一、筛选与搜索
1.1 grep 命令 筛选数据
grep 是 Globally search a regular expression and print 的缩写。意思是全局搜索一个正则表达式,并且打印。
考虑这样的一个名为 a.txt 的文件:

执行 grep apple ./a.txt 即可匹配所有含有 apple 的字符
默认情况下,grep 命令是区分大小写的,加上 -i 参数即可忽略大小写

加入 -n 参数可以显示行号

使用 -v 参数是反选,匹配搜索不到的行

使用 -r 可以在所有子目录下查找文本
比如:grep -r "apple" folder/ 命令即在整个 folder 下文件夹匹配 apple 这个关键词。
1.2 使正则与 grep 命令
正则表达式高深莫测,在这里只列举一些常用的使用方式。
使用 grep 命令的 -E 参数可以使用正则表达式:
| . | 匹配除 “\n” 之外的任何单个字符 |
| ^ | 匹配行首(匹配输入字符串的开始位置) |
| $ | 匹配行尾(匹配输入字符串的结束位置) |
| [ ] | 在中括号的任意一个字符 |
| ? | 问号前面的元素出现零次或一次 |
| * | 星号前面的元素可能出现零次,一次或多次 |
| + | 加号前面的元素必须出现一次以上(包含一次) |
| | | 逻辑或 |
| ( ) | 表达式的分组(表示范围和有限度) |
grep -E ^apple ./a.txt 命令 即匹配以 apple 开头的一行数据
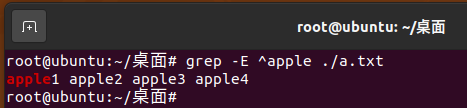
grep -E [Aa] ./a.txt 命令 即匹配 A 或 a 任意一个字符

grep -E [a-e1-9] ./a.txt 命令 匹配 a~e 和 1~9 之间的字符

二、管道
管道符号 | ,管道就是把两个命令连接起来使用,一个命令的输出作为另一个命令的输入。

比如我们有这三个文件,使用命令 ls | grep “.txt” 即可匹配到含有 .txt 的文件

wc -l 命令可以统计行数,我们在之后加入 ls | grep “.txt” | wc -l 即可统计匹配到的文件个数

有一些命令原生不支持管道符,考虑这样的命令:find -name *.txt” | ls -l 作用是将找到所有的 *.txt 然后交给 ls -l 详细输出。
但是输出效果却强差人意,是因为 ls 命令不支持管道符输入,他没有接收管道之前的命令,直接执行了 ls -l。

此时在命令加入 xargs 它的作用是将参数列表转换成小块分段传递给其他命令,以避免参数列表过长的问题。
find -name *.txt” | xargs ls -l 执行,可见效果符合我们的预期。

三、重定向
grep a a.txt > b.txt 命令即可将a.txt 中匹配到的字符不在终端输出,从而输出到 b.txt 里。这一过程被称为重定向。
注意!如果 b.txt 不存在即会创建,存在则会被覆盖掉!

3.2 重定向到文件末尾
如果我们只想追加到文件末尾,可以使用 >> 符号。
基于上边的案例,grep t a.txt >> b.txt

3.3 重定向错误输出
在Linux下,当一个用户进程被创建的时候,系统会自动为该进程创建三个数据流。(在下一章将会主要讲解进程这一概念,目前可以先把进程理解为一条命令)。分别是:
stdin、stdout、stderr 三种,分别是标准输入流,标准输出流,标准输出错误流。
一般来说,终端命令所反馈的东西都输出到标准输出流中,比如我们执行 date
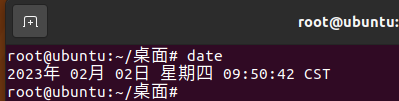
这个日期被输出到标准输出流中,但是一些错误信息会被输出到标准错误流:

即使是执行 find c.txt > b.txt 这行错误信息也会在终端打印出来,因为 > 符号只能重定向标准输出流。

3.3.1 文件描述符
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。通过这个索引值我们就可以获得其中的内容。
| 文件描述符 | 名字 | 解释 |
| 0 | stdin | 标准输入 |
| 1 | stdout | 标准输出 |
| 2 | stderr | 标准错误输出 |
如果需要将标准错误流输出到指定文件,只需将原来的 > 改写成 2> 也就是在前面加上了标准错误流的文件描述符。其实 > 符也等价于 1> ,两者并无区别。
来执行 find c.txt 2> error.log 可见标准错误没有输出到终端,但是输出到了文件夹。

如果使用 find c.txt 2>&1 a.txt 这样无论是标准输出还是标准错误输出都会输出到 a.txt 里。
四、进程管理
linux 是多任务多用户的操作系统。
多任务:linux 可以管理多个同时运行的程序。
多用户:多个用户可以在不同地方通过网络连接到同一个 linux 网络。
4.1 w 和 who 命令查看当前登录的用户
w 命令用于显示目前登入系统的用户信息。
执行后会提示出当前计算机的平均负载、当前时间、登录用户列表等信息。
对于单核 CPU 的 linux 电脑来说,负载为 1 即为满载。双核 2 为满载。同理,假设有50核,那么50 才是满载。

同时还有一个更纯净的 who 命令,他将只显示当前登录用户不显示别的:

4.2 ps 和 top 命令,列出运行的进程
进程就是加载到内存的程序。大多程序只在内存中加载一个进程,当然也可以使用多个进程。
2.2.1 ps 命令
ps 命令会列出当前用户,在当前终端所运行的程序,并不会列出其他用户的。
第一列 PID:为进程唯一标号
第二列 TTY:程序运行所在的终端
第三列 TIME:进程运行多久
第四列 CMD:产生这个进程的程序名,如果有好几个都是同样的程序名,那就是同一个程序产生了很多的进程

ps -ef 命令即可显示所有用户,所有终端的进程。
PPID 是进程的父进程号
STIME 为进程启动时间

4.2.2 top 命令
使用 top 命令可以实时看到更详细的说明,并且定时更新。摁q键可以退出

4.3 kill 命令 终止进程
| 信号编号 | 信号名 | 含义 |
|---|---|---|
| 0 | EXIT | 程序退出时收到该信息。 |
| 1 | HUP | 挂掉电话线或终端连接的挂起信号,这个信号也会造成某些进程在没有终止的情况下重新初始化。 |
| 2 | INT | 表示结束进程,但并不是强制性的,常用的 "Ctrl+C" 组合键发出就是一个 kill -2 的信号。 |
| 3 | QUIT | 退出。 |
| 9 | KILL | 杀死进程,即强制结束进程。 |
| 11 | SEGV | 段错误。 |
| 15 | TERM | 正常结束进程,是 kill 命令的默认信号。 |
kill 命令可以向内核发送一个信号量,内核根据信号量的指示做出相应的操作,而这些命令多是终止进程的。在上表已经列出了较为常用的信号量。
kill 不加参数默认信号量15正常结束命令,信号量15有时候不能结束程序,此时可以使用 kill -9 强制结束,这也是比较常用的参数。

4.4 将进程放置到后台运行
考虑执行 find / -name "*.log" 这样的一个命令,其作用是搜索找所有 *.log 的文件。
他会把所有输出的值打印在终端。
如果想要终止这种操作可以摁 ctrl + c 终止这个进程。
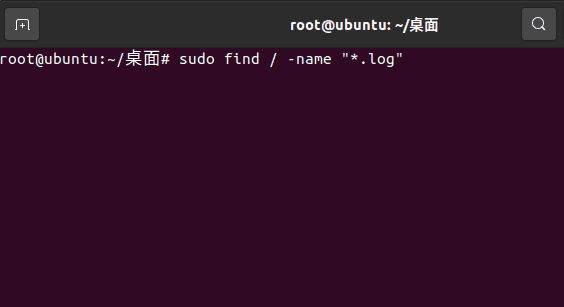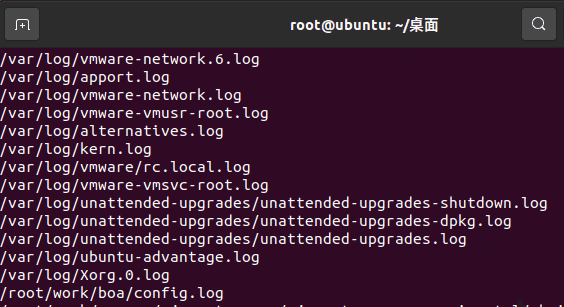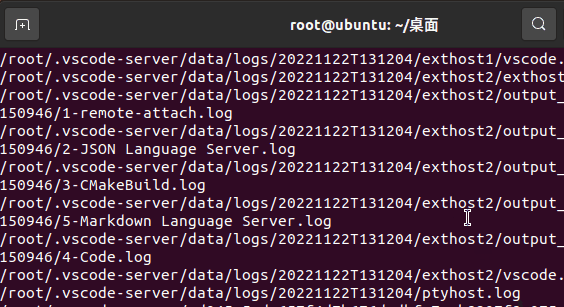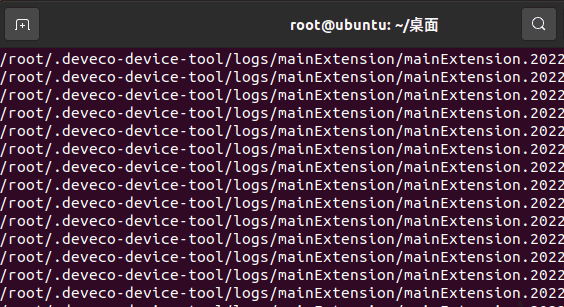
在 linux 中,任何命令后接一个 & 符号即可放置到后台运行
我们来执行 find / -name "*.log" & 但是其结果还是输出到终端了。这是因为程序虽然在后台运行,但是命令本身就是被设定为输出终端。转到后台并不影响其设定。
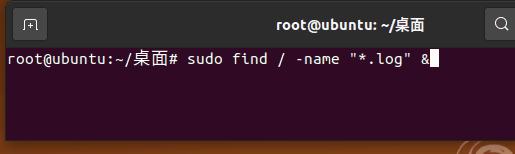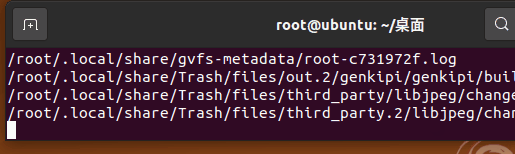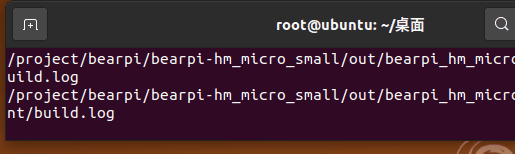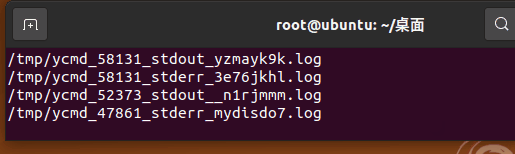
来改进一下: find / -name "*" > output_find 2>&1 & 其作用是寻找根目录下所有的文件写入到 output_find 文件中,错误输出也输出到另一个文件中。这样就不会打印在终端。
可见执行后输出了进程号 2331 并且之后我还执行了 date 命令,也是正常的。

4.5 nohup 命令 使进程与终端分离
在上面命令后加 & 转到后台有一个缺点,如果关闭终端,此命令也会终止。
nohup 用法很简单,只需要在命令前加上 nohup 即可。
nohup find / -name "*" > output_find 2>&1 &
4.6 ctrl + z 将前台程序转到后台
执行命令 find / -name "*" > output_find 2>&1 请注意,此命令没有在末尾加入 & 也就是他将在前台运行,摁 ctrl + z 后,提示 [1]+ 已停止。此进程后台编号为 1 (并不是PID进程编号),这是这条命令被放置在后台并暂停运行。
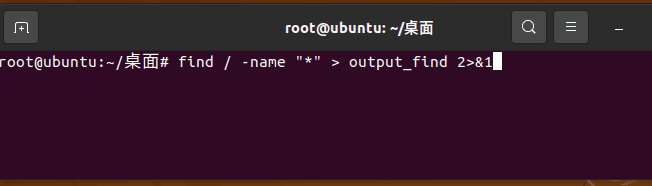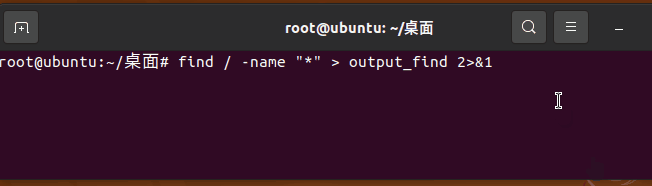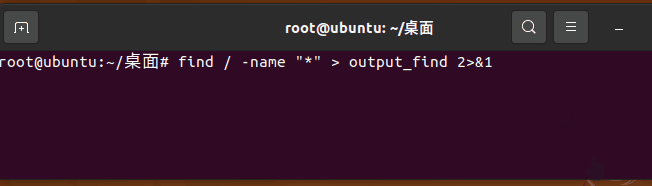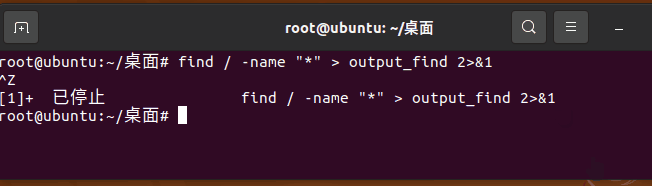
在此刻使用 ps -l 命令查看当前用户当前终端的进程详细情况查看:此进程当前在状态列显示 T 为stop 暂停的缩写,表示此进程暂停。

4.7 bg 命令 使进程在前后台切换
bg 命令在不加参数的时候,默认对最后一个后台进程操作。作用是将暂停的后台进程在后台运行。
下面还是先执行了 find / -name "*" > output_find 2>&1 ,之后 ctrl+z 后台暂停运行。
之后运行了 ps -l 查看此进程的状态为 S 暂停运行。
之后使用 bg 命令将其转为后台运行。
之后再使用 ps -l 查看进程状态,显示转为了 R 正在运行。

也可以使用 %+标号使指定的程序运行:
以下执行 bg %1 可以恢复标号为1的暂停进程

4.8 fg 命令 使进程转到前台
在下图中首先使用了 top 命令,
然后 ctrl+z 转为后台暂停
然后执行 fg %5 转为前台运行

4.9 进程前后台转化总结

五、任务的定时与延时
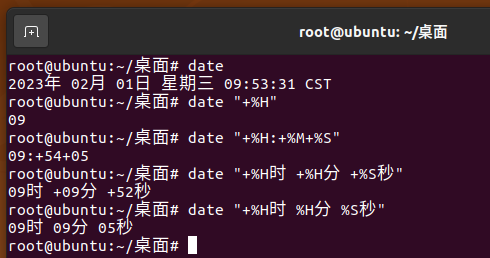
5.1 date 命令 显示时间
date 命令可以定制输出



![[oeasy]python0070_ 字体样式_下划线_中划线_闪动效果_反相_取消效果](https://img-blog.csdnimg.cn/img_convert/7aac12e5545e9317af986e8824d4341c.png)


![[Linux系列]linux bond详解](https://img-blog.csdnimg.cn/6a81679e694242dd81c1970eb0e7dfe9.png)