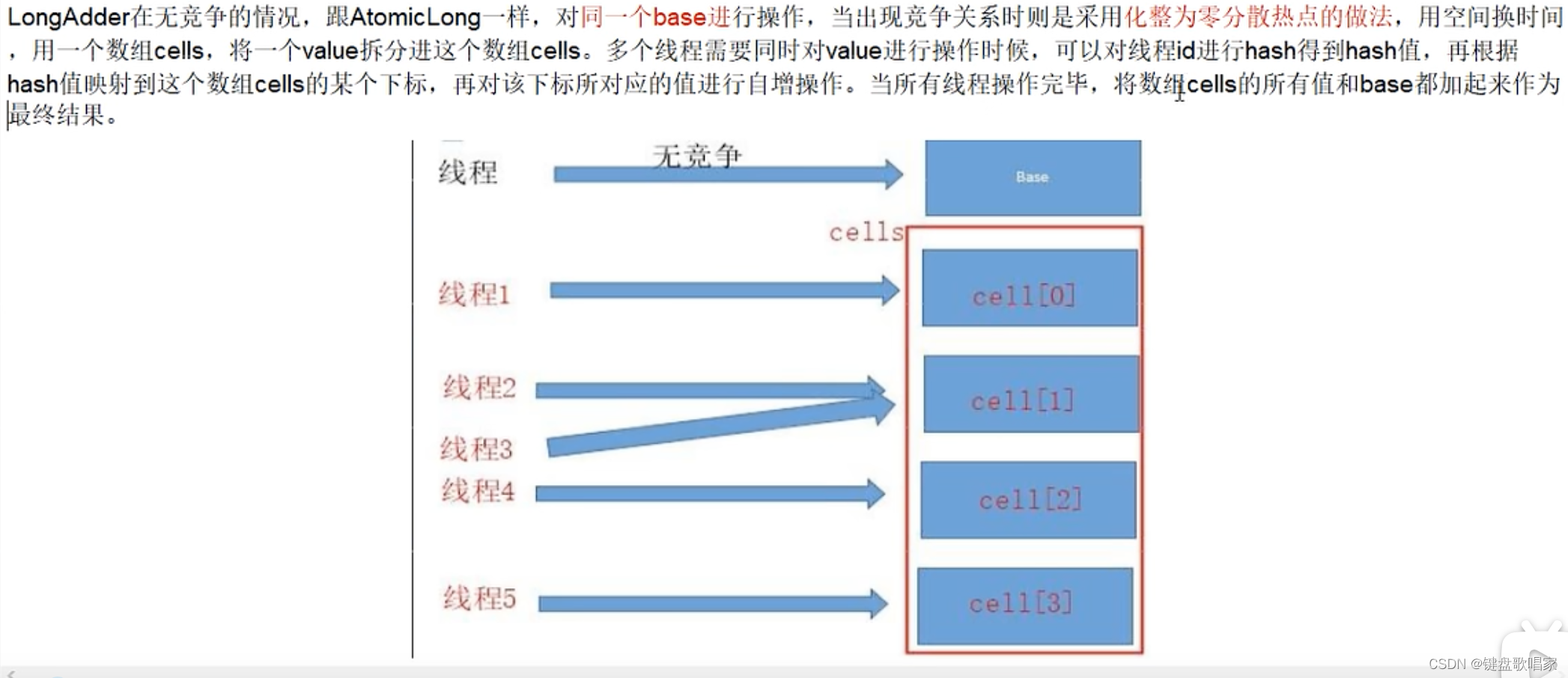
2.LongAdder类源码分析
1.分析add方法

public void add(long x) {
//as是striped64中cells数组属性
//b是striped64中的base属性
//v是当前线程hash到的cell中存储的值
//m是cells的长度减1
//a是当前线程hash命中的cells单元格
Cell[] as; long b, v; int m; Cell a;
//首次首线程((as == cells) != null)一定是false,此时走casBase方法,以CAS的方式更新base值,且只有当cas失败时,才会走到if中
//条件1: cells不为空
//条件2: cas操作base失败,说明其他线程先一步修改了base,正在出现竞争
if ((as = cells) != null || !casBase(b = base, b + x)) {
// true无竞争 false表示竞争激烈,多个线程hash到同一个cell,可能要扩容
boolean uncontended = true;
//条件1:cells为空(第一次进来肯定符合条件,于是进行longAccumulate中创建cells[])
//条件2:应该不会出现
//条件3:当前线程所在的cell为空,说明当前线程还没有更新过cell,应该初始化一个cell
//条件4:更新当前线程所在的cell失败,说明现在竞争很激烈,多个线程hash到了同一个cell,应扩容
if (as == null || (m = as.length - 1) < 0 ||
//getProbe()方法返回的是线程中threadLocalRandomProbe字段
//它是通过随机数生成的一个值,对于一个确定的线程这个值是固定的(除非刻意修改它)
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);//调用striped64中的方法处理
}
}
总结:
1.如果cells表为空,尝试用CAS更新base字段,成功则退出
2.如果cells表为空,CAS更新base字段失败,出现竞争,uncontended为true,调用longAccumulate(初始化大小为2的cells数组,并把当前线程hash命中的槽位初始化)
3.如果cells表非空,但当前线程映射的槽为空,uncontended为true,调用longAccumulate(初始化该槽位的cell)
4.如果cells表非空,且当前线程映射的槽非空,CAS更新cell的值,成功则返回,否则,uncontended设为false,调用longAccumulate(先尝试让当前线程换个槽再来一次cas,如果依旧失败则对cells数组进行扩容)
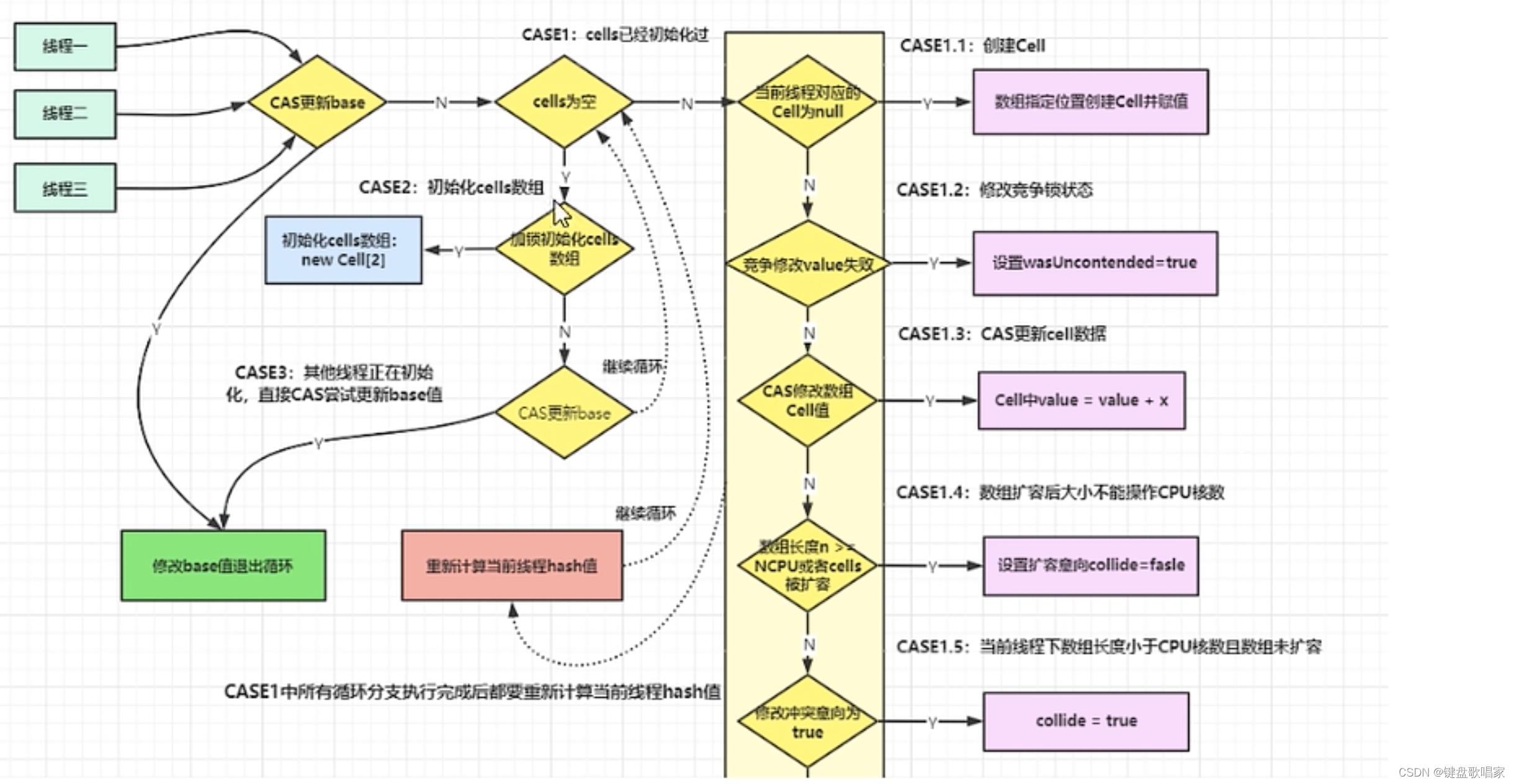
2.分析longAccumulate

final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
// 存储线程的probe值
int h;
// 如果getProbe()方法返回0,说明随机数未初始化
if ((h = getProbe()) == 0) { // 这个if相当于给当前线程生成一个非0的hash值
// 使用 ThreadLocalRandom 为当前线程重新计算一个hash值,强制初始化
ThreadLocalRandom.current(); // force initialization
// 重新获取probe值,hash值被重置就好比一个全新的线程一样,所以设置了wasUncontended竞争状态为true。
h = getProbe();
// 重新计算了当前线程的hash后认为此次不算是一次竞争,都未初始化,肯定还不存在竞争激烈,wasUncontended竞争状态为true
wasUncontended = true;
}
//如果hash取模映射到得到的cell单元不是null,则为true,此值也可以看作是扩容意向
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
// CASE1: cells已经被初始化了
if ((as = cells) != null && (n = as.length) > 0) {
// 前面add方法中第二个if判断的条件3成立就会走下面的这个if里面的逻辑
if ((a = as[(n - 1) & h]) == null) { // 当前线程的hash值运算后映射得到的Cell单元为null,说明cell没有被使用
if (cellsBusy == 0) { // cell[]数组没有正在扩容 Try to attach new Cell
Cell r = new Cell(x); // 创建一个cell单元 Optimistically create
if (cellsBusy == 0 && casCellsBusy()) { // 尝试加锁,成功后 cellBusy == 1
boolean created = false;
try { // 在有锁的情况下再检查一遍之前的判断 Recheck under lock
Cell[] rs; int m, j; // 将cell单元附到Cell[]数组上
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
else if (!wasUncontended) // wasUncontended表示第一次CAS更新Cell单元是否成功了 CAS already known to fail
wasUncontended = true; // 重新置为true,后面会调用”h = advanceProbe(h);“重新计算线程的hash值。由于此处没有break,再次循环会进入下面的if Continue after rehash
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x)))) // 尝试CAS更新cell单元格,cas成功则直接跳出循环(能进入改行说明当前线程对应的数组中有了数据,也重置过hash值)
break;
else if (n >= NCPU || cells != as) // 当Cell数组的大小已经超过CPU核数后,永远不会再进行扩容
collide = false; // 扩容标识,置为false,表示不会再进行扩容,并重新计算当前线程的hash值继续循环 At max size or stale
else if (!collide)
collide = true; // 如果扩容意向collide是false,则重新计算当前线程的hash值继续循环
else if (cellsBusy == 0 && casCellsBusy()) { // 尝试加锁进行扩容
try {
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1]; // 扩容后的大小 == 当前容量 * 2
for (int i = 0; i < n; ++i) // 扩容后再将之前数组的元素拷贝到新数组中
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
// 重置当前线程的hash值
h = advanceProbe(h);
}
// CASE2:cells没有加锁且没有初始化,则尝试对它进行加锁,并初始化cells的值
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
// 如果不进行double check,就会再次new一个cell数组,上一个线程对应数组中的值将会被篡改
if (cells == as) {
// 新建一个大小为2的Cell数组
Cell[] rs = new Cell[2];
// 找到当前线程hash到数组中的位置并创建其对应的Cell,x的默认值是1
// h & 1 类似于我们之前HashMap常用到的计算散列桶index的算法,通常都是hash & (tab.len - 1),同hashmap一个意思
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
// CASE3: cells正在进行初始化,则尝试直接在基数base上进行累加操作
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
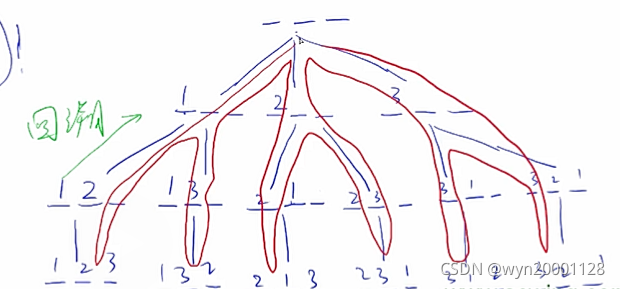
流程图总结:

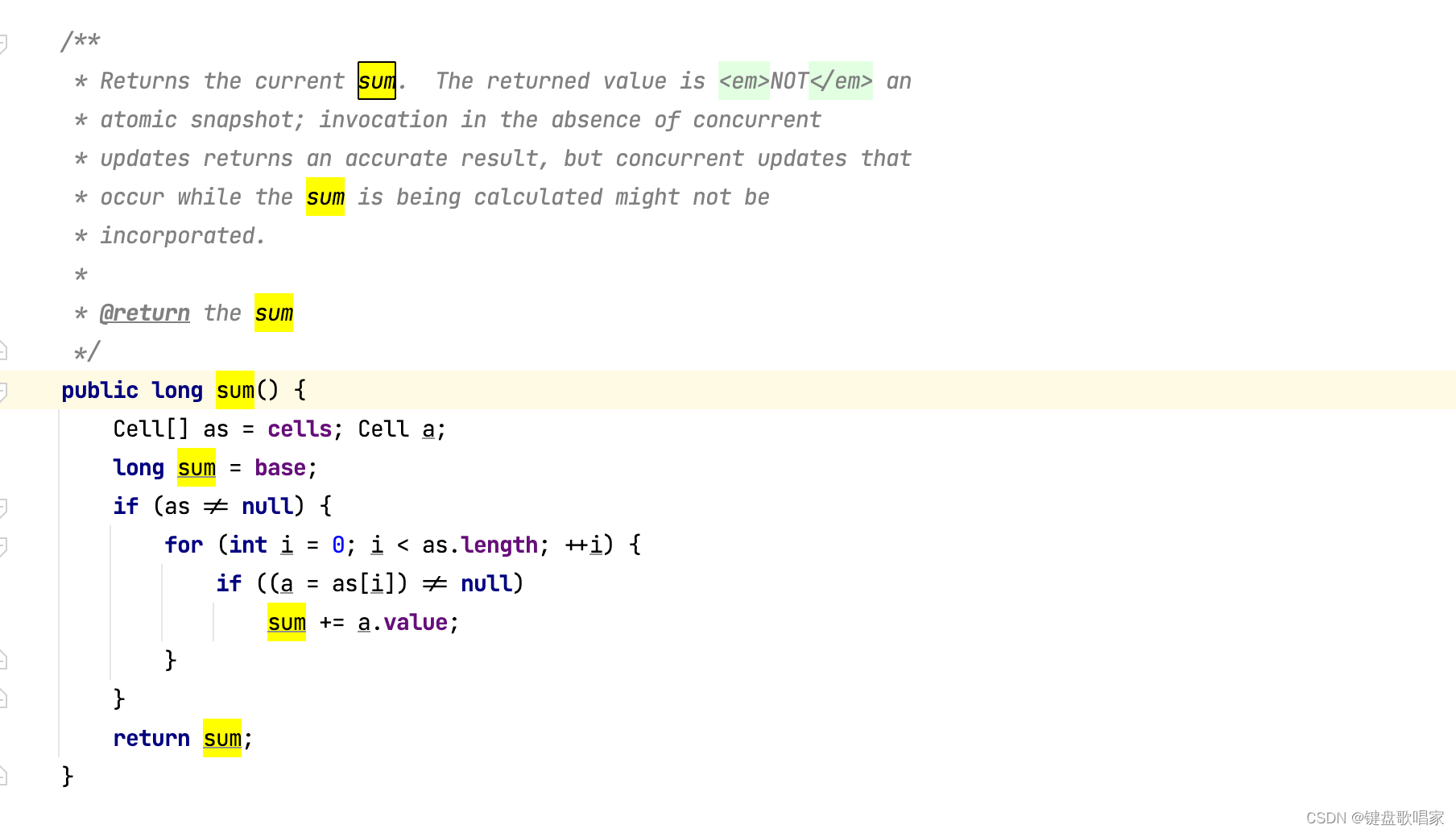
3.分析sum方法
发现底层很简单啊,直接把base和cells[]数组中的每个元素加起来,并且该方法没有加锁
三、最终总结表
AtomicLong:

LongAdder:








![[oeasy]python0070_ 字体样式_下划线_中划线_闪动效果_反相_取消效果](https://img-blog.csdnimg.cn/img_convert/7aac12e5545e9317af986e8824d4341c.png)